

之前初学python时写过一个练手的Demo,程序实现了在主机上根据关键词和获得赞同数爬取“掘金”中的文章:利用Python爬虫过滤“掘金”的关键词检索结果。但是这个项目只是简单地实现了功能,在很多方面都需要加强。现利用假期在这个程序地基础上修改了一下,加入了Web支持,并且部署到了我私人的服务器上,大家如果有兴趣可以访问使用:点我试用。
- 首先看一下使用方法和结果:
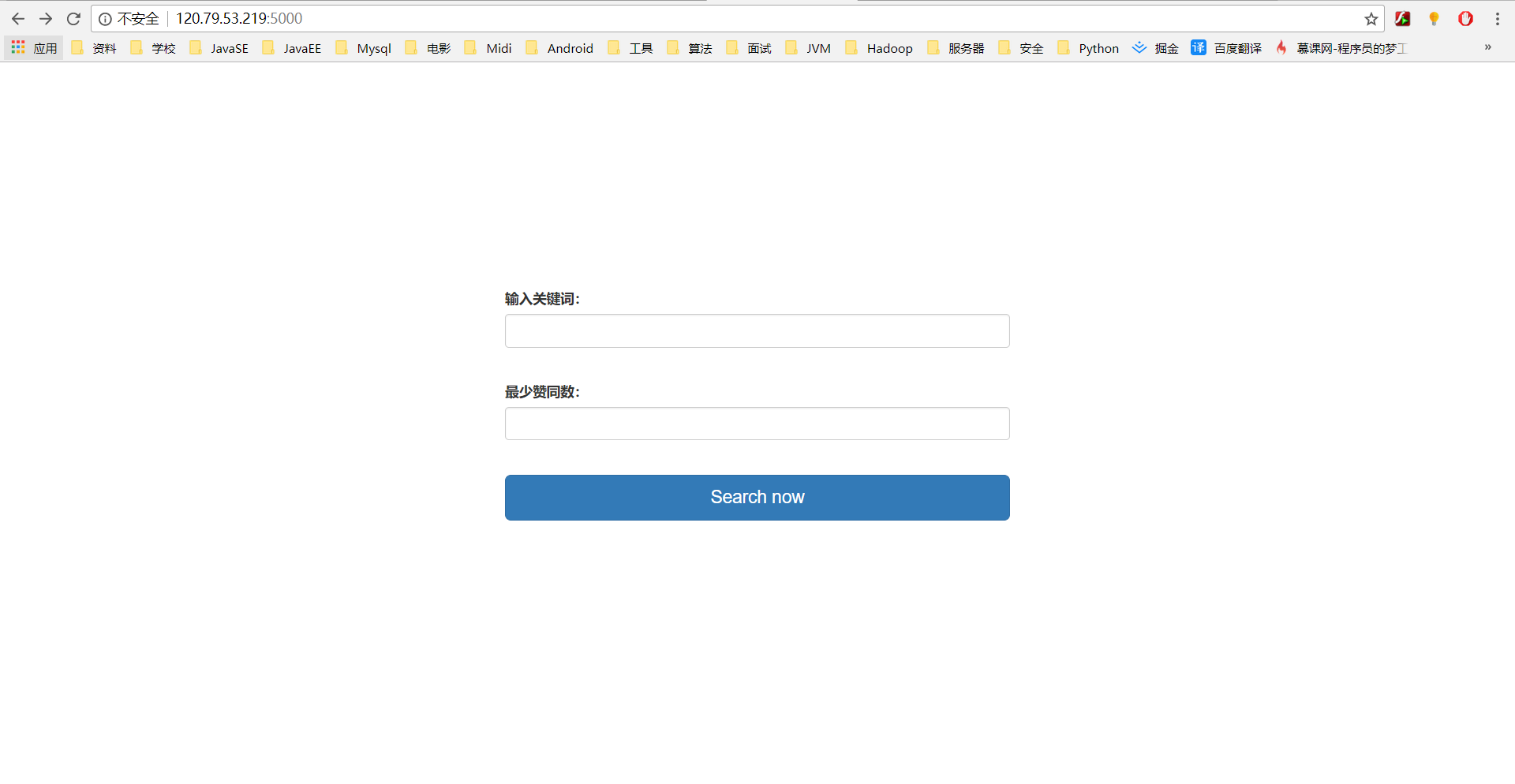
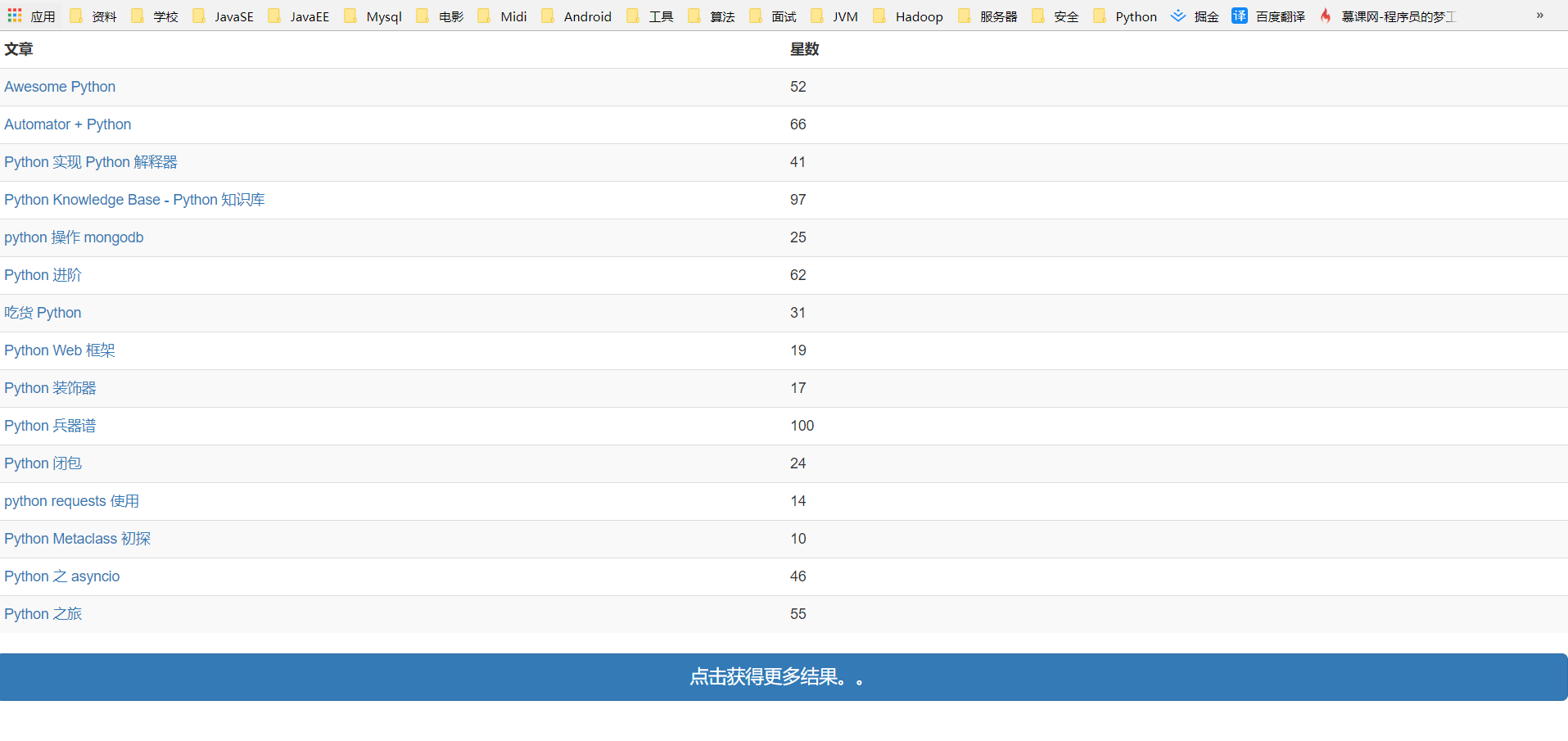
如果想要获取更多结果,继续点击 '点击获得更多结果。。'就好了,不过后台设置了不断获取数据的限制(15页搜索结果,一般够用了)。
1. 项目结构
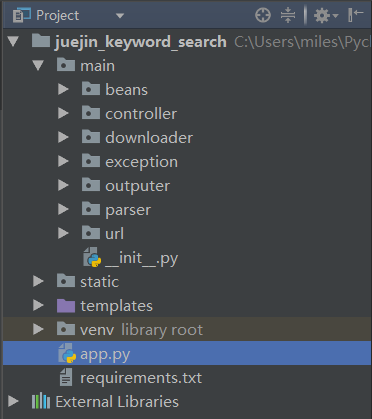
其中'main'包中是程序文件,'static'放置静态文件,'templates'放置html模板文件,'venv'是虚拟环境,'app.py'是主程序入口文件,'requirements.txt'记录程序所有依赖及版本号。
2. app.py
app.py负责构建Flask应用,且由于程序功能比较简单,将视图函数也放置其中,
app = Flask(__name__)
# set the secret key. keep this really secret:
app.secret_key = os.urandom(24)
# 带爬取的url地址,不包含请求参数
ajax_base_url = 'https://search-merger-ms.juejin.im/v1/search'
# 根目录,返回输入截面
@app.route('/')
def index():
return render_template('input.html')
# 搜索功能视图函数
@app.route('/search')
def search():
try:
baseline = int(request.args.get('baseline')) # 从请求参数中获取文章赞同数的下限值
except ValueError:
raise InvalidParameter('输入框不能为空或者请不要在输入框第二栏中输入非数字字符!')
