

背景
在当下互联网行业,监控概念与重要性已经不需要再进行阐述,然而监控分为多种,对物理层(机房,云主机)的监控,对传输链路的监控,对已部署服务的监控等等,而后端的代码通常直接运行在服务器并处于24小时实时的监控状态之下,一旦服务的可用性出现问题,SRE和DEV往往在第一时间就会收到告警,并根据告警信息在第一时间解决故障。相比之下,前端代码则运行在客户端上,为了让前端能够和后端一样,需要将客户端的前端代码监控起来,当客户端出现故障时,能第一时间通知到前端负责人,定位故障,及时止损。
那前端监控系统都需要监控什么?在前端应用日渐复杂的今天,我认为对于前端的监控主要分为三个方面:
性能监控
为什么要监控性能呢?因为对于任何一家互联网公司,性能往往与利益直接相关。有数据调查显示:当Google 延迟 400ms时,搜索量下降 0.59%、Bing 延迟 2s,收入下降 4.3%、Yahoo 延迟 400ms,流量下降 5-9%,所以,很多公司在做用户体验分析时,第一个看的就是性能监控指标,在前端领域,性能无非是以下参考指标:
- 白屏时间;
- 首屏时间;
- 用户可交互时间;
- 总下载时间;
- TCP连接时间;
- HTTP请求时间;
- HTTP响应时间;
而且很重要的一点,也是大家往往最容易忽视的:性能会伴随产品的迭代而有所衰减。特别在移动端,网络条件十分不稳定的情况下。性能优化不存在“黄金法则”,我们需要一套性能监控系统持续监控、评估、预警页面性能状况、发现瓶颈,更有针对性的指导优化工作的进行。
异常监控
除了性能之外,我们还要监控客户端脚本发生的报错,前端报错受网络,机型,业务逻辑影响而且大部分错误难以还原现场,比如我们团队时时收到用户的反馈和投诉:
- 甲用户 : 点击XX按钮之后页面白屏了
- 乙用户: 优惠劵消费后,支付金额显示不正确
- 丙用户:最近页面特别卡,点击tab好久才能反应过来
面对用户的反馈,开发经常感到困惑:到底有多卡,哪个步骤卡?是个别现象还是大面积都受到了影响?白屏时页面请求的返回码是多少?是被运行商劫持还是CDN出了问题?能让用户用Charles配合抓个包么?如何做有针对性的优化?优化的结果怎么去衡量?
为了解决这些痛点,我们需要对客户端服务进行基于用户行为的监控。
数据监控
互联网公司的产品,每一个决策,每一个迭代都需要分析各种数据,数据中往往会有我们需要的答案:
- 页面PV,UV可能直接影响转化率
- 从用户访问页面的顺序挖掘使用习惯(等等)
这部分监控数据主要供PM/PD使用,业务数据可以驱动业务自身的增长,有人曾说:“要降低创业失败的可能性只有两种方法:一是未卜先知,另一个是做精益的数据分析”,由此可见数据分析的重要性。
传统解决方案及缺陷
目前已经存在了一些针对前端监控解决方案:Sentry,Badjs,jsTracker,GrowingIo等等,在公司内部也有自研的监控系统。它们都从不同维度试着解决前端在监控方面的问题,大家的实现思路都很类似、要实现监控,首先要采集指标:
性能指标
这里要针对的主要是白屏时间、首屏时间、用户可操作、总下载时间。
这里以首屏时间为例:高版本chrome浏览器中可以直接通过 firstPaintTime 接口来获取load time,但大部分浏览器并不支持,必须想其他办法来监测。谨记一点,在做时间相关测量时,千万不要使用setTimeout和setInterval方法,因为在单线程执行引擎中,异步队列的执行是不能确保执行时间的。这边给出一种可行的测量方案,准确率在99成以上。
<doctype html>
<html>
<head>
<script type="text/javascript">
var timerStart = Date.now();
</script>
<!-- 加载其他资源,执行代码blabla -->
</head>
<body>
<!-- 路由框架挂载节点 -->
<script type="text/javascript">
$(document).ready(function() {
console.log("DOMready 时间 ", Date.now()-timerStart);
});
$(window).load(function() {
console.log("所有资源加载完成 时间: ", Date.now()-timerStart);
});
</script>
</body>
</html>
另一种优雅的解决方案是直接使用window.performance接口:
connectEnd Time when server connection is finished.
