

前言
正则表达式是软件领域为数不多的伟大创作。与之相提并论是分组交换网络、Web、Lisp、哈希算法、UNIX、编译技术、关系模型、面向对象等。正则自身简单、优美、功能强大、妙用无穷。
学习正则表达式,语法并不难,稍微看些例子,多可照葫芦画瓢。但三两篇快餐文章,鲜能理解深刻。再遇又需一番查找,竹篮打水一场空。不止正则,其他技术点同样,需要系统的学习。多读经典书籍,站在巨人肩膀前行。
本文前半部分复述正则基础知识,覆盖常见功能结构;次节探讨正则匹配原理、解决思路、常用优化。为避免泛泛而谈、自以为是,文中理论示例,多引用《精通正则表达式》 等相关书籍。能力有限,边学边悟,不求哗众取宠,但求实实在在。
第一章 正则基础
正则表达式严谨来讲,是一种描述字符串结构模式的形式化表达方法。起始于数学领域,流行于 Perl 正则引擎。JavaScript 从 ES 3 引入正则表达式,ES 6 扩展对正则表达式支持。
字符组
顾名思义,字符组是一组字符,表示在同一位置可能出现的多种字符。语法是在方括号 [ ] 之间列出可能出现的字符。字符组支持 - 范围表示法、^ 排除型字符组。
范围表示法中,范围一般由字符对应码值确定,码值小的字符在前,码值大的字符在后(参考ASCII、Unicode码表)。排除型字符组表示,匹配除[ ]中之外的任意字符,注意仍然需要匹配一个字符。示例如下。
| 字符组 | 含义 |
|---|---|
| [ab] | 匹配 a 或 b |
| [0-9] | 匹配 0 或 1 或 2 ... 或 9 |
| [^ab] | 匹配 除 a、b 任意字符 |
对于常见 [0-9]、[a-z] 等字符组,正则表达式提供简记形式。
| 字符组 | 含义 |
|---|---|
| \d | 表示 [0-9],数字字符 |
| \D | 表示 [^0-9],非数字字符 |
| \w | 表示 [_0-9a-zA-Z],单词字符,注意下划线 |
| \W | 表示 [^_0-9a-zA-Z],非单词字符 |
| \s | 表示 [ \t\v\n\r\f],空白符 |
| \S | 表示 [^ \t\v\n\r\f],非空白符 |
| . | 表示 [^\n\r\u2028\u2029]。通配符,匹配除换行符、回车符、行分隔符、段分隔符外任意字符 |
注意上述 \d、\w、\s 匹配规则,是针对 ASCII 编码而言。对于 Unicode 字符匹配,参照 ES6扩展 段落。
量词
量词也称重复,可以匹配固定或非固定长度字符。其常见形式是 {m,n},注意逗号之后绝不能有空格,表示连续出现最少 m 次,最多 n 次。
量词又可分为,匹配优先量词(贪婪量词)、忽略优先量词(惰性量词)。对于不确定是否要匹配时,匹配优先量词会尝试匹配,忽略量词则选择不匹配。
示例如下,贪婪正则匹配 abc, 惰性正则匹配 a 字符。
const greedyRe = /\w+/
const lazyRe = /\w+?/
greedyRe.exec('abc')
lazyRe.exec('abc')
常见量词形式:
| 匹配优先量词 | 忽略优先量词 | 含义 |
|---|---|---|
| {m,n} | {m,n}? | 表示至少出现 m 次,至多 n 次 |
| {m,} | {m,}? | 表示至少出现 m 次 |
