

DNS解析的作用是把域名解析成相应的IP地址,因为在广域网上路由器需要知道IP地址才知道把报文发给谁。DNS是Domain Name System域名系统的缩写,它是一个协议,在RFC 1035具体描述了这个协议。具体过程如下图所示:
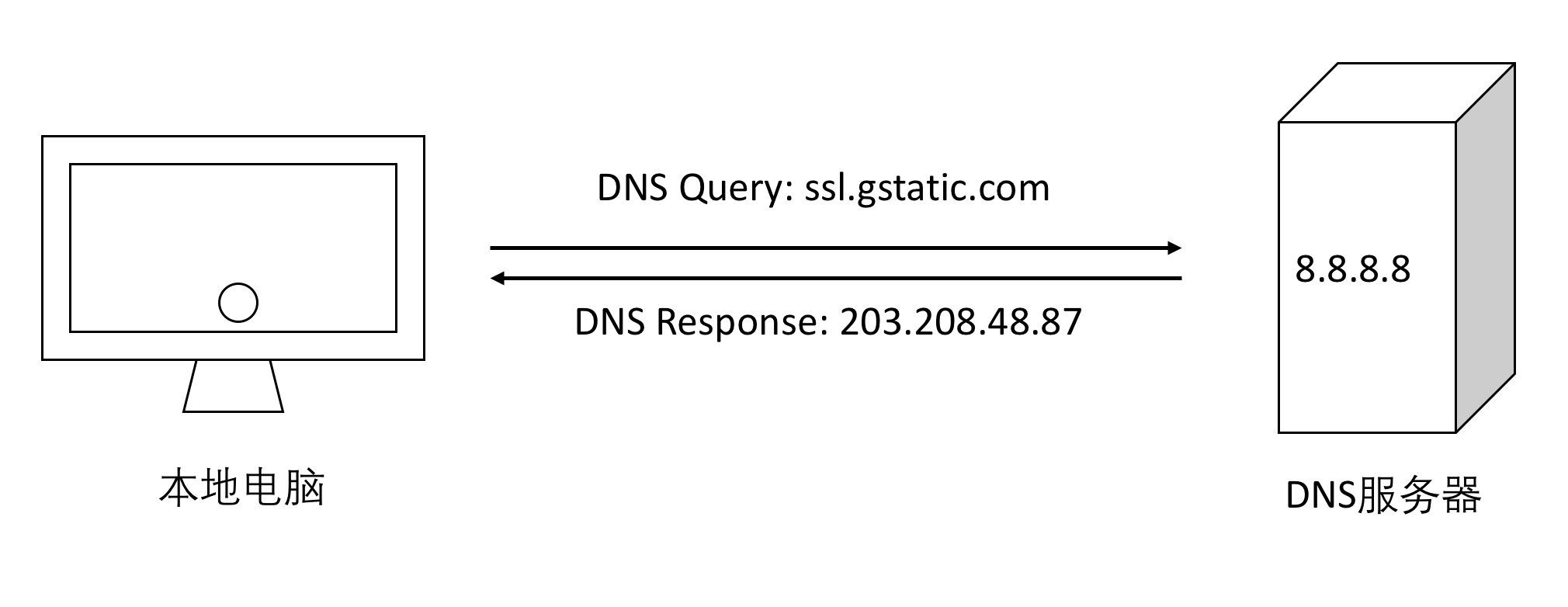
这个过程看似简单,但是有几个问题:
(1)浏览器是怎么知道DNS解析服务器,如上图的8.8.8.8这台?
(2)一个域名可以解析成多个IP地址吗,如果只有一个IP地址,在并发量很大的情况下,那台服务器可能会爆?
(3)把域名绑了host之后,是不是就不用域名解析了直接用的本地host指定的IP地址?
(4)域名解析的有效时间为多长,即过了多久后同一个域名需要再次进行解析?
(5)什么是域名解析的A记录、AAAA记录、CNAME记录?
