

本文源码基于spark 2.2.0
基本概念
Application
用户编写的Spark程序,通过一个有main方法的类执行,完成一个计算任务的处理。它是由一个Driver程序和一组运行于Spark集群上的Executor组成
RDD
弹性分布式数据集。RDD是Spark的核心数据结构,可以通过一系列算子进行操作。当RDD遇到Action算子时,将之前的所有算子形成一个有向无环图(DAG)。再在Spark中转化为Job,提交到集群执行
spark2.x后就使用DataFrame/DateSet了
SparkContext
SparkContext是Spark的入口,负责连接Spark集群,创建RDD,累积量和广播量等。从本质上来说,SparkContext是Spark的对外接口,负责向调用者提供Spark的各种功能。
Only one SparkContext may be active per JVM. You must
stop()the active SparkContext before creating a new one. This limitation may eventually be removed; see SPARK-2243 for more details.
每个JVM只有一个SparkContext,一台服务器可以启动多个JVM
SparkSession
The entry point to programming Spark with the Dataset and DataFrame API.
包含了SQLContext和HiveContext
Driver
运行main方法的Java虚拟机进程,负责监听spark application的executor进程发来的通信和连接,将工程jar发送到所有的executor进程中
Driver与Master、Worker协作完成application进程的启动、DAG划分、计算任务封装、分配task到executor上、计算资源的分配等调度执行作业等
driver调度task给executor执行,所以driver最好和spark集群在一片网络内,便以通信
driver进程通常在worker节点中,和Cluster Manager不在同一个节点上
Cluster Manager作用对象是整个saprk集群(集群资源分配),所有应用,而Driver是作用于某一个应用(协调已经分配给application的资源),管理层面不一样
Worker
集群中的工作节点,启动并运行executor进程,运行作业代码的节点
standalone模式下:Worker进程所在节点
yarn模式下: yarn的nodemanager进程所在的节点
Executor
运行在worker节点上,负责执行作业的任务,并将数据保存在内存或磁盘中
每个spark application,都有属于自己的executor进程,spark application不会共享一个executor进程
在启动参数中有
executor-cores,executor-memory,每个executor都会占用cpu core和内存,又spark application间不会复用executor,则很容易导致worker资源不足
executor在整个spark application运行的生命周期内,executor可以动态增加/释放,见动态资源分配一节
executor使用多线程运行SparkContext分配过来的task,来一批task就执行一批
Job
一个spark application可能会被分为多个job,每次调用Action时,逻辑上会生成一个Job,一个Job包含了一个或多个Stage。
Stage
每个job都会划分为一个或多个stage(阶段),每个stage都会有对应的一批task(即一个taskset),分配到executor上去执行
Stage包括两类:ShuffleMapStage和ResultStage,如果用户程序中调用了需要进行Shuffle计算的Operator,如groupByKey等,就会以Shuffle为边界分成ShuffleMapStage和ResultStage。
如果一次shuffle都没执行,那就只有一个stage
TaskSet
一组关联的,但相互之间没有Shuffle依赖关系的Task集合;Stage可以直接映射为TaskSet,一个TaskSet封装了一次需要运算的、具有相同处理逻辑的Task,这些Task可以并行计算,粗粒度的调度是以TaskSet为单位的。
一个stage对应一个taskset
Task
driver发送到executor上执行的计算单元,每个task负责在一个阶段(stage),处理一小片数据,计算出对应的结果
Task是在物理节点上运行的基本单位,Task包含两类:ShuffleMapTask和ResultTask,分别对应于Stage中ShuffleMapStage和ResultStage中的一个执行基本单元。
InputSplit-task-partition有一一对应关系,Spark会为每一个partition运行一个task来进行处理(见本文知识点-Spark集群中的节点个数、RDD分区个数、cpu内核个数三者与并行度的关系一节)
手动设置task数量spark.default.parallelism
Cluster Manager
集群管理器,为每个spark application在集群中调度和分配资源的组件,如Spark Standalone、YARN、Mesos等
Deploy Mode
不论是standalone/yarn,都分为两种模式,client和cluster,区别在于driver运行的位置
client模式下driver运行在提交spark作业的机器上,可以实时看到详细的日志信息,方便追踪和排查错误,用于测试
cluster模式下,spark application提交到cluster manager,cluster manager(比如master)负责在集群中某个节点上,启动driver进程,用于生产环境
通常情况下driver和worker在同一个网络中是最好的,而client很可能就是driver worker分开布置,这样网络通信很耗时,cluster没有这样的问题
standalone模式
master做集群管理
Master进程和Worker进程组成的集群, 可以不需要yarn集群,不需要HDFS
Master
standalone模式下,集群管理器(Cluster Manager)的一种,为每个spark application在集群中调度和分配资源的组件
注意和driver的区别,即Cluster Manager和driver的区别
yarn模式
yarn做集群管理
ResourceManager进程和NodeManager进程组成的集群
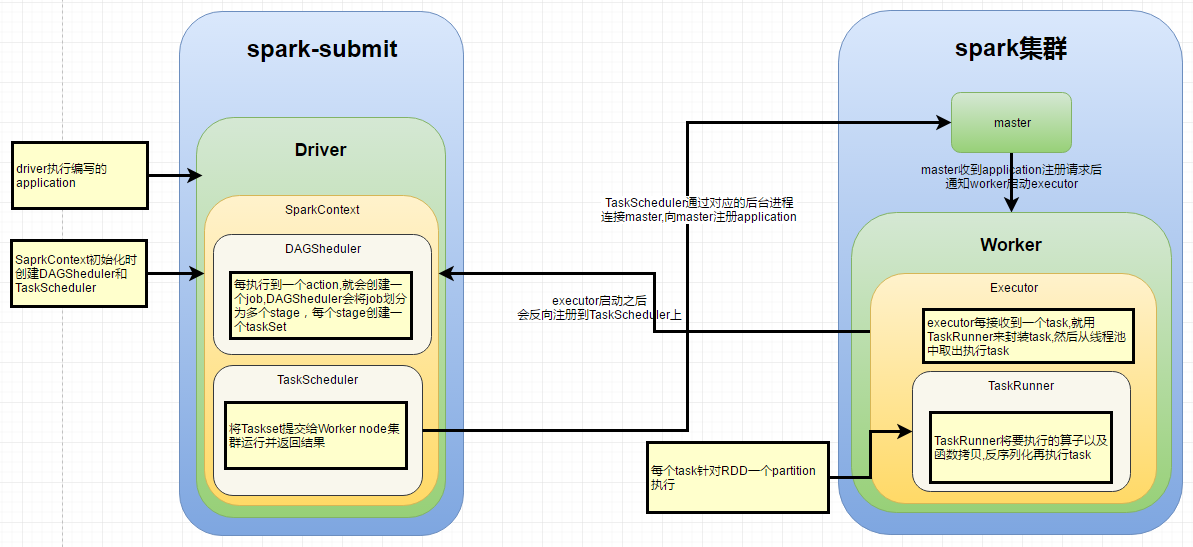
DAGScheduler
根据Job构建基于Stage的DAG,并提交Stage给TaskScheduler。
TaskScheduler
将Taskset提交给Worker node集群运行并返回结果。
spark基本工作原理
Driver向Master申请资源;
Master让Worker给程序分配具体的Executor
Driver把划分好的Task传送给Executor,Task就是我们的Spark程序的业务逻辑代码
job生成,stage划分和task分配都是发生在driver端?是
Spark VS MapReduce
Spark和MapReduce最大不同:迭代式计算
- MapReduce
一个job分两个阶段,map和reduce,两阶段处理完就算结束了 - Spark
可分为n个阶段,为内存迭代式
RDD
全称为Resillient Distributed Dataset,即弹性分布式数据集。
提供了容错性,可以自动从来源数据重新计算,从节点失败中恢复过来
默认是在内存中,内存不足则写入磁盘
一个RDD是分布式的,数据分布在一批节点上,每个节点存储了RDD部分partition
RDD内存不足会自动写入磁盘,调用cache()和persist()会将RDD数据按storelevel存储
RDD创建
SparkContext.wholeTextFiles()可以针对一个目录中的大量小文件,返回<filename,fileContent>组成的个PairRDDSparkContext.sequenceFile[K,V]()可以针对SequenceFile创建RDD,K和V泛型类型就是SequenceFile的key和value的类型。K和V要求必须是Hadoop的序列化类型,比如IntWritable、Text等。SparkContext.hadoopRDD()可以针对Hadoop的自定义输入类型创建RDD。该方法接收JobConf、InputFormatClass、Key和Value的Class。SparkContext.objectFile()方法,可以针对之前调用RDD.saveAsObjectFile()创建的对象序列化的文件,反序列化文件中的数据,并创建一个RDD。
并行化创建RDD
调用parallelize()方法,可以指定要将集合切分成多少个partition(实际上应该是指定了InputSplit数量,InputSplit-task-partition),Spark会为每一个partition运行一个task来进行处理(见本文知识点-Spark集群中的节点个数、RDD分区个数、cpu内核个数三者与并行度的关系一节)
Spark官方建议为集群中的每个CPU创建2~4个partition,避免CPU空载
如果集群中运行了多个任务,包括spark hadoop任务,是否也是以一个cpu core负载2-4个计算任务来配置?
Transformation和Action
Transformation
针对已有的RDD创建一个新的RDD
transformation具有lazy特性,只是记录了对RDD所做的操作,但是不会自发地执行。只有Action操作后,所有的transformation才会执行,可以避免产生过多中间结果
| 操作 | 介绍 |
|---|---|
| map | 将RDD中的每个元素传入自定义函数,获取一个新的元素,然后用新的元素组成新的RDD |
| filter | 对RDD中每个元素进行判断,如果返回true则保留,返回false则剔除。 |
| flatMap | 与map类似,是先映射后扁平化 |
| gropuByKey | 根据key进行分组,每个key对应一个Iterable |
| reduceByKey | 对每个key对应的value进行reduce操作。 |
| sortByKey | 对每个key对应的value进行排序操作。 |
| join | 对两个包含<key,value>对的RDD进行join操作,每个key join上的pair,都会传入自定义函数进行处理。 |
| cogroup | 同join,但是每个key对应的Iterable都会传入自定义函数进行处理。 |
map与flatMap的区别
map对rdd之中的元素逐一进行函数操作映射为另外一个rdd。
flatMap对集合中每个元素进行操作然后再扁平化。通常用来切分单词
实验:flatMap是否会将多层嵌套的元素再拍扁
实验结论:只往下一层做flatten操作,不会递归进去做flatten操作
val arr = sc.parallelize(Array(("A", 1), ("B", 2), ("C", 3)))
arr.flatMap(x => (x._1 + x._2)).foreach(print) //A1B2C3
val arr2 = sc.parallelize(Array(
Array(
("A", 1), ("B", 2), ("C", 3)),
Array(
("C", 1), ("D", 2), ("E", 3)),
Array(
("F", 1), ("G", 2), ("H", 3))))
arr2.flatMap(x => x).foreach(print) //(A,1)(B,2)(C,3)(C,1)(D,2)(E,3)(F,1)(G,2)(H,3)
val arr3 = sc.parallelize(Array(
Array(
Array(("A", 1), ("B", 2), ("C", 3))),
Array(
Array(("C", 1), ("D", 2), ("E", 3))),
Array(
Array(("F", 1), ("G", 2), ("H", 3)))))
arr3.flatMap(x => x).foreach(print) //[Lscala.Tuple2;@11074bf8 [Lscala.Tuple2;@c10a22d [Lscala.Tuple2;@40ef42cd
map和flatMap源码
def map[B](f: A => B): Iterator[B] = new AbstractIterator[B] {
def hasNext = self.hasNext
//直接遍历元素,对元素应用f方法
def next() = f(self.next())
}
/** Creates a new iterator by applying a function to all values produced by this iterator
* and concatenating the results.