| {m} | {m}? | 表示必须出现 m 次,等价 {m,m} |
| ? | ?? | 等价 {0,1} |
| + | +? | 等价 {1,} |
| * | *? | 等价 {0,} |
这里需要注意,. 能匹配几乎所有字符,而 * 表示可以为任意数目,.* 通常用来表示一组任何字符。如果正则中使用 .*,而又不真正了解其中原理,就有可能事与愿违。关于 .* 问题,则匹配原理章节后有详细讨论。
括号
括号在正则中主要有三种用途:分组,将相关的元素归拢,构成单个元素;多选结构,(...|...),规定可能出现的多个子表达式;引用分组,存储子表达式匹配文本,供之后引用。
分组与多选显而易见,对于引用分组会存在两种情形:在 JS API 里引用,在正则表达式里引用。前者可通过 $数字 提取相应顺序分组,后者通过 \数字 形式引用,即反向引用。注意引用不存在的分组时,正则不会报错,只是匹配反向引用字符本身。例如 \2 就是匹配 "\2", "\2" 表示对 "2" 进行转义。
示例,将 yyyy-mm-dd 时间,替换 mm/dd/yyyy 格式。
const re = /(\d{4})-(\d{2})-(\d{2})/
const str = '2018-01-12'
const result = str.replace(re, '$2/$3/$1')
console.log(result)
// => '01/12/2018'
示例,利用反向引用匹配成对标签,如<h1>title</h1>。(注:未考虑标签属性和标签嵌套情形)
const re = /<([a-zA-Z0-9]+)>.*?<\/\1>/
const str = '<h1>title</h1>'
const result = re.test(str)
console.log(result)
// => true
事实上,正则表达式只要出现括号,在匹配时就会把括号内的子表达式存储起来提供引用。如果不需要引用,保存数据无疑会影响性能。正则表达式提供 非捕获分组(non-capturing group)。类似于普通捕获分组,只是在开括号后紧跟问号和冒号 (?:...)。
锚点与断言
正则表达式中有些结构并不真正匹配文本,只负责判断在某个位置左/右侧的文本是否符合要求,被称为锚点。常见锚点有三类:行起始/结束位置、单词边界、环视。在 ES5 中共有 6 个锚点。
| 锚点 | 含义 |
|---|---|
| ^ | 匹配开头,多行匹配中匹配行开头 |
| $ | 匹配结尾,多行匹配中匹配行结尾 |
| \b | 单词边界,\w 与 \W 之间位置 |
| \B | 非单词边界 |
| (?=p) | 该位置后面字符要匹配 p |
| (?!p) | 该位置后面字符不匹配 p |
需要注意,\b 也包括 \w 与 ^ 之间的位置,以及 \w 与 $ 之间的位置。如图所示。
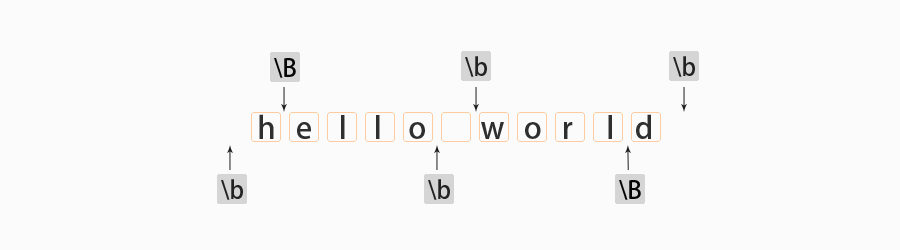
(?=...) 和 (?!...) 分别表示肯定顺序环视(positive lookahead)和否定顺序环视(negative lookahead),也有翻译为正向先行断言和负向先行断言。比如 (?=p) 可以理解成,接下来的字符与 p 匹配,但不包括 p 匹配的字符。
