

之前突然发现自己对字符编码还是一知半解,基本上只是听说过各种编码的名字,对它们之间的特点和区别还是不甚了解。所以这段时间查阅了许多资料,对字符编码也大概有了一些整体的了解,写下这篇文章作为总结。
在Unicode之前
为了在计算机的中储存人类可以阅读的文本,必须按照一定的规范将字符映射为计算机可以储存的数值,在计算机发展的早期渐渐形成了统一的标准,在1967年ASCII编码首次作为规范标准发布。这是一套用来表示现代英文的编码约定,全称为美国信息交换标准代码。ASCII编码非常简单,只定义了128个字符,每个字符通过唯一的编号来表示,每个字符占用一个字节(8bit)的空间,因为只有128个字符(2的7次方),所以每个字符的第一位始终为0。
一个ASCII字符只有8位,最多只能表示256个字符,对于英文来说足够了,但是对于像中文这样的语言而言是远远不足的。所以在ASCII之上做了一些扩展,用两个字节来表示一个字符,这就是1981年发布的GB2312编码,为了与ASCII作区分,GB2312中每个字节的最高位都是1。这一套编码中包含了6000多个常用的简体汉字,基本满足日常使用的需求。但是不支持繁体汉字和一些生僻字,所以在后来又在GB2312上进行了扩展,这就是之后的GBK编码,全称为汉字内码扩展规范。
事实上在那个年代还有很多不同的汉字编码百花齐放,而且不止是中文,世界上其他各种语言都在指定自己的标准,不同编码之间无法相互兼容,这为互联网的推广带来了很大的麻烦,统一字符编码势在必行。
Unicode
Unicode是国际标准化组织制定的一套字符编码方案,致力于统一世界上所有语言字符的编码。Unicode为每个字符分配了一个固定的数值,称为编码点(Code Point),所有的编码点组成的集合称为编码空间(Code Space)。目前Unicode的编码空间共包含0x10FFFF(十进制的1114111)个编码点,被划分为17个平面,每个平面包含0xFFFF个字符。从1991年发布的第一个版本开始,每一年都会有新的字符被编入Unicode中,目前所定义的字符集只用了不到五分之一的编码空间。
编码方式
Unicode制定了一套字符集编码的标准,而在实际中如何去表示一个编码点呢,有几种不同编码方案:UTF-8、UTF-16和UTF-32,这几种方案各有特点。
UTF-32:
这是最简单的一种编码方式,定长编码。使用4个字节作为一个编码单元,也就是说每一个编码点都用4个字节来表示。
定长编码的一个好处就是每个字符的做占用的空间都是相同的,所以当我们想要获取第n个位置的字符时,直接在首字符的地址加上一个固定的偏移量就可以了,也就是说可以在O(1)的时间复杂度索引字符串的任意位置,这也是我们常说的随机索引。但是这样做的缺点也十分明显,每个字符占用32个bit,肯定会造成大量的空间浪费,出于这个原因UTF-32编码用得并不多。
UTF-16:
在介绍UTF-16之前,先讲讲UCS-2编码。在早期的Unicode标准中,只定义了不到65535(0xFFFF,2的16次方)个编码点,所有的字符都可以用两个字节的UTF-16编码来表示,所以在那个时候UTF-16还是一个定长编码,UCS-2就等同于UTF-16。然而设计师还是错误的估算了编码点的范围,16位的范围并不足以囊括世界上的所有文字,所以Unicode需要扩大最初的范围。在新的标准中编码空间被扩展到了0x10FFFF的大小,分成17块65535大小的板块,第一个板块包含了最初UCS-2中定义的65535个编码点,被称为基本多文种平面(BMP),余下新增的16个板块称为辅助平面。所以在今天来说,UTF-16可以看成UCS-2的父集。
随着标准的扩充,UTF-16也必须扩展以支持更多的编码点。在如今的UTF-16编码中使用了2个字节作为一个编码单元,一个编码点需要2个或4个字节来表示。
为了能正确表示辅助平面中的编码点,UTF-16对编码点的前缀做了一些约束,引入了一个称为代理编码点(surrogate)的概念。也就是在Unicode的编码空间中划分出了一块保留区域,落在在这个区域中的编码点就是代理编码点,这块区域包含从前缀110110到前缀110111的所有编码点,也就是从1101100000000000到1101111111111111的范围,十六进制为0xD800到0xDFFF。这个区域中的编码点只能成对出现在UTF-16编码中,出现在UTF-32和UTF-8中都是非法的。
