

前言
可能大家更常见到隐马尔科夫模型(HMM),马尔科夫模型可以看成是一个更基础的模型,它是对能直接观察到的事件进行建模,所以与HMM相对应,有时也叫它为显马尔科夫(VMM)。马尔科夫模型要处理的是序列问题,核心思想就是统计所有样本的过程,得到系统中状态之间的转移概率。
马尔可夫过程
马尔可夫过程是一个随机过程,系统从一个状态到另外一个状态存在转移概率,而转移概率仅通过前一状态来计算出来,与过去的状态和初始状态都没有关系。这里的随机过程主要是说该过程随时间而变化,且每个时刻的状态值是随机的,按照一定的概率分布。
随机过程相关状态如果向之前的状态推广,那么过程中的每个状态的转移依赖于之前的n个状态,此模型就为n阶模型。所以上面提到的马尔可夫过程为一阶过程,它的特点是每个状态的转移都只依赖于前一个状态。以此类推,根据之前n个状态计算转移概率的则为n阶过程。
马尔可夫链
时间和状态都是离散的马尔可夫过程即为马尔可夫链。假设马尔可夫链包含的所有可能的值的集合为,则S称为状态空间。设一个马尔科夫链
,其中的每个变量的取值范围都在S集合内,且t表示一共有t个时刻。
与前面n阶过程对应,同样存在n阶马尔科夫链。比如,如果某个状态出现的概率与它的前一个状态有关,这时就为一阶马尔科夫链,在处理自然语言中则是对应二元语法。同样的,如果某个状态出现的概率与它的前两个状态有关,则为二阶马尔科夫链,对应的是三元语法。其中n阶马尔科夫模型对应的是n+1元语法。
关于n元语法可以参考之前写的文章《n元语法》。
马尔科夫假设
对于n阶马尔科夫过程,可以假设状态与前一个或几个词相关,这个就是马尔科夫假设。一阶马尔科夫链,转移过程状态概率与前一状态有关,此时可以表示为,
举个例子
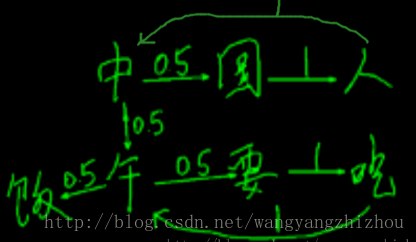
用简单的“中国人中午要吃午饭”一句话看下不同状态的转换及其概率。“中”到“国”“午”概率各50%,“午”到“饭”“要”概率各50%,其他状态转化为100%。当我们用大量语料进行训练后,就能得到很大的转移矩阵,每个字后面可能都会有很多种状态连接,并且有相应的概率。
实现
其中某次输出可能为“吃 午 要”。
import random
words = ["中", "国", "人", "中", "午", "要", "吃", "午", "饭"]
cache = {}
size = 3
def binary():
for i in range(len(words) - 1):
yield (words[i], words[i + 1])
for w1, w2 in binary():
key = w1
if key in cache:
cache[key].append(w2)
else:
cache[key] = [w2]
seed = random.randint(0, len(words) - 1)
seed_word = words[seed]
word1 = seed_word
_words = []
for i in range(size):
_words.append(word1)
word1, = random.choice(cache[word1])
print(' '.join(_words))
-------------推荐阅读------------
------------------广告时间----------------
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
欢迎关注:

