

Coroutine in Python
引言: 本文出自David Beazley 的关于协程的PPT,现在笔者将他翻译过来。并整理成文。感谢在协程方面的专家David Beazley, 能给我们这么深入的协程上面的讲座。也希望本文能给更多pythoner普及yield的更多用法,使python的这个特性能够更加多的活跃在大家的代码中。
源PPT和源码可以从这里下载:
http://www.dabeaz.com/coroutines/
问题:
1. 什么是协程
2. 协程怎么用
3. 要注意什么
4. 用他们好么
第一部分:生成器和协程的介绍
生成器(Generator)的本质和特点
生成器 是 可以生成一定序列的 函数。 函数可以调用next()方法。
生成器的例子:
- 例子1: follow.py 可以使用生成器完成 tail -f 的功能,也就是跟踪输出的功能。
import time
def follow(thefile):
thefile.seek(0,2) # Go to the end of the file
while True:
line = thefile.readline()
if not line:
time.sleep(0.1) # Sleep briefly
continue
yield line
- 例子2: 生成器用作程序管道(类似unix pipe)
ps:unix pipe
A pipeline is a sequence of processes chained together by their standard streams
标注:unix管道
一个uinx管道是由标准流链接在一起的一系列流程.
pipeline.py
def grep(pattern,lines):
for line in lines:
if pattern in line:
yield line
if __name__ == '__main__':
from follow import follow
# Set up a processing pipe : tail -f | grep python
logfile = open("access-log")
loglines = follow(logfile)
pylines = grep("python",loglines)
# Pull results out of the processing pipeline
for line in pylines:
print line,
理解pipeline.py
在pipeline中,follow函数和grep函数相当于程序链,这样就能链式处理程序。
Yield作为表达【我们开始说协程了~】:
grep.py
def grep(pattern):
print "Looking for %s" % pattern
print "give a value in the coroutines"
while True:
line = (yield)
if pattern in line:
print line
# Example use
if __name__ == '__main__':
g = grep("python")
g.next()
g.send("Yeah, but no, but yeah, but no")
g.send("A series of tubes")
g.send("python generators rock!")
yield最重要的问题在于yield的值是多少。
yield的值需要使用coroutine协程这个概念 相对于仅仅生成值,函数可以动态处理传送进去的值,而最后值通过yield返回。
协程的执行:
协程的执行和生成器的执行很相似。 当你初始化一个协程,不会返回任何东西。 协程只能响应run和send函数。 协程的执行依赖run和send函数。
协程启动:
所有的协程都需要调用.next( )函数。 调用的next( )函数将要执行到第一个yield表达式的位置。 在yield表达式的位置上,很容易去执行就可以。 协程使用next()启动。
使用协程的修饰器:
由【协程启动】中我们知道,启动一个协程需要记得调用next( )来开始协程,而这个启动器容易忘记使用。 使用修饰器包一层,来让我们启动协程。 【以后所有的协程器都会先有@coroutine
def coroutine(func):
def start(*args, **kwargs):
cr = func(*args, **kwargs)
cr.next()
return cr
return start
@coroutine
def grep(pattern):
...
关闭一个协程:
使用close()来关闭。
使用except捕获协程的关闭close():
grepclose.py
@coroutine
def grep(pattern):
print "Looking for %s" % pattern
try:
while True:
line = (yield)
if pattern in line:
print line,
except GeneratorExit:
print "Going away. Goodbye"
使用GeneratorExit这个异常类型
抛出一个异常:
在一个协程中,可以抛出一个异常
g.throw(RuntimeError,"You're hosed")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "<stdin>", line 4, in grep
RuntimeError: You're hosed
异常起源于yield表达式 可以用常规方法去抓取
一些小tips
* 尽管有点相似,但是生成器和协程是*两个完全不同的概念*。