keyword = quote(request.args.get('keyword')) # 获取搜索的关键字, urllib.parse.quote() 复杂处理url中的中文
if keyword is None or len(keyword) == 0:
raise InvalidParameter('输入框不能为空!')
params = {} # 对应的请求参数
params['query'] = keyword
params['page'] = '0'
params['raw_result'] = 'false'
params['src'] = 'web'
new_url = url_manager.build_ajax_url(ajax_base_url, params) # 构建请求地址
craw_json = crawler.craw_one_page(crawler.parse_from_json) # 选择json解析器
datas = craw_json(new_url, baseline) # 进行下载、解析,获得结果
if datas is None or len(datas) == 0:
return
return render_template('output.html', datas=datas, keyword=request.args.get('keyword'), baseline=baseline) # keyword传原始值,否则next_page中再进行quote则会出错
# 请求获得更多数据
@app.route('/nextPage')
def next_page():
keyword = quote(request.args.get('keyword')) # 获取搜索的关键字, urllib.parse.quote() 复杂处理url中的中文
try:
baseline = int(request.args.get('baseline'))
req_page = int(request.args.get('req_page'))
except ValueError:
return redirect(url_for('index'))
if keyword is None or len(keyword) == 0:
return redirect(url_for('index'))
params = {} # 对应的请求参数
params['query'] = keyword
params['page'] = str(req_page)
params['raw_result'] = 'false'
params['src'] = 'web'
new_url = url_manager.build_ajax_url(ajax_base_url, params) # 构建请求地址
craw_json = crawler.craw_one_page(crawler.parse_from_json) # 选择json解析器
datas = craw_json(new_url, baseline) # 进行下载、解析,获得结果
# 将结果对象构成的列表转完成json数组
json_array = []
for data in datas:
json_array.append(data.__dict__)
return jsonify(json_array)
# 参数错误界面
@app.errorhandler(InvalidParameter)
def invalid_param(error):
return render_template('param-error.html', error_message=error.message), error.status_code
if __name__ == '__main__':
app.debug = True
app.run()
app.py中主要包含了三个视图函数:index(), search(), next_page();search()负责搜索文章数据,next_page()负责获取下一页的文章数据。
3. 下载并解析数据
我们可以通过两种不同的URL来获取掘金的文章信息,一种会返回html数据,一种会返回JSON数据。我们选择第二种方式获取JSON数据。下面首先介绍程序的下载器: downloader.py
import urllib.request
def download_json(url):
if url is None:
print('one invalid url is found!')
return None
response = urllib.request.urlopen(url)
if response.getcode() != 200:
print('response from %s is invalid!' % url)
return None
return response.read().decode('utf-8')
通过该方法返回的是JSON的字符串数据。接下来使用解析器来解析JSON数据: json_parser.py
# 将json字符创解析为一个对象
def json_to_object(json_content):
if json_content is None:
print('parse error!json is None!')
return None
return json.loads(str(json_content))
# 从JSON构成的对象中提取出文章的title、link、collectionCount等数据,并将其封装成一个Bean对象,最后将这些对象添加到结果列表中
def build_bean_from_json(json_collection, baseline):
if json_collection is None:
raise ParseError('build bean from json error! json_collection is None!')
list = json_collection['d'] # 文章的列表
result_list = [] # 结果的列表
if list is None or len(list) == 0:
return []
for element in list:
starCount = element['collectionCount'] # 获得的收藏数,即获得的赞数
if int(starCount) >= baseline: # 如果收藏数不小于baseline,则构建结果对象并添加到结果列表中
title = element['title']
link = element['originalUrl']
result = ResultBean(title, link, starCount)
result_list.append(result) # 添加到结果列表中
print(title, link, starCount)
return result_list
4. 爬取器
上面的下载、解析都可以看作是爬取过程中的工具,下面我们通过爬取模块将下载和解析过程结合起来: crawler.py
# 爬取一页信息
def craw_one_page(func):
def in_craw_one_page(new_url, baseline=10): # 默认baseline=10
print('begin to main..')
content = downloader.download_json(new_url) # 根据URL获取网页
datas = func(content, baseline) # 一次解析所得的结果
print('main end..')
return datas
return in_craw_one_page
def parse_from_json(content, baseline):
json_collection = json_parser.json_to_object(content)
results = json_parser.build_bean_from_json(json_collection, baseline)
return results
def parse_from_html(content, baseline):
html_parser.build_soup(content) # 使用BeautifulSoup将html网页构建成soup树
results = html_parser.build_bean_from_html(baseline)
return results
这里使用闭包修饰爬取函数,使我们可以传入html或JSON对应的解析器。
完成
- github: github
- 部署: 通过Gunicorn部署flask应用(阿里云服务器:Ubuntu 16.04)