UTF-16在编码的时候遵循以下规则:
| 字节数 | UTF-16二进制表示 | 编码点 | 编码范围 |
|---|---|---|---|
| 2 | xxxxxxxxyyyyyyyy | xxxxxxxxxxxxxxxx | 0 ~ 0xFFFF |
| 4 | 110110xxxxxxxxxx + 110111yyyyyyyyyy | xxxxxxxxxxyyyyyyyyyy + 0x10000 | 0x10000 ~ 0x10FFFF |
当编码点在0到0xFFFF的范围内时,这两个字节中的所有bit都可用来表示编码点;而当编码点大于0xFFFF,就必须要使用两个代理编码点了,分别取前后两个字节中低位的10个bit,这样就有了20bit的编码空间,最大能表示0x100000的值,再加上0xFFFF,正好就是0x10FFFF,Unicode中定义的最大编码空间。
UTF-8:
UTF-8使用单个字节作为编码单元,这是一种变长编码,根据需要使用1个到4个字节来表示一个编码点。在这种编码模式中,一个字节可能是表示一个单字节的字符,也可能是多字节字符中的一部分,在解析的时候必须要能够区分出来。所以在UTF-8中每个字节最高的几个bit不用来储存编码值,而是用来表示该字节在其所表示的字符中的位置:
| 字节数 | UTF-8二进制表示 | 编码点 | 编码范围 |
|---|---|---|---|
| 1 | 0xxxxxxx | xxxxxxx (7bit) | 0 ~ 0x7F |
| 2 | 110xxxxx + 10yyyyyy | yyyyyzzzzzz (11bit) | 0x80 ~ 0x7FF |
| 3 | 1110xxxx + 10yyyyyy + 10zzzzzz | xxxxyyyyyyzzzzzz (16bit) | 0x800 ~ 0xD7FF + 0xE000 ~ 0xFFFF |
| 4 | 11110xxx + 10yyyyyy + 10zzzzzz + 10wwwwww | xxxyyyyyyzzzzzzwwwwww (21bit) | 0x10000 ~ 0x10FFFF |
3个字节的情况下有两个编码范围,这是因为上一节中提到的代理编码点不能表示任何字符
简单来说UTF-8的编码规则只有两条:
- 单字节字符的最高位为0,后7位为该字符的编码值。
- n个字节的符号(n > 1),第一个字节的最高n位都为1,n + 1位为0,剩余的字节的最高位都为10。
可以看到,单字节的UTF-8编码最高位作为标志位始终为0,在上面提到的ASCII编码中最高位没有用上也始终为0。也就是说前128个字符的编码方式与ASCII是完全相同的,这样一来UTF-8就能够完全兼容ASCII,用ASCII编码的文件无需任何转换就可以直接被UTF-8所识别。
对空间的高效利用,以及对ASCII兼容性,使得UTF-8成为了最主流的编码方式。
字节序
说到字节序的问题必须先谈一谈大端和小端,在计算机的世界中多字节的数据会按照其字节顺序被储存,而字节之间的排列方式有两种:大端模式(Big-Endian)和小端模式(Big-Endian):
- 大端模式:低位字节排放在内存中的高位地址,高位字节排放在内存中的低位地址。
- 小端模式:低位字节排放在内存中的低位地址,高位字节排放在内存中的高位地址。
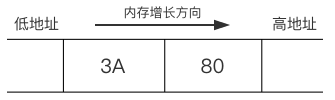
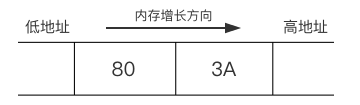
比如说有一个short类型的数据0x3A80,需要占用2个字节的空间,其中高位字节为3A,低位字节为80。
使用大端模式储存时内存的排列方式如下,内存中的高地址方向存放的是低位字节80:
使用小端模式存储时内存中的排列方式如下,内存中高地址方向存放的是高位字节3A:
再回到Unicode中,由于UTF-16使用了两个字节作为一个编码单元,在解析的时候每次需要读取两个字节,所以字节序就变得尤为重要。例如汉字呀的编码点为0x5440,如果以错误的字节序来读取的话,则会将其识别为0x4054,这样一来就变成了汉字䁔。