* 生成器用来产生序列。
* 协程用来处理序列。
* 很容易产生一些误解。因为协程有的时候用来对进程里面的用来产生迭代对象的生成器作微调。
生成器不能够同时生成值和接受值
* 不能往generator里面send东西。
* 协程和迭代器的概念没有关系
* 虽然有一种用法,确实是在一个协程里面生成一些值,但是并不和迭代器有关系。
第二部分:协程,管道,数据流
进程管道:如下图所示,一连串进程串起来像管道一样。

第一部分,管道源/协程源:
进程管道需要一个初始的源(一个生产者)。 这个初始的源驱动整个管道。 管道源不是协程。
第二部分,管道终止/协程终止:
管道必须有个终止点。 管道终止/协程终止是进程管道的终止点。
例子:以实现tail -f 功能为例子
from coroutine import coroutine
# A data source. This is not a coroutine, but it sends
# data into one (target)
import time
def follow(thefile, target):
thefile.seek(0,2) # Go to the end of the file
while True:
line = thefile.readline()
if not line:
time.sleep(0.1) # Sleep briefly
continue
target.send(line)
# A sink. A coroutine that receives data
@coroutine
def printer():
while True:
line = (yield)
print line,
# Example use
if __name__ == '__main__':
f = open("access-log")
follow(f,printer())
分析:第一个follow函数是协程源,第二个printer函数是协程终止。协程源不是一个协程,但是需要传入一个已经初始化完毕的协程。在协程源当中,调用send()。
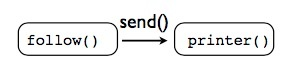
第三部分,管道过滤器:
叫过滤器其实并不贴切,应该叫中间人Intermediate:其两端都是send()函数。

@coroutine
def filter(target): # 这个target是传递参数的对象
while True:
item = (yield) # 这里用来接收上一个send()传入的value
# Transform/filter item
# processing items
# Send it along to the next stage
target.send(item) # 像target传递参数
分析可知,中间层需要接受上一个coroutine,也需要往下一个coroutine里面传递值。
一个管道过滤器的例子 从文章中找出具有“python”关键字的句子打印。 grep.py:
@coroutine
def grep(pattern, target): # 这个target用来接收参数
while True:
line = (yield) # 这里用来接收上一个send()传入的value
# Transform/filter item
# processing items
if pattern in line:
target.send(line)
# Send it along to the next stage
Hook it up with follow and printer:
f = open("access-log")
follow(f, grep('python', printer()))
grep 从中间传入follow,然后printer传入grep。

协程和生成器的对比

变得多分支:(上一个协程发送数据去多个下一段协程)
图示:
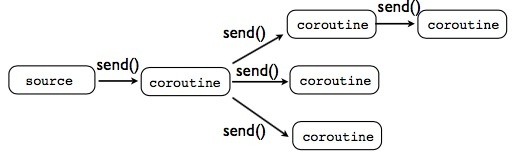
使用协程,你可以发送数据 给 多个 协程过滤器/协程终了。但是请注意,协程源只是用来传递数据的,过多的在协程源中传递数据是令人困惑并且复杂的。
一个例子
@coroutine
def broadcast(targets):
while True:
item = (yield)
for target in targets:
target.send(item)
Hook it Up!
if __name__ == '__main__':
f = open("access-log")
follow(f,
broadcast([grep('python',printer()),
grep('ply',printer()),
grep('swig',printer())])
)
从文章中分别打印出含有’python‘ ’ply‘ ’swig‘ 关键字的句子。使用了一个协程队列向所有printer协程 送出 接收到的数据。 图示:
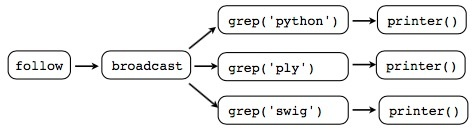
或者这样Hook them up:
if __name__ == '__main__':
f = open("access-log")
p = printer()
follow(f,
broadcast([grep('python',p),
grep('ply',p),
grep('swig',p)])
)
图示:
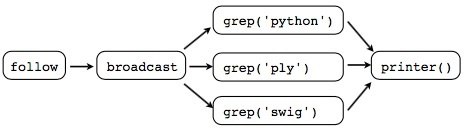
为什么我们用协程
- 协程相较于迭代器,存在更加强大的数据路由(就像上图的数据流向)的可能。
- 协程可以将一系列简单的数据处理组件,整合到管道,分支,合并等复杂的布置当中。