看个典型示例,数字千位添加分隔符。比如把 "12345678" 变成 "12,345,678"。简单分析可得出,插入位置必须满足: “左边有数字,右边数字的个数正好是3的倍数”。前者用否定顺序环视避免开头位置,后者可用肯定顺序环视判断。
const re = /(?!^)(?=(\d{3})+$)/g
const str = '123456789'
const result = str.replace(re, ',')
console.log(result)
// => '123,456,789'
修饰符
修饰符是指匹配时使用的模式规则。ES5 中存在三种匹配模式:忽略大小写模式、多行模式、全局匹配模式,对应修饰符如下。
| 修饰符 | 含义 |
|---|---|
| i | 不区分大小写匹配 |
| m | 允许匹配多行 |
| g | 执行全局匹配 |
更多修饰符细节,多行匹配模式,^ 匹配一行的开头和字符串的开头,$ 匹配行的结束和字符串的结束。全局模式,需要找到所有的匹配项,而不是找到第一个后就停止。
ES6扩展
ES6 中正则表达式添加 u 修饰符,含义为 “Unicode 模式”,用来正确处理大于 \uFFFF 的 Unicode 字符。也就是可以处理 4 个字节的 UTF-16 编码。
/^\uD83D/u.test('\uD83D\uDC2A')
// => false
/^\uD83D/.test('\uD83D\uDC2A')
// => true
除了 u 修饰符,ES6 还添加 y 修饰符,叫作 “粘连”(sticky)修饰符。y 也是全局匹配,但会确保匹配必须从剩余第一个位置开始。
const s = 'aaa_aa_a'
const r1 = /a+/g
const r2 = /a+/y
r1.exec(s) // ['aaa']
r2.exec(s) // ['aaa']
r1.exec(s) // ['aa']
r2.exec(s) // null
上述在第二次执行,g 修饰符没有位置要求,会返回匹配结果。而 y 修饰符要求匹配必须从头部开始,所以返回 null。将正则表达式修改为 /a+_/y,y 修饰符会返回结果。
ES 规范中也有对 后行断言 和 具名分组的提案。详细可参考《ES6 标准入门》第5章。
经典示例
验证密码问题
密码格式要求,长度 6-12 位,由数字、小写字母和大写字母组成,但必须至少包括 2 种字符。如果写成多个正则来判断,比较容易,单一正则较为麻烦。为节约篇幅,笔者简短描述解法。
首先判断长度 6-12 位的三种字符,可用 [0-9a-zA-Z]{6,12} 判断。至少包括 2 种字符,可以具体分为大小写字母、数字与小写字母、数字与大写字母三种情形。要求必须包含某类字符,可以使用环视 (?=...) 来描述。比如同时包含数字和小写字母,可用 (?=.*[0-9])(?=.*[a-z]) 判断。相应判断多种情况,得到正则如下。
/((?=.*[0-9])(?=.*[a-z])|(?=.*[0-9])(?=.*[A-Z])|(?=.*[a-z])(?=.*[A-Z]))^[0-9A-Za-z]{6,12}$/
另一种解法,至少包括两种字符,也就是不能全部都是数字,不能全部都是小写字母,也不能全部都是大写字母。要求 “不能全部都是数字” 可用顺序否定环视,(?!^[0-9]{6-12}$)。完整正则如下。