*
* @return the iterator resulting from applying the given iterator-valued function
* `f` to each value produced by this iterator and concatenating the results.
*/
def flatMap[B](f: A => GenTraversableOnce[B]): Iterator[B] = new AbstractIterator[B] {
private var cur: Iterator[B] = empty
//这一步只是取当前元素的Iterator,没有递归往下层取
private def nextCur() { cur = f(self.next()).toIterator }
def hasNext: Boolean = {
while (!cur.hasNext) {
if (!self.hasNext) return false
nextCur()
}
true
}
//在调用next方法时,最终会调用到nextCur方法
def next(): B = (if (hasNext) cur else empty).next()
}
join VS cogroup VS fullOuterJoin VS leftOuterJoin VS rightOuterJoin
val studentList = Array(
Tuple2(1, "leo"),
Tuple2(2, "jack"),
Tuple2(3, "tom"));
val scoreList = Array(
Tuple2(1, 100),
Tuple2(2, 90),
Tuple2(2, 90),
Tuple2(4, 60));
val students = sc.parallelize(studentList);
val scores = sc.parallelize(scoreList);
/*
* (4,(CompactBuffer(),CompactBuffer(60)))
* (1,(CompactBuffer(leo),CompactBuffer(100)))
* (3,(CompactBuffer(tom),CompactBuffer()))
* (2,(CompactBuffer(jack),CompactBuffer(90, 90)))
*/
val studentCogroup = students.cogroup(scores) //union key数组延长
/*
* (1,(leo,100))
* (2,(jack,90))
* (2,(jack,90))
*/
val studentJoin = students.join(scores) //交集
/*
* (4,(None,Some(60)))
* (1,(Some(leo),Some(100)))
* (3,(Some(tom),None))
* (2,(Some(jack),Some(90)))
* (2,(Some(jack),Some(90)))
*/
val studentFullOuterJoin = students.fullOuterJoin(scores) //some可为空 union
/*
* (1,(leo,Some(100)))
* (3,(tom,None))
* (2,(jack,Some(90)))
* (2,(jack,Some(90)))
*/
val studentLeftOuterJoin = students.leftOuterJoin(scores) //左不为空
/*
* (4,(None,60))
* (1,(Some(leo),100))
* (2,(Some(jack),90))
* (2,(Some(jack),90))
*/
val studentRightOuterJoin = students.rightOuterJoin(scores) //右不为空
Action
对RDD进行最后的操作,如遍历,reduce,save等,启动计算操作,并向用户程序返回值或向外部存储写数据
会触发一个spark job的运行,从而触发这个action之前所有的transformation的执行
对于操作key-value对的Tuple2 RDD,如groupByKey,scala是通过隐式转换为PairRDDFunction,再提供对应groupByKey方法实现的,需要手动导入Spark的相关隐式转换,import org.apache.spark.SparkContext._
对groupByKey,saprk2.2显式使用HashPartitioner,没有看到隐式转换为PairRDDFunction Action操作一定会将结果返回给driver?是的,见下文的runJob方法
Action操作特征
Action操作在源码上必调用runJob()方法,可能是直接或间接调用
//直接调用了runJob
def collect(): Array[T] = withScope {
val results = sc.runJob(this, (iter: Iterator[T]) => iter.toArray)
Array.concat(results: _*)
}
/**
* Run a function on a given set of partitions in an RDD and pass the results to the given
* handler function. This is the main entry point for all actions in Spark.
*
* @param resultHandler callback to pass each result to
*/
//会把结果传递给handler function,handle function就是对返回结果进行处理的方法
//如上文的collect方法的handler function就是 (iter: Iterator[T]) => iter.toArray
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint()
}
| 操作 | 介绍 |
|---|---|
| reduce | 将RDD中的所有元素进行聚合操作。第一个和第二个元素聚合,值与第三个元素聚合,值与第四个元素聚合,以此类推。 |
| collect | 将RDD中所有元素获取到本地客户端。注意数据传输问题,spark.driver.maxResultSize可以限制action算子返回driver的结果集最大数量 |
| count | 获取RDD元素总数。 |
| take(n) | 获取RDD中前n个元素。 |
| saveAsTextFile | 将RDD元素保存到文件中,对每个元素调用toString方法 |
| countByKey | 对每个key对应的值进行count计数。 |
| foreach | 遍历RDD中的每个元素。 |
//从本地文件创建
val lines = spark.sparkContext.textFile("hello.txt")
//Transformation,返回(key,value)的RDD
val linePairs = lines.map(line => (line, 1))
//Transformation,隐式装换为PairRDDFunction,提供reduceByKey等方法
//源码中是用HashPartitioner
val lineCounts = linePairs.reduceByKey(_ + _)
//Action,发送到driver端执行
lineCounts.foreach(lineCount => println(lineCount._1 + " appears " + lineCount._2 + " times."))
mapPartitions
map:一次处理一个partition中的一条数据
mapPartitions:一次处理一个partition中所有的数据
使用场景:
RDD的数据量不是特别大,建议采用mapPartitions算子替代map算子,可以加快处理速度,如果RDD的数据量特别大,则不建议用mapPartitions,可能会内存溢出
val studentScoresRDD = studentNamesRDD.mapPartitions { it =>
var studentScoreList = Array("a")
while (it.hasNext) {
...
}
studentScoreList.iterator
}
mapPartitionsWithIndex:加上了partition的index
studentNamesRDD.mapPartitionsWithIndex{(index:Int,it:Iterator[String])=>
...
}
其他算子
- sample:按比例取样本,transformation操作
- takeSample:按个数取样本,action操作
- cartesian:笛卡尔积
- coalesce:将RDD的partition缩减,将数据压缩到更少的partition中去.
使用场景:若很多partition中的数据不均匀(如filter后),可以使用coalesce压缩rdd的partition数量,从而让各个partition中的数据都更加的紧凑
rdd.coalesce(3):压缩成3个partition
coalesce和repartition区别
repartition是coalesce的简化版
/**
* 返回一个经过简化到numPartitions个分区的新RDD。这会导致一个窄依赖
* 例如:你将1000个分区转换成100个分区,这个过程不会发生shuffle,相反如果10个分区转换成100个分区将会发生shuffle。
* 然而如果你想大幅度合并分区,例如合并成一个分区,这会导致你的计算在少数几个集群节点上计算(言外之意:并行度不够)
* 为了避免这种情况,你可以将第二个shuffle参数传递一个true,这样会在重新分区过程中多一步shuffle,这意味着上游的分区可以并行运行。
*/
def coalesce(numPartitions: Int, shuffle: Boolean = false,
partitionCoalescer: Option[PartitionCoalescer] = Option.empty)
(implicit ord: Ordering[T] = null)
: RDD[T] = withScope {...}
/**
* 返回一个恰好有numPartitions个分区的RDD,可以增加或者减少此RDD的并行度。
* 在内部,这将使用shuffle重新分布数据,如果你减少分区数,考虑使用coalesce,这样可以避免执行shuffle
*/
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}
设RDD分区数从N变更为M
| 分区数关系 | shuffle = true | shuffle = false |
|---|---|---|
| N < M | N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个 | coalesce为无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系 |
| N > M | 将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区 | |
| N >> M | shuffle = true,在重新分区过程中多一步shuffle,上游的分区可以并行运行,使coalesce之前的操作有更好的并行度 | 父子RDD是窄依赖关系,在同一个Stage中,可能造成Spark程序的并行度不够(计算在少数几个集群节点上进行),从而影响性能 |
- 返回一个减少到M个分区的新RDD,这会导致窄依赖,不会发生shuffle
- 返回一个增加到M个分区的新RDD,会发生shuffle
- 如果shuff为false时,N<M,RDD的分区数是不变的,也就是说不经过shuffle,是无法将RDD的partition数变多的
RDD持久化
cache()和persist()
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
如果需要从内存中清除缓存,那么可以使用unpersist()方法。
class StorageLevel private(
private var _useDisk: Boolean, //磁盘
private var _useMemory: Boolean,//内存
private var _useOffHeap: Boolean,//内存满就存磁盘
private var _deserialized: Boolean,//序列化储存
private var _replication: Int = 1)//冗余备份,默认1,只自己储存一份
extends Externalizable {
| 持久化级别 | 含义 |
|---|---|
| MEMORY_ONLY | 以非序列化的Java对象的方式持久化在JVM内存中。如果内存无法完全存储RDD所有的partition,那么那些没有持久化的partition就会在下一次需要使用它的时候,重新被计算。 |
| MEMORY_AND_DISK | 同上,但是当某些partition无法存储在内存中时,会持久化到磁盘中。下次需要使用这些partition时,需要从磁盘上读取。 |