- 但有些限制…【后文会说】 相对于对象的优势
- 从概念上简单一点:协程就是一个函数,对象要构建整个对象。
- 从代码执行角度上来说,协程相对要快一些。
第三部分:协程,事件分发
事件处理
协程可以用在写各种各样处理事件流的组件。
介绍一个例子【这个例子会贯穿这个第三部分始终】要求做一个实时的公交车GPS位置监控。编写程序的主要目的是处理一份文件。传统上,使用SAX进行处理。【SAX处理可以减少内存空间的使用,但SAX事件驱动的特性会让它笨重和低效】。
把SAX和协程组合在一起
我们可以使用协程分发SAX事件,比如:
import xml.sax
class EventHandler(xml.sax.ContentHandler):
def __init__(self,target):
self.target = target
def startElement(self,name,attrs):
self.target.send(('start',(name,attrs._attrs)))
def characters(self,text):
self.target.send(('text',text))
def endElement(self,name):
self.target.send(('end',name))
# example use
if __name__ == '__main__':
from coroutine import *
@coroutine
def printer():
while True:
event = (yield)
print event
xml.sax.parse("allroutes.xml",
EventHandler(printer()))
解析:整个事件的处理如图所示
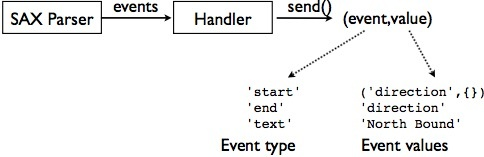
【最终的组合】
比如,把xml改成json最后从中筛选的出固定信息. buses.py
@coroutine
def buses_to_dicts(target):
while True:
event, value = (yield)
# Look for the start of a <bus> element
if event == 'start' and value[0] == 'bus':
busdict = {}
fragments = []
# Capture text of inner elements in a dict
while True:
event, value = (yield)
if event == 'start':
fragments = []
elif event == 'text':
fragments.append(value)
elif event == 'end':
if value != 'bus':
busdict[value] = "".join(fragments)
else:
target.send(busdict)
break
协程的一个有趣的事情是,您可以将初始数据源推送到低级别的语言,而不需要重写所有处理阶段。比如,PPT 中69-73页介绍的,可以通过协程和低级别的语言进行联动,从而达成非常好的优化效果。如Expat模块或者cxmlparse模块。 ps: ElementTree具有快速的递增xml句法分析
第四部分:从数据处理到并发编程
复习一下上面学的特点:
协程有以下特点。
- 协程和生成器非常像。
- 我们可以用协程,去组合各种简单的小组件。
- 我们可以使用创建进程管道,数据流图的方法去处理数据。
- 你可以使用伴有复杂数据处理代码的协程。
一个相似的主题:
我们往协程内传送数据,向线程内传送数据,也向进程内传送数据。那么,协程自然很容易和线程和分布式系统联系起来。
基础的并发:
我们可以通过添加一个额外的层,从而封装协程进入线程或者子进程。这描绘了几个基本的概念。
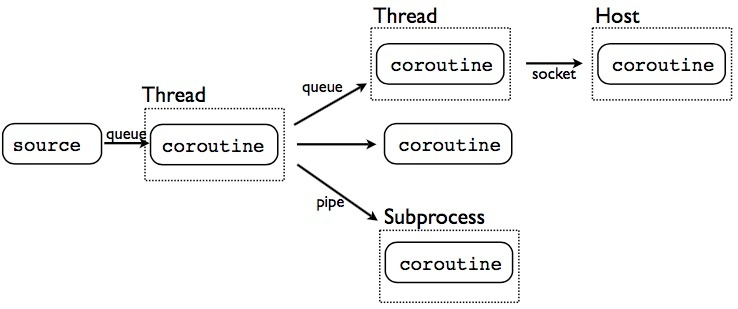
目标!协程+线程【没有蛀牙。
下面看一个线程的例子。 cothread.py
@coroutine
def threaded(target):
# 第一部分:
messages = Queue()
def run_target():
while True:
item = messages.get()
if item is GeneratorExit:
target.close()
return
else:
target.send(item)
Thread(target=run_target).start()
# 第二部分:
try:
while True:
item = (yield)
messages.put(item)
except GeneratorExit:
messages.put(GeneratorExit)
例子解析:第一部分:先新建一个队列。然后定义一个永久循环的线程;这个线程可以将其中的元素拉出消息队列,然后发送到目标里面。第二部分:接受上面送来的元素,并通过队列,将他们传送进线程里面。其中用到了GeneratorExit ,使得线程可以正确的关闭。
Hook up:cothread.py
if __name__ == '__main__':
import xml.sax
from cosax import EventHandler
from buses import *
xml.sax.parse("allroutes.xml", EventHandler(
buses_to_dicts(
threaded(
filter_on_field("route", "22",
filter_on_field("direction", "North Bound",