/(?!^[0-9]{6,12}$)(?!^[a-z]{6,12}$)(?!^[A-Z]{6,12}$)^[0-9A-Za-z]{6,12}$/
去除文本首尾空白字符
去除文本首尾空白字符,最简单也是效率最高的方式是使用两条正则替换,/^\s+/ 和 /\s+$/。当然也可通过一条正则表达式解决问题,不过效率会有不同。下文列出三两条作为示例。
const str = ' hello world '
// 解法 0:两次替换方式
str.replace(/^\s+/, '').replace(/\s+$/, '')
// 解法 1:使用全局匹配
str.replace(/^\s+|\s$/g, '')
// 解法 2:使用惰性量词
str.replace(/\s*(.*?)\s*$/, '$1')
// 解法 3:使用贪婪量词
str.replace(/^\s*((?:.*\S)?)\s*$/, '$1')
日期字符匹配
以 yyyy-mm-dd 为例,如 “2017-01-17”。时间匹配需要注意的是数据取值范围:月份只能在 0-12 之间,正则为 (0?[1-9]|1[012]);日期一般在 0-31 之间,正则为 (0?[1-9]|[12][0-9]|3[01]);年份多无限制,\d{4} 即可。完整正则如下:。
/\d{4}-(0?[1-9]|1[012])-(0?[1-9]|[12][0-9]|3[01])/
匹配路径
文件路径区分系统,UNIX 路径 和 Windows 路径。UNIX 路径示例:“/usr/local”,“/usr/bin/node” 。
这里需要注意的地方是,文件或目录名不能包含 “\ / : * % < > | " ?” 、换行符空字符,所以匹配文件名的表达式是 [^\\/:*%<>|"?\r\n]。路径内部所有目录名之后必须有 “/”,所以可以用 [^\\/:*%<>|"?\r\n]+/ 匹配。末尾如果是目录,可能以 “/” 结尾,最后部分为 [^\\/:*%<>|"?\r\n]+/?。注意 “/” 字符需要转移,完整正则字面量如下。
/\/([^\/:*%<>|"?\r\n]+\/)*[^\/:*%<>|"?\r\n]+\/?/
Windows路径匹配与上同理,开头需要匹配 “盘符:\”,文件名中不能包含 “\ / : * < > | " ? \n \r” 字符。Windows 路径名称示例 “C:\book\regular.pdf”,完整正则如下。
/[a-zA-Z]:\\([^\/:*<>|"?\r\n]+\\)*[^\/:*<>|"?\r\n]+\\?/
匹配URL
相对来说,匹配URL的表达式比较复杂,主机名、路径名、参数等部分都有复杂的规范。这里给出一个相对简单的正则示例。
/(https?|ftp):\/\/[^/?:]+(:[0-9]{1-5})?(\/?|(\/[^/]+)*(\?[^\s"']+)?)/
最开始是协议名,可能是 http、https、ftp。然后匹配 “:\”;主机名使用相对简单的 [^/?:]+ 匹配,然后用 (:[0-9]{1,5})? 匹配可能出现的端口部分(端口最大为65536,简要规定为 5 位数字)。URL 还可能包含路径以及参数,分别用 (/[^/]+)* 和 (\?[^\s"']+)? 匹配。