| MEMORY_ONLY_SER | 同MEMORY_ONLY,但是会使用Java序列化方式,将Java对象序列化后进行持久化。可以减少内存开销,但是需要进行反序列化,因此会加大CPU开销。 |
| MEMORY_AND_DSK_SER | 同MEMORY_AND_DSK。但是使用序列化方式持久化Java对象。 |
| DISK_ONLY | 使用非序列化Java对象的方式持久化,完全存储到磁盘上。 |
| MEMORY_ONLY_2 MEMORY_AND_DISK_2 等等 | 如果是尾部加了2的持久化级别,表示会将持久化数据复用一份,保存到其他节点,从而在数据丢失时,不需要再次计算,只需要使用备份数据即可。 |
优先级排序(内存优先)
- MEMORY_ONLY
- MEMORY_ONLY_SER,将数据进行序列化进行存储
- DISK
共享变量
- 默认
一个算子的函数中使用到了某个外部的变量,则拷贝变量到每个task中,此时每个task只能操作自己的那份变量副本 - Broadcast Variable(广播变量)
将使用到的变量,为每个节点拷贝一份(不是每个task),减少网络传输以及内存消耗
只读变量 - Accumulator(累加变量)
让多个task共同操作一份变量,主要可以进行累加操作
val rdd = sc.parallelize(Array(1, 2, 3, 4, 5))
val factorBroadcast = sc.broadcast(3)
val sumAccumulator = new DoubleAccumulator()
//Accumulator must be registered before send to executor
sc.register(sumAccumulator)
val multipleRdd = rdd.map(num => num * factorBroadcast.value)
//不能获取值,只能在driver端获取
val accumulator = rdd.map(num2 => sumAccumulator.add(num2.toDouble))
//action:3,6,9,12,15
multipleRdd.foreach(num => println(num))
//要先执行action操作才能获取值
accumulator.collect() //15
println(sumAccumulator.value)
accumulator.count() //30,再次加15
println(sumAccumulator.value)
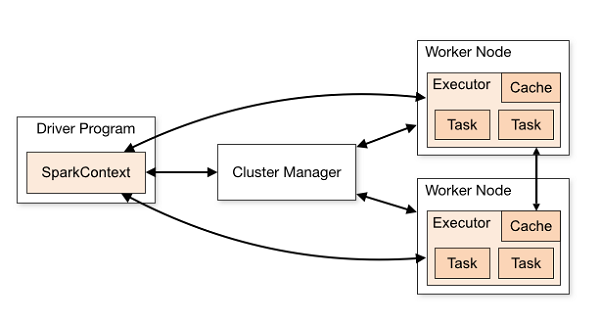
spark 内核架构
standalone模式下
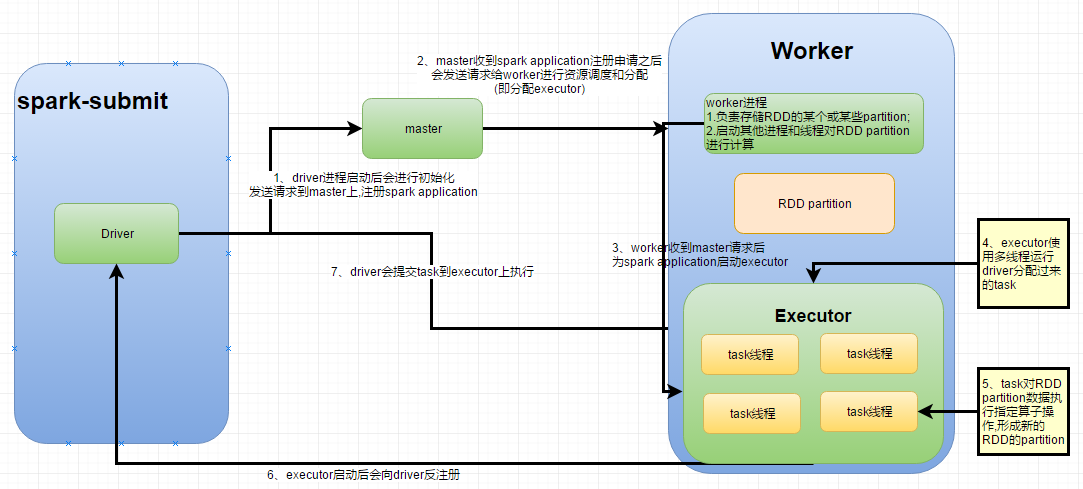
TaskScheduler把taskSet里每一个task提交到executor上执行
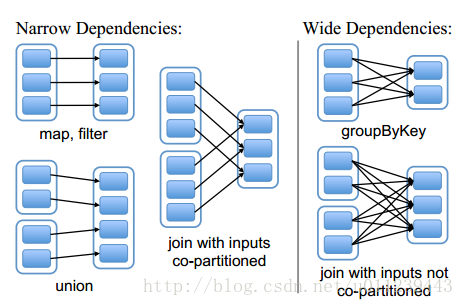
宽依赖与窄依赖
窄依赖(narrow dependency):每个parent RDD 的 partition 最多被 child RDD的一个partition使用
宽依赖(wide dependency):每个parent RDD 的 partition 被多个 child RDD的partition使用
区别:
- 窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;
宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。 - 窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算;
而对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
spark提交模式
- spark内核模式/standalone 模式 : 基于spark的master-worker集群
- 基于Yarn的yarn-cluster模式
- 基于Yarn的yarn-client模式
在spark提交脚本中设置
--master参数值为yarn-cluster / yarn-client
默认是standalone 模式
spark提交脚本
/usr/local/spark/bin/spark-submit \
--class com.feng.spark.spark1.StructuredNetworkWordCount \
--master spark://spark1:7077 \ #standalone模式
--num-executors 3 \ // #分配3个executor
--driver-memory 500m \
--executor-memory 500m \ # //每个executor500m内存
--executor-cores 2 \ // # 每个executor2个core
/usr/local/test_data/spark1-0.0.1-SNAPSHOT-jar-with-dependencies.jar \
整个应用需要3*500=1500m内存,3*2=6个core
--master local[8]:进程中用8个线程来模拟集群的执行
--total-executor-cores:指定所有executor的总cpu core数量
--supervise:指定了spark监控driver节点,如果driver挂掉,自动重启driver
配置方式
按优先级从高到低排序
- SparkConf:通过程序设置,在编辑器中用local模式执行运行时,只能在SparkConf中设置属性
- spark-submit脚本命令:当前应用有效,推荐
- spark-defaults.conf文件:全局配置
SparkConf.set("spark.default.parallelism", "100")
spark-submit: --conf spark.default.parallelism=50
spark-defaults.conf: spark.default.parallelism 10
在spark-submit脚本中,可以使用--verbose,打印详细的配置属性的信息
可以先在程序中创建一个空的SparkConf对象,如
val sc = new SparkContext(new SparkConf())
然后在spark-submit脚本中用--conf设置属性值,如
--conf spark.eventLog.enabled=false
依赖管理
--jars:额外依赖的jar包会自动被发送到集群上去
指定关联的jar:
- file: 由driver的http文件服务提供支持,所有的executor都会通过driver的HTTP服务来拉取文件
- hdfs:/http:/https:/ftp: 直接根据URI,从指定的地方拉取
- local: 这种格式的文件必须在每个worker节点上都要存在,所以不需要通过网络io去拉取文件,适用于特别大的文件或jar包,可以提升作业的执行性能
文件和jar都会被拷贝到每个executor的工作目录中,这就会占用很大一片磁盘空间,因此需要在之后清理掉这些文件
在yarn上运行spark作业时,依赖文件的清理都是自动进行的
使用standalone模式,需要配置spark.worker.cleanup.appDataTtl属性,来开启自动清理依赖文件和jar包
相关参数见conf/spark-evnsh参数一节
--packages:绑定maven的依赖包
--repositories:绑定额外的仓库
yarn-cluster模式
用于生产模式,driver运行在nodeManager,没有网卡流量激增问题,但查看log麻烦,调试不方便
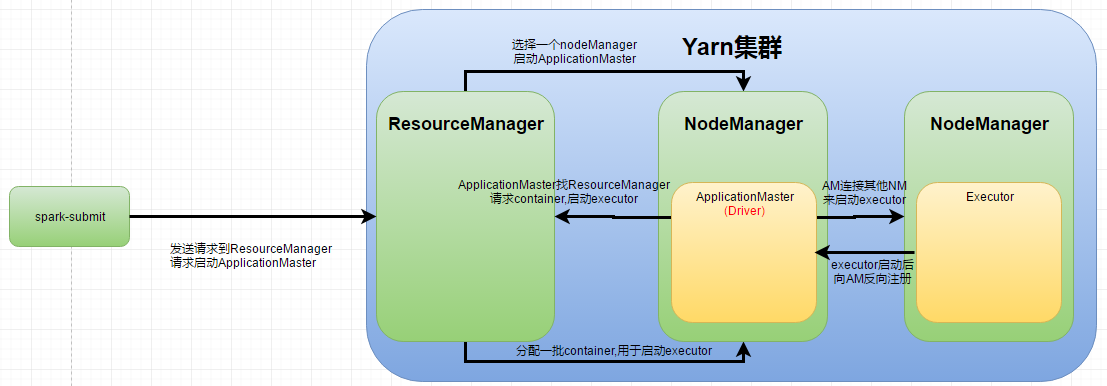
yarn-client模式
yarn-client用于测试,driver运行在本地客户端,负责调度application,会与yarn集群产生超大量的网络通信,从而导致网卡流量激增
yarn-client可以在本地看到所有log,方便调试
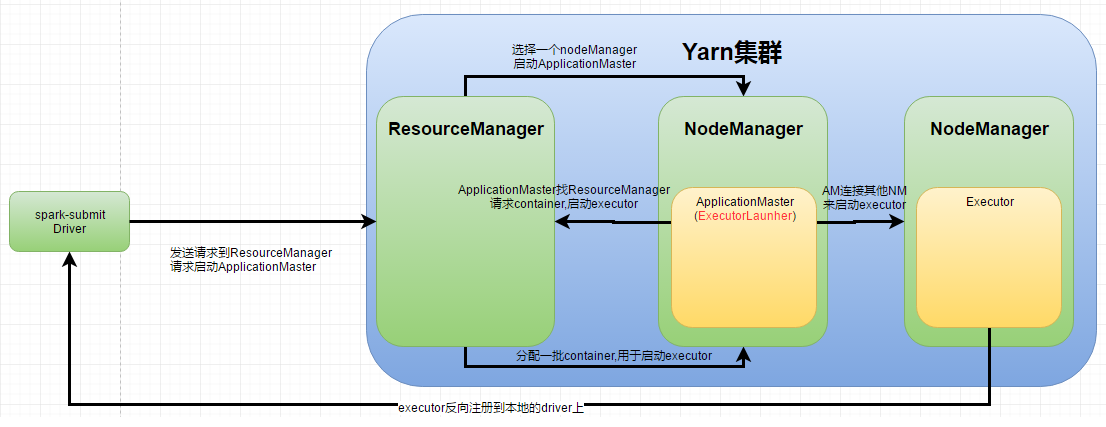
- yarn-client下,driver运行在spark-submit提交的机器上,ApplicationMaster只是相当于一个ExecutorLauncher,仅仅负责申请启动executor;driver负责具体调度
- yarn-cluster下,ApplicationMaster是driver,ApplicationMaster负责具体调度
standalone核心组件交互流程
基本要点:
- 一个Application会启动一个Driver
- 一个Driver负责跟踪管理该Application运行过程中所有的资源状态和任务状态
- 一个Driver会管理一组Executor
- 一个Executor只执行属于一个Driver的Task
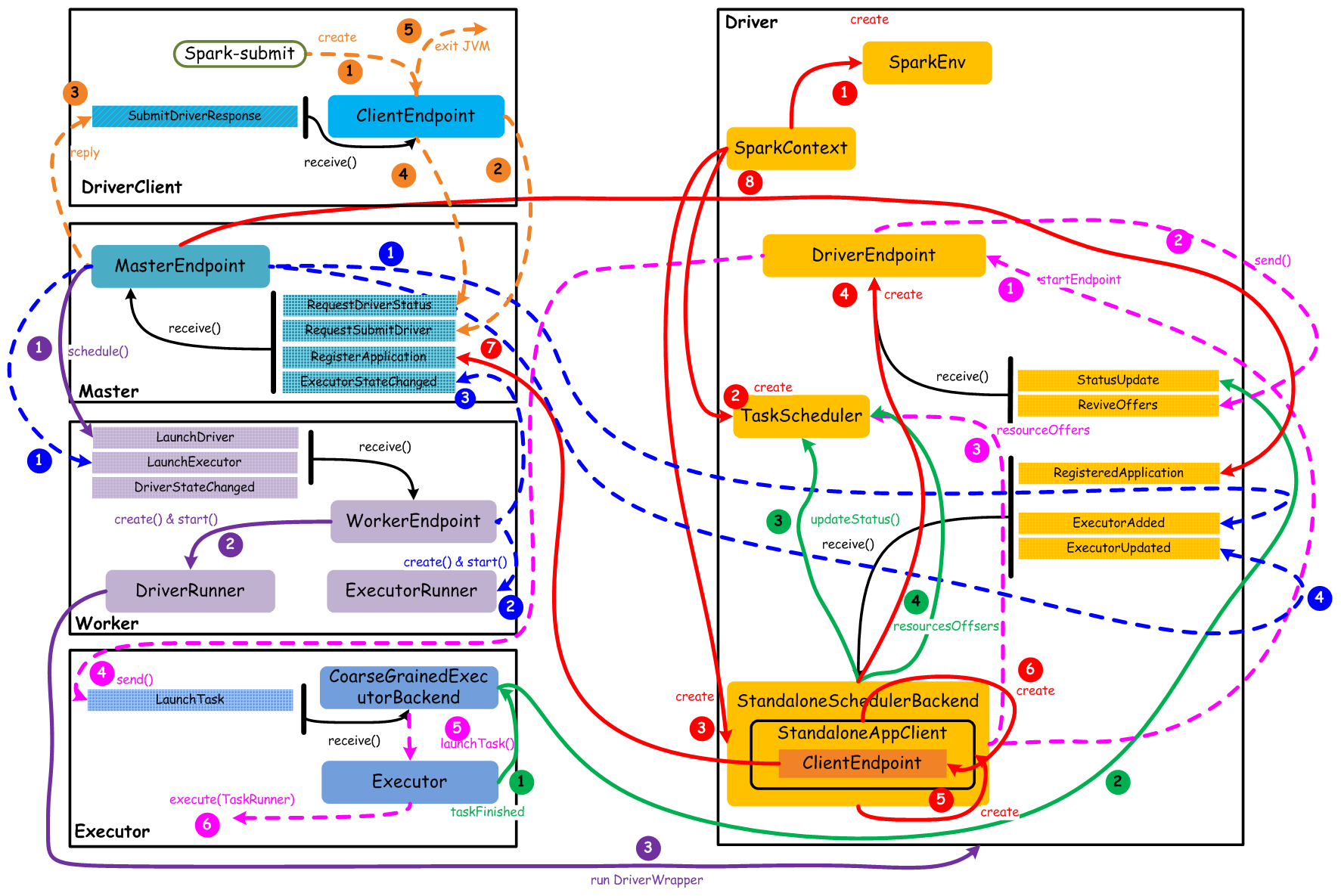
-
橙色:提交用户Spark程序
用户提交一个Spark程序,主要的流程如下所示:- 用户spark-submit脚本提交一个Spark程序,会创建一个ClientEndpoint对象,该对象负责与Master通信交互
- ClientEndpoint向Master发送一个RequestSubmitDriver消息,表示提交用户程序
- Master收到RequestSubmitDriver消息,向ClientEndpoint回复SubmitDriverResponse,表示用户程序已经完成注册
结合4,5,应该是表示用户程序已经在master注册,但driver可能并未启动
- ClientEndpoint向Master发送RequestDriverStatus消息,请求Driver状态
MasterEndPoint应该会向DriverClient返回一个类似DriverStatusResponse的应答?周期性应答,当获知driver已启动,则导致5
- 如果当前用户程序对应的Driver已经启动,则ClientEndpoint直接退出,完成提交用户程序
-
紫色:启动Driver进程
当用户提交用户Spark程序后,需要启动Driver来处理用户程序的计算逻辑,完成计算任务,这时Master需要启动一个Driver:- Maser内存中维护着用户提交计算的任务Application,每次内存结构变更都会触发调度,向Worker发送LaunchDriver请求
- Worker收到LaunchDriver消息,会启动一个DriverRunner线程去执行LaunchDriver的任务
- DriverRunner线程在Worker上启动一个新的JVM实例,该JVM实例内运行一个Driver进程,该Driver会创建SparkContext对象
当前worker节点运行driver进程
-
红色:注册Application
Dirver启动以后,它会创建SparkContext对象,初始化计算过程中必需的基本组件,并向Master注册Application,流程描述如下:- 创建SparkEnv对象,创建并管理一些基本组件
SparkEnv Holds all the runtime environment objects for a running Spark instance (either master or worker), including the serializer, RpcEnv, block manager, map output tracker, etc. Currently Spark code finds the SparkEnv through a global variable, so all the threads can access the same SparkEnv
- 创建TaskScheduler,负责Task调度
- 创建StandaloneSchedulerBackend,负责与ClusterManager进行资源协商
- 创建DriverEndpoint,其它组件可以与Driver进行通信
只是创建,还未启动
- 在StandaloneSchedulerBackend内部创建一个StandaloneAppClient,负责处理与Master的通信交互
- StandaloneAppClient创建一个ClientEndpoint,实际负责与Master通信
- ClientEndpoint向Master发送RegisterApplication消息,注册Application
- Master收到RegisterApplication请求后,回复ClientEndpoint一个RegisteredApplication消息,表示已经注册成功
-
蓝色:启动Executor进程
- Master向Worker发送LaunchExecutor消息,请求启动Executor;同时Master会向Driver发送ExecutorAdded消息,表示Master已经新增了一个Executor(此时还未启动)
executor还未真实启动,master只是发出一个启动executor的消息给worker而已. 这一步表明master才是负责启动和分配executor,driver只是提交task到executor
- Worker收到LaunchExecutor消息,会启动一个ExecutorRunner线程去执行LaunchExecutor的任务
- Worker向Master发送ExecutorStageChanged消息,通知Executor状态已发生变化
- Master向Driver发送ExecutorUpdated消息,此时Executor已经启动