为了保证字符串始终能以正确的字节序来读取,标准建议UTF-16文件在起始的位置加上0xFEFF,称为字节顺序标记(BOM)。因为在读取文件是按照低地址到高地址的顺序,所以如果读取到0xFEFF则说明该文件是采用大端模式来储存的;如果读取到0xFFFE则说明文件是采用小端模式来存储的。
如果使用的是UTF-8编码则不需要关心这个问题,因为UTF-8的编码单元只有一个字节,每次只需要读取一个字节即可,所以不存在字节顺序的问题。
组合字符
Unicode的复杂性不仅体现在其编码方式上,在Unicode中有一些字符存在多种不同的表示方式。这是什么意思呢?有一些文字会带有音调符号,比如一个带有音标的符号ǎ,它可以直接通过编码点0x01CE来表示,也可以使用一个a(编码点为0x0061)和一个̌(编码点为0x030C)组合起来表示,虽然说编码看起来不一样,但是这两种写法在语义上和视觉上都是相同的。这样就引入了一个新的概念,我们称ǎ字符和a、̌组成的序列是标准等价的。
这样麻烦就来了,当用两种写法来表示同一个字符的时候,计算机根据字节比较会认为它们是不同的。为了能正确判断字符串之间的等价性,Unicode规定了一套标准的正规化算法(有四种正规化的形式,就不再展开介绍了),也就是将所有标准等价的字符转换成统一的表示形式:
let c1 = '\u{01CE}'; // ǎ
let c2 = '\u{0061}\u{030C}'; // ǎ
c1.normalize(); // 01CE
c1.normalize(); // 01CE
在上面的这一段JavaScript代码中,ǎ的两种写法在经过正规化之后都被转换成了相同编码01CE,这样一来就能正确的进行相等性比较了。
到了Emoji这边情况就变得更加复杂了,很多Emoji表情是用多个Unicode码点来表示的,比如说❤️是由一个心型字符 ❤(0x2764)和一个样式控制符号(0xFE0F)组合而成。此外Emoji还支持使用零宽度连接符(ZWJ,码点为0x200D)将多个Emoji字符组合新的字符。也就是将0x200D字符放在两个Emoji字符的中间,这两个Emoji会被连接起来组成新的Emoji字符。比如说👩和👦可以组合成👩👦(\u{1f469}\u{200d}\u{1f466}),像👨👩👧👧这种Emoji更是由7个Unicode字符组合成的复杂字符。
从上面的这些例子中可以看出,在Unicode中语义上的单个字符实际上可能是由许多个字符组合而成的,为了更好的描述这种场景,Unicode中引入了一个称为字位簇(grapheme cluster)的概念。字位簇用来表示一个语义上的字符,不论是单个字符还是包含多个字符序列的组合字符,都视为一个字位簇。
实际应用
在了解了Unicode的各种特性之后再来看看不同语言中对于字符编码的处理吧,下面对比了一下个人平常使用的语言中字符编码的异同:
JavaScript
在JavaScript刚刚发布的那个年代,还是UCS-2的天下,所以JavaScript内部字符串的编码方式采用了UTF-16,准确的说是UTF-16的子集UCS-2。
这一历史问题为今天的JavaScript带来了一些困扰,因为所有的字符在JavaScript中都被视为两个字节的编码,如果字符串中包含辅助平面的编码点时,JavaScript会将其视为2个2字节的字符来处理。这个问题影响了JavaScript中的字符处理函数:
let c = '𠀗'; // 0x20017
c.length; // 2
c.charCodeAt(0).toString(16); // 0xD840
c.charCodeAt(1).toString(16); // 0xDC17
上面代码中汉字"𠀗"的Unicode编码点是0x20017,大小超过了0xFFFF,位于辅助平面中,所以在UTF-16中需要4个字节,编码为0xD840DC17。调用length的输出是2,说明JavaScript将其识别成了两个字符。charCodeAt是一个用来打印指定位置字符编码值的方法,将结果转换成16进制后可以看到分别输出了两个编码单元的值d840和dc17。想必前端的同学一定对这些多字节字符处理上的坑深恶痛绝。
不过好消息是ES6以来这些坑也在陆续填上了:新增的codePointAt方法能正确识别4字节的UTF-16字符、新的Unicode字符表示方法\u{20017}、新增for…of循环也能正确的遍历4字节字符...
