

本文由 「AI前线」原创,原文链接:微软程序归纳新技术:元程序归纳
作者|Rishabh Singh
译者|张健欣
编辑|Natalie
最近许多关于 AI 的研究集中于扩展深度学习框架的能力:从简单的分类和模式识别到更复杂的学习算法任务领域,例如归纳编程。基于我们过去在神经程序合成方面的工作(用一种功能型语言来学习字符转换),我们大部分最近的工作探索了训练神经架构来归纳 Karel 语言程序的挑战。Karel 是一种更具挑战性的并且具有复杂控制流的命令语言。
具体来说,我们正在努力解决只有有限代码示例可用时进行程序归纳的困难。传统上,神经程序归纳方案都是基于非常多的输入输出示例来获取可接受的结果。这些例子能有大约成百上千到成千上万个。我们研究的一部分是尝试开发新技术,这些技术能够以明显更少的示例来获取理想的结果。这些新技术,通常用术语称为“组合调整(portfolio adaptation)”和“元程序归纳(meta program induction)”。它们基于的原理是,从相似的学习任务中迁移知识,来弥补缺少输入 / 输出示例的问题。
我们用大范围数据集的基准测试比较了四种这样的技术的性能。在测试用例中,我们使用了 Karel 编程语言,它引入了复杂的控制流,包括条件和循环以及一套必要的动作。这个测试用例向神经架构提供了固定数量的输入 / 输出示例(从 1 到 100,000 的范围),然后让它们从一套新的输入集中得到正确的输出结果(通过隐式学习来归纳相应的 Karel 程序)。下图展示了一组 Karel 数据集的程序归纳任务,我们的元模型可以精准地只从 2 到 4 个示例学习到不错的结果。
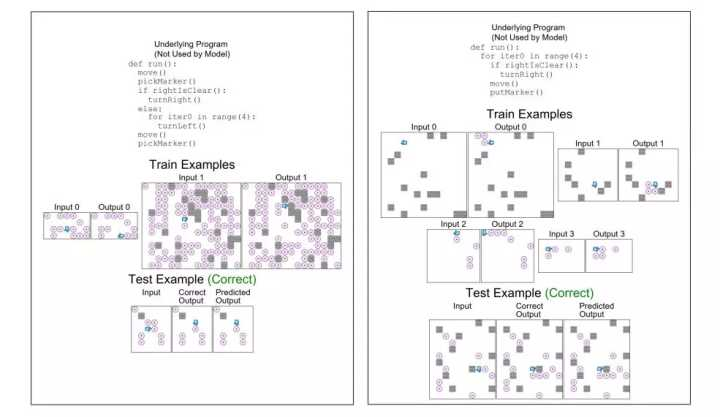
正如我们最近发表的论文中阐述的那样,结果非常好(与单纯使用 PLAIN 的示例驱动技术取得的 0% 的准确率相比):我们的其中一项元归纳技术从不足 10 个示例中取得了大约 40% 的准确率。
附随的图表说明了这 4 个模型在相同样例数目下每一个的性能是如何变化的。可以看到,提供的示例越少时,技术越新执行效果明显越好。我们认为,尽管结果随着示例数目的增多而逐渐收敛,但我们更新颖的技术仍然展现出了某些优势,因为它们比传统的模型需要更少的计算资源和处理时间。
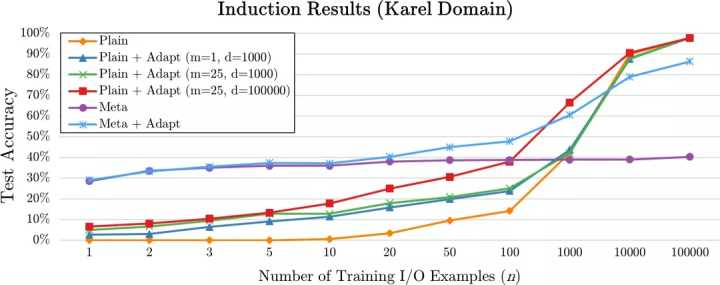
下面对这 4 种技术进行了总结。
- 普通程序归纳(Plain Program Induction, PLAIN) 。用有监督学习来训练可以对单个任务进行归纳的模型,例如,读入一个该任务的输入示例,然后推测出相应的输出。跨任务的知识没有共享。
- 组合调整过的程序归纳(Portfolio-Adapted Program Induction, PLAIN+ADAPT)。用简单的迁移学习来调整一个新任务的模型(这个模型已经在一个相关任务中训练过)。
- 元程序归纳(Meta Program Induction, META)。用多样本学习风格的模型来代表数目呈指数增长的任务,将与任务相关的 I/O 示例有条件地作为神经网络的输入。这个模型无需额外的训练就可以推广到新的任务。
- 调整过的元程序归纳(Adapted Meta Program Induction, META+ADAPT)。对新的特定任务的 I/O 示例用每次淘汰一个的循环赛法训练,使元程序归纳模型适应该任务。
这个领域的相关工作将会继续,来优化这些模型并且开发新技术。这些新技术应该使神经网络能够在不需要无数示例的情况下,用成熟的编程语言执行复杂的编程任务。
相关文章
Microsoft Research at NIPS 2017
www.microsoft.com/en-us/resea…
Neural Program Meta-Induction
www.microsoft.com/en-us/resea…
Neural Program Synthesis
www.microsoft.com/en-us/resea…
查看英文原文:
New Meta-learning Techniques for Neural Program Induction
更多干货内容,可关注AI前线,ID:ai-front,后台回复「AI」、「TF」、「大数据」可获得《AI前线》系列PDF迷你书和技能图谱。