匹配成对的HTML Tag
比如匹配 <h3>regular expression</h3> 字符串。最常见的办法就是用 <[^>]+> 匹配 HTML 标签。如果 tag 中含有 “>” 就不能正常匹配了,例如 <input value=">">,当然这种情况也很少见。
面对上述情况,可以区分情形。“<...>” 中允许出现引号文本和非引号文本(除 “>” 和 引号之外的任意字符 )。HTML引文可以用单引号,也可以用双引号,可用 ("[^"]*"|'[^']'*|[^'">]) 来匹配除 Tag 名称以外字符。
对于 HTML 标签名称,第一个字符必须是 [a-z]。为匹配完整匹配标签名称,用肯定顺序环视 (?=[\s>]) 保证它之后是空白字符或 “>”。完整表达式如下。
/<([a-z][a-z0-9]*)(?=[\s>])('[^']*'|"[^"]*"|[^'">])*>.*?<\/\1>/
再多说两句,上述正则表达式并不支持标签嵌套情形。例如目标字符串 <h1>hello<h1>world</h1></h1>,实际匹配字符为 <h1>hello<h1>world</h1>。本质上是因为正则表达式无法匹配任意深度的嵌套结构。
第二章 正则原理
对于固定字符串的处理,简单的字符串匹配算法(类KMP算法)相较更快;但如果进行复杂多变的字符处理,正则表达式速度则更胜一筹。那正则表达式具体匹配原理是什么?打破砂锅问到底,接下来一探究竟。注意后文会涉及编译原理相关知识,笔者尽量简短浅显描述,如想了解更多可参考文末资料。
有穷自动机
正则表达式引擎实现采用一种特殊理论模型:有穷自动机(Finite Automata)也叫有限状态自动机(finite-state machine)。这种模型具有有限个状态,可以根据不同条件在状态之间转移。映射到正则场景,引擎首先根据表达式生成自动机,而后根据输入字符串在状态之间游走,判断是否匹配。
以正则表达式 a(bb)+a 为例,对应有限状态自动机如下。
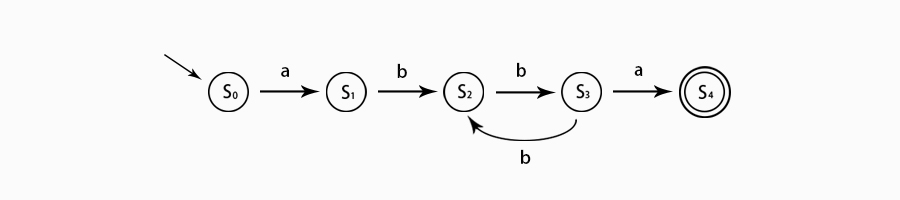
上图有穷自动机中,S0、S1、...、S4是各个状态,S0为开始状态,S4为最终状态;状态转移过程为:当前状态S0,输入字符a,则转移到S1,如果输入不是a,那么直接退出。自动机对字符串 abbbba 匹配流程如下。
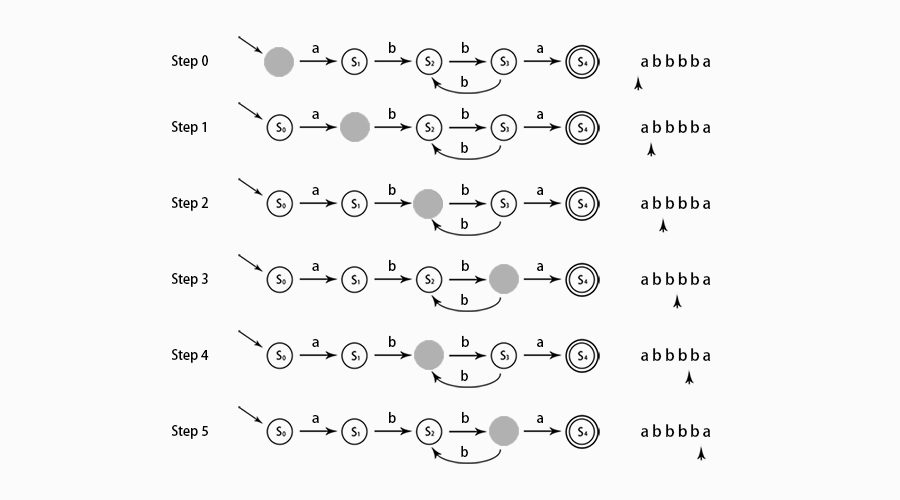
同一个正则表达式对应的有穷自动机不止一台,这些有穷自动机是等价的。正则表达式 a(bb)+a 对应的所有等价自动机如图。
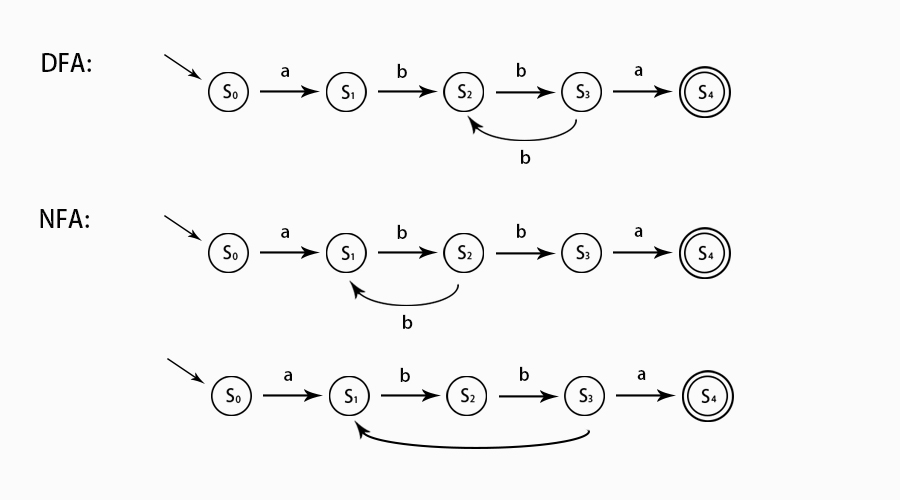
根据状态的确定与否,可以将自动机(正则引擎)分为两类:一类是确定型有穷自动机(Definite Finite Automata 简DFA),任何时候所处的状态都是确定的;另一种是非确定性有穷自动机(Non-definite Finite Automata 简称NFA),即某个时刻自动机所处状态是不确定的。如上图 NFA 第一个示例,输入 ab 之后再输入 b,此时所处状态是不确定的,可能在 S1,也可能在 S3。
