

各位小伙伴们大家好,数据平滑这个地方我想使用宗成庆老师的书中的一个例子进行开始,从而引出这一篇文章的主题,我们为什么要需要数据平滑以及常用的数据平滑的模型,话不多说,开始行动:
请看这个例子:
假设语料是由下面的三个句子构成:
①:BROWN READ HOLY BIBLE
②:MARK READ A TEXT BOOK
③:HE READ A BOOK BY DAVID
如果按照最大似然估计的方法计算p(BROWN READ A BOOK)的话:

因此:

但是这时候问题来了:
如果我们这时候要求p(David read a book),这时候概率是多少呢?

但是根据我们自己积累的知识,Brown和David都是人,Brown可以看书,为啥David不可以看书,这个显然是不对的,而造成这个方法的主要原因还是因为我们的语料库太小,不够丰富,事实上我们是希望我们的语料库越大越好,越全越给力,不然一旦给定你的语句的概率是0,无论你的句子书写的多么优美,也是达不到我们人类的期望的效果,所以这时候我们需要给所有可能出现的字符串一个非零的概率值来去解决这样的问题,这就是所谓的平滑.
平滑的目的在上边我们已经所说,总结概括就是解决由于数据匮乏(稀疏)引起的零概率的问题,而所采用的方法就是从高概率语句中分出微小的概率给予零概率的句子,在宗成庆老师的书中形象的说明是”劫富济贫”,而数据平滑是语言模型的核心的问题,宗成庆老师的书中给出了太多的算法,在这里我只记录几种算法,然后贯通思路,如果大家深入了解的话可以自己读书和读宗老师提供的论文:
一:加法平滑方法
算法的基本思想是:在这里先说一下加一法,加一法其实是每一种情况出现之后次数加1,即假设每个二元语法出现的次数比实际出现的次数多一次,这样就叫做了加一法,而加法平滑其实就是不是让每一个n元语法发生的次数比实际的统计次数多一次,而是假设比实际出现的情况多发生△次,并且0<△<1,这就有公式:
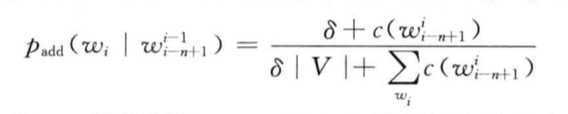
二:Good Turing估计法:
这个方法是很多平滑技术的核心

在上边为什么会是小于1,在这里我证明了一下:
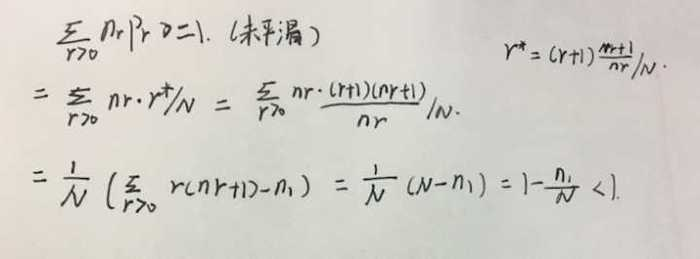
缺陷:

三:Jelinek-Merer平滑方法
基本思想:主要利用低元N-gram模型对高元N-gram模型进行线性插值

四:绝对减值法

各种平滑方法的比较:
不管训练语料规模多大,对于二元语法和三元语法而言,Kneser-Ney平滑方法和修正的Kneser-Ney平滑方法的效果都好于其他所有的平滑方法。Katz平滑方法和Jelinek- Mercer平滑方法次之。
在稀疏数据的情况下,Jelinek-Mercer平滑方法优于Katz平滑方法;而在有大量数据 的情况下,Katz平滑方法则优于Jelinek-Mercer平滑方法。
这里我画了一张图:
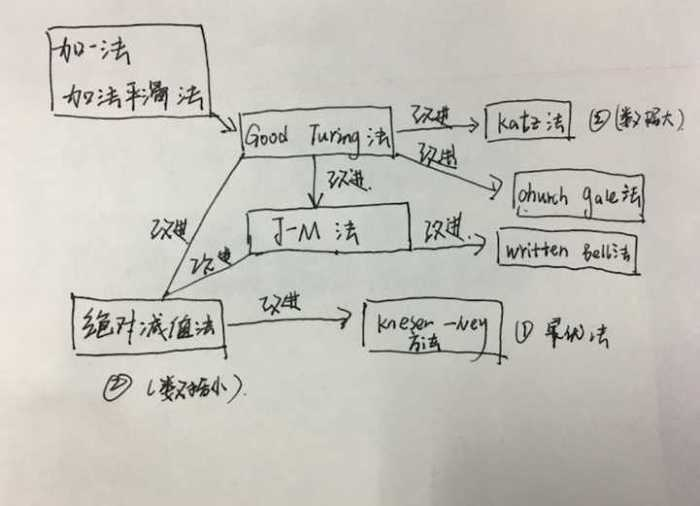
这里浅谈一下我在读宗成庆老师这本书的时候的一点点小看法,读宗老师的书总是感觉太过于全,但是很多东西都讲得不够透彻,并且很多地方也是有赶工的痕迹,不过总体上的路线都能够总结出来,但是其中宗老师提供了很多的论文地址,大家可以去搜一搜然后在去详细深入.
影响平滑算法性能的因素:
平滑方法的相对性能不训练语料的规模、n元语法模型的阶数和训练语料本身有较大 的关系,其效果可能会随着这些因素的丌同而出现很大的变化。

语言模型的缺陷 :
1:在训练语言模型时所采用的语料往往来自多种丌同的领域,这些综合性语料难以反映在不同领域之间在语言使用规律上的差异,而语言模型恰恰对于训练文本的类型、主题 和风格等都十分敏感;
2:n 元语言模型的独立性假设的前提是一个文本中的当前词出现的概率只不它前面相邻 的n-1 个词相关,但这种假设在很多情况下是明显不成立的。
