

前言:本文的目的是打算深入浅出讲讲以太坊的整体结构以及存储相关的内容,会聚焦在存储上,同时会结合源码讲解,整个过程也可以体会到作者的设计思想之精妙。
一,区块
block是最重要的数据结构之一,主要由header和body两部分组成
1, block源码(部分重要字段)
type Block struct {
header *Header //区块头
uncles []*Header //叔节点
transactions Transactions //交易数组
hash atomic.Value
size atomic.Value
td *big.Int //所有区块Difficulty之和
ReceivedAt time.Time
ReceivedFrom interface{}
}
1.1,header
type Header struct {
ParentHash common.Hash //指向父区块的指针
UncleHash common.Hash //block中叔块数组的RLP哈希值
Coinbase common.Address //挖出该区块的人的地址
Root common.Hash //StateDB中的stat trie的根节点的RLP哈希值
TxHash common.Hash //tx trie的根节点的哈希值
ReceiptHash common.Hash //receipt trie的根节点的哈希值
Bloom Bloom //布隆过滤器,用来判断Log对象是否存在
Difficulty *big.Int //难度系数
Number *big.Int //区块序号
GasLimit uint64 //区块内所有Gas消耗的理论上限
GasUsed uint64 //区块内消耗的总Gas
Time *big.Int //区块应该被创建的时间
Nonce BlockNonce //挖矿必须的值
}
1.2,body
type Body struct {
Transactions []*Transaction //交易的数组
Uncles []*Header
}
二,MPT树
看源码总是最好的方式,我们先看看trie的结构体的字段
1,Trie
type Trie struct {
root node //根节点
db Database //数据库相关,在下面再仔细介绍
originalRoot common.Hash //初次创建trie时候需要用到