实际上,大多数程序都采用 NFA 引擎,其中也包括 JavaScript。这是为什么呢?从正则表达式出发,构建 NFA 的难度要小于 DFA,构建 NFA 的时间更短;再有 NFA 在某一时刻状态不唯一,这决定在匹配过程中需要保存可能的状态,相比之下 DFA 状态是唯一确定的。故NFA 具有很多 DFA 无法提供的功能,比如捕获分组 (...),反向引用 \num,环视功能 (?=),惰性量词 +?、*?等。后文讨论情形也限于 NFA 引擎。
回溯
讨论匹配原理,永远绕不过去 “回溯”。NFA 匹配时,正则引擎并不确定当前状态,只能将所有可能状态保存,逐一尝试。当一条路走不通时,回溯到先前状态,选择其他状态再次尝试,如此以往,直到最终完成状态。不难发现,回溯的过程本质是深度优先搜索。
以正则表达式 /".*"/ 为例,字符串 "hello" 匹配过程如下。
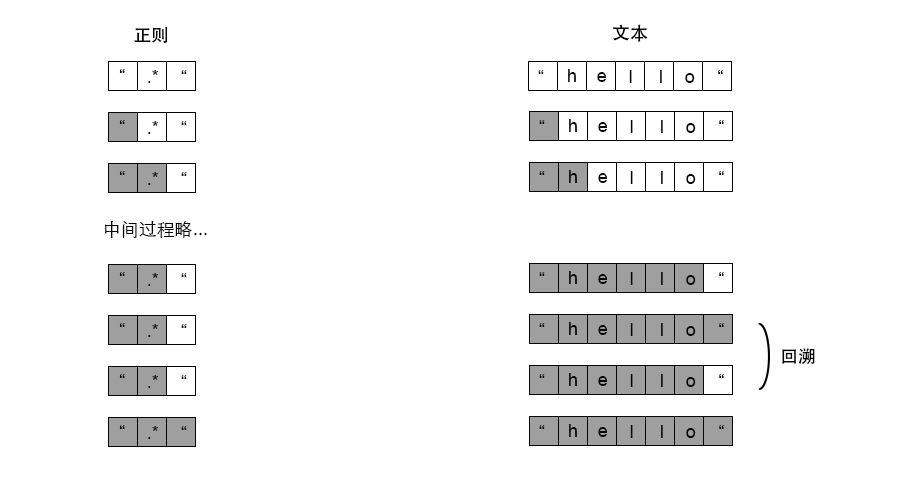
从图中可以看出,在匹配过程中 .* 曾经匹配 hello",但为了保证表达式最后一个 " 匹配,不得不回退先前状态。这种 “尝试失败-重新选择” 的过程就是回溯。假如将字符串变为 "hello" world ,回溯次数又将会增加。.* 会优先尝试匹配剩余 hello" world 字符串,而后不断回溯。
常见回溯形式
造成回溯主要缘由是 NFA 不能确定当前状态,需要不断尝试前进回溯。常见非确定状态形式有:贪婪量词、惰性量词、分支结构情形。
贪婪量词
上面的示例其实是贪婪量词相关,比如 /".*"/ ,对于非确定状态会优先选择匹配。虽然局部匹配是贪婪的,但也要满足整体正确匹配。皮之不存,毛将焉附之理。
惰性量词
惰性量词语法上是在贪婪量词之后加个问号。表示在满足条件情况下,尽可能少的匹配。虽然惰性量词不贪,但有时也会出现回溯现象。看个示例。
/^\d+?\d{1,3}$/
对于目标字符串 “12345”,我们很容易能理解:\d+? 首先仅会匹配一个字符,但后续 \d{1,3}$ 最多只能匹配三个字符,此时 $ 并不能匹配结尾,当前匹配失败。后续回溯使 \d+? 匹配两字符,从而整体匹配。
分支结构
分支结构在 JavaScript 中也是惰性的,比如 /Java|JavaScript/,匹配 JavaScript 字符串时,得到的结果是 Java。引擎会优先选择最左端的匹配结果。
分支结构可能前面的子模式形成局部匹配,如果后面表达式整体不匹配时,仍然会尝试剩下的分支。相应这种尝试也可看成一种回溯。
滥用 .* 问题
. 几乎能匹配任何字符,而 * 又表示 “匹配优先”,所以 .* 经常匹配到文本末尾。当需要整体模式匹配时,只能不断回溯 “交还” 字符串。但有时会出现问题,看个示例。
const re = /".*"/
const str = 'The great "pleasure" in "life" is doing what people say you cannot do'
const result = re.exec(str)
console.log(result[0])
// => "pleasure" in "life"
了解匹配原理之后,结果也就显而易见。.* 会一直匹配到字符串末尾,为了最后双引号能够匹配,.* 不断交还字符直到全局匹配。但这并不是我们期望的结果,那如何获得 "pleasure" 字符串?