bus_locations()))))))
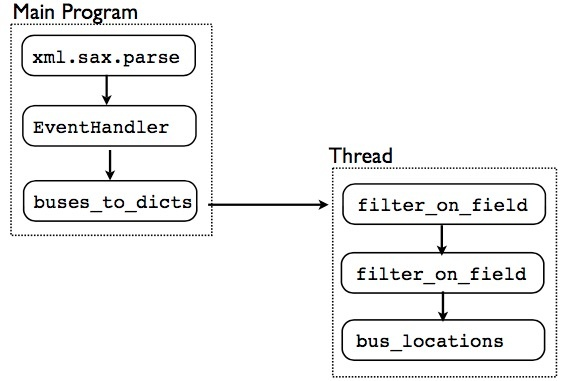
但是:添加线程让这个例子慢了50%
目标!协程+子进程
我们知道,进程之间是不共享系统资源的,所以要进行两个子进程之间的通信,我们需要通过一个文件桥接两个协程。

import cPickle as pickle
from coroutine import *
@coroutine
def sendto(f):
try:
while True:
item = (yield)
pickle.dump(item, f)
f.flush()
except StopIteration:
f.close()
def recvfrom(f, target):
try:
while True:
item = pickle.load(f)
target.send(item)
except EOFError:
target.close()
# Example use
if __name__ == '__main__':
import xml.sax
from cosax import EventHandler
from buses import *
import subprocess
p = subprocess.Popen(['python', 'busproc.py'],
stdin=subprocess.PIPE)
xml.sax.parse("allroutes.xml",
EventHandler(
buses_to_dicts(
sendto(p.stdin))))
程序通过sendto()和recvfrom()传递文件。
和环境结合的协程:
使用协程,我们可以从一个任务的执行环境中剥离出他的实现。并且,协程就是那个实现。执行环境是你选择的线程,子进程,网络等。
需要注意的警告:
- 创建大量的协同程序,线程和进程可能是创建 不可维护 应用程序的一个好方法,并且会减慢你程序的速度。需要学习哪些是良好的使用协程的习惯。
- 在协程里send()方法需要被适当的同步。
- 如果你对已经正在执行了的协程使用send()方法,那么你的程序会发生崩溃。如:多个线程发送数据进入同一个协程。
- 同样的不能创造循环的协程:
- 堆栈发送正在构建一种调用堆栈(send()函数不返回,直到目标产生)。
- 如果调用一个正在发送进程的协程,将会抛出一个错误。
- send() 函数不会挂起任何一个协程的执行。
第五部分:任务一样的协程
Task的概念
在并发编程中,通常将问题细分为“任务”。 “任务”有下面几个经典的特点: * 拥有独立的控制流。 * 拥有内在的状态。 * 可以被安排规划/挂起/恢复。 * 可与其他的任务通信。 协程也是任务的一种。
协程是任务的一种:
- 下面的部分 来告诉你协程有他自己的控制流,这里 if 的控制就是控制流。
@coroutine
def grep(pattern):
print "Looking for %s" % pattern
print "give a value in the coroutines"
while True:
line = (yield)
if pattern in line:
print line
- 协程是一个类似任何其他Python函数的语句序列。
- 协程有他们内在的自己的状态,比如一些变量:其中的pattern和line就算是自己的状态。
@coroutine
def grep(pattern):
print "Looking for %s" % pattern
print "give a value in the coroutines"
while True:
line = (yield)
if pattern in line:
print line
- 本地的生存时间和协程的生存时间相同。
- 很多协程构建了一个可执行的环境。
- 协程可以互相通信,比如:yield就是用来接受传递的信息,而上一个协程的send( )就是用来向下一个协程。
@coroutine
def grep(pattern):
print "Looking for %s" % pattern
print "give a value in the coroutines"
while True:
line = (yield)
if pattern in line:
print line
- 协程可以被挂起,重启,关闭。
- yield可以挂起执行进程。
- send() 用来 重启执行进程。
- close()用来终止/关闭进程。
总之,一个协程满足以上所有任务(task)的特点,所以协程非常像任务。但是协程不用与任何一个线程或者子进程绑定。
第六部分:操作系统的中断事件。(微嵌课程学的好的同学可以直接跳到这部分的“启示”✌️)
操作系统的执行(复习微嵌知识)
当计算机运行时,电脑没有同时运行好几条指令的打算。而无论是处理器,应用程序都不懂多任务处理。所以,操作系统需要去完成多任务的调度。操作系统通过在多个任务中快速切换来实现多任务。
需要解决的问题(还在复习微嵌知识)
CPU执行的是应用程序,而不是你的操作系统,那没有被CPU执行的操作系统是怎么控制正在运行的应用程序中断的呢。
中断(interrupts)和陷阱(Traps)
操作系统只能通过两个机制去获得对应用程序的控制:中断和陷阱。 * 中断:和硬件有关的balabala。 * 陷阱:一个软件发出的信号。 在两种状况下,CPU都会挂起正在做的,然后执行OS的代码(这个时候,OS的代码成功插入了应用程序的执行),此时,OS来切换了程序。
中断的底层实现(略…码字员微嵌只有70分🤦♀️)
中断的高级表现:
* 中断(Traps)使得OS的代码可以实现。
* 在程序运行遇到中断(Traps)时,OS强制在CPU上停止你的程序。
