

一、 索引:
按脚本新建两张表T1,T2表中数据存储如下:
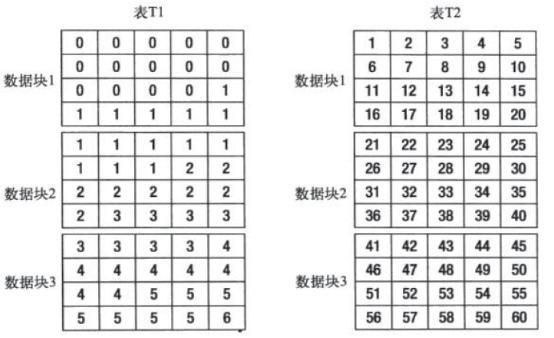
当对两张表进行相同的查询操作时,T1表会使用索引,但T2表不会它将进行全表扫描。
select * from t1 where id=10;
select * from t2 where id=10;
这主要是因为T1表的聚簇因子的值接近表的表块数量,而 T2表的聚簇因子的值接近表中数据数量。 如果聚簇因子的值接近表的表块数量,则说明目标索引索引行和存储于对应表中数据行的存储顺序相似程度非常高。这就意味着Oracle走索引范围扫描后取得目标rowid再回表访问对应表块中的数据时,相邻的索引行所对应的rowid找到的表数据极可能处于同一表块中。即Oracle在通过索引行记录的rowid回表第一次读取对应的表块并将该表块缓存在buffer cache中后,当再通过相邻索引行记录的rowid回表第二次去读取对应的表块时就不需要再产生物理I/O了,因为这两次访问的是同一个表块,而这个表块已经缓存在buffer cache中了。 如果聚簇因子的值接近表的记录数,则说明目标索引索引行和存储于对应表中数据行的存储顺序相似程度非常低,这就意味着Oracle走索引范围扫描取得rowid再回表访问对应表块的数据时,相邻的索引行所对应的rowid极可能不处于同一表块中,说明Oracle每次都要读对应的表块,每次都产生物理I/O。
B-TREE索引结构
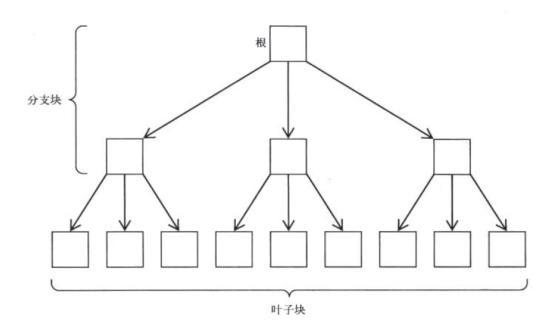
通过B树索引访问数据的过程:先访问相关的B树索引,然后根据访问该索引后得到的ROWID再回表访问相应的数据行记录。 这里访问相关的B树索引和回表都需要消耗I/O,这意味着访问索引的成本由两部分组成:一部分是访问相关的B树索引的成本(从根节点定位到相关的分支块,再定位到相关的叶子块,最后对这些叶子块进行扫描);另一部分是回表的成本(根据ROWID再回表扫面对应的数据行所在数据块)
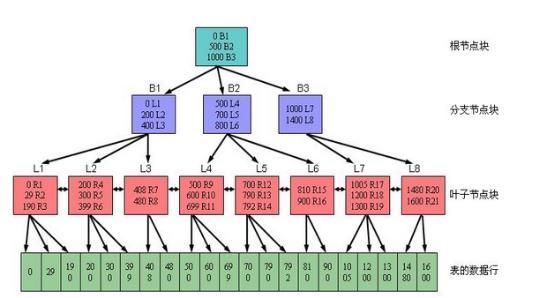
B树索引的优势:
- 所有的索引叶子块都在同一层,即它们距离索引根节点的深度是相同的。这也意味着访问索引叶子块的任何一个索引键值所花费的时间几乎相同;
- 通过B树索引访问表里行记录的效率并不会随着表的数据量的递增而显著降低,即通过走索引访问数据的时间是可控的、基本稳定的。
二、 访问索引的方法:
1.索引唯一性扫描,即准对唯一索引的扫面。

2.索引范围扫描,当扫描的对象时唯一性索引时,where条件一定是范围查询(即detween、<、>等);非唯一索引时没有限制。

3.索引全扫描:
适用于所有类型的B树索引。所谓的索引全扫描是指扫描目标索引的所有叶子块的所有索引列。这里需要注意索引全扫描需要扫描所有的叶子块但不意味着需要扫描所有的分支块。Oracle在做索引全扫描时只需要通过访问必要的分支块定位到位于该索引最左边的叶子块的第一行索引行就可以利用该索引叶子块之间的双向指针链表,从左到右依次顺序扫描该索引所有叶子块的所有索引行了。 因为索引是有序的所以通过索引全扫描得到的结果也是有序的即可以避免排序操作。

因为索引全扫描得到的结果是有序所以不能并行执行,而且只能单块读。
注意:索引列不能允许null,否则将不会走索引全扫描。
4.索引快速全扫描:和索引全扫描类似但它可以使用多块读,也可以并行执行,但它的结果是无序的。
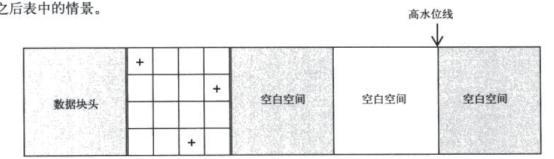
5.全表扫描可以使用多块读,会一直扫描到高水位。
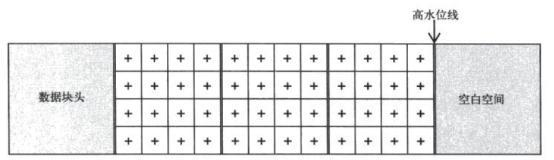
需要注意当使用delete删除数据时,高水位会保持不变就是说全表扫描所需的时间会差不多。
三、 索引的实际开发中的使用
- 查询列的值为null的情况下如何走索引,可以参考创建如下的索引:
create index idx_t3 on test3(object_id,0);
- 函数索引:
create index idx_t3_tm on test3(trunc(created));
- 左%使用索引:
create index idx_t3_nm on test3(reverse(object_name));
- 两列拼后接走索引:
create index idx_t3_un on test3(owner||'_'||object_type);
- 组合索引:选择性高的字段放前面
create index idx_t3 on test3(object_name,object_id);
select t.* from edcs.test3 t where t.object_id > 1 and t.object_name='I_IND1';
四、 表连接方法
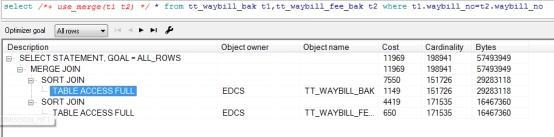
1. 排序合并链接(Sort Merge Join)
如果两张表(T1和T2表)在做表链接时使用的是排序合并链接,则Oarcle会按下面的步骤执行:
- 首先以目标表SQL中指定的谓语条件(如果有的话)去访问表T1,然后对访问结果按照表T1中的链接列做排序,排序后得到的结果集记为1;
- 接着以目标表SQL中指定的谓语条件(如果有的话)去访问表T2,然后对访问结果按照表T2中的链接列做排序,排序后得到的结果集记为2;
