

- 原文地址:Upgrade Your Project with CSS Selector and Custom Attributes
- 原文作者:Tim Harrison
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:MechanicianW
- 校对者:Hades tvChan
用 CSS 选择器和自定义属性来升级你的项目
这篇文章原文刊登在 TestProject。感谢你们的支持,让 SitePoint 成为可能。
Selenium WebDriver 的元素选择器是 自动化测试框架 中所提及的核心组件中的一种,同时也是与 web 应用进行交互的关键。在对 自动化元素选择器 的回顾中, 我们讨论了很多不同的选择器应用策略,探究其功能,权衡优缺点,最终我们推荐 最佳的选择器应用策略 —— 带有自定义属性的 CSS 选择器。
Selenium 的元素选择器
选择最好的 元素选择器 策略是成功的关键,也减轻了自动化工作的维护压力。因此,做出选择的时候应该从使用难度,多功能性,是否具有在线支持,文档丰富程度以及性能等多方面进行考虑。前期的充分考虑是有回报的,自动化工作会更容易维护。
就像从技术方面考虑元素选择器一样,也要考虑到团队文化。在自动化工作中采用元素选择器时,在开发者与 QA 之间成熟的合作文化可以解锁更高成就,取得更好的效果。夯实软件开发周期中其它方面的合作基础不仅对自动化工作有益,更是对团队有益。
所有的代码示例都是由 Python 和 Selenium WebDriver 中的命令编写而成,但也普遍适用于其它编程语言和框架。
HTML 代码示例:
在每一段的示例中,都是使用以下导航菜单的 HTML 片段代码:
<div id="main-menu">
<div class="menu"><a href="/home">Home</a></div>
<div class="menu"><a href="/shop">Shop</a>
<div class="submenu">
<a href="/shop/gizmo">Gizmo</a>
<a href="/shop/widget">Widget</a>
<a href="/shop/sprocket">Sprocket</a>
</div>
</div>
</div>
糟糕的选择器: 标签名,链接文本,部分链接文本和 name 属性选择器
关于这部分内容不需要花太多时间来讲,因为这些选择器的使用场景都很有限。在整个自动化框架中广泛使用这些选择器不是一个好选择。它们所完成的需求完全可以通过其它元素选择器策略轻松实现。只有在特定需求中需要去处理特殊案例的时候才使用这几种选择器。即使如此,大多数特殊场景并没有特殊到非要使用这几种选择器才能解决。你可以在没有其他选择器选项可用(例如自定义标签或 id)的情况下使用。
举个栗子:
使用标签名称选择器,会选择到非常多的匹配到标签名称的元素。它的用途非常有限,只能作为在需要选择大量相同类型的元素的唯一情况下的解决方案。下面这个例子会返回示例 HTML 代码中全部 4 个 div 元素。
driver.find_elements(By.TAG_NAME, "div")
也可以像下面的例子这样通过链接来选择。如你所见,这样只能定位到锚点标签而且只能定位这些锚点标签的文本:
driver.find_elements(By.LINK_TEXT, "Home")
driver.find_elements(By.PARTIAL_LINK_TEXT, "Sprock")
最后,也可以通过 name 属性来选择元素,但是在 HTML 代码示例中可以看出,那些标签是没有 name 属性的。这在绝大多数应用中都是一个常见问题,因为给每个 HTML 属性中添加一个 name 属性不是常规的代码实践。假如主菜单元素像下面一样有一个 name 属性:
<div id="main-menu" name="menu"></div>
可以像这样匹配到这个元素:
driver.find_elements(By.NAME, "menu")
如你所见,以上这些元素选择策略的使用场景都很有限。下面的方法都会更好一些,它们更灵活多变。
总结: 标签名,链接文本,部分链接文本和 name 属性选择器
| 优点 | 缺点 |
|---|---|
| 使用简单 | 不够灵活 |
| 使用场景极其有限 | |
| 在某些场景甚至可能用不了 |
还不错的选择器: XPath
