

今天从大哥手里接了一个需求:
验证一下新的 Docker 镜像仓库(Docker Registry)是否迁移成功了
简单粗暴的方法就是拿到老仓库中的镜像列表(Image List),在新仓库模拟用户重新拉取(pull)一遍来验证,我们开始
subprocess
如果我们用 Shell 来写,执行 Docker 命令很容易,直接写就是了,但是对结果的判断就不那么友好了(Shell 大神忽略),那么 Python 呢,如何优雅的执行 Linux 命令呢?这里我们用到了一个 Python 标准库(standard module) :
import subprocess我们都知道,命令执行过程中会有标准输出(stdout)和标准错误(stderror):
def run_cmd(cmd):
return subprocess.Popen(cmd,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE).communicate()上面代码封装了一个方法,它会启动一个子进程执行命令,并将标准输出和标准错误通过管道(进程间通信最常用的方式)收集
管道其实就是文件描述符对,子进程会继承父进程中的所有文件描述符
最后,通过序列解包:
stdout, stderr = run_cmd('uname -a')获取标准输出和标准错误,这个方法我们后面要用到好多
我拿到镜像列表文件了,先使用
cat imagelist | wc -l查看了一下行数(镜像数量),4254 个,还行,不算太多
思路:
- 拉取列表中的镜像,拉取成功后将其删除并标记为成功
- 拉取失败就标记为失败和并记录错误
- 如果拉取超时,就标记超时
如何标记呢,因为我们将会使用多进程,多个进程间通信还是蛮麻烦的,这里偷个懒:直接使用 append 模式直接将结果写入文件
with open('timeout_image.txt','a') as timeout_file:
timeout_file.write(image)我们先写出如何验证一个镜像的逻辑:
def pull_worker(image):
try:
# 这里我们设置了 10 分钟的超时
with Timeout(600):
cmd = 'docker pull {0}'.format(image)
shell_cmd(cmd)
out, err = shell_cmd('docker images {0}'.format(image))
# 如果验证 pull 成功
if not err:
out, err = shell_cmd('docker rmi {0}'.format(image))
# 如果删除镜像失败
if err:
print "[ERROR docker rmi] {0} {1}".format(image, err)
return
# 完美
with open('good_image.txt','a') as goodImageFile:
goodImageFile.write(image)
# 如果 pull 失败,将镜像名和失败信息写入文件
else:
with open('error_image.txt','a') as timeout_file:
timeout_file.write(image + " {0}".format(err))
# 如果超时
except Timeout:
with open('timeout_image.txt','a') as timeout_file:
timeout_file.write(image)后面就仅仅是并发的问题了
sys
首先我们想控制并发数量,最简单是使用 sys 模块
if len(sys.argv) == 4:
pass
else:
print "Need three params:\n# 1 File\n# 2 Process numbers\n# 3 Parallels numbers for each process"
return
# 这里同样使用了序列解包,第一个参数是脚本名字,忽略掉
_, file, coreNum, poolNum = sys.argv这样的程序执行起来像这样:
python check_images.py imagelist 8 5gevent
然后是实现,我们使用的这个模块需要安装,它是大名鼎鼎的 gevent,为什么使用它,因为我们的任务是 I/O 密集 型的,gevent 擅长处理这类任务(有兴趣可以去了解下猴子补丁)
pip install gevent我们看导入模块的代码:
import gevent.pool
import gevent.monkey
from gevent import Timeout
gevent.monkey.patch_all() # 猴子补丁
from multiprocessing import Process最后一行也是使用了 Python 的标准库,多进程模块:multiprocessing
不要和我说什么Python 有全局解释器锁(GIL),多进程没有 GIL,多进程没有 GIL,多进程没有 GIL
如何并发呢:
- 启动和核数相等的进程(跑满机器,尽快完成任务为目的)
- 每个进程里面 docker pull 的并发为 5(gevent 协程池)
所以我们总的并发数就是
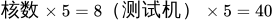
这样我们就完成了并发 40 的脚本,当然具体可以根据情况调整
代码如下:
def each_process(task_object_list):
pool = gevent.pool.Pool(int(poolNum))
pool.map(pull_worker, task_object_list)
stop = time.time()
elapsed = stop - start
print "End precess with {0} s".format(elapsed)
with open(file) as f:
for line in f:
line = line.strip()
all_task_list.append(line)
print "All task: {0}".format(len(all_task_list))
for sliced_task_list in slice_list(all_task_list, int(coreNum)):
print "Start process with tasks: {0}".format(len(sliced_task_list))
p = Process(target=each_process, args=(sliced_task_list,))
p.start()
这里需要注意的一点是,4254 个镜像,是按照核心数量分组(slice_list),然后交给不同的进程处理的,完整的实现可以去这里看(传送门)
写脚本花了 20 分钟 😏,写文章花了两个小时 🤣
今天就到这里,别忘了关注喔