- 最后对结果集1和结果集1做合并操作,从中取出匹配的记录返回。
通常情况下,排序合并链接的效率不如哈希链接,但哈希链接只能使用等值链接条件,而排序合并链接可以用于非等值链接。排序合并链接因为需要对数据进行排序当数据量很大时排序是很耗I/O的。
可以使用use_merge()提示指定走排序合并链接。
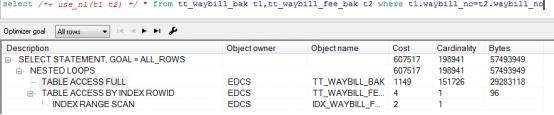
2. 嵌套循环链接(Nested Loops Join)
如果两张表(T1和T2表)在做表链接时使用的是嵌套循环链接,则Oarcle会按下面的步骤执行:
- 首先优化器会按一定的规则来决定表T1 、T2中谁是驱动表、谁是被驱动表。驱动表用于外层循环,被驱动表用于内层循环。这里假设T1是驱动表,T2是被驱动表;
- 接着以目标SQL中指定的谓语条件(如果有的话)去访问驱动表T1得到的结果集记为结果集1;
- 然后遍历结果集1逐条取出,在遍历被驱动表T2找到匹配的记录。相当于java中的两层for循环;
通过上面的描述我们可以看出,驱动表的结果集往往比较小,如果在被驱动表的链接上又存在选择性较好的索引,那么嵌套循环执行效率就会非常高。 嵌套循环还有一个优势就是它可以实现快速响应,即它可以第一时间将已链接过且符合链接条件的数据先返回,而不用等所有的链接操作都完成在返回。 可以使用use_nl()提示指定走嵌套循环链接。
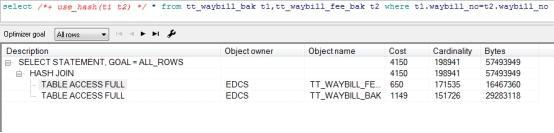
3、 哈希链接(Hash Join)
哈希链接是一种两个表在做表链接时主要依靠哈希运算来得到链接结果集的表链接方法。
在Oracle7.3之前数据库常用的表连接方法主要是排序合并链接和嵌套循环链接两种,但这两种方法都有各自明显的缺陷。对于排序合并链接,如果两个表在施加了目标SQL中指定的谓语条件后得到的结果集很大且需要排序则排序合并链接的执行效率一定不高;对于嵌套循环链接如果驱动表对应的驱动结果集很大,即使在被驱动表的链接列上存在索引效率也是很低。为解决上面的问题在Oracle7.3以后引入了哈希链接。但它只适用于等值的链接条件。
可以使用use_hash()提示指定走哈希链接。
4. 笛卡尔链接(Cross Join)
如果两张表(T1和T2表)在做表链接时使用的是笛卡尔链接,则Oarcle会按下面的步骤执行:
- 首先以目标表SQL中指定的谓语条件(如果有的话)去访问表T1,此时得到的结果集记为结果集1记录数为m;
- 接着以目标表SQL中指定的谓语条件(如果有的话)去访问表T2,此时得到的结果集记为结果集2记录数为n;
- 最终对结果集1和结果集2执行合并操作,最终的记录数为m*n。
sql优化脚本
--建表
create table test1 as (select trunc((rownum-1)/100) id,rpad(rownum,100) t_pad from dba_source where rownum<=10000);
create table test2 as (select mod(rownum-1,100) id,rpad(rownum,100) t_pad from dba_source where rownum<=10000);
--建索引
create index idx_t1 on test1(id);
create index idx_t2 on test2(id);
--表分析的方法
analyze table test1 compute statistics for table ;
analyze table test2 compute statistics for table ;
--索引分析的方法
analyze index idx_t1 compute statistics ;
analyze index idx_t2 compute statistics ;
--查看统计信息
SELECT A.INDEX_NAME, B.NUM_ROWS, B.BLOCKS, A.CLUSTERING_FACTOR
FROM USER_INDEXES A, USER_TABLES B
WHERE A.INDEX_NAME IN ('IDX_T1','IDX_T2')
AND A.TABLE_NAME = B.TABLE_NAME;
select count(1) from test1 where id=10;
select count(1) from test2 where id=10;
select count(1) from test1 ;
select count(1) from test2 ;
select * from edcs.test1 where id=10;
select * from edcs.test2 t where id=10;
create table test3 as select * from dba_objects;
analyze table edcs.test3 compute statistics for table ;
create index idx_t3 on test3(object_id);
analyze index idx_t3 compute statistics;
create index idx_t3_tm on test3(created);