关键点在于,我们希望匹配的不是双引号之间的“任何”文本,而是“除双引号以外的任何文本”。如果用 [^"]* 取代 .*,就不会出现上面问题。
再看多字符引文问题,匹配 <b>love</b> is <b>love</b> 标签 b 中内容。与双引号字符串例子相似,使用 <b>.*</b> 会匹配全部字符串。假如仅匹配开头 b 标签,<b>[^</b>]*</b> "排除型字符组"正则显然不可行。字符组仅排除包括单个字符,而不是一组字符。
解决问题方式有,使用惰性量词。<b>.*?</b> 正则中 .*? 结构对于可匹配字符优先忽略。但假如字符串变为 “<b>love is <b>love</b></b>”,此时上述正则会匹配 “<b>love is <b>love</b>”,可见惰性量词并不是排除类的完美解决方式。
更优方式,使用排除环视,比如 (?!</b>) 表示只有 “</b>” 不在字符串中当前位置时才能成功。把点号替换为 ((?!</?b>).) 得到正则表达式如下:
/<b>((?!</?b>).)*</b>/
有序多选结构陷阱
有序多选分支结构容许使用者控制期望的匹配,但也有时也会不明就里出些问题。假如需要匹配 “Jan 31” 之类的日期,首先需要将日期部分拆开。用 0?[1-9] 匹配可能以 0 开头的前九天,用 [12][0-9] 处理十号到二十九号,用 3[01] 处理最后两天。连接起来就是。
/Jan (0?[1-9]|[12][0-9]|3[01])/
但假如以上述表达式匹配 “Jan 31”,有序多选分支只会捕获 “Jan 3”。其实这里主要是因为,引擎是以优先选择最左端的匹配结果为原则。(0?[1-9]) 分支可以匹配 3,后续分支不会继续尝试。
需要重新安排多选结构的顺序,把能够匹配的数字最短的放到最后:Jan ([12][0-9]|3[0-1]|0?[1-9])。通过示例可以看到,如果多选分支是有序的,而能够匹配同样文本的分支不止一个,就要小心安排多选分支的先后顺序。
避免“指数级”匹配
举个简短栗子,假如存在正则表达式 ([^\\"]+)*,匹配非引号非转义字符(详情见《精通正则表达式》P227)。目标字符串 makudonarudo ,星号可能会迭代 12 次,每次迭代中 [^\\"] 匹配一个字符,星号还可能迭代 11 次,前 11次 迭代中 [^\\"] 匹配一个字符,最后匹配两个字符,或者 10、9、8 次等等。
多个量词修饰同一分组,间接相当于指数级匹配时间复杂度。上例中,长度为 12 的字符串存在 4096 种可能(2的12次方)。除DFA 和 传统型NFA 引擎外,还有一种 POSIX NFA 引擎。其和传统型NFA引擎主要差别在于,传统型NFA在遇到第一个完整匹配时会停止。而 POSIX NFA 会尝试匹配所有情形,寻找最长匹配字符。并且不难想象,如果没有完整匹配,即使传统型NFA也需要尝试所有可能。所以尽可能避免 *、+ 量词嵌套情形。
如何从表达式角度避免指数级匹配,内容较为复杂,牺牲可读性和可维护性。笔者这里不再搬运文字,详情可阅读《精通正则表达式》P261,消除循环章节。
常识性优化措施
-
使用非捕获型括号
如果不需要引用括号内文本,请使用非捕获型括号
(?:...)。这样不但能够节省捕获的时间,而且会减少回溯使用的状态数量。 -
消除不必要括号
非必要括号有时会阻止引擎优化。比如,除非需要知道
.*匹配的最后一个字符,否则请不要使用(.)*。 -
不要滥用字符组
避免单个字符的字符组。例如
[.]或[*],可以通过转义转换为\.和\*\。 -
使用起始锚点
除非特殊情况,否则以
.*开头的正则表达式都应该在最前面添加^。如果表达式在字符串的开头不能匹配,显然在其他位置也不能匹配。 -
从量词中提取必须元素
用
xx*替代x+能够保留匹配必须的 “x”。同样道理,-{5,7}可以写作-----{0,2}。 -
提取多选结构开头的必须元素
用
th(?:is|at)替代(?:this|that),就能暴露除必须的 “th”。 -
忽略优先还是匹配优先?