这里master才真正告诉driver executor已经启动
-
粉色:启动Task执行
- StandaloneSchedulerBackend启动一个DriverEndpoint
之前已经创建,但未启动,之前和master的通信都是StandaloneSchedulerBackend完成的
- DriverEndpoint启动后,会周期性地检查Driver维护的Executor的状态,如果有空闲的Executor便会调度任务执行
启动一个driver-revive-thread后台线程,周期性地发送ReviveOffers给自己,让自己检查executor状态
- DriverEndpoint向TaskScheduler发送Resource Offer请求
DriverEndpoint是CoarseGrainedSchedulerBackend内部的一个持有对象
- 如果有可用资源启动Task,则DriverEndpoint向Executor发送LaunchTask请求
- Executor进程内部的CoarseGrainedExecutorBackend调用内部的Executor线程的launchTask方法启动Task
- Executor线程内部维护一个线程池,创建一个TaskRunner线程并提交到线程池执行
-
绿色:Task运行完成
- Executor进程内部的Executor线程通知CoarseGrainedExecutorBackend,Task运行完成
- CoarseGrainedExecutorBackend向DriverEndpoint发送StatusUpdated消息,通知Driver运行的Task状态发生变更
- StandaloneSchedulerBackend调用TaskScheduler的updateStatus方法更新Task状态
StandaloneSchedulerBackend父类CoarseGrainedSchedulerBackend内部持有DriverEndpoint(内部类),DriverEndpoint收到StatusUpdate信息后,直接调用
scheduler.statusUpdate(taskId, state, data.value)- StandaloneSchedulerBackend继续调用TaskScheduler的resourceOffers方法,调度其他任务运行
Spark Standalone集群单独启动master和worker
用start-all.sh脚本可以启动master进程和所有worker进程,快速启动整个spark standalone集群
分别启动master和worker进程
为何要分别启动
分别启动可以通过命令行参数,为进程配置一些独特的参数
如监听端口号、web ui端口号、使用的cpu和内存
如同一台机器上不仅运行了saprk程序,还运行了storm程序,就可以限制spark worker进程使用更少的资源(cpu core,memory),而非机器上所有资源
| 参数 | 含义 | 对象 | 使用频率 |
|---|---|---|---|
| -h HOST, --ip HOST | 在哪台机器上启动,默认就是本机 | master & worker | 不常用 |
| -p PORT, --port PORT | 在机器上启动后,使用哪个端口对外提供服务,master默认是7077,worker默认是随机的 | master & worker | 不常用 |
| --webui-port PORT | web ui的端口,master默认是8080,worker默认是8081 | master & worker | 不常用 |
| -c CORES, --cores CORES | 总共能让spark作业使用多少个cpu core,默认是当前机器上所有的cpu core | worker | 常用 |
| -m MEM, --memory MEM | 总共能让spark作业使用多少内存,是100M或者1G这样的格式,默认是1g | worker | 常用 |
| -d DIR, --work-dir DIR | 工作目录,默认是SPARK_HOME/work目录 | worker | 常用 |
| --properties-file FILE | master和worker加载默认配置文件的地址,默认是conf/spark-defaults.conf | master & worker | 不常用 |
启动顺序
先启动master,再启动worker,因为worker启动以后,需要向master注册
关闭顺序1.worker(
./stop-slave.sh) ;2. master(./stop-master);3. 关闭集群./stop-all.sh
启动master
- 使用
start-master.sh启动 - 启动日志就会打印一行
spark://HOST:PORT,这就是master的URL地址,worker进程就会通过这个URL地址来连接到master进程,并进行注册可以使用
SparkSession.master()设置master地址 - 可以通过
http://MASTER_HOST:8080来访问master集群的监控web ui,web ui上, 会显示master的URL地址
手动启动worker进程
使用start-slave.sh <master-spark-URL>在当前节点上启动worker进程
http://MASTER_HOST:8080web ui上会显示该节点的cpu和内存资源等信息
eg:./start-slave.sh spark://192.168.0.001:8080 --memory 500m
spark所有启动和关闭脚本
| 参数 | 含义 |
|---|---|
| sbin/start-all.sh | 根据配置,在集群中各个节点上,启动一个master进程和多个worker进程 |
| sbin/stop-all.sh | 在集群中停止所有master和worker进程 |
| sbin/start-master.sh | 在本地启动一个master进程 |
| sbin/stop-master.sh | 关闭master进程 |
| sbin/start-slaves.sh | 根据conf/slaves文件中配置的worker节点,启动所有的worker进程 |
| sbin/stop-slaves.sh | 关闭所有worker进程 |
| sbin/start-slave.sh | 在本地启动一个worker进程 |
配置文件
worker节点配置
配置作为worker节点的机器,如hostname/ip地址,一个机器是一行
配置后,所有的节点上,都拷贝这份文件
默认情况下,没有conf/slaves文件,只有一个空conf/slaves.template,
此时,就只是在当前主节点上启动一个master进程和一个worker进程,此时就是master进程和worker进程在一个节点上,也就是伪分布式部署
conf/slaves文件样本
spark1
spark2
spark3
conf/spark-evnsh参数
是对整个spark的集群部署,配置各个master和worker
和启动脚本--参数的效果一样
./start-slave.sh spark://192.168.0.001:8080 --memory 500m,临时修改参数时这种脚本命令更适合
命令行参数优先级更高,会覆盖spark-evnsh参数
| 参数 | 含义 |
|---|---|
| SPARK_MASTER_IP | 指定master进程所在的机器的ip地址 |
| SPARK_MASTER_PORT | 指定master监听的端口号(默认是7077) |
| SPARK_MASTER_WEBUI_PORT | 指定master web ui的端口号(默认是8080) |
| SPARK_MASTER_OPTS | 设置master的额外参数,使用"-Dx=y"设置各个参数 |
| SPARK_LOCAL_DIRS | spark的工作目录,包括了shuffle map输出文件,以及持久化到磁盘的RDD等 |
| SPARK_WORKER_PORT | worker节点的端口号,默认是随机的 |
| SPARK_WORKER_WEBUI_PORT | worker节点的web ui端口号,默认是8081 |
| SPARK_WORKER_CORES | worker节点上,允许spark作业使用的最大cpu数量,默认是机器上所有的cpu core |
| SPARK_WORKER_MEMORY | worker节点上,允许spark作业使用的最大内存量,格式为1000m,2g等,默认最小是1g内存 |
| SPARK_WORKER_INSTANCES | 当前机器上的worker进程数量,默认是1,可以设置成多个,但是这时一定要设置SPARK_WORKER_CORES,限制每个worker的cpu数量 |
| SPARK_WORKER_DIR | spark作业的工作目录,包括了作业的日志等,默认是spark_home/work |
| SPARK_WORKER_OPTS | worker的额外参数,使用"-Dx=y"设置各个参数 |
| SPARK_DAEMON_MEMORY | 分配给master和worker进程自己本身的内存,默认是1g |
| SPARK_DAEMON_JAVA_OPTS | 设置master和worker自己的jvm参数,使用"-Dx=y"设置各个参数 |
| SPARK_PUBLISC_DNS | master和worker的公共dns域名,默认是没有的 |
-
SPARK_MASTER_OPTS
设置master的额外参数,使用-Dx=y设置各个参数
eg:export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=1"参数名 默认值 含义 spark.deploy.retainedApplications 200 在spark web ui上最多显示多少个application的信息 spark.deploy.retainedDrivers 200 在spark web ui上最多显示多少个driver的信息 spark.deploy.spreadOut true 资源调度策略,spreadOut会尽量将application的executor进程分布在更多worker上,适合基于hdfs文件计算的情况,提升数据本地化概率;非spreadOut会尽量将executor分配到一个worker上,适合计算密集型的作业 spark.deploy.defaultCores 无限大 每个spark作业最多在standalone集群中使用多少个cpu core,默认是无限大,有多少用多少 spark.deploy.timeout 60 单位秒,一个worker多少时间没有响应之后,master认为worker挂掉了 -
SPARK_WORKER_OPTS
worker的额外参数参数名 默认值 含义 spark.worker.cleanup.enabled false 是否启动自动清理worker工作目录,默认是false spark.worker.cleanup.interval 1800 单位秒,自动清理的时间间隔,默认是30分钟 spark.worker.cleanup.appDataTtl 7 * 24 * 3600 默认将一个spark作业的文件在worker工作目录保留多少时间,默认是7天
Spark Application运行
local 模式
主要用于本机测试
/usr/local/spark/bin/spark-submit \
--class cn.spark.study.core.xxx \
--num-executors 3 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 2 \
/usr/local/test/xxx.jar \
standalone模式
参数设置
standalone模式与local区别,就是要将master设置成spark://master_ip:port,如spark://192.168.0.103:7077
- 代码:
val spark = SparkSession.builder().master("spark://IP:PORT")... spark-submit: --master spark://IP:PORT --deploy-mode client/cluster
默认client模式spark-shell: --master spark://IP:PORT:用于实验和测试/usr/local/spark/bin/spark-submit \ --class cn.spark.study.core.xxx \ --master spark://192.168.0.103:7077 \ --deploy-mode client \ --num-executors 1 \ --driver-memory 100m \ --executor-memory 100m \ --executor-cores 1 \ /usr/local/test/xxx.jar \
--master:
- 不设置:local模式
spark://xxx:standalone模式,会提交到指定的URL的Master进程上去yarn-xxx:yarn模式,会读取hadoop配置文件,然后连接ResourceManager
standalone client模式作业进程
提交运行作业后,立即使用jps查看进程,可以看到启动了如下进程
- SparkSubmit: driver进程,在本机上启动(spark-submit所在的机器)
- CoarseGrainedExecutorBackend(内部持有一个Executor对象,CoarseGrainedExecutorBackend即executor进程): 在执行spark作业的worker机器上,给作业分配和启动一个executor进程
SparkSubmit给CoarseGrainedExecutorBackend分配task
standalone cluster模式
standalone cluster模式支持监控driver进程,并且在driver挂掉的时候,自动重启该进程,主要是用于spark streaming中的HA高可用性,spark-submit脚本中,使用--supervise标识即可
要杀掉反复挂掉的driver进程
bin/spark-class org.apache.spark.deploy.Client kill <master url> <driver ID>,通过http://<maser url>:8080可查看到driver id
yarn下杀掉application
yarn application -kill applicationid
进程:
- SparkSubmit短暂执行,只是将driver注册到master上,由master来启动driver,马上就停止;
- 在Worker上,会启动DriverWrapper进程
- 如果能够申请到足够的cpu资源,会在其他worker上,启动CoarseGrainedExecutorBackend进程
...
--deploy-mode cluster \
--num-executors 1 \
--executor-cores 1 \
...
cluster模式下
- worker启动driver,占用一个cpu core
- driver去跟master申请资源,在有空闲cpu资源的worker上启动一个executor进程
cpu core太少,可能导致executor无法启动,一直waiting,比如只有一个worker,一个cpu core时
在 cluster 模式下,driver 是在集群中的某个 Worker中的进程中启动,并且 client进程将会在完成提交应用程序的任务之后退出,而不需要等待应用程序完成再退出
standalone多作业资源调度
默认提交的每一个spark作业都会尝试使用集群中所有可用的cpu资源,此时只能支持作业串行起来运行,所以standalone集群对于同时提交上来的多个作业,仅仅支持FIFO调度策略
- 设置多作业同时运行
可以设置spark.cores.max参数,限制每个作业能够使用的最大的cpu core数量,让作业不会使用所有的cpu资源,后面提交上来的作业就可以获取到资源运行,默认情况下,它将获取集群中的 all cores (核),这只有在某一时刻只允许一个应用程序运行时才有意义
spark.conf.set("spark.cores.max", "num")- 提交脚本命令
spark-submit: --master spark://IP:PORT --conf spark.cores.max=num spark-env.sh全局配置:export SPARK_MASTER_OPTS="-Dspark.deploy.defaultCores=num" 默认数量
standalone web ui
spark standalone模式默认在master机器上的8080端口提供web ui,可以通过配置spark-env.sh文件等方式,来配置web ui的端口,地址如spark://192.168.0.103:8080
spark yarn模式下应该在YARN web ui上查看,如
http://192.168.0.103:8088/
- application web ui
application detail ui在作业的driver所在的机器的4040端口
- 作业层面
可以用于具体定位问题,如- task数据分布不均匀:数据倾斜
- stage运行时间长:根据stage划分算法,定位stage对应的代码,去优化性能
- 每个作业在每个executor上的日志
stdout:System.out.println;
stderr:System.err.println和系统级别log作业运行完,信息消失,需要启动history server
yarn模式
前提:spark-env.sh文件中,配置HADOOP_CONF_DIR或者YARN_CONF_DIR属性,值为hadoop的配置文件目录HADOOP_HOME/etc/hadoop,其中包含了hadoop和yarn所有的配置文件,比如hdfs-site、yarn-site等
用途:spark读写hdfs,连接到yarn resourcemanager上
两种运行模式
- yarn-client模式
driver进程会运行在提交作业的机器上,ApplicationMaster仅仅只是负责为作业向yarn申请资源(executor)而已,driver还是会负责作业调度 - yarn-cluster模式
driver进程会运行在yarn集群的某个工作节点上,作为一个ApplicationMaster进程运行
查看yarn日志
日志散落在集群中各个机器上,参数配置yarn-site.xml
- 聚合日志方式(推荐)
属性设置 含义 yarn.log-aggregation-enable=truecontainer的日志会拷贝到hdfs上去,并从机器中删除 yarn.nodemanager.remote-app-log-dir当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效) yarn.nodemanager.remote-app-log-dir-suffix远程日志目录子目录名称(启用日志聚集功能时有效) yarn.log-aggregation.retain-seconds聚合后的日志在HDFS上保存多长时间,单位为s yarn logs -applicationId <app ID>查看日志,yarn web ui上可以查看到applicationId(也可以直接在hdfs上查看日志文件) yarn.nodemanager.log.retain-second当不启用日志聚合此参数生效,日志文件保存在本地的时间,单位为s yarn.log-aggregation.retain-check-interval-seconds隔多久删除过期的日志 - web ui查看
需要启动History Server,运行spark history server和mapreduce history server
不做配置就只能查看到正在运行的日志
配置见Spark History Web UI一节 - 分散查看
默认日志在YARN_APP_LOGS_DIR目录下,如/tmp/logs或者$HADOOP_HOME/logs/userlogs
如果yarn集群中没有开启History Server,想要查看system.out日志,需要在yarn-site.xml文件中设置yarn.log.aggregation-enable值为ture(将日志拷贝到hdfs上),查看时通过yarn logs -applicationId xxx在机器上查看
提交脚本
/usr/local/spark/bin/spark-submit \
--class xxx \
# 自动从hadoop配置目录中的配置文件中读取cluster manager地址
--master yarn-cluster/yarn-client \
--num-executors 1 \
--driver-memory 100m \
--executor-memory 100m \
--executor-cores 1 \
--conf <key>=<value> \
# 指定不同的hadoop队列,项目或部门之间队列隔离
--queue hadoop队列 \
/usr/local/test/xxx.jar \
${1}
--conf: 配置所有spark支持的配置属性,使用key=value的格式;如果value中包含了空格,那么需要将key=value包裹的双引号中--conf "<key>=<value>"
application-jar: 打包好的spark工程jar包,在当前机器上的全路径名
application-arguments: 传递给主类的main方法的参数; 在shell中用${1}占位符接收传递给shell的参数;在java中可以通过main方法的args[0]等参数获取,提交spark应用程序时,用 ./脚本.sh 参数值
yarn模式运行spark作业属性
可以在提交脚本上--conf设置属性
| 属性名称 | 默认值 | 含义 |
|---|---|---|
| spark.yarn.am.memory | 512m | client模式下,YARN Application Master使用的内存总量 |
| spark.yarn.am.cores | 1 | client模式下,Application Master使用的cpu数量 |
| spark.driver.cores | 1 | cluster模式下,driver使用的cpu core数量,driver与Application Master运行在一个进程中,所以也控制了Application Master的cpu数量 |
| spark.yarn.am.waitTime | 100s | cluster模式下,Application Master要等待SparkContext初始化的时长; client模式下,application master等待driver来连接它的时长 |
| spark.yarn.submit.file.replication | hdfs副本数 | 作业写到hdfs上的文件的副本数量,比如工程jar,依赖jar,配置文件等,最小一定是1 |
| spark.yarn.preserve.staging.files | false | 如果设置为true,那么在作业运行完之后,会避免工程jar等文件被删除掉 |
| spark.yarn.scheduler.heartbeat.interval-ms | 3000 | application master向resourcemanager发送心跳的间隔,单位ms |
| spark.yarn.scheduler.initial-allocation.interval | 200ms | application master在有pending住的container分配需求时,立即向resourcemanager发送心跳的间隔 |
| spark.yarn.max.executor.failures | executor数量*2,最小3 | 整个作业判定为失败之前,executor最大的失败次数 |
| spark.yarn.historyServer.address | 无 | spark history server的地址 |
| spark.yarn.dist.archives | 无 | 每个executor都要获取并放入工作目录的archive |
| spark.yarn.dist.files | 无 | 每个executor都要放入的工作目录的文件 |
| spark.executor.instances | 2 | 默认的executor数量 |
| spark.yarn.executor.memoryOverhead | executor内存10% | 每个executor的堆外内存大小,用来存放诸如常量字符串等东西 |
| spark.yarn.driver.memoryOverhead | driver内存7% | 同上 |
| spark.yarn.am.memoryOverhead | AM内存7% | 同上 |
| spark.yarn.am.port | 随机 | application master端口 |
| spark.yarn.jar | 无 | spark jar文件的位置 |
| spark.yarn.access.namenodes | 无 | spark作业能访问的hdfs namenode地址 |
| spark.yarn.containerLauncherMaxThreads | 25 | application master能用来启动executor container的最大线程数量 |
| spark.yarn.am.extraJavaOptions | 无 | application master的jvm参数 |
| spark.yarn.am.extraLibraryPath | 无 | application master的额外库路径 |
| spark.yarn.maxAppAttempts | 提交spark作业最大的尝试次数 | |
| spark.yarn.submit.waitAppCompletion | true | cluster模式下,client是否等到作业运行完再退出 |
关于master的高可用方案
standalone模式下调度器依托于master进程来做出调度决策,这可能会造成单点故障:如果master挂掉了,就没法提交新的应用程序了。
为了解决这个问题,spark提供了两种高可用性方案,分别是基于zookeeper的HA方案(推荐)以及基于文件系统的HA方案。
基于zookeeper的HA方案
概述
使用zookeeper来提供leader选举以及一些状态存储,可以在集群中启动多个master进程,让它们连接到zookeeper实例。其中一个master进程会被选举为leader,其他的master会被指定为standby模式。
如果当前的leader master进程挂掉了,其他的standby master会被选举,从而恢复旧master的状态。
配置
在启动一个zookeeper集群之后,在多个节点上启动多个master进程,并且给它们相同的zookeeper 配置(zookeeper url和目录)。master就可以被动态加入master集群,并可以在任何时间被移除掉
在spark-env.sh文件中,设置SPARK_DAEMON_JAVA_OPTS选项:
spark.deploy.recoveryMode:设置为ZOOKEEPER来启用standby master恢复模式(默认为NONE)spark.deploy.zookeeper.url:zookeeper集群urlspark.deploy.zookeeper.dir:zookeeper中用来存储恢复状态的目录(默认是/spark)
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=192.168.0.103:2181,192.168.0.104:2181 -Dspark.deploy.zookeeper.dir=/spark"
如果在集群中启动了多个master节点,但是没有正确配置master去使用zookeeper,master在挂掉进行恢复时是会失败的,因为没法发现其他master,并且都会认为自己是leader。这会导致集群的状态不是健康的,因为所有master都会自顾自地去调度。
细节
为了调度新的应用程序或者向集群中添加worker节点,它们需要知道当前leader master的ip地址,这可以通过传递一个master列表来完成。可以将SparkSession 的master连接的地址指向spark://host1:port1,host2:port2。这就会导致SparkSession尝试去注册所有的master,如果host1挂掉了,那么配置还是正确的,因为会找到新的leader master
当一个应用程序启动的时候,或者worker需要被找到并且注册到当前的leader master的时候。一旦它成功注册了,就被保存在zookeeper中了。如果故障发生了,new leader master会去联系所有的之前注册过的应用程序和worker,并且通知它们master的改变。应用程序甚至在启动的时候都不需要知道new master的存在。
故而,new master可以在任何时间被创建,只要新的应用程序和worker可以找到并且注册到master即可
在其他节点启动备用master:./start-master.sh
基于文件系统的HA方案
概述
FILESYSTEM模式:当应用程序和worker都注册到master之后,master就会将它们的信息写入指定的文件系统目录中,以便于重启时恢复注册的应用程序和worker状态;
需要手动重启
配置
在spark-env.sh中设置SPARK_DAEMON_JAVA_OPTS
spark.deploy.recoveryMode:设置为FILESYSTEM来启用单点恢复(默认值为NONE)spark.deploy.recoveryDirectory:spark存储状态信息的文件系统目录,必须是master可以访问的目录
eg:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/usr/local/spark_recovery"
细节
- 该模式更加适合于开发和测试环境
stop-master.sh脚本杀掉一个master进程是不会清理它的恢复状态,当重启一个新的master进程时,它会进入恢复模式。需要等待之前所有已经注册的worker等节点先timeout才能恢复。- 可以使用一个NFS目录(类似HDFS)作为恢复目录。如果原先的master节点挂掉,可以在其他节点上启动一个master进程,它会正确地恢复之前所有注册的worker和应用程序。之后的应用程序可以找到新的master,然后注册。
saprk作业监控
作业监控方式:Spark Web UI,Spark History Web UI,RESTFUL API以及Metrics
Spark Web UI
每提交Spark作业并启动SparkSession后,会启动一个对应的Spark Web UI服务。默认情况下Spark Web UI的访问地址是driver进程所在节点的4040端口,如http://<driver-node>:4040
Spark Web UI包括了以下信息:
- stage和task列表
- RDD大小以及内存使用的概览
- 环境信息
- 作业对应的executor的信息
如果多个driver在一个机器上运行,它们会自动绑定到不同的端口上。默认从4040端口开始,如果发现已经被绑定,那么会选择4041、4042等端口,以此类推。
这些信息默认情况下在作业运行期间有效,一旦作业完毕,driver进程以及对应的web ui服务也会停止。如果要在作业完成之后,也可以看到其Spark Web UI以及详细信息,需要启用Spark的History Server。
Spark History Web UI
- 创建日志储存目录
创建的目录hdfs://ip:port/dirName
命令hdfs dfs -mkidr /dirName - 修改
spark-defaults.confspark.eventLog.enabled true #启用 spark.eventLog.dir hdfs://ip:port/dirName spark.eventLog.compress true #压缩 - 修改
spark-env.shexport SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=50 -Dspark.history.fs.logDirectory=hdfs://ip:port/dirName"spark.eventLog.dir指定作业事件记录地址
spark.history.fs.logDirectory指定从哪个目录中去读取作业数据
两个目录地址要相同 - 启动HistoryServer
./sbin/start-history-server.sh在启动界面可以看到history-server的访问地址,通过访问地址打开History Web UI
RESTFUL API
提供了RESTFUL API来返回关于日志的json数据
| API | 含义 |
|---|---|
| /applications | 获取作业列表 |
| /applications/[app-id]/jobs | 指定作业的job列表 |
| /applications/[app-id]/jobs/[job-id] | 指定job的信息 |
| /applications/[app-id]/stages | 指定作业的stage列表 |
| /applications/[app-id]/stages/[stage-id] | 指定stage的所有attempt列表 |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id] | 指定stage attempt的信息 |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id]/taskSummary | 指定stage attempt所有task的metrics统计信息 |
| /applications/[app-id]/stages/[stage-id]/[stage-attempt-id]/taskList | 指定stage attempt的task列表 |
| /applications/[app-id]/executors | 指定作业的executor列表 |
| /applications/[app-id]/storage/rdd | 指定作业的持久化rdd列表 |
| /applications/[app-id]/storage/rdd/[rdd-id] | 指定持久化rdd的信息 |
| /applications/[app-id]/logs | 下载指定作业的所有日志的压缩包 |
| /applications/[app-id]/[attempt-id]/logs | 下载指定作业的某次attempt的所有日志的压缩包 |
eg:http://192.168.0.103:18080/api/v1/applications
作业资源调度
静态资源分配
- application并行:每个spark application都会运行自己独立的一批executor进程,用于运行task和存储数据,此时集群管理器会提供同时调度多个application的功能
- job并行:在每个spark application内部,多个job也可以并行执行
同时提交多个spark application
默认的作业间资源分配策略为静态资源分配,在这种方式下,每个作业都会被给予一个它能使用的 最大资源量的限额,并且可以在运行期间持有这些资源。这是spark standalone集群和YARN集群使用的默认方式。
-
Standalone集群
默认情况下,提交到standalone集群上的多个作业,会通过FIFO的方式来运行,每个作业都会尝试获取所有的资源。
spark.cores.max:限制每个作业能够使用的cpu core最大数量
spark.deploy.defaultCores:设置每个作业默认cpu core使用量
spark.executor.memory:设置每个作业最大内存。 -
YARN
--num-executors:配置作业可以在集群中分配到多少个executor
--executor-memory和--executor-cores可以控制每个executor能够使用的资源。
没有一种cluster manager可以提供多个作业间的内存共享功能,需要共享内存,可以单独使用一个服务(例如:alluxio),这样就能实现多应用访问同一个RDD的数据。
动态资源分配
当资源被分配给了一个作业,但资源有空闲,可以将资源还给cluster manager的资源池,被其他作业使用。在spark中,动态资源分配在executor粒度上被实现,启用时设置spark.dynamicAllocation.enabled为true,在每个节点上启动external shuffle service,并将spark.shuffle.service.enabled设为true。external shuffle service 的目的是在移除executor的时候,能够保留executor输出的shuffle文件。
申请策略
spark application会在它有pending(等待执行)的task等待被调度时,申请额外的executor
task已提交但等待调度->executor数量不足
- driver轮询式地申请executor
当在一定时间内spark.dynamicAllocation.schedulerBacklogTimeout有pending的task时,就会触发真正的executor申请 - 每隔一定时间后
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout,如果又有pending的task了,则再次触发申请操作。 - 每一轮申请到的executor数量采用指数级增加(比如1,2,4,8,..):采用指数级增长策略的原因有两个:
第一,对于任何一个Spark应用如果只需要多申请少数几个执行器的话,那么必须非常谨慎的启动资源申请,这和TCP慢启动有些类似;
第二,如果一旦Spark应用确实需要申请多个执行器的话,那么可以确保其所需的计算资源及时增长。
移除策略
一个spark作业会在它的executor出现了空闲超过一定时间后(spark.dynamicAllocation.executorIdleTimeout),被移除掉。
这意味着没有task被pending住,executor有空闲,和申请条件互斥。
保存中间状态
spark使用一个外部的shuffle服务来保存每个executor的中间写状态,这个服务是一个长时间运行的进程,集群的每个节点上都会运行一个,如果服务被启用,那么spark executor会在shuffle write和read时,将数据写入该服务,并从该服务获取数据。这意味着所有executor写的shuffle数据都可以在executor声明周期之外继续使用。
多了个中间数据存储角色,也改变了executor的读写方式
除了写shuffle文件,executor也会在内存或磁盘中持久化数据。当一个executor被移除掉时,所有缓存的数据都会消失。
shuffle服务写入的数据和executor持久化数据不是一个概念?executor移除后/挂掉后,其持久化的数据将消失,而shuffle服务保存的数据还将存在
standalone模式下动态资源分配
- 在worker启动前设置spark.shuffle.service.enabled为true
- application
--conf spark.dynamicAllocation.enabled=true \
Mesos模式下动态资源分配
- 在各个节点上运行
$SPARK_HOME/sbin/start-mesos-shuffle-service.sh,并设置spark.shuffle.service.enabled为true - application
--conf spark.dynamicAllocation.enabled=true \
yarn模式下动态资源分配
需要配置yarn的shuffle service(external shuffle service),用于保存executor的shuffle write文件,从而让executor可以被安全地移除.