analyze index idx_t3_tm compute statistics ;
select count(1) from test3 t; --77230
--查看执行计划
F5
set autot trace;
select * from table(dbms_xplan.display_cursor(null,null,'advanced'));
--唯一索引
select * from tm_dcs_process_detail_config t where t.process_detail_id=2585378;
--范围索引
select * from edcs.test3 t where t.object_id=15;
--索引全扫描
select t.process_detail_id from tm_dcs_process_detail_config t ;
--索引快速全扫描
select T.OBJECT_ID from TEST3 T;
select /*+ index_ffs(T IDX_T3) */ T.OBJECT_ID from TEST3 T;
--索引开发举例
--存在null值走索引的方法
select rowid ,t.* from test3 t where t.object_id is null;
drop index idx_t3;
create index idx_t3 on test3(object_id,0);
analyze index idx_t3 compute statistics ;
--函数索引
select * from test3 t where trunc(created)>=date'2011-09-16';
drop index idx_t3_tm;
create index idx_t3_tm on test3(trunc(created));
analyze index idx_t3_tm compute statistics ;
--%使用索引
create index idx_t3_nm on test3(object_name);
select * from test3 t where t.object_name like '%CON1';
drop index idx_t3_nm;
create index idx_t3_nm on test3(reverse(object_name));
analyze index idx_t3_nm compute statistics ;
select t.* from test3 t where reverse(t.object_name) LIKE reverse('%CON1');
--两列拼接走索引
select * from test3 t where owner||'_'||object_type ='SYS_CLUSTER';
create index idx_t3_un on test3(owner||'_'||object_type);
analyze index idx_t3_un compute statistics ;
--组合索引
create index idx_t3 on test3(object_id,object_name);
create index idx_t3 on test3(object_name,object_id);
select t.* from edcs.test3 t where t.object_id > 1 and t.object_name='I_IND1';
--表连接方式
select * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_merge(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_nl(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select /*+ use_hash(t1 t2) */ * from tt_waybill_bak t1,tt_waybill_fee_bak t2 where t1.waybill_no=t2.waybill_no;
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);
select t1.*
from tt_waybill_fee_bak t1,temp3 t2
where t1.waybill_no = t2.waybill_no;
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select /*+ no_unnest */ t2.waybill_no from temp3 t2);
--并行
select /*+ PARALLEL(T1 4)*/ t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);
select t1.*
from tt_waybill_fee_bak t1
where t1.waybill_no in
(select t2.waybill_no from temp3 t2);
转载自: 简书 - 低至一折起