connectStart Time just before server connection begins.
domComplete Time just before document readiness completes.
domContentLoadedEventEnd Time after DOMContentLoaded event completes.
domContentLoadedEventStart Time just before DOMContentLoaded starts.
domInteractive Time just before readiness set to interactive.
domLoading Time just before readiness set to loading.
domainLookupEnd Time after domain name lookup.
domainLookupStart Time just before domain name lookup.
fetchStart Time when the resource starts being fetched.
loadEventEnd Time when the load event is complete.
loadEventStart Time just before the load event is fired.
navigationStart Time after the previous document begins unload.
redirectCount Number of redirects since the last non-redirect.
redirectEnd Time after last redirect response ends.
redirectStart Time of fetch that initiated a redirect.
requestStart Time just before a server request.
responseEnd Time after the end of a response or connection.
responseStart Time just before the start of a response.
timing Reference to a performance timing object.
navigation Reference to performance navigation object.
performance Reference to performance object for a window.
type Type of the last non-redirect navigation event.
unloadEventEnd Time after the previous document is unloaded.
unloadEventStart Time just before the unload event is fired.接口兼容性:
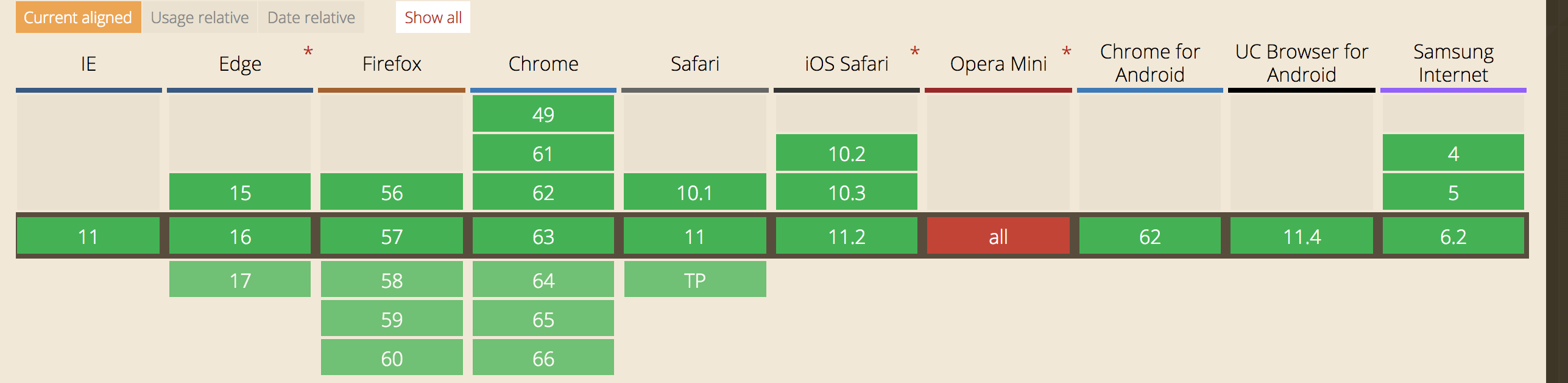
异常指标
主动捕获异常方案主要是 onError 和 addEventListener,onError 在 IE6 开始就支持了,所以 大部分系统的主动采集是使用的 onError。这里注意浏览器的同源性策略(CORS),在高级浏览器中如果浏览器捕获到了错误信息,如果 JS 文件所在的域名(如:meituan.com)和当前的页面地址(如:dianping.com)是跨域的,那么引擎会自动把onError 中的参数 替换为 script error,此时无法获取行列数以及报错详细信息。解决方案是在标签引入时加上crossorigin字段。
虽然传统方法能够自动catch大部分错误,但是也伴随着以下缺陷:
- 部分应用在不同网络,机型上表现不同,开发人员需要获取到更详细的分类信息,传统系统很难做分类聚合,开发面对几十页分类的table无从下手。
- 错误与错误之间往往成相关性,但是在传统系统中catch到的错误都是孤立的,没有基于用户行为的分析。
- 针对异常的告警配置不够灵活,无法满足开发需求:大部分异常告警指标伴随高低峰期波动,没有一成不变的指标,而传统告警平台都是采用绝对阈值的告警方案,要么高峰期误报太多,要么低峰期错误无法发现。
数据指标
传统监控方案采用的都是手动埋点上报,但是缺点十分明显:手动埋点往往会出现埋点混乱,甚至埋错、漏埋的问题,埋点沟通过程中,数据团队和业务工程团队配合困难,新功能的开发往往伴随着新埋点的增加,而且数据团队的需求优先级往往靠后,导致很多新上线功能得不到数据的验证。
而有些基于关系型数据库的系统实时性差,数据要隔天才能查看,查询命令执行一次动辄耗费几十分钟乃至上小时,已经没有效率可言。
新解决方案
伴随着上面讨论的问题,我们寻求新的解决方案,一种高可用的监控方案。它应该具有如下特征:
- 全量采集:监控指标健全,端到端采集全量的性能指标,关键执行方法,业务指标,覆盖率做到2个9以上。
- 无需埋点:全量上报,无需开发人员手动埋点,从根本上杜绝错埋和漏埋
- 查询便捷:能够按照地域,机型,操作系统,浏览器版本,网络状况等多个维度进行数据查询,最好支持全文搜索,分类聚合。
- 场景还原:根据打点信息,还原用户从登陆开始一系列操作,建立基于用户行为的时序图。
- 实时性强:秒级查询,上线后能立即看到优化效果并指导下一步优化。
- 智能告警:采用静态阈值和动态阈值结合的方式,兼顾高低峰,减少误报漏报。并针对业务数据建立告警指标,发现系统深层次问题。
根据这些需求,我们团队打造了一套全新的监控体系,新系统采用了无埋点SDK(小程序),ELK做本地化日志存储,并使用了基于动态阈值的告警策略。下面是系统架构图:
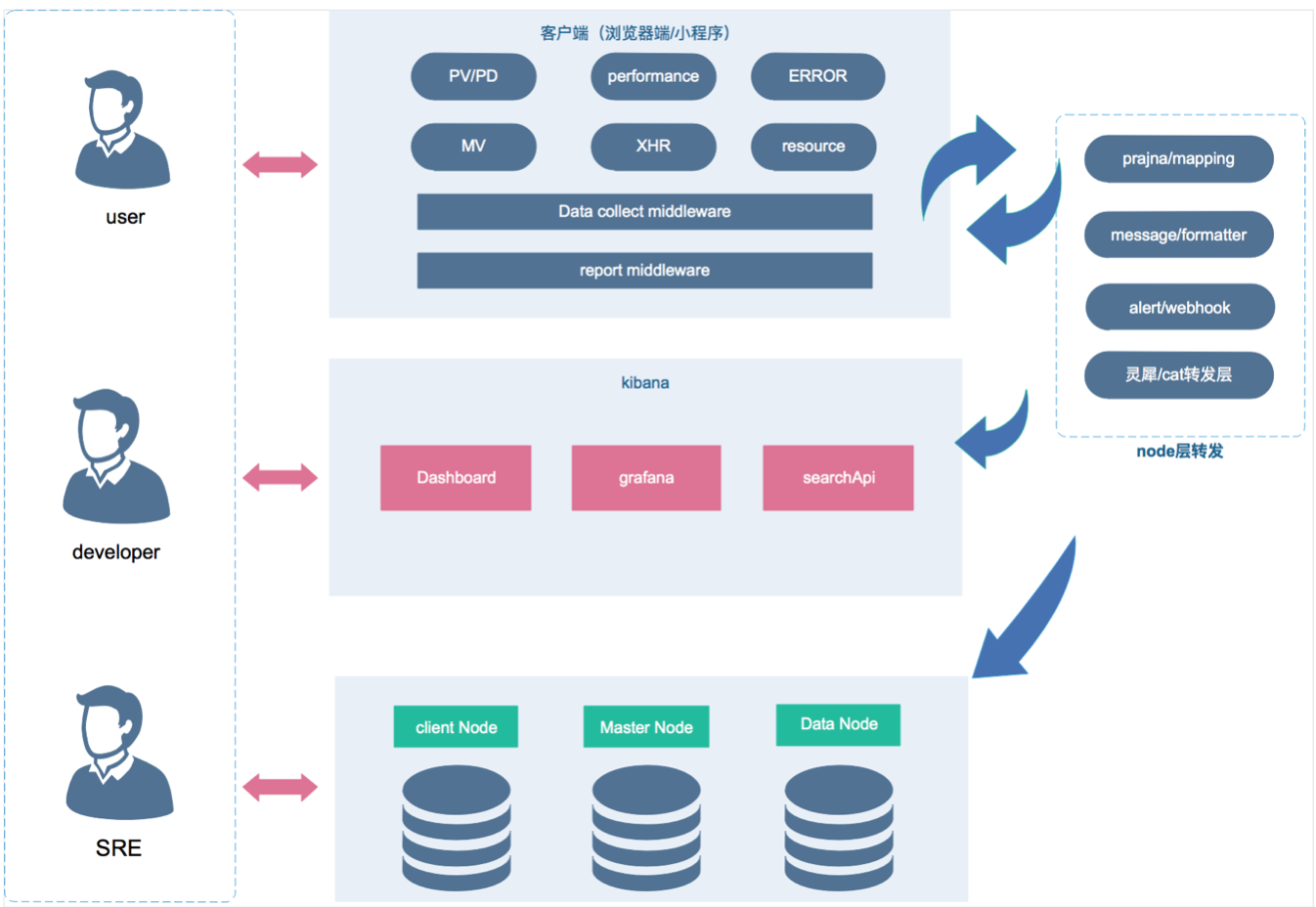
开发人员在本地通过代码接入SDK后,即可使用监控体系的全部功能:数据采集,上报,聚合分析,智能告警等功能,而且所有数据均是实时上报,秒级查询。
在最开始探索过程中,我们使用webpack插件+npm包下载方式,但是由于两部分上报逻辑在网络极差的情况下,会出现写缓存冲突的问题,导致重复上报或错误上报,现已将架构调整为单一script标签引入的方式,部分保留下来的主动上报接口,开发可以根据自己需要在业务代码中再次封装:
...
moduleClick(options) {
const { name, ...otherOptions } = options;
M.moduleClick(name, otherOptions);
},
/**
* 曝光事件
* @param options
*/
moduleView(options) {
const { name, ...otherOptions } = options;
M.moduleView(name, otherOptions);
},
/**
* 编辑事件
* @param options
*/
moduleEdit(options) {
const { name, ...otherOptions } = options;
M.moduleEdit(name, otherOptions);
},
...
接入后,新版系统和之前相比有哪些变化?