- 添加jar包
将$SPARK_HOME/lib下的spark-<version>-yarn-shuffle.jar加入到所有NodeManager的classpath中,即hadoop/yarn/lib目录中 - 修改
yarn-site.xml<propert> <name>yarn.nodemanager.aux-services</name> <value>spark_shuffle</value> <!-- <value>mapreduce_shuffle</value> --> </property> <propert> <name>yarn.nodemanager.aux-services.spark_shuffle.class</name> <value>org.apache.spark.network.yarn.YarnShuffleService</value> </property> - 启动spark application
--conf spark.shuffle.service.enabled=true \ --conf spark.shuffle.service.port=7337 \ --conf spark.dynamicAllocation.enabled=true \
多个job调度
job是一个spark action操作触发的计算单元,在一个spark作业内部,多个并行的job是可以同时运行的 。
FIFO调度
默认情况下,spark的调度会使用FIFO的方式来调度多个job。每个job都会被划分为多个stage,而且第一个job会对所有可用的资源获取优先使用权,并且让它的stage的task去运行,然后第二个job再获取资源的使用权,以此类推
Fair调度
在公平的资源共享策略下,spark会将多个job的task使用一种轮询的方式来分配资源和执行,所以所有的job都有一个基本公平的机会去使用集群的资源
conf.set("spark.scheduler.mode", "FAIR")
--conf spark.scheduler.mode=FAIR
公平调度资源池
fair scheduler也支持将job分成多个组并放入多个池中,以及为每个池设置不同的调度优先级。这个feature对于将重要的和不重要的job隔离运行的情况非常有用,可以为重要的job分配一个池,并给予更高的优先级; 为不重要的job分配另一个池,并给予较低的优先级。
在代码中设置sparkContext.setLocalProperty("spark.scheduler.pool", "poolName"),所有在这个线程中提交的job都会进入这个池中,设置是以线程为单位保存的,很容易实现用同一线程来提交同一用户的所有作业到同一个资源池中。设置为null则清空池子。
默认情况下,每个池子都会对集群资源有相同的优先使用权,但是在每个池内,job会使用FIFO的模式来执行。
可以通过配置文件来修改池的属性
- schedulingMode: FIFO/FAIR,来控制池中的jobs是否要排队,或者是共享池中的资源
- weight: 控制资源池相对其他资源池,可以分配到资源的比例。默认情况下,所有池子的权重都是1.如果将某个资源池的 weight 设为 2,那么该资源池中的资源将是其他池子的2倍,如果将 weight 设得很高,如 1000,可以实现资源池之间的调度优先级 – weight=1000 的资源池总能立即启动其对应的作业。
- minShare: 每个资源池最小资源分配值(CPU 个数),公平调度器总是会尝试优先满足所有活跃(active)资源池的最小资源分配值,然后再根据各个池子的 weight 来分配剩下的资源。因此,minShare 属性能够确保每个资源池都能至少获得一定量的集群资源。minShare 的默认值是 0。
配置文件默认地址spark/conf/fairscheduler.xml,自定义文件conf.set("spark.scheduler.allocation.file", "/path/to/file")
<allocations>
<pool name="production">
<schedulingMode>FAIR</schedulingMode>
<weight>1</weight>
<minShare>2</minShare>
</pool>
<pool name="test">
<schedulingMode>FIFO</schedulingMode>
<weight>2</weight>
<minShare>3</minShare>
</pool>
</allocations>
没有在配置文件中配置的资源池都会使用默认配置(schedulingMode : FIFO,weight : 1,minShare : 0)。
Spark常用算子
union
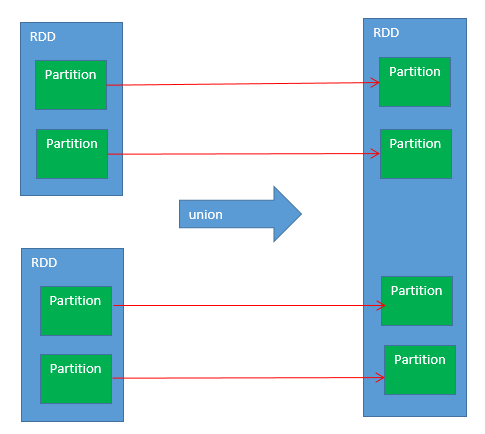
- 新的rdd,会将旧的两个rdd的partition,复制过去
- 新的rdd的partition的数量,就是旧的两个rdd的partition的数量之和
groupByKey
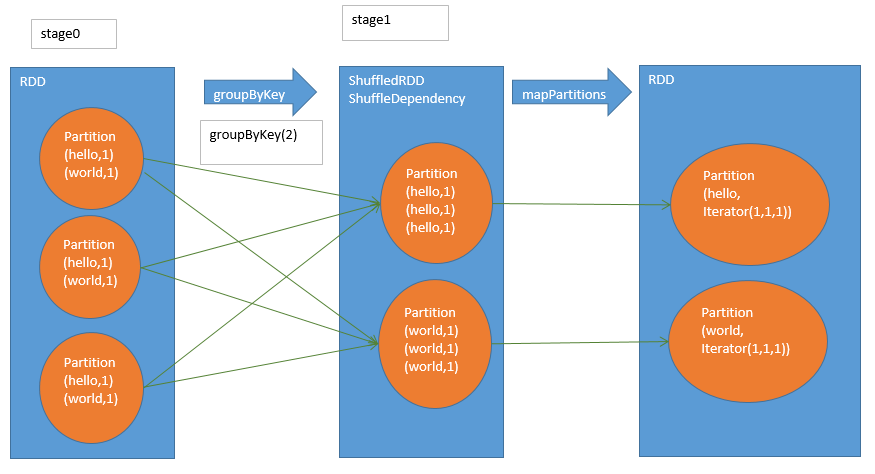
reduceByKey
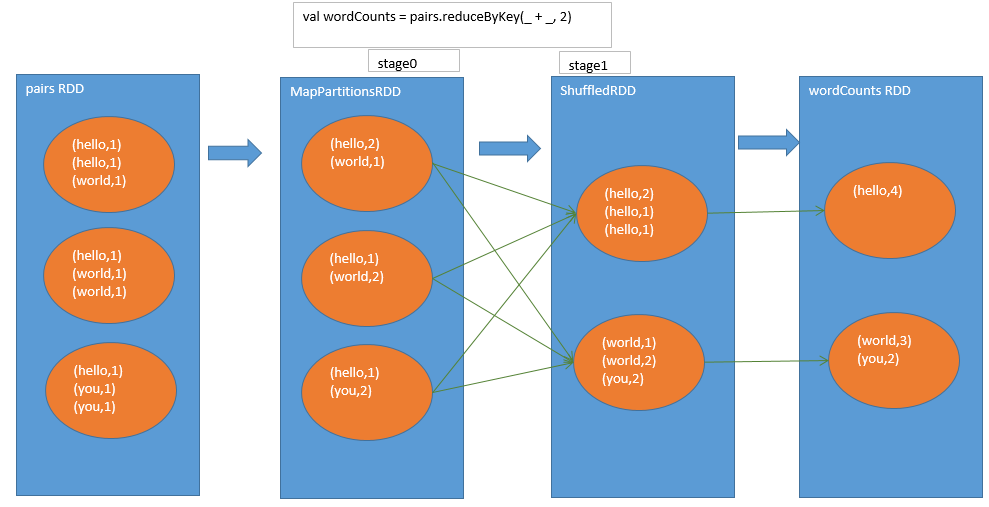
-
不同之处
reduceByKey,中间多了一个MapPartitionsRDD,是本地数据聚合后的rdd,可以减少网络数据传输。 -
相同之处
read和聚合的过程基本和groupByKey类似。都是ShuffledRDD做shuffle read再聚合,得到最终的rdd
distinct
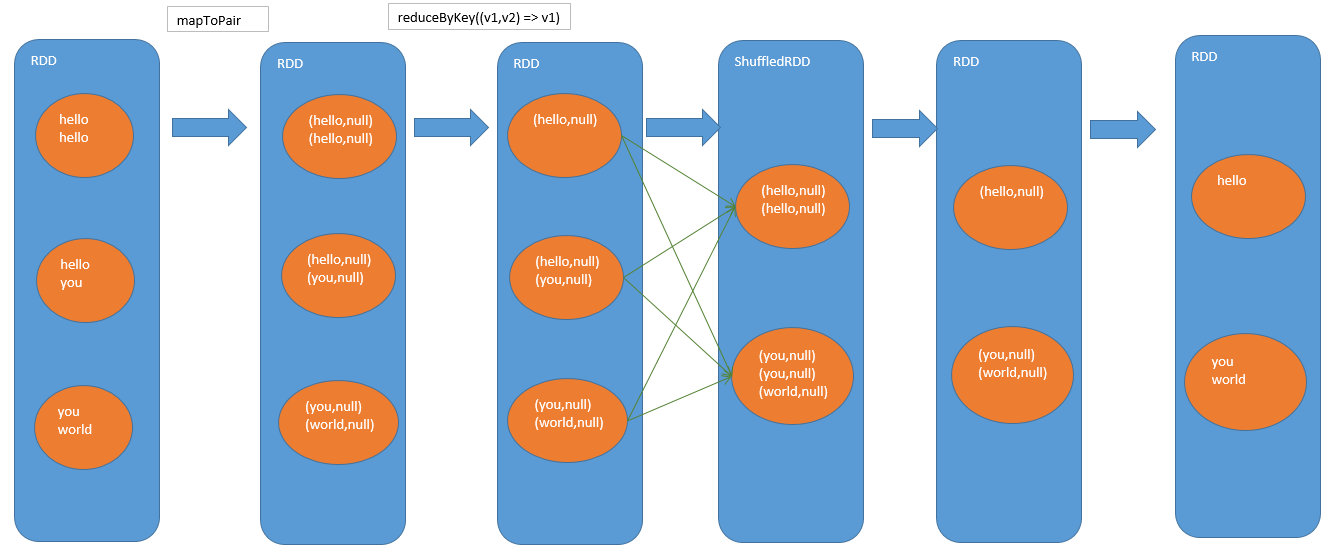
- 将每个原始值转换成tuple
- 会进行本地聚合(类似reduceByKey)
- 最后会将tuple转换回单值
cogroup
cogroup算子是其他算子的基础,如join,intersection操作
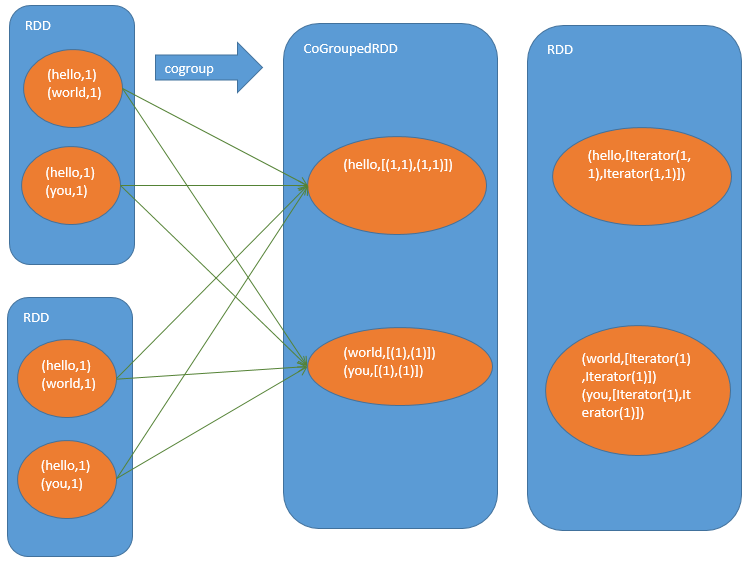
先按RDD分区聚合结果,(hello,[(1,1),(1,1)]):第1个(1,1)是第一个RDD 的helo聚合结果,第二个(1,1)是第2个RDD聚合结果 若第一个RDD的第一个partition没有hello,则(1),不是(,1)
intersection
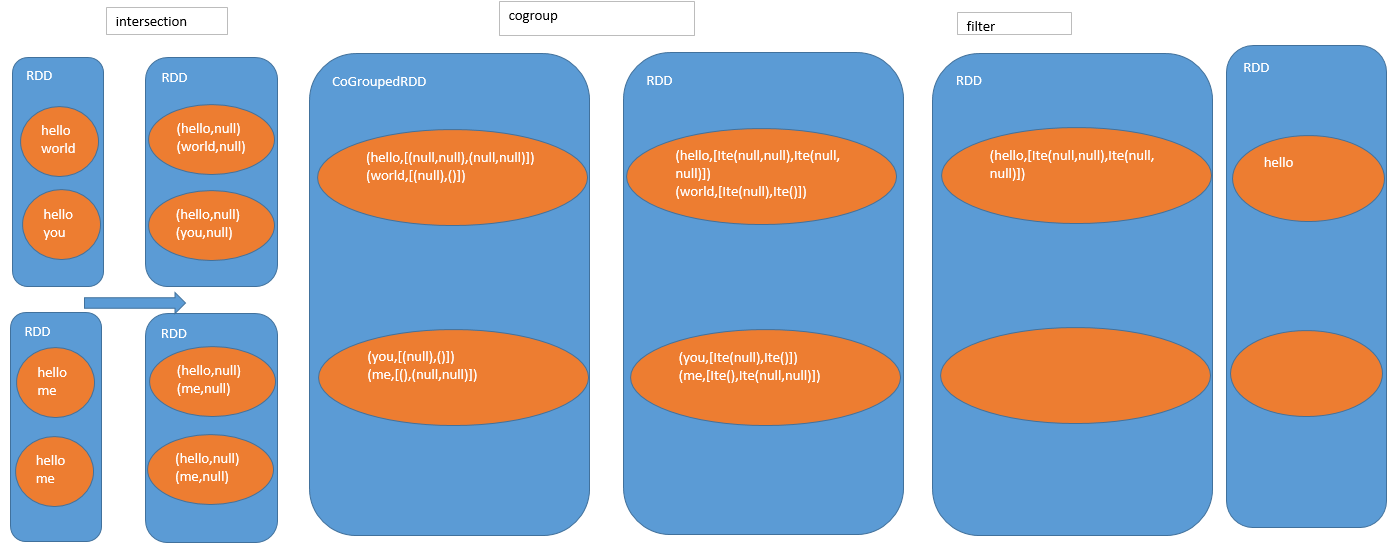
filter:过滤掉两个集合中任意一个集合为空的key
join
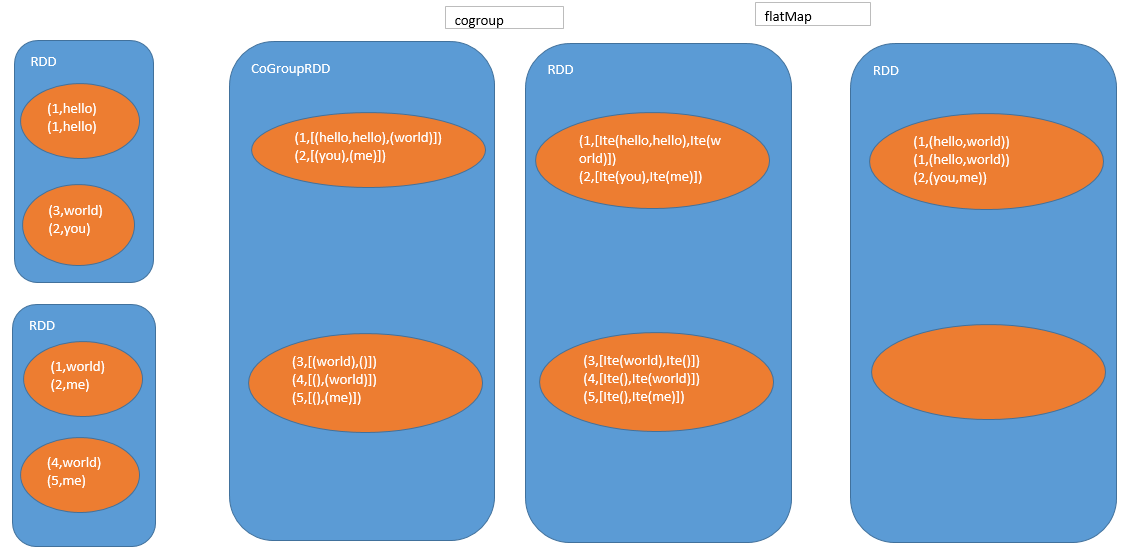
- cogroup,聚合两个rdd的key
- flatMap,聚合后的每条数据,都可能返回多条数据 将每个key对应的两个集合的所有元素,做了一个笛卡尔积
sortByKey
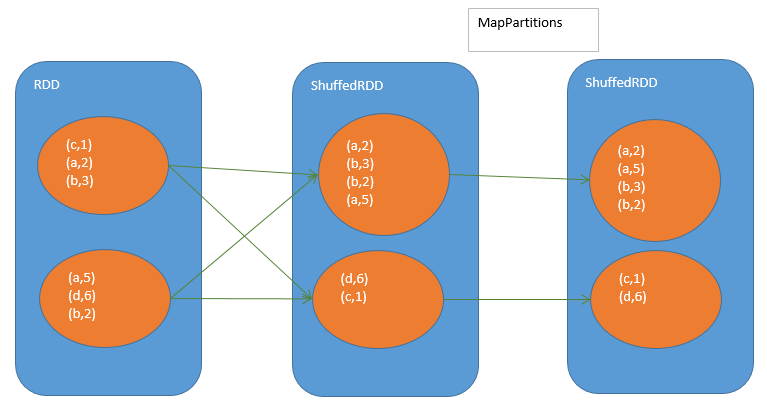
- ShuffledRDD,做shuffle read,将相同的key拉到一个http://ozijnir4t.bkt.clouddn.com/spark/learning/sortByKey.pngpartition中来
- mapPartitions,对每个partitions内的key进行全局的排序
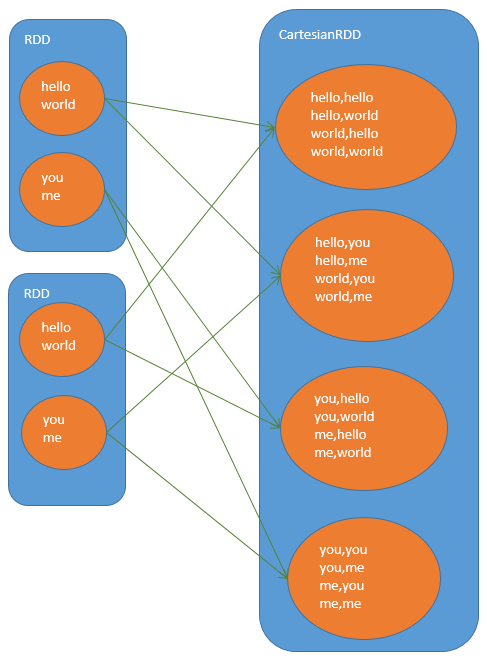
cartesian
笛卡尔乘积
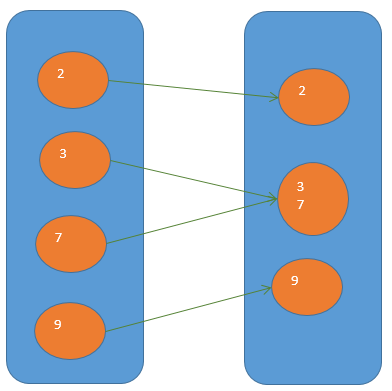
coalesce
一般用于减少partition数量
repartition
repartition算子=coalesce(true)
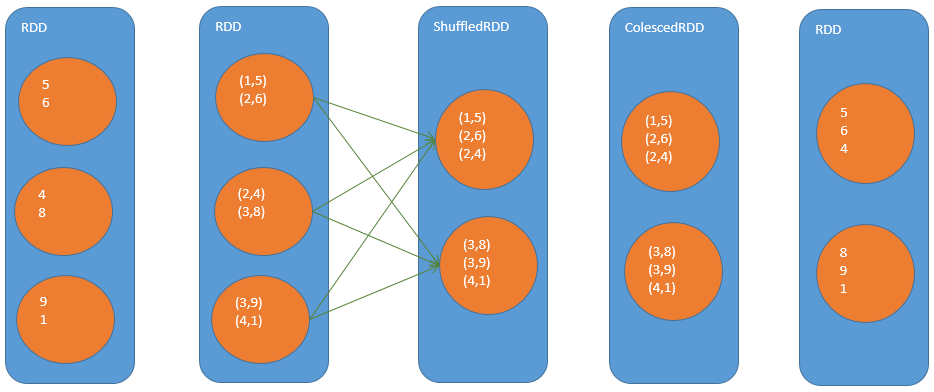
repartition操作在中间生成的隐式RDD中会给值计算出前缀作为key,在最后做Shuffle操作时一个partition就放特定的一些key值对应的tuple,完成重分区操作
知识点
Spark集群中的节点个数、RDD分区个数、cpu内核个数三者与并行度的关系
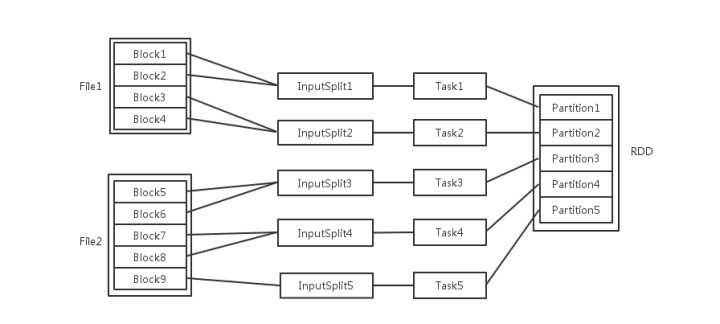
- 每个file包含多个block
- Spark读取输入文件时,会根据具体数据格式对应的InputFormat进行解析,一般是将若干个Block合并成一个输入分片,称为InputSplit,注意InputSplit不能跨越文件
- 一个InputSplit生成一个task
- 每个Executor由若干core组成,每个Executor的每个core一次只能执行一个Task
- 每个Task执行后生成了目标RDD的一个partiton
如果partition的数量多,能起实例的资源也多,那自然并发度就多
如果partition数量少,资源很多,则task数量不足,它也不会有很多并发
如果partition的数量很多,但是资源少(如core),那么并发也不大,会算完一批再继续起下一批
Task被执行的并发度 = Executor数目 * 每个Executor核数
这里的core是虚拟的core而不是机器的物理CPU核,可以理解为就是Executor的一个工作线程?
每个executor的core数目通过spark.executor.cores参数设置。这里的cores其实是指的工作线程。cpu info里看到的核数是物理核(或者一般机器开了超线程以后是的物理核数*2),和spark里的core不是一个概念,但是一般来说spark作业配置的executor核数不应该超过机器的物理核数。
partition的数目
- 数据读入阶段,如
sc.textFile,输入文件被划分为多少InputSplit就会需要多少初始Task - Map阶段partition数目保持不变
- Reduce阶段,RDD的聚合会触发shuffle操作,聚合后的RDD的partition数目跟具体操作有关,例如repartition操作会聚合成指定分区数,还有一些算子是可配置的