cachegen, cachelimit uint16 //cache次数的计数器,每次Trie的变动提交后自增
}
从上面我们可以看到节点类型是node,那么接下来看看node的各个实现类
2,node的各个实现类
type (
fullNode struct {
Children [17]node
flags nodeFlag
}
shortNode struct {
Key []byte
Val node
flags nodeFlag
}
hashNode []byte
valueNode []byte
)
(1) fullNode
可以拥有多个子节点,长度为17的node数组,前16位对应16进制,子节点根据key的第一位,插入到相应的位置。第17位,还不清除具体作用是什么。
(2) shortNode
仅有一个子节点的节点。它的成员变量Val指向一个子节点
(3) valueNode
叶子节点,携带数据部分的RLP哈希值,数据的RLP编码值作为valueNode的匹配项存储在数据库里
(4) hashNode
是fullNode或者shortNode对象的RLP哈希值,以nodeFlag结构体的成员(nodeFlag.hash)的形式,被fullNode和shortNode间接持有
3,对key进行编码
接下来看看在MPT树中,是如何对key进行编码的,在encoding.go中,我们可以看到,有三种编码方式
(1) KEYBYTES:
就是真正的key(一个[]byte),没什么特殊的含义
(2) HEX:
先看一幅图,结合图来说明:
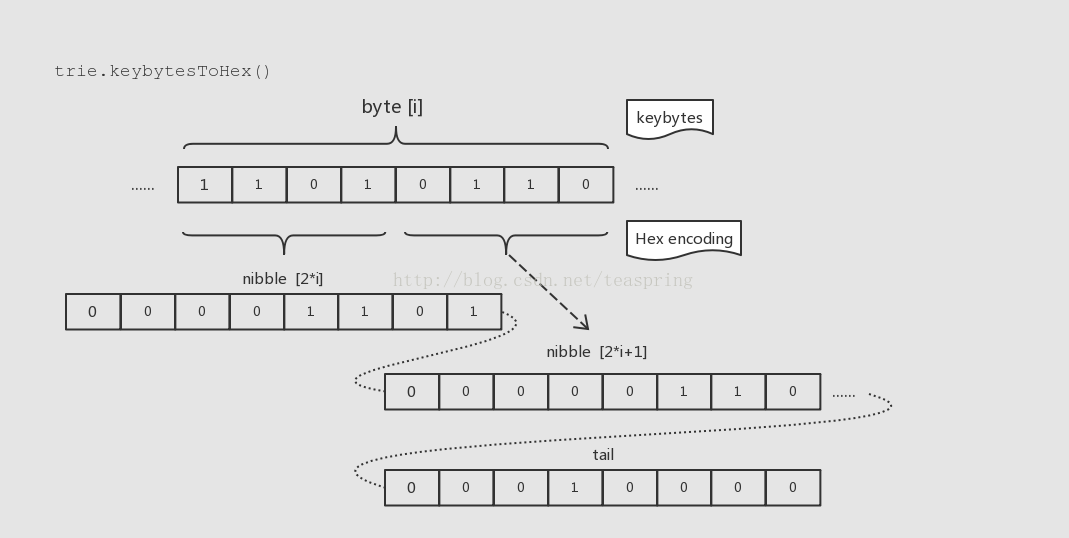
将一个byte的高4位和低4位分别存到两个byte中(每4位即一个nibble),然后在尾部加上一个标记来标识这是属于HEX编码方式。通过这种方式,每个byte都可以表示为一个16进制,从而加入到上面提到的fullNode的children数组中
(3) COMPACT:
同样,看一个图:
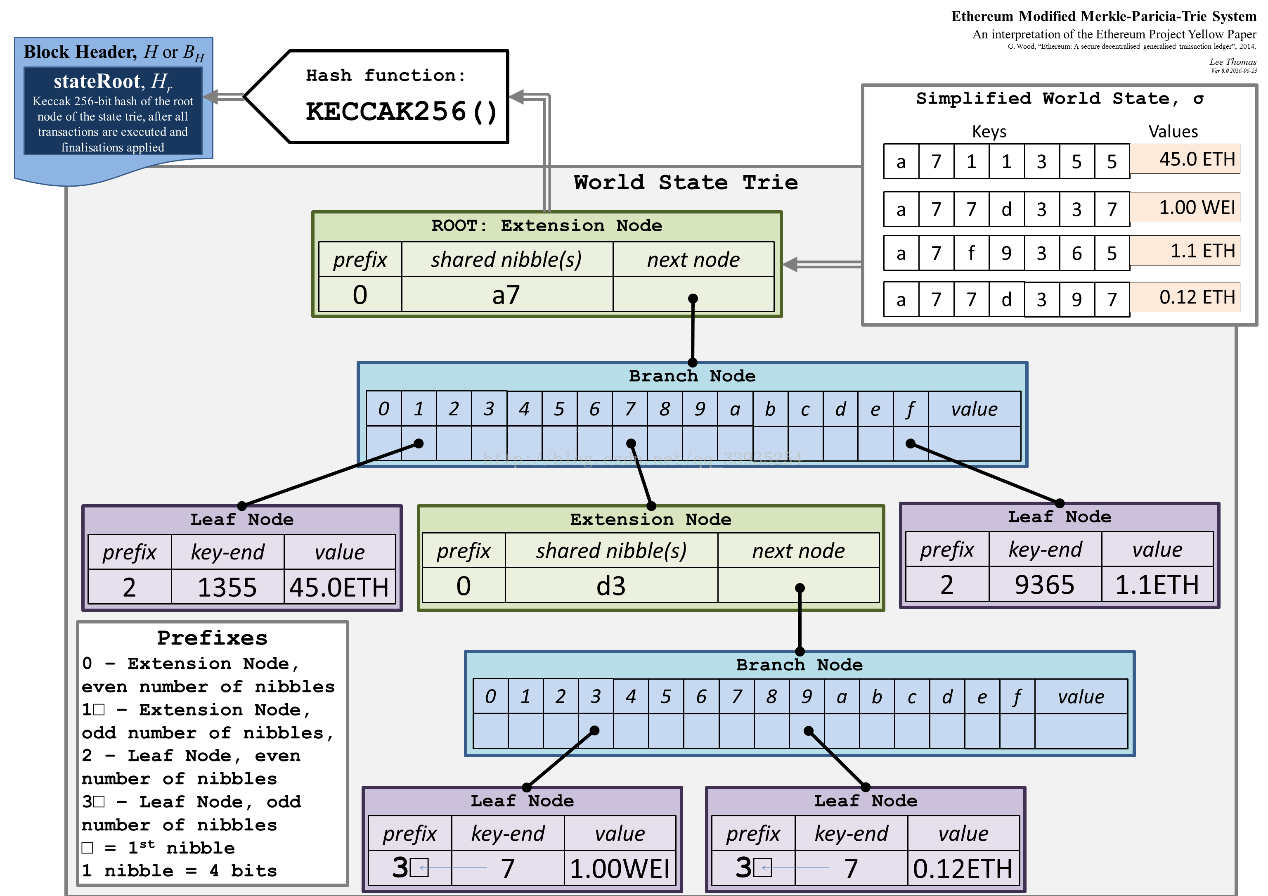
func hexToCompact(hex []byte) []byte {
terminator := byte(0)
//判断是否是包含真实的值
if hasTerm(hex) {
terminator = 1
hex = hex[:len(hex)-1] //截取掉HEX的尾部
}
buf := make([]byte, len(hex)/2+1)