其实域名解析和Chrome没有直接关系,即使是最简单的curl命令也需要进行域名解析,但是我们可以通过Chrome源码来看一下这个过程是怎么样的,并且回答上面的问题。
首先第一个问题,浏览器是怎么知道DNS解析服务器的,在本机的网络设置里面可以看到当前的DNS服务器IP,如我电脑的:
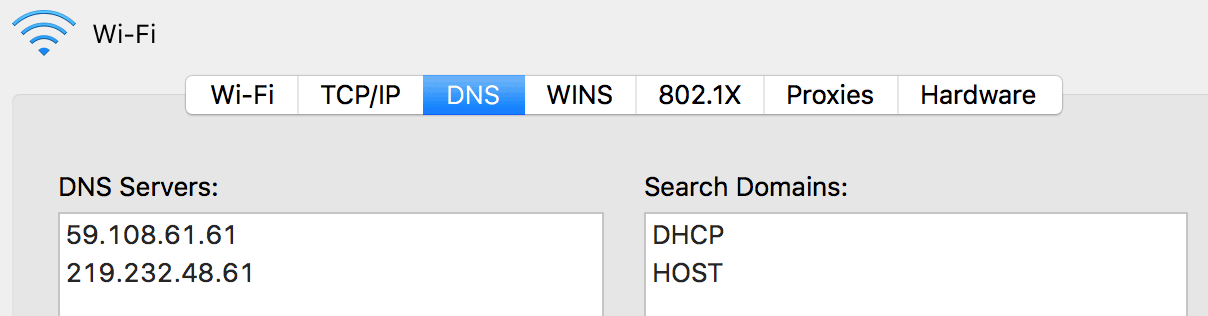
这两个DNS Server是我家接的某正宽带提供的:
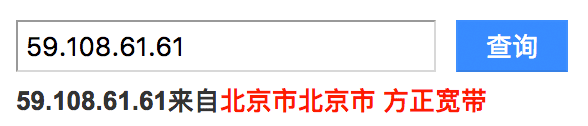
一般宽带服务商都会提供DNS服务器,谷歌还为公众提供了两个免费的DNS服务,分别为8.8.8.8和8.8.4.4,取这两个IP地址是为了容易记住,当你的DNS服务不好用的时候,可以尝试改成这两个。
入网的设备是怎么获取到这些IP地址的呢?是通过动态主机配置协议(DHCP),当一台设备连到路由器之后,路由器通过DHCP给它分配一个IP地址,并告诉它DNS服务器,如下路由器的DHCP设置:

通过wireshark抓包可以观察到这个过程:
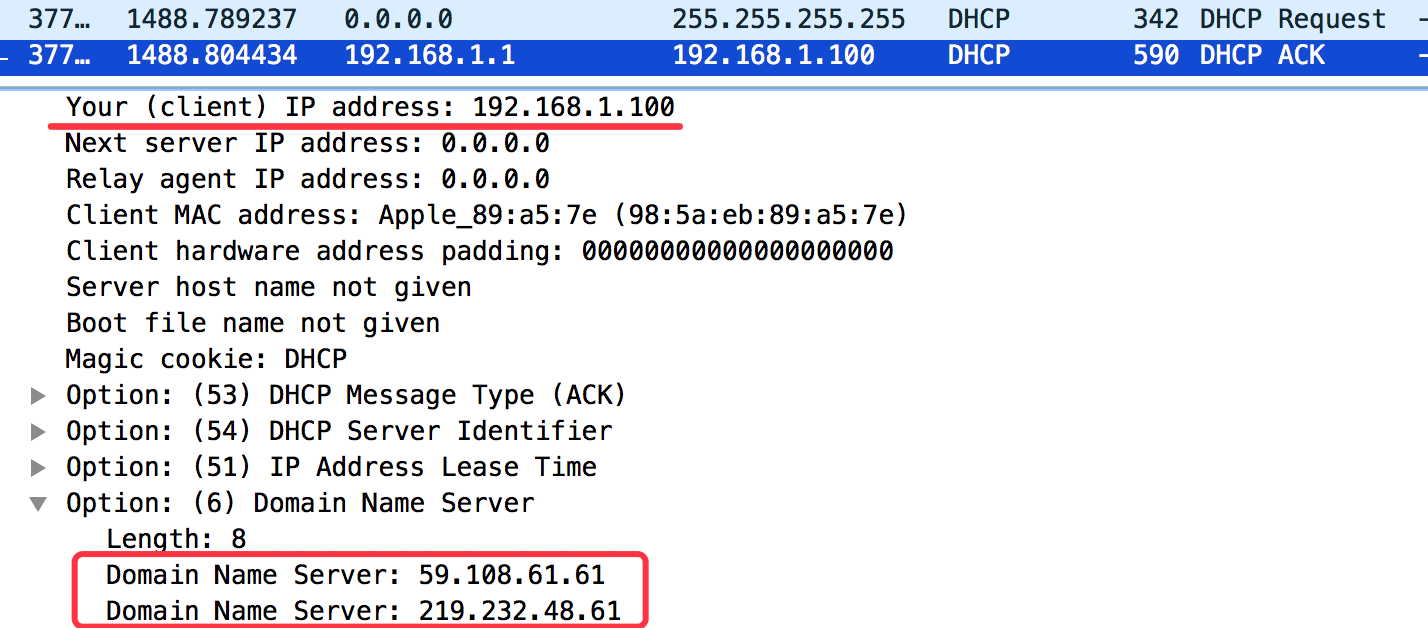
当我的电脑连上wifi的时候,会发一个DHCP Request的广播,路由器收到这个广播后就会向我的电脑分配一个IP地址并告知DNS服务器。
这个时候系统就有DNS服务器了,Chrome是调res_ninit这个系统函数(Linux)去获取系统的DNS服务器,这个函数是通过读取/etc/resolver.conf这个文件获取DNS:
#
# Mac OS X Notice
#
# This file is not used by the host name and address resolution
# or the DNS query routing mechanisms used by most processes on
# this Mac OS X system.
#
# This file is automatically generated.
#
search DHCP HOST
nameserver 59.108.61.61
nameserver 219.232.48.61search选项的作用是当一个域名不可解析时,就会尝试在后面添加相应的后缀,如ping hello,无法解析就会分别ping hello.DHCP/hello.HOST,结果最后都无法解析。