XPath 是一种灵活多变的选择器策略。这是我个人很喜欢的。XPath 可以选择页面中的任意元素,无论它有没有 class 和 id (虽然没有 class 和 id 的话很难维护)。该选项非常灵活有用,因为你可以选择 父元素。XPath也有许多内置的功能,可以让你自定义元素选择。
但是,多功能性也带来了复杂性。鉴于 XPath 可以做这么多事,相比于其它选择器,它的学习曲线也更陡峭。这一不足是可以被它非常赞的在线文档抵消的。在 W3Schools.com 上找到的 XPath 入门指南 是一个很不错的资源。
还应该指出,使用 XPath 的时候有一件事需要进行权衡。虽然可以通过 XPath 选择父元素并使用一系列内置函数,但是 XPath 在 IE 浏览器的表现不佳。在选择元素选择器策略时,应该考虑这个问题。如果你有选择父元素的需要的话,要考虑它对 IE 上进行的 跨浏览器 测试的影响。本质上,在 IE 中运行自动化测试的耗时更长。如果你的用户群体的 IE 使用率不高的话,考虑到在 IE 上跑测试的时候更少,XPath 依然是一个好选择。如果你的用户基本上都是 IE 重度使用者的话,XPath 就只能作为没有其它更好方式时的备胎选择了。
举个栗子:
如果你有需求要选择父元素,那就必须采用 XPath。下面是做法,依然使用我们的示例,假设你要定位一个基于锚点元素的主菜单元素的父元素:
driver.find_elements(By.XPATH, "//a[id=menu]/../")
这个元素选择器会定位到第一个 id 等于 "menu" 的锚点标签,然后通过 “/../” 定位到它的父元素。最终结果就是你会定位到主菜单元素。
总结: XPath
| 优点 | 缺点 |
|---|---|
| 可以定位到父元素 | IE 上表现欠佳 |
| 非常灵活 | 陡峭的学习曲线 |
| 非常多的在线支持 |
超级棒的元素选择器: ID 和 Class
ID 和 Class 元素选择器在自动化中是两个不同的选项,会在应用程序中执行不同的功能。然而作为自动化工作的选择器策略,这两种选择器的区别很小,我们没必要将它们分开考虑。在应用程序中,UI 界面开发者可以操作和给定义了 "id" 和 "class" 属性的元素设置样式。对于自动化工作来说,我们使用它们来针对特定元素进行交互。
使用 ID 和 Class 原则器的一大好处是它们受应用程序结构变化的影响最小。假设,你要创建一个链式地依赖于一些元素和 子元素 的 XPath 或 CSS 选择器,如果此时有一个功能需要增加一些新元素从而中断了这个链条,会发生什么?使用 ID 和 Class 元素选择器,您可以定位特定的元素,而不是依赖页面结构。同时也没有过于宽松易变。应该通过给特定元素的位置创建测试用例来自动检测改动。改动不应该毁坏你的整个自动化套件。但是,如果开发者直接对自动化中使用的 ID 或 Class 进行更改的话,还是会影响到你的测试。
又或者如果 HTML 标签没有自动化程序中可使用的 ID 和 Class 属性的话,这种策略就无法使用。如果 HTML 标签没有自动化程序中可使用的 ID 和 Class 属性的话,这种方法就很难使用。
举个栗子:
在示例中,如果我们想选择到顶级的菜单元素,那应该是这样的:
driver.find_elements(By.ID, "main-menu")
如果要选择第一个菜单项,则是这样:
driver.find_elements(By.CLASS_NAME, "menu")
总结: ID 和 Class 选择器
| 优点 | 缺点 |
|---|---|
| 易于维护 | 开发人员可能会直接修改它们,自动化工作就无法进行了 |
| 学习难度低 | |
| 受页面结构的影响最小 |
最佳的元素选择器: 具有自定义属性的 CSS 选择器
如果你们的 QA 团队与开发部门合作良好的话,你们很有可能会选择这种最佳实践方法应用到自动化工作中。使用自定义属性和 CSS 选择器来定位元素对于 QA 团队和整个组织来说都有很多好处。对于 QA 团队来说,这可以让自动化工程师直接定位到特定元素,无需创建复杂的元素原则器。但是,这需要在应用程序中添加自动化团队所需的属性。为了充分发挥最佳实践的优势,开发部门和 QA 团队应共同实施这一策略。
我想简短地提示一下,CSS 选择器方法并不依赖于自定义属性。CSS 选择器可以像 XPath 一样定位到 HTML 文档流中的任意标签和属性。
现在我们来看这个方法需要我们做什么。为了能最好地执行这一策略,你们的自动化团队了解自己在自动化工作中想要定位什么。在与开发人员的合作中,最有可能是与前端工程师的合作中,QA 团队需要制定一个自定义属性的应用模式,放到团队所需要连接合作的每一个目标中。对于这个例子来说,我们把 "tid" 属性附加到了目标元素上。