buf[0] = terminator << 5 // the flag byte
if len(hex)&1 == 1 { //说明有效长度是奇数
buf[0] |= 1 << 4 // odd flag
buf[0] |= hex[0] // first nibble is contained in the first byte
hex = hex[1:]
}
decodeNibbles(hex, buf[1:])
return buf
}
三,存储
前面只是简单的一个介绍,这里才是本文的一个重点,接下来将学习是各种数据如何进行存储的。以太坊中使用的数据库是levelDB
(1) header和block存储
headerPrefix = []byte("h") // headerPrefix + num (uint64 big endian) + hash -> header
tdSuffix = []byte("t") // headerPrefix + num (uint64 big endian) + hash + tdSuffix -> td
numSuffix = []byte("n") // headerPrefix + num (uint64 big endian) + numSuffix -> hash
blockHashPrefix = []byte("H") // blockHashPrefix + hash -> num (uint64 big endian)
bodyPrefix = []byte("b") // bodyPrefix + num (uint64 big endian) + hash -> block body
blockReceiptsPrefix = []byte("r") // blockReceiptsPrefix + num (uint64 big endian) + hash -> block receipts
lookupPrefix = []byte("l") // lookupPrefix + hash -> transaction/receipt lookup metadata
bloomBitsPrefix = []byte("B") // bloomBitsPrefix + bit (uint16 big endian) + section (uint64 big endian) + hash -> bloom bits