Chrome在启动的时候根据不同的操作系统去获取DNS服务器配置,然后把它放到DNSConfig的nameservers:
// List of name server addresses.
std::vector<IPEndPoint> nameservers;Chrome还会监听网络变化同步改变配置。
然后用这个nameservers列表去初始化一个socket pool即套接字池,套接字是用来发请求的。在需要做域名解析的时候会从套接字池里面取出一个socket,并传递想要用的server_index,初始化的时候是0,即取第一个DNS服务IP地址,一旦解析请求两次都失败了,则server_index + 1使用下一个DNS服务。
unsigned server_index =
(first_server_index_ + attempt_number) % config.nameservers.size();
// Skip over known failed servers.
// 最大attempts数为2,在构造DnsConfig设定的
server_index = session_->NextGoodServerIndex(server_index);如果所有的nameserver都失败了,那么它会取最早失败的nameserver.
Chrome在启动的时候除了会读取DNS server之外,还会去取读取和解析hosts文件,放到DNSConfig的hosts属性里面,它是一个哈希map:
// Parsed results of a Hosts file.
//
// Although Hosts files map IP address to a list of domain names, for name
// resolution the desired mapping direction is: domain name to IP address.
// When parsing Hosts, we apply the "first hit" rule as Windows and glibc do.
// With a Hosts file of:
// 300.300.300.300 localhost # bad ip
// 127.0.0.1 localhost
// 10.0.0.1 localhost
// The expected resolution of localhost is 127.0.0.1.