* 程序挂起,然后OS运行。
表现如下图:
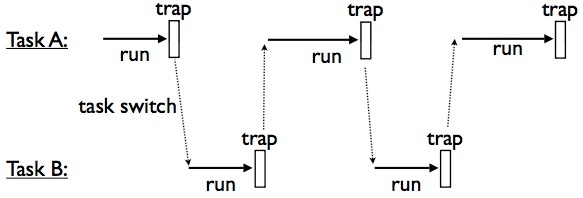
任务调度(非常简单):
为了执行很多任务,添加一簇任务队列。
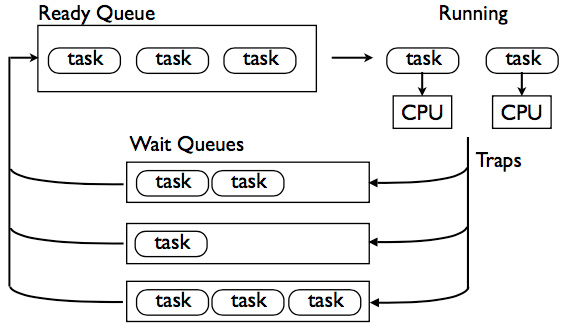
启示(很重要):
BB了这么多微嵌的内容,得到的是什么结论呢。类比任务调度,协程中yield声明可以理解为中断(Traps)。当一个生成器函数碰到了yield声明,那函数将立即挂起。而执行被传给生成器函数运行的任何代码。如果你把yield声明看成了一个中断,那么你就可以组件一个多任务执行的操作系统了。
第七部分:让我们建一个操作系统。【起飞了,请握好扶手
目标:满足以下条件建成一个操作系统。
1. 用纯python语句。
2. 不用线程。
3. 不用子进程。
4. 使用生成器和协程器。
我们用python去构建操作系统的一些动机:
* 尤其在存在线程锁(GIL)的条件下,在线程间切换会变得非常重要。我要高并发!
* 不阻塞和异步I/O。我要高并发!
* 在实战中可能会遇到:服务器要同时处理上千条客户端的连接。我要高并发!
* 大量的工作 致力于实现 事件驱动 或者说 响应式模型。我要组件化!
* 综上,python构建操作系统,有利于了解现在高并发,组件化的趋势。
第一步:定义任务
定义一个任务类:任务像一个协程的壳,协程函数传入target;任务类仅仅有一个run()函数。 pyos1.py
# Step 1: Tasks
# This object encapsulates a running task.
class Task(object):
taskid = 0 # 所有task对象会共享这个值。不熟悉的朋友请补一下类的知识
def __init__(self,target):
Task.taskid += 1
self.tid = Task.taskid # Task ID
self.target = target # Target coroutine
self.sendval = None # Value to send
# Run a task until it hits the next yield statement
def run(self):
return self.target.send(self.sendval)
任务类的执行:
if __name__ == '__main__':
# A simple generator/coroutine function
def foo():
print "Part 1"
yield
print "Part 2"
yield
t1 = Task(foo())
print "Running foo()"
t1.run()
print "Resuming foo()"
t1.run()
在foo中,yield就像中断(Traps)一样,每次执行run(),任务就会执行到下一个yield(一个中断)。
第二步:构建调度者
下面是调度者类,两个属性分别是Task队列和task_id与Task类对应的map。schedule()向队列里面添加Task。new()用来初始化目标函数(协程函数),将目标函数包装在Task,进而装入Scheduler。最后mainloop会从队列里面拉出task然后执行到task的target函数的yield为止,执行完以后再把task放回队列。这样下一次会从下一个yield开始执行。 pyos2.py
from Queue import Queue
class Scheduler(object):
def __init__(self):
self.ready = Queue()
self.taskmap = {}
def new(self,target):
newtask = Task(target)
self.taskmap[newtask.tid] = newtask
self.schedule(newtask)
return newtask.tid
def schedule(self,task):
self.ready.put(task)
def mainloop(self):
while self.taskmap:
task = self.ready.get()
result = task.run()
self.schedule(task)
下面是一个执行的例子:
# === Example ===
if __name__ == '__main__':
# Two tasks
def foo():
while True:
print "I'm foo"
yield
print "I am foo 2"
yield
def bar():
while True:
print "I'm bar"
yield
print "i am bar 2"
yield
# Run them
sched = Scheduler()
sched.new(foo())
sched.new(bar())
sched.mainloop()
执行结果,可以发现两个task之间任务是交替的,并且以yield作为中断点。每当执行撞到yield(中断点)之后,Scheduler对Tasks做重新的规划。下图是两个循环。 上述执行的结果:
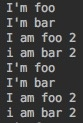
第三步:确定任务的停止条件
如果,target函数里面不是死循环,那么上面的代码就会出错。所以我们对Scheduler做改进。添加一个从任务队列中删除的操作,和对于StopIteration的验证。 【对scheduler做改进的原因是任务的性质:可以被安排规划/挂起/恢复。】
class Scheduler(object):
def __init__(self):
...