1.因为采集是无埋点全量的,关键方法都会进行参数上报,然后可以通过分类聚合建立用户的操作时序,通过故障上下文准确定位问题。
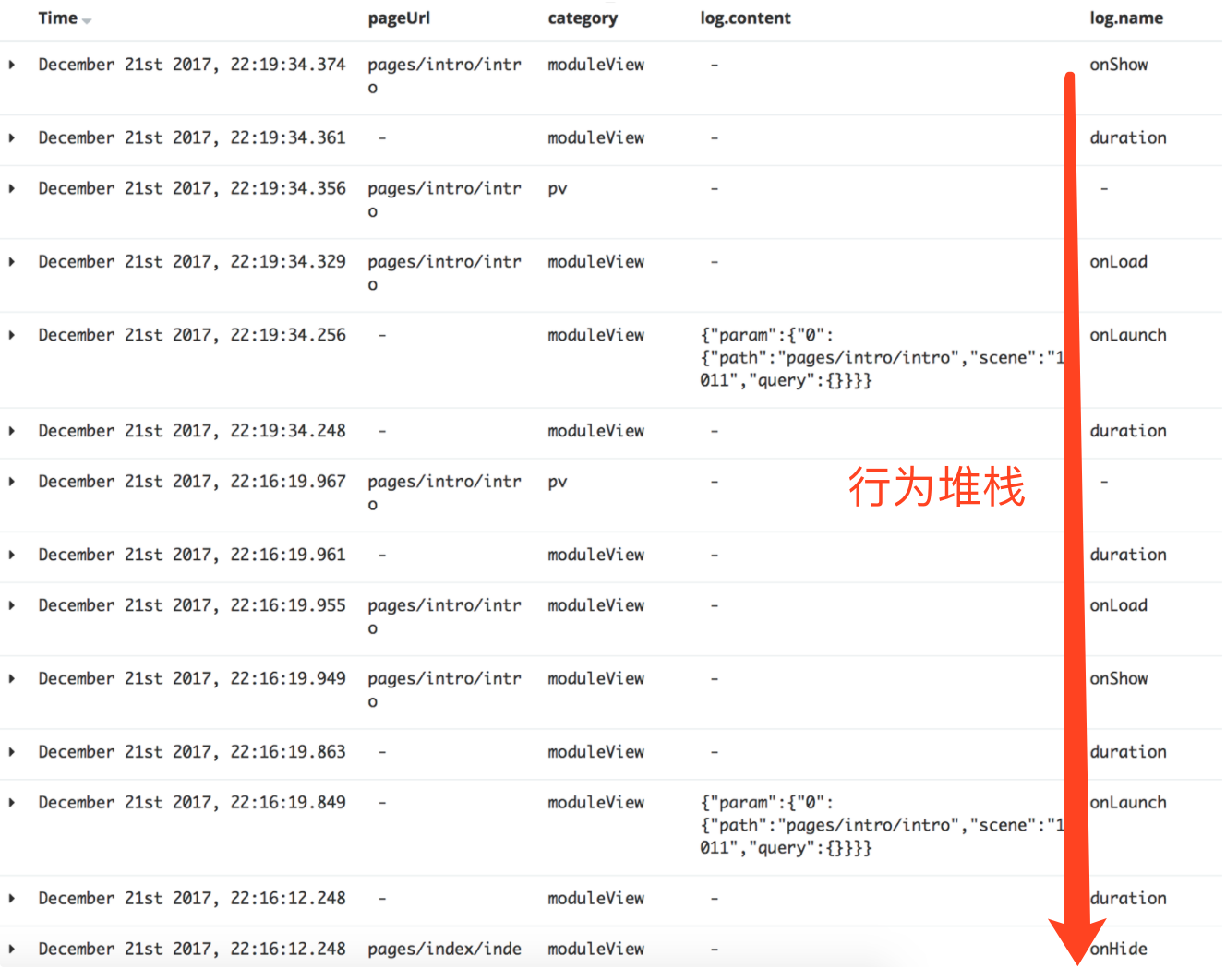
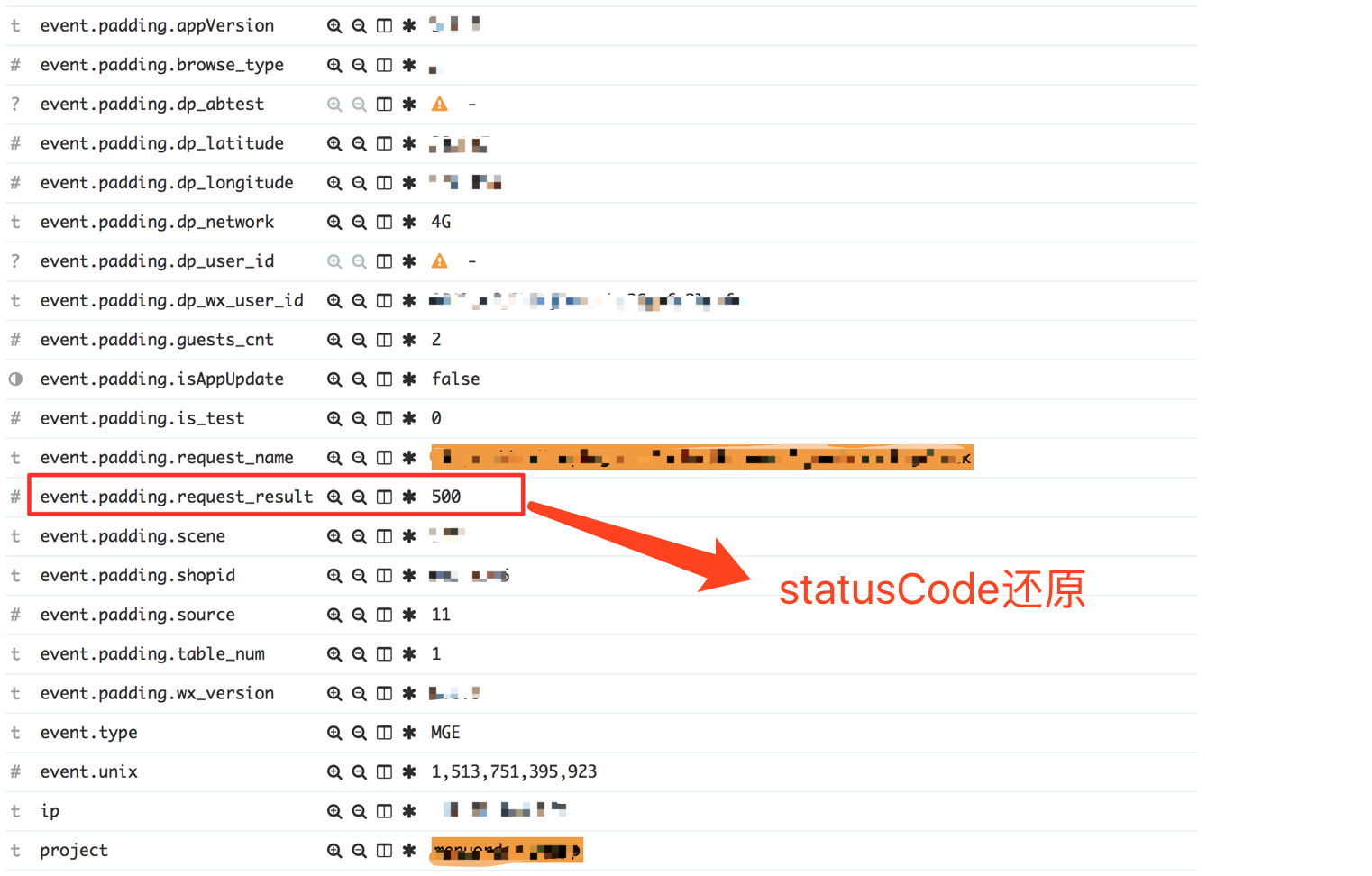
2. 对resource和ajax请求指标做采集,可以筛选出故障用户当时的场景信息:
3.告警采用动态阈值,对于周期性强的数据,通过机器学习的算法进行环比告警,大大降低了误报和漏报:
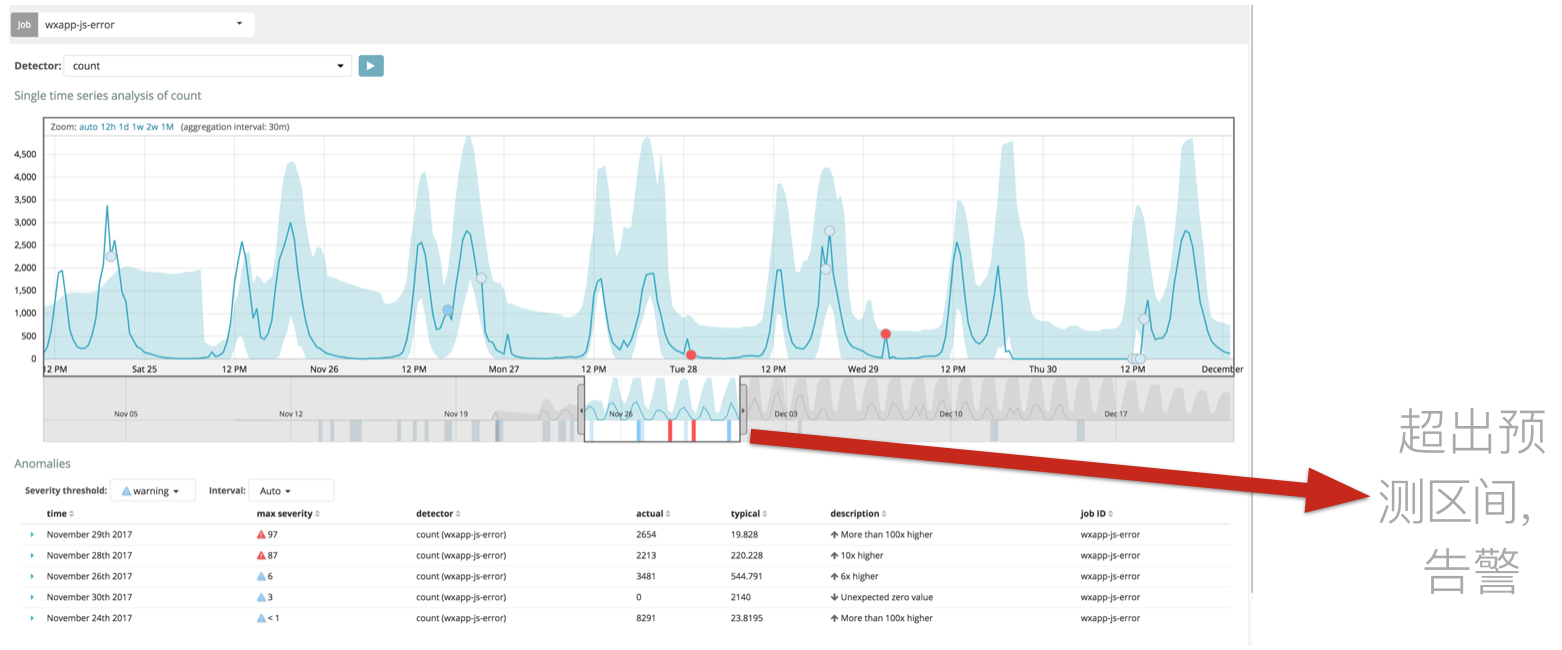