using DnsHosts = std::unordered_map<DnsHostsKey, IPAddress, DnsHostsKeyHash>;hosts文件在linux系统上是在/etc/hosts:
const base::FilePath::CharType kFilePathHosts[] =
FILE_PATH_LITERAL("/etc/hosts");读取这个文件没有什么技巧,需要一行行地去处理,并做一些非法情况的判断,如上面代码的注释。
这样DNSConfig里面就有两个配置了,一个是hosts,另一个是nameservers,DNSConfig是组合到DNSSession,它们的组合关系如下图所示:
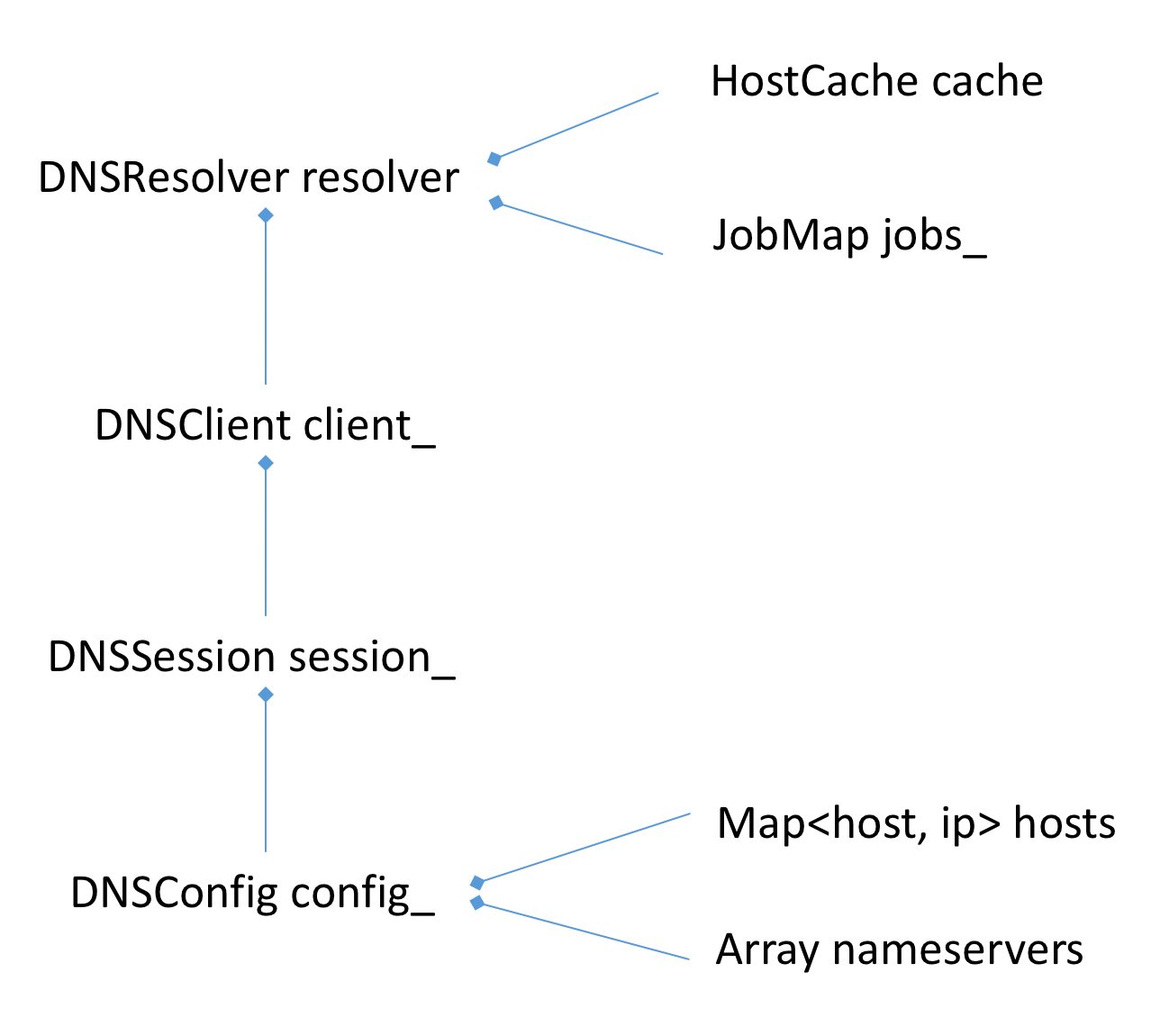
resolver是负责解析的驱动类,它组合了一个client,client创建一个session,session层有一个很大的作用是用来管理server_index和socket pool如分配socket等,session初始化config,config用来读取本地绑的hosts和nameservers两个配置。这几层各有各的职责。
resolver有一个重要的功能,它组合了一个job,用来创建任务队列。resolver还组合了一个Hostcache,它是放解析结果的缓存,如果缓存缓存命中的话,就不用去解析了,这个过程是这样的,外部调rosolver提供的HostResolverImpl::Resolve接口,这个接口会先判断在本地是否能处理:
int net_error = ERR_UNEXPECTED;
if (ServeFromCache(*key, info, &net_error, addresses, allow_stale,
stale_info)) {
source_net_log.AddEvent(NetLogEventType::HOST_RESOLVER_IMPL_CACHE_HIT,
addresses->CreateNetLogCallback());
// |ServeFromCache()| will set |*stale_info| as needed.
return net_error;
}
// TODO(szym): Do not do this if nsswitch.conf instructs not to.