def new(self,target):
...
def schedule(self,task):
...
def exit(self,task):
print "Task %d terminated" % task.tid
del self.taskmap[task.tid]
def mainloop(self):
while self.taskmap:
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
continue
self.schedule(task)
第四步:添加系统调用基类。
在OS中,中断是应用程序请求系统服务的方式。在我们的代码中,OS是调度者(scheduler),而中断是yield。为了请求调度者服务,任务需要带值使用yield声明。 pyos4.py
class Scheduler(object):
...
def mainloop(self):
while self.taskmap: # 1
task = self.ready.get()
try: # 2
result = task.run()
if isinstance(result, SystemCall):
result.task = task
result.sched = self
result.handle()
continue
except StopIteration:
self.exit(task)
continue
self.schedule(task) # 3
class SystemCall(object): # 4
def handle(self):
pass
代码解析: 1. 如果taskmap里面存在task,就从ready队列里面拿任务出来,如果没有就结束mainloop。 2. 【就是传说中的系统调运部分】ready队列里面的task被拿出来以后,执行task,返回一个result对象,并初始化这个result对象。如果队列里面的task要停止迭代了(终止yield这个过程)就从队列里删除这个任务。 3. 最后再通过schedule函数把执行后的task放回队列里面。 4. 系统调用基类,之后所有的系统调用都要从这个基类继承。
第4.5步:添加第一个系统调用
这个系统调用想返回任务的id。 Task的sendval属性就像一个系统调用的返回值。当task重新运行的是后,sendval将会传入这个系统调用。 pyos4.py
...
class GetTid(SystemCall):
def handle(self):
# 把task的id传给task的返回参数:
self.task.sendval = self.task.tid
# 再把task给放入Scheduler的队列里面
self.sched.schedule(self.task)
class Task(object):
...
# Run a task until it hits the next yield statement
def run(self):
return self.target.send(self.sendval)
进行最后的调用:
if __name__ == '__main__':
def foo():
mytid = yield GetTid()
for i in xrange(5):
print "I'm foo", mytid
yield
def bar():
mytid = yield GetTid()
for i in xrange(10):
print "I'm bar", mytid
yield
sched = Scheduler()
sched.new(foo())
sched.new(bar())
sched.mainloop()
理解这段代码的前提:(非常重要) 1. send()函数有返回值的,返回值是yield表达式右边的值。在本段代码中,result的返回值是yield GetTid()的GetTid的实例或者是yield后面的None。 2. 执行send(sendval)以后,sendval被传入了yield表达式。并赋给了mytid,返回GetTid()给ruselt。
执行顺序: 先创建一个调度者(Scheduler),然后在调度者里面添加两个协程函数:foo(), bar(),最后触发mainloop进行协程的调度执行。
系统调用原理: 系统调用是基于系统调用类实现的,如GetTid类,其目的是传出自己的tid。传出自己的tid之后,再将task放回队列。
第五步:任务管理
上面我们搞定了一个GetTid系统调用。我们现在搞定更多的系统调用: * 创建一个新的任务。 * 杀掉一个已经存在的任务。 * 等待一个任务结束。 这些细小的相同的操作会与线程,进程配合。
1. *创建一个新的系统调用*:通过系统调用加入一个task。
# Create a new task
class NewTask(SystemCall):
def __init__(self,target):
self.target = target
def handle(self):
tid = self.sched.new(self.target)
self.task.sendval = tid
self.sched.schedule(self.task)
2. *杀掉一个系统调用*:通过系统调用杀掉一个task。
class KillTask(SystemCall):
def __init__(self, tid):
self.tid = tid
def handle(self):
task = self.sched.taskmap.get(self.tid, None)
if task:
task.target.close()
self.task.sendval = True
else:
self.task.sendval = False
self.sched.schedule(self.task)
3. 进程等待:需要大幅度改进Scheduler。
class Scheduler(object):
def __init__(self):
...