从上面代码我们可以看出存储的对应规则,接下来对几个字段解释一下。 num:区块号(uint64大端格式); hash:区块哈希值;
这里有一个需要特别注意的地方:因为Header的前向指针是不能修改的,那么当把Header写入数据库时候,我们必须要先保证parent和parent的parent等,已经写入数据库
(2) 交易存储
这里我们看一下代码
func WriteTxLookupEntries(db ethdb.Putter, block *types.Block) error {
// 遍历每个交易并且编码元数据
for i, tx := range block.Transactions() {
entry := TxLookupEntry{
BlockHash: block.Hash(),
BlockIndex: block.NumberU64(),
Index: uint64(i),
}
data, err := rlp.EncodeToBytes(entry)
if err != nil {
return err
}
if err := db.Put(append(lookupPrefix, tx.Hash().Bytes()...), data); err != nil {
return err
}
}
return nil
}
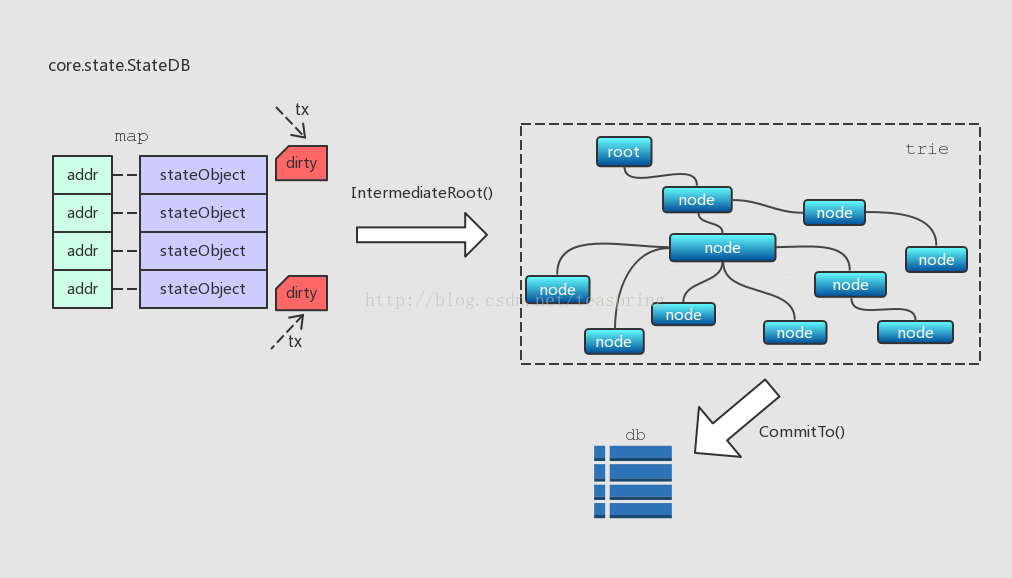
(3) StateDB模块
在以太坊中,账户的呈现形式是一个stateObject,所有账户首StateDB管理。StateDB中有一个成员叫trie,存储stateObject,每个stateObject有20bytes的地址,可以将其作为key;每次在一个区块的交易开始执行前,trie由一个哈希值(hashNode)恢复出来。另外还有一个map结构,也是存放stateObject,每个stateObject的地址作为map的key
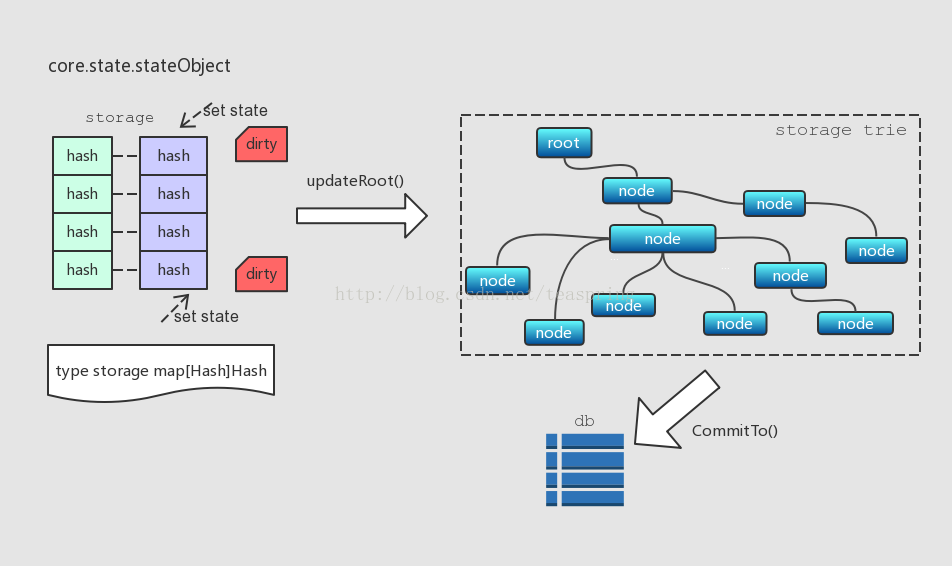
(4) 存储账户(stateObject)
每个stateObject对应了一个账户(Account包含了余额,合约发起次数等数据),同时它也包含了一个trie(storage trie),用来存储State数据。相关信息如下图
四,收获
不仅仅对以太坊的存储原理更加理解,同时,在系统设计方面,以太坊也有很多可以借鉴之处,例如:多级缓存,数据存储方式等等。