// http://crbug.com/117655
if (ServeFromHosts(*key, info, addresses)) {
source_net_log.AddEvent(NetLogEventType::HOST_RESOLVER_IMPL_HOSTS_HIT,
addresses->CreateNetLogCallback());
MakeNotStale(stale_info);
return OK;
}
return ERR_DNS_CACHE_MISS;上面代码先调serveFromCache去cache里面看有没有,如果cache命中的话则返回,否则看hosts是否命中,如果都不命中则返回CACHE_MISS的标志位。如果返回值不等于CACHE_MISS,则直接返回:
if (rv != ERR_DNS_CACHE_MISS) {
LogFinishRequest(source_net_log, info, rv);
RecordTotalTime(info.is_speculative(), true, base::TimeDelta());
return rv;
}否则创建一个job,并看是否能立刻执行,如果job队列太多了,则添加到job队列后面,并传递一个成功的回调处理函数。
所以这里和我们的认知基本上是一样的,先看下cache有没有,然后再看hosts有没有,如果没有的话再进行查询。在cache查询的时候如果这个cache已经过时了即staled,也会返回null,而判断是否stale的标准如下:
bool is_stale() const {
return network_changes > 0 || expired_by >= base::TimeDelta();
}即网络发生了变化,或者expired_by大于0,则认为是过时的cache。这个时间差是用当前时间减掉当前cache的过期时间:
stale.expired_by = now - expires_;而过期时间是在初始化的时候使用now + ttl的值,而这个ttl是使用上一次请求解析的时候返回的ttl:
uint32_t ttl_sec = std::numeric_limits<uint32_t>::max();
ttl_sec = std::min(ttl_sec, record.ttl);
*ttl = base::TimeDelta::FromSeconds(ttl_sec);上面代码做了一个防溢出处理。在wireshark的dns response可以直观地看到这个ttl:
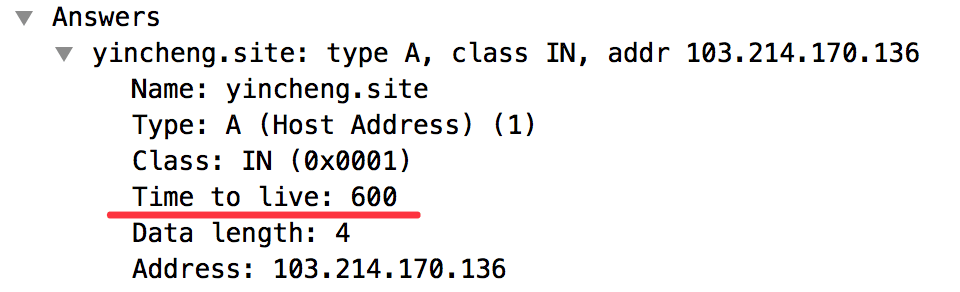
当前域名的TTL值为600s即10分钟。这个可以在买域名的提供商进行设置:

另外可以看到这个记录类型是A的,什么是A呢,如下图所示:
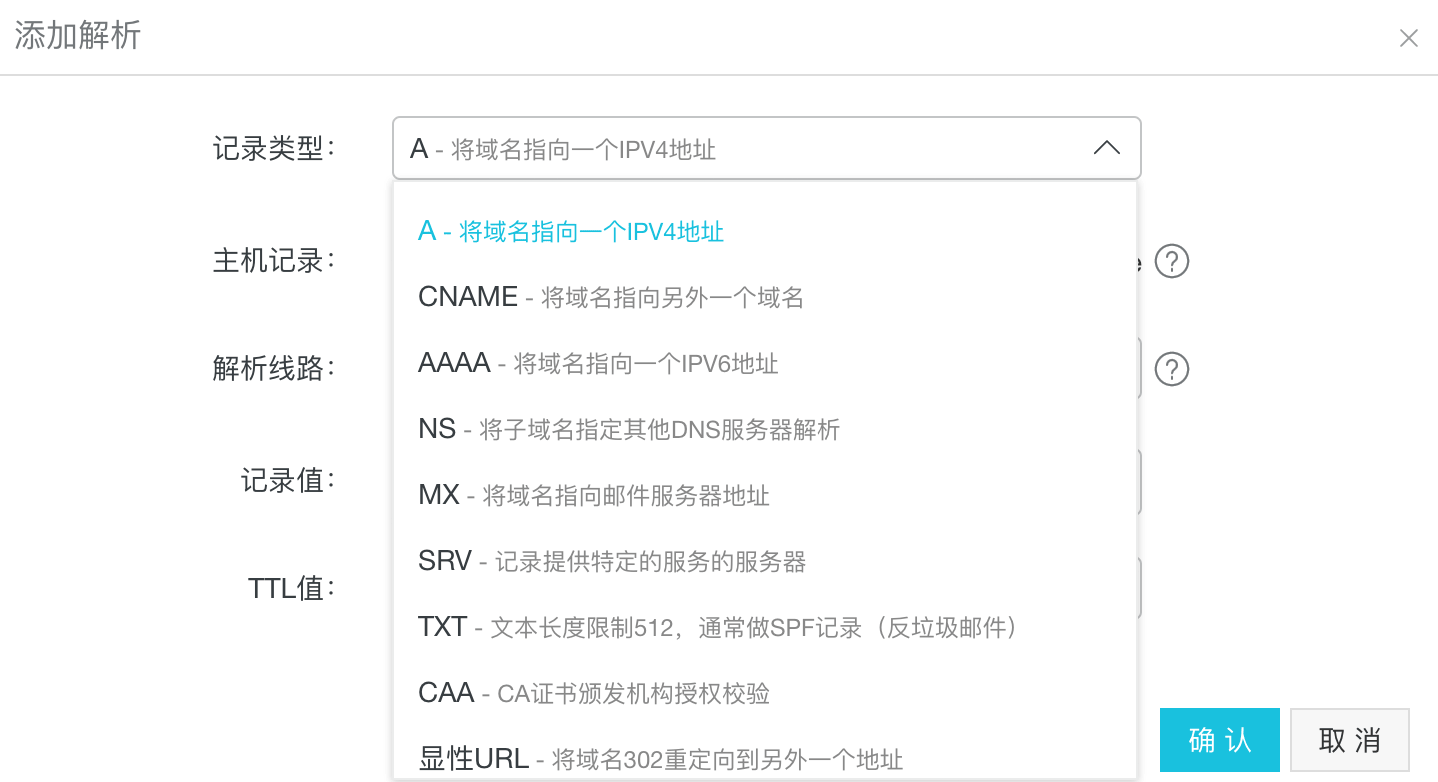
在添加解析的时候可以看到,A就是把域名解析到一个IPv4地址,而AAAA是解析到IPv6地址,CNAME是解析到另外一个域名。使用CNAME的好处是当很多其它域名指向一个CNAME时,当需要改变IP地址时,只要改变这个CNAME的地址,那么其它的也跟着生效了,但是得做二次解析。
如果域名在本地不能解析的话,Chrome就会去发请求了。操作系统提供了一个叫getaddrinfo的系统函数用来做域名解析,但是Chrome并没有使用,而是自己实现了一个DNS客户端,包括封装DNS request报文以及解析DNS response报文。这样可能是因为灵活度会更大一点,例如Chrome可以自行决定怎么用nameservers,顺序以及失败尝试的次数等。
在resolver的startJob里面启动解析。取到下一个queryId,然后构建一个query,再构建一个DnsUDPAttempt,再执行它的start,因为DNS客户端查询使用的是UDP报文(辅域名服务器向主域名服务器查询是用的TCP):
uint16_t id = session_->NextQueryId();
std::unique_ptr<DnsQuery> query;
query.reset(new DnsQuery(id, qnames_.front(), qtype_, opt_rdata_));
DnsUDPAttempt* attempt =
new DnsUDPAttempt(server_index, std::move(lease), std::move(query));
int rv = attempt->Start(
base::Bind(&DnsTransactionImpl::OnUdpAttemptComplete,
base::Unretained(this), attempt_number,
base::TimeTicks::Now()));具体解析的过程拆成了几步,这个代码组织是这样的,通过一个state决定执行顺序:
int rv = result;
do {
// 最开始的state为STATE_SEND_QUERY
State state = next_state_;