这里需要强调的一个技术上的注意事项是 CSS 选择器的限制。CSS 选择器是不允许像 XPath 一样选择父元素的。这是为了避免页面上 CSS 样式的无限循环。这对网页设计来说是件好事,但是,当它作为自动化的元素选择器时是一种限制。幸运的是,这种限制可以由开发实现自定义属性来避免。QA 应请求合适的自定义属性,以便无需选择父元素。
如果你们公司的开发部门和 QA 团队不存在合作文化的话,也不用担心!应该实施这个策略,因为它是可以推动合作的途径。无论这种合作文化是否存在,你也应该先采用这种方式然后看看效果怎么样。你不但会拥有一个易于维护的选择器策略,你还会看到遍及整个公司的协作文化所带来的便利。这种合作关系会在质量保障的多个方面受益,比如减少缺陷,缩短上市时间并提高生产力。
为了更好地实行这个策略并创建合作关系,QA 团队应该从一开始就参与到设计过程中,与开发部门合作并 review 需求。随着开发部门设计功能,QA 应该建议哪里可以实现自定义属性的位置,以最好地支持自动化工作。通过在设计阶段初期就鼓励这种合作,能够让 QA 团队和开发部门会在合作关系中走得更近,提高开发效率。这也可能会对软件开发周期的其它领域产生溢出效应。在鼓励开发部门与 QA 团队的合作中,他们彼此更将熟悉,同样的,这种关系也会映射到其它领域的合作中。
举个栗子:
在示例 HTML 代码中的锚点元素上使用自定义属性:
<div id="main-menu">
<div class="menu"><a tid="home-link" href="/home">Home</a></div>
<div class="menu"><a tid="shop-link" href="/shop">Shop</a>
<div class="submenu">
<a tid="gizmo-link" href="/shop/gizmo">Gizmo</a>
<a tid="widget-link" href="/shop/widget">Widget</a>
<a tid="sprocket-link" href="/shop/sprocket">Sprocket</a>
</div>
</div>
</div>
注意,一些元素上有了新属性。我们创建了一个叫 "tid" 的新属性,与标准的 HTML 属性并无任何充冲突。有了自定义属性,我们可以通过一个 CSS 元素选择器去定位它:
driver.find_element(By. CSS_SELECTOR, "[tid=home-link]")
假设,你想选择菜单中所有的链接,无论一级菜单还是二级菜单。你可以通过 CSS 选择器,创建灵活多变的元素选择器组:
driver.find_element(By.CSS_SELECTOR, "#main-menu [tid*='-link']")
"*=" 做的是,在所有元素的 "tid" 字段中由通配符搜索 "-link"。把它放到 "#main-menu" ID 选择符的后面,它就只搜索主菜单内的元素了。
如果你想脱离自定义属性来使用这个策略,也依然是正确路线。举例说,你可以通过如下方式定位到 Shop 的子菜单中的链接:
driver.find_element(By. CSS_SELECTOR, "#main-menu .submenu a")
这一策略可以使得工程师创建易于维护且不受 UI 界面中无关变化影响的自动化工作。选择这一策略是最好的方法。这不仅是一个易于维护的自动化解决方案,而且还会鼓励 QA 团队和开发人员之间的合作。
总结:具有自定义属性的 CSS 选择器
| 优点 | 缺点 |
|---|---|
| 学习难度低 | 初始阶段就涉及到与开发人员合作 |
| 丰富的在线支持 | |
| 灵活多变 | |
| 超级棒的兼容性 |
结论
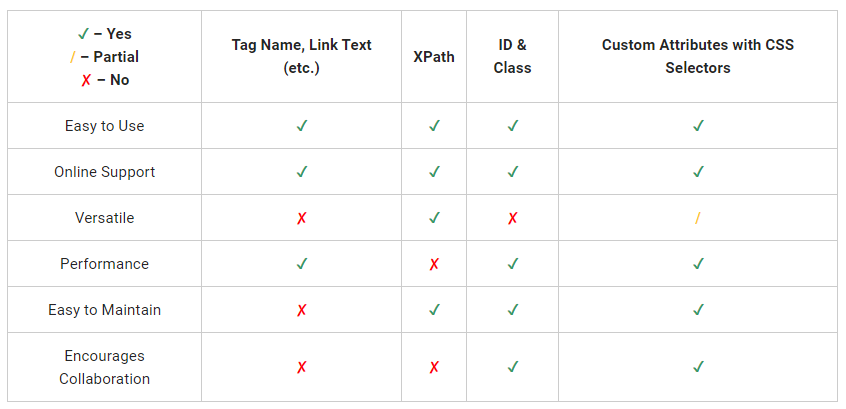
在自动化框架中实现企业标准级的元素选择器策略有一些很好的选择。应该避免选择像是标签名或链接文本选择器,除非它们是你唯一的选择。XPath,ID 和 Class 选择器则是一个好路线。到目前为止,最好的方法是实现自定义属性并用 CSS 选择器来定位。这也鼓励了开发部门与 QA 团队之间的合作。
这是所有选项的比较表:
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