通常,使用忽略优先量词(惰性)还是匹配优先量词(贪婪)取决于正则表达式的具体需求。举例来说,
/^.*:/不同于^.*?:,因为前者匹配到最后的冒号,而后者匹配到第一个冒号。总的来说,如果目标字符串很长,冒号会比较接近字符串的开头,就是用忽略优先。如果在接近字符串末尾位置,就是用匹配优先量词。 -
拆分正则表达式
有时候,应用多个小正则表达式的速度比单个正则要快的多。“大而全”的正则表达式必须在目标文本中的每个位置测试所有表达式,效率较为低下。典型例子可以参考前文, 去除字符串开头和结尾空白。
-
将最可能匹配的多选分支放在前头
多选分支的摆放顺序非常重要,上文有提及。总的来说,将常见匹配分支前置,有可能获得更迅速更常见的匹配。
-
避免指数级匹配
从正则表达式角度避免指数级匹配,应尽可能减少
+ *量词叠加,比如([^\\"]+)*。从而减少可能匹配情形,加快匹配速度。
这里简述的仅是常见优化措施,当然在提高匹配效率时也需要平衡正则表达式的可读性。不仅是效率,假如编写正则表达式晦涩难懂,维护成本相应会也加重。正则表达式可读性、可维护性也是很重要的一方面。
正则引擎
本节整体描述从正则表达式到DNA的构建过程。限于笔者本身能力有限,在此仅简单描述正则编译流程,以及过程中用到的算法数据结构。具体细节,笔者也未曾实践,就不再信口胡言。下文主要参考 编译原理 课程视频。
简短回顾正则引擎工作流程,接受一条声明式的规范(正则表达式),通过词法分析自动生成器,生成词法分析代码。如下图所示,自动生成器将正则表达式变成 NFA,再转换成 DFA 数据结构(DFA引擎),再到词法分析算法代码。
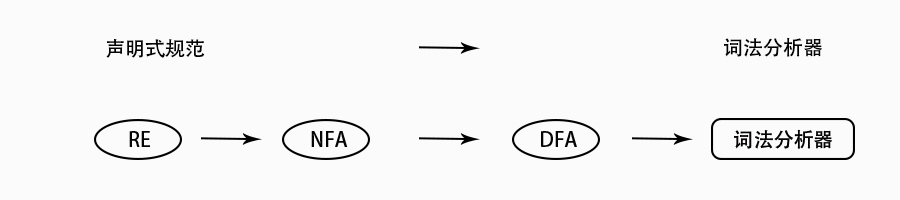
RE转换NFA,从正则表达式到非确定有限状态自动机,主要采用 Thompson 算法。Thompson算法基于对正则表达式的结构做归纳,对基本的RE 直接构造,对复合的 RE 递归构造。递归算法,比较容易实现。
NFA转换DFA,从非确定有限状态自动机到确定有限状态自动机,主要采用 子集构造算法。DFA最小化,目的希望DFA尽可能小,效率尽可能高。一般采用 Hopcroft 最小化算法。
结语
正则表达式尤其复杂规则,初看头昏脑涨。不过熟悉基本结构,拆分不同模块,也就慢慢理解。
啰里啰嗦,拙文一篇。看完书记录下,希望时间匆匆而过,回首有可回味之地。此篇文章以笔者目前功力,写起来有些赶鸭子上架强人所难。但愧知识短浅,诚恐贻笑大方。不过另一方面来说,不断挑战自我,逃离舒适区,也算是一种成长。
多说几句,近来发现自己,一起笔就有种老气横秋的赶脚。用老话说,少年不识愁滋味,为赋新词强说愁。这可能与笔者的性格有关,不喜闹,偏安静。每篇文章竭尽向正经八股文靠拢,不希望文字中透露幼稚气。文章自己慢慢读来,也会发现有些地方不自然,刻意为之,后续尽量提高。
笔者能力有限,行文难免有所疏忽,如有误导,敬请斧正。
参考文档
-
《精通正则表达式(第三版)》
-
《JavaScript权威指南》(第10章)
-
《正则指引》
-
《正则表达式必知必会》

打个广告,欢迎关注笔者公众号