next_state_ = STATE_NONE;
switch (state) {
case STATE_SEND_QUERY:
rv = DoSendQuery();
break;
case STATE_SEND_QUERY_COMPLETE:
rv = DoSendQueryComplete(rv);
break;
case STATE_READ_RESPONSE:
rv = DoReadResponse();
break;
case STATE_READ_RESPONSE_COMPLETE:
rv = DoReadResponseComplete(rv);
break;
default:
NOTREACHED();
break;
}
} while (rv != ERR_IO_PENDING && next_state_ != STATE_NONE);state从第一个case执行完之后变成第二个case的state,在第二个case的执行函数里面又把它改成第三个,这样依次下来,直到变成while循环里面的STATE_DONE,或者是ERR状态结束当前transaction事务。所以这个代码组织还是比较有趣的。
最后解析成功之后,会把结果放到cache里面:
if (did_complete) {
resolver_->CacheResult(key_, entry, ttl);
RecordJobHistograms(entry.error());
}然后生成一个addressList,传递给相应的callback,因为DNS解析可能会返回多个结果,如下面这个:
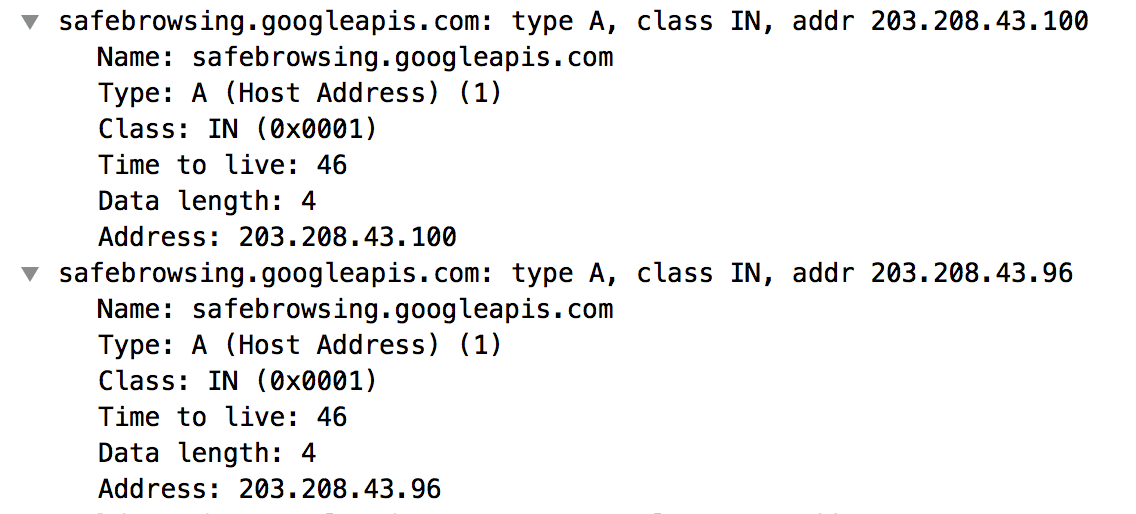
这里我们没用Chrome打印结果了,都是直接看的wireshark的输出,因为添加打印函数比较麻烦,直接看wireshark的输出比较直观,节省时间。
本文简单地介绍了DNS解析的过程以及DNS的一些相关概念,相信到这里,应该可以回答上面提出的几个问题了。总地来说,客户端向域名解析服务器发起查询,然后服务器返回响应。DNS服务器nameservers是在设备接入网络的时候路由器通过DHCP发给设备的,chrome会按照nameservers的顺序发起查询,并将结果缓存,有效时间根据ttl,有效期内两次查询直接使用cache。DNS解析的结果有几种类型,最常见的是A记录和CNAME记录,A记录表示结果是一个IP地址,CNAME表示结果是另外一个域名。
本文没有很深入详细地介绍,但是核心的概念和逻辑过程应该是都有涉及了。