let c = '𠀗';
Array.from(c).length; // 1
c.codePointAt(0) // 20017
Objective-C
OC中对字符串的处理与JavaScript类似,内部的字符串编码同样采用了UCS-2,上面的那个例子在OC中会获得同样的结果:
NSString *s = @"𠀗"; // 0x20017
s.length; // 2
[s characterAtIndex:0]; // 0xD840
[s characterAtIndex:1]; // 0xDC17
想要获得正确的字符数可以先将字符串转换成定长的UTF-32编码,然后再除以4:
[@"𠀗" lengthOfBytesUsingEncoding:NSUTF32StringEncoding] / 4; // 1
这样子可以正确的识别出Unicode码点的个数,然而对于组合字符还是无能为力。
这个问题同样会影响到比较字符串时常用的isEqualToString方法:
NSString *s1 = @"a\u030C"; // ǎ
NSString *s2 = @"\u01CE"; // ǎ
[s1 isEqualToString:s2]; // NO
若要对字符串进行标准等价比较,必须使用compare方法,或者先使用precomposedStringWithCanonicalMapping方法将字符串正规化:
[s1 compare:s2] == NSOrderedSame; // YES
[s1 precomposedStringWithCanonicalMapping];
Swift
String
Swift在字符串编码上做了很多事情,Swift用String类型来表示字符串,不同的是在遍历字符串的时候有很多种选择,可以按照字符来遍历,也可以按照UTF-8或UTF-16编码来遍历:
let s = "\u{0061}\u{030C}" // ǎ
for var c in s {...} // ǎ
for var c in s.utf8 {...} // 0x61、0xCC、0x8C
for var c in s.utf16 {...} // 0x0061、0x030C
在上面的代码中s是直接以Unicode标量来初始化的,而s.utf8会将其转换成UTF-8的编码方式,随后遍历每一个编码单元,UTF-16也与之类似。字符串对象中utf8和utf16这两个属性的类型分别是String.UTF8View和String.UTF16View,它们都是一个集合类型,实现了BidirectionalCollection协议,之所以没实现RandomAccessCollection是因为UTF-8和UTF-16都是变长编码,没办法做到随机索引。
String类型重载了==符号,而且在比较的时候会自动将字符串正规化后再进行比较:
let s1 = "\u{0061}\u{030C}" // ǎ
let s2 = "\u{01CE}" // ǎ
s1 == s2 // true
在这一点上
Character
一个字符串是多个字符组成的序列,Swift中表示单个字符的类型是Character。Character表示的是一个Unicode的字位簇,也就是说一个Character中可以包含多个Unicode编码点:
let s = "👨👩👧👧abc"
s.first // 👨👩👧👧
可以看到像上面这种带组合字符的情况在Character中能够被正确的处理,s.first获取到的第一个字符是👨👩👧👧(而不是👨)。
Character中提供了unicodeScalars属性用来访问字位簇中的每一个Unicode编码点,每个编码点通过Unicode.Scalar类型来表示:
let c = "👨👩👧👧"
c.unicodeScalars.count // 7
c.unicodeScalars.first?.value // 0x1F468 (Unicode编码点)
c.unicodeScalars.first?.utf16 // 0xD83D、0xDC68
参考资料
http://blog.csdn.net/zhuxipan1990/article/details/51602299
http://blog.jobbole.com/111261/
https://zh.wikipedia.org/wiki/UTF-16
https://zh.wikipedia.org/wiki/UTF-8
https://objccn.io/issue-9-1/
