/**
* The default initial capacity - MUST be a power of two.
* 默认初始容量-必须是2的幂。
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
MAXIMUM_CAPACITY 默认最大容量 常量
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*如果有一个更大的值被用于构造HashMap,则使用最大值
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
DEFAULT_LOAD_FACTOR 负载因子(默认0.75) 常量
/**
* The load factor used when none specified in constructor.
* 加载因子,如果构造函数中没有指定,则使用默认的
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
EMPTY_TABLE 默认的空表
/**
* An empty table instance to share when the table is not inflated.
* 当表不膨胀时共享的空表实例。
*/
static final Entry<?,?>[] EMPTY_TABLE = {};
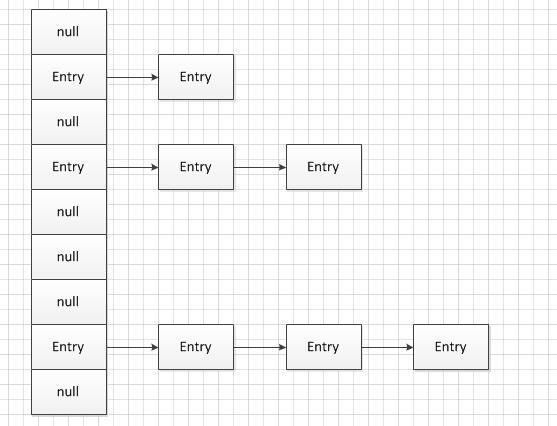
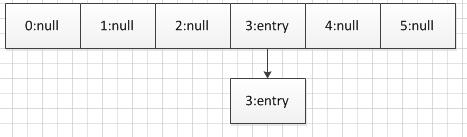
table 表,必要时调整大小。长度必须是两个幂。
这个也是hashmap中的核心的存储结构
/**
* The table, resized as necessary. Length MUST Always be a power of two.
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
size 表示HashMap中存放KV的数量(为链表/树中的KV的总和)
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
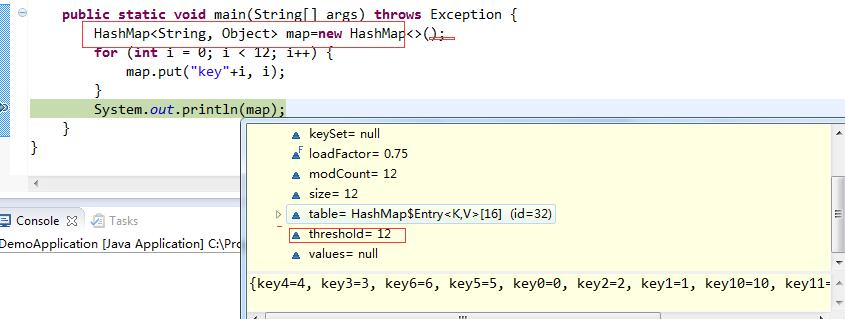
int threshold;
/**
* The number of times this HashMap has been structurally modified
* Structural modifications are those that change the number of mappings in
* the HashMap or otherwise modify its internal structure (e.g.,
* rehash). This field is used to make iterators on Collection-views of
* the HashMap fail-fast. (See ConcurrentModificationException).
*/
transient int modCount;
/**
* A randomizing value associated with this instance that is applied to
* hash code of keys to make hash collisions harder to find. If 0 then
* alternative hashing is disabled.
*/
transient int hashSeed = 0;
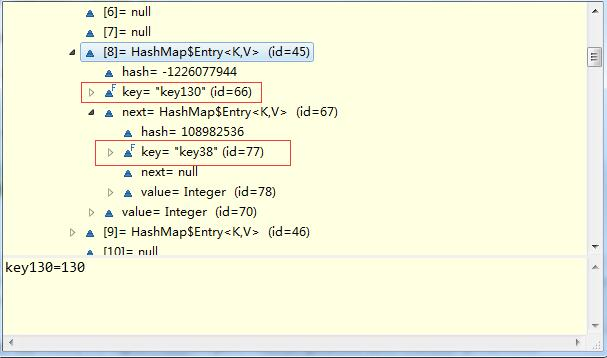
static class Entry<K,V> implements Map.Entry<K,V> {
final K key; //键对象
V value; //值对象
Entry<K,V> next; //指向链表中下一个Entry对象,可为null,表示当前Entry对象在链表尾部
int hash; //键对象的hash值
/**
* 构造对象
*/
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
/**
* 获取key
*/
public final K getKey() {
return key;
}
/**
* 获取value
*/
public final V getValue() {
return value;
}
/**
* 设置value,这里返回的是oldValue(这个不太明白,哪位大佬清楚的可以留言解释下,非常感谢)
*/
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
/**
* 重写equals方法
*/
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
returnfalse;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
returntrue;
}
returnfalse;
}
/**
* 重写hashCode方法
*/
public final int hashCode() {
return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue());
}
public final String toString() {
return getKey() + "=" + getValue();
}
/**
* This method is invoked whenever the value in an entry is
* overwritten by an invocation of put(k,v) for a key k that's already
* in the HashMap.
*/
void recordAccess(HashMap<K,V> m) {
}
/**
* This method is invoked whenever the entry is
* removed from the table.
*/
void recordRemoval(HashMap<K,V> m) {
}
}
/**
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
//这个函数确保在每个比特位置上仅以恒定倍数不同
//的散列码具有有限数量的冲突(在默认加载因子下大约为8)。
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}