

我将CART独立于其他经典决策树算法的原因是CART相对来说较为复杂。因为它不仅仅可以作为分类树,还可以作为回归树。
CART分类树算法
对于对于CART分类树,这就和我们之前所说的《经典决策树算法》中的ID3与C4.5非常类似,但是与他们不同的是,我们在CART中并不采用信息增益或者是信息增益比来作为决策条件,而是采用了一种叫做基尼指数的衡量标准。这里我们不得不提到一个新的衡量特征好坏的方式:基尼指数。
基尼指数

基尼指数公式表达的是任取两个样本,这两个样本不相同的概率。宏观表达的是描述一个集合的混乱程度。基尼指数越大,表示这个样本集合D越混乱。这和熵的作用有些类似,但这仅仅是一个指数,能够判断大小,但不能像熵一样线性的量化集合中的混乱程度。 我们也很容易发现,基尼指数是一个(0,1)的数。 我们还有一个特征条件下的集合基尼指数定义:

CART分类生成算法

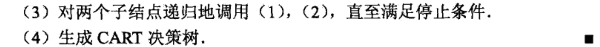
算法停止与节点样本个数小于阈值,或者是基尼指数小于阈值(样本基本属于同一类),或者没有更多特征。 CART分类树生成算法比较简单。就是将分配原则设定成了基尼指数。当然,我们还是最主要关注基尼指数的计算过程。我介绍个例子来辅助理解计算过程。
 

CART回归树算法
CART生成回归树的算法是用来根据已有数据生成一个回归树,具体算法如下:

这个算法比前面的那些算法要更加复杂一点,有很多公式。要想理解这个算法的作用,我们得先从感性上理解这个算法是做什么的。 我们考虑最简单的最小二乘回归,CART要求我们将所有输入数据都当作在二维的平面上若干个数据点。以x轴为划分依据(也就是最后的回归树的分界线是x的值,x大于或小于某个值会判断成什么)。
- 先自己认定一组切分点(一般认为是两个点x值的中点)。然后计算这一组切分点中每一个切分点对应的均方误差,找到均方误差最小的那个切分点作为一个节点。
- 这个切分点已经将整个空间划为两块(我们只考虑最简单的二维,所以一个点代表一条垂直于x轴的线),我们分别对这两块继续计算均方误差,找到下一个节点;
- 知道总的均方误差达到要求为止。
放个例子辅助理解:



参考文献:
李航《统计学习方法》 周志华《机器学习》