在做日志存储的时候,数据量是一个挑战,我们采用的是集群架构,但是一个用户量很大的站点,日志的上报量是非常高的,高峰期时,一个1万日活APP可能会突破3000的qps,这对日志系统并发能力和稳定性是很大的挑战。我们选择了全量master+data节点的方式,对数据副本分片设置为1,任意一台节点挂掉,会由副本选举出新的主分片,不会造成日志丢失。在写入方面,我们选择了bulk方式批量写入,通过反复试验,批量写入线程大小在5MB-15MB之间。由于日志系统是主要面对写入的,所以关闭了_all查询,写入性能优化1倍,同时gc新老分配为1:4,保证了批量写入的稳定。
总结与未来规划
通过对新监控解决方案的探索,我们积累了比较宝贵的数据分析经验,对于终端哪些数据对于故障处理,性能优化起到重要作用有了新的认识,不过目前系统仍处于迭代过程中,距离预定的目标还有比较大的优化空间。
在未来,我们将重点攻克以下几个问题:
减少上报量:合并数据结构,释放更多上行带
优化SDK性能:减少缓存写入频率,做到业务对监控模块无感
识别周高峰和节假日,同时增强数据清洗能力,提高数据的可用性
3.优化数据分析体验
开放埋点配置平台,让产品自主配置业务埋点,通过配置文件转化成埋点,省时高效。