# Tasks waiting for other tasks to exit
self.exit_waiting = {}
def new(self, target):
...
def exit(self, task):
print "Task %d terminated" % task.tid
del self.taskmap[task.tid]
# Notify other tasks waiting for exit
for task in self.exit_waiting.pop(task.tid, []):
self.schedule(task)
def waitforexit(self, task, waittid):
if waittid in self.taskmap:
self.exit_waiting.setdefault(waittid, []).append(task)
return True
else:
return False
def schedule(self, task):
...
def mainloop(self):
...
exit_waiting 是用来暂时存放要退出task的地方。
class WaitTask(SystemCall):
def __init__(self, tid):
self.tid = tid
def handle(self):
result = self.sched.waitforexit(self.task, self.tid)
self.task.sendval = result
# If waiting for a non-existent task,
# return immediately without waiting
if not result:
self.sched.schedule(self.task)
设计讨论: * 在任务中引用另一个任务的唯一办法 是 使用scheduler分配给它的任务ID。 * 上述准则是一个安全的封装策略。 * 这个准则让任务保持独立,不与内核混淆在一起。 * 这个准则能让所有的任务都被scheduler管理的好好的。
网络服务器的搭建:
现在已经完成了: * 多任务。 * 开启新的进程。 * 进行新任务的管理。 这些特点都非常符合一个web服务器的各种特点。下面做一个Echo Server的尝试。
from pyos6 import *
from socket import *
def handle_client(client, addr):
print "Connection from", addr
while True:
data = client.recv(65536)
if not data:
break
client.send(data)
client.close()
print "Client closed"
yield # Make the function a generator/coroutine
def server(port):
print "Server starting"
sock = socket(AF_INET, SOCK_STREAM)
sock.bind(("", port))
sock.listen(5)
while True:
client, addr = sock.accept()
yield NewTask(handle_client(client, addr))
def alive():
while True:
print "I'm alive!"
yield
sched = Scheduler()
sched.new(alive())
sched.new(server(45000))
sched.mainloop()
但问题是这个网络服务器是I / O阻塞的。整个python的解释器需要挂起,一直到I/O操作结束。
非阻塞的I/O
先额外介绍一个叫Select的模块。select模块可以用来监视一组socket链接的活跃状态。用法如下:
reading = [] # List of sockets waiting for read
writing = [] # List of sockets waiting for write
# Poll for I/O activity
r,w,e = select.select(reading,writing,[],timeout)
# r is list of sockets with incoming data
# w is list of sockets ready to accept outgoing data
# e is list of sockets with an error state
下面实现一个非阻塞I/O的网络服务器,所用的思想就是之前所实现的Task waiting 思想。
class Scheduler(object):
def __init__(self):
...
# I/O waiting
self.read_waiting = {}
self.write_waiting = {}
...
# I/O waiting
def waitforread(self, task, fd):
self.read_waiting[fd] = task
def waitforwrite(self, task, fd):
self.write_waiting[fd] = task
def iopoll(self, timeout):
if self.read_waiting or self.write_waiting:
r, w, e = select.select(self.read_waiting,
self.write_waiting,
[], timeout)
for fd in r:
self.schedule(self.read_waiting.pop(fd))
for fd in w:
self.schedule(self.write_waiting.pop(fd))
源码解析:__init__里面的是两个字典。用来存储阻塞的IO的任务。waitforread()和waitforwrite()将需要等待写入和等待读取的task放在dict里面。这里的iopoll():使用select()去决定使用哪个文件描述器,并且能够不阻塞任意一个和I/O才做有关系的任务。poll这个东西也可以放在mainloop里面,但是这样会带来线性的开销增长。 详情请见:Python Select 解析 - 金角大王 - 博客园
添加新的系统调用:
# Wait for a task to exit
class WaitTask(SystemCall):
def __init__(self, tid):
self.tid = tid
def handle(self):
result = self.sched.waitforexit(self.task, self.tid)
self.task.sendval = result
# If waiting for a non-existent task,
# return immediately without waiting
if not result:
self.sched.schedule(self.task)
# Wait for reading
class ReadWait(SystemCall):
def __init__(self, f):
self.f = f
def handle(self):
fd = self.f.fileno()
self.sched.waitforread(self.task, fd)
# Wait for writing
class WriteWait(SystemCall):
def __init__(self, f):
self.f = f
def handle(self):
fd = self.f.fileno()
self.sched.waitforwrite(self.task, fd)
更多请见开头那个连接里面的代码:pyos8.py
这样我们就完成了一个多任务处理的OS。这个OS可以并发执行,可以创建、销毁、等待任务。任务可以进行I/O操作。并且最后我们实现了并发服务器。
第八部分:协程栈的一些问题的研究。
我们可能在使用yield的时候会遇到一些问题:
先来看一段示例代码:
def Accept(sock):
yield ReadWait(sock)
return sock.accept()
def server(port):
while True:
client,addr = Accept(sock)
yield NewTask(handle_client(client,addr))
这种情况下,server()函数里面的有调用Accept(),但是accept函数里面的yield不起作用。这是因为yield只能在函数栈的最顶层挂起一个协程。你也不能够把yield写进库函数里面。 【这个限制是Stackless Python要解决的问题之一。
解决这个只能在函数栈顶挂起协程的解决方法。 * 有且只有一种方法,能够创建可挂起的子协程和函数。 * 但是,创建可挂起的子协程和函数需要通过我们之前所说的Task Scheduler本身。 * 我们必须严格遵守yield声明。 * 我们需要使用一种 -奇淫巧技- 叫做Trampolining(蹦床)。
让我们来看看这个叫蹦床的奇淫巧技。
代码:trampoline.py
def add(x, y):
yield x + y
# A function that calls a subroutine
def main():
r = yield add(2, 2)
print r
yield
def run():
m = main()
# An example of a "trampoline"
sub = m.send(None)
result = sub.send(None)
m.send(result)
# execute:
run()
整个控制流如下:
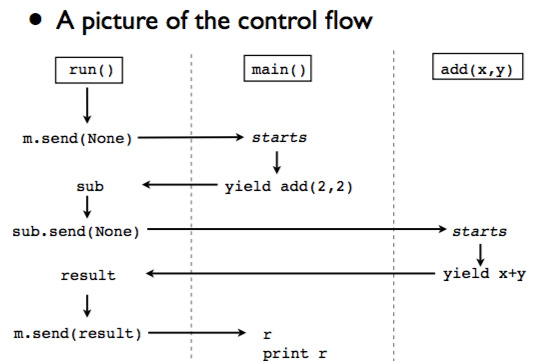
我们看到,上图中左侧为统一的scheduler,如果我们想调用一个子线程,我们都用通过上面的scheduler进行调度。
控制流:
控制过程: scheduler -> subroutine_1 -> scheduler -> subroutine_2 -> scheduler -> subroutine_1 就像蹦床(trampolining)一样,所有的子进程调度都要先返回scheduler,再进行下一步。【有点像汽车换挡。
而不是: -scheduler -> subroutine_1 -> subroutine_2 -> subroutine_1- 这种直接栈式的子协程调度是不被允许的。
第九部分:最后的一些话。
更加深远的一些话题。
有很多更加深远的话题值得我们去讨论。其实在上面的套路里面都说了一些。 * 在task之间的通信。 * 处理阻塞的一些操作:比如和数据库的一些链接。 * 多进程的协程和多线程的协程。 * 异常处理。
让我们对yield一点小尊重:
Python 的生成器比很多人想象的有用的多。生成器可以:
* 定制可迭代对象。
* 处理程序管道和数据流。【第二部分提到】
* 事物处理。【第三部分提到的和SAX结合的事务处理】
* 合作的多任务处理【第四部分提到的Task,子进程子线程合作】
在下列三种蛀牙的情况下我们可以想起来,使用yield。
* 迭代器:要产生数据。
* 接受数据/消息:消费数据。
* 一个中断:在合作性的多任务里面。
千万不要一个函数里面包含两个或多个以上的功能,比如函数是generator就是generator,是一个coroutine就是一个coroutin。
最后
感谢大家阅读。我是LumiaXu。一名电子科大正在找实习的pythoner~。
更多访问原作者的网站: http://www.dabeaz.com
#python/coroutine#
