

前言
前面的《马尔科夫模型》主要是研究能直接观察到的序列的概率问题,通过马尔科夫假设能建立起马尔科夫链,从而解决一些序列问题。但有时候观察的对象并不是我们待处理的目标对象,它的规律隐含在观察对象中,观察的事件和隐含事件存在一定的相关关系,这时候就要用到隐马尔科夫模型(HMM)。
比如nlp中常见的词性标注任务就经常用HMM,其中显状态就是单词,而隐状态为词性,通过我们观察到的单词序列去标出隐含的词性。
隐马尔科夫模型
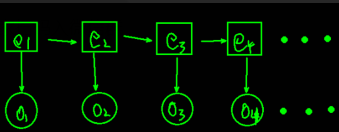
隐马尔科夫模型是一种有向图模型,图模型能清晰表达变量相关关系的概率,常见的图模型还有条件随机场,节点表示变量,节点之间的连线表示两者相关概率。用以下定义来描述HMM模型,
设系统所有可能的状态集合为,所有能观察的对象的集合
,那么就一共有n种隐状态和m种显状态。
再设总共T个时刻的状态序列,对应有T个时刻的观察序列
,这两个很容易理解,对应到nlp的词性标注中就是一句话和这句话的词性标注,比如“我/是/中国/人”和“代词/动词/名词/名词”。
隐马尔科夫模型主要有三组概率:转移概率、观测概率和初始状态概率。
系统状态之间存在着转移概率,设一个转移矩阵,因为有n中隐状态,所以是n行n列。概率的计算公式为,
此表示任意时刻t的状态若为,则下一时刻状态为
的概率,即任意时刻两种状态的转移概率了。
观测概率矩阵为,其中
,它用于表示在任意时刻t,若状态为
,则生成观察状态
的概率。
除此之外还有一个初始状态概率为,用于表示初始时刻各状态出现的概率,其中
,即t=1时刻状态为
的概率。
综上所述,一个隐马尔科夫模型可以用描述。
重要假设
- 齐次马尔科夫性假设,即任意时刻t的状态只依赖于前一时刻的状态,与其他时刻的状态及观测序列无关,比如
只与
相关,其他时刻也如此。
- 观测独立性假设,即任意时刻t的观测只依赖于该时刻状态,与其他时刻的观测和状态无关,比如
只与
- 不动性假设,即状态与具体的时间无关,比如状态从
的概率在任意时刻都是相等的。
三个问题
马尔科夫模型思想在实际应用中有三个问题需要关注:
- 似然度问题,即给定一个隐马尔科夫模型,计算观察序列的似然度
,比如对于一个HMM,计算序列“我是中国人”的概率是多少。
- 预测问题,也称解码问题,即给定观察序列O和隐马尔科夫模型,找到与之最匹配的隐状态序列E,也可以说由观察序列推断隐状态序列。比如对于一个HMM,已知序列“我是中国人”,计算出它的词性序列。
- 学习问题,即给定一个观察序列O以及其对应的状态序列E,训练出最佳的模型参数,使之能最好地描述观察序列。比如已知序列“我/是/中国/人”和状态序列“代词/动词/名词/名词”,训练一个隐马尔科夫模型。
似然度问题的计算
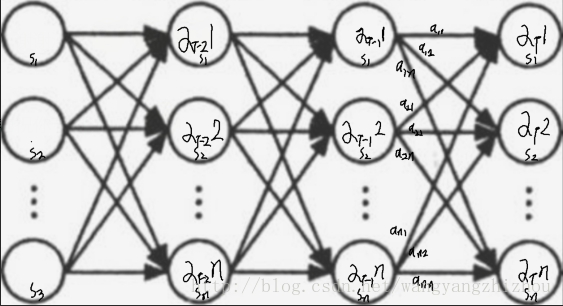
第一个问题是关于序列概率的计算,如果通过列举所有可能序列的概率并求和的形式,将会导致计算量是相当大,所以需要一种更高效的方法,即前向算法。
首先定义前向概率,对于指定HMM,在某时刻t部分观测序列为且状态为
的概率即为前向概率,记为
。
通过如下步骤递推就可以得到观察序列。
- n种状态的初始值,
- 时刻t从1到T-1递推前向概率,
- 对T时刻累加求和,
可以看到不同状态有不同的初始值,值为状态为且观察值为
的联合概率;t+1时刻的前向概率可以通过前一时刻的前向概率乘以对应的状态转换概率进行累加后,再乘以
的观察概率;对T时刻前向概率求和,得到最终结果,即是最后时刻不同状态的可能性之和。整个过程可以结合下面的图更好理解,怎么样?是不是很熟悉?就像全连接神经网络一样,每个节点都相连,而每个节点到下一层的节点都会有相应的分量。
预测问题
第二个问题是预测问题,也是解码问题,常用的方法有viterbi方法,参照前面写的一篇文章《隐马尔可夫模型的Viterbi解码算法》。
学习问题
第三个问题是学习问题,这里只看监督学习方式。设训练样本集为,其中k为样本数量。由极大似然估计法可计算转移概率、观测概率及初始状态概率。
设k个样本中在所有时刻t除于状态而t+1时刻除于状态
的频数为
,则转移概率
。再设样本中状态为
且观察值为
的频数为
,则观察概率
。而初始状态则直接计算k个样本中初始状态为
的频率。
如何生成观测序列
首先根据初始状态概率就可以选择出初始状态,然后根据这个状态就可以通过观测概率得到一个观测值,接着再利用这个状态去通过转移概率得到下一个状态,然后又可以继续得到下一个观测值,以此类推,直到把观测序列生成完毕。
demo
https://github.com/sea-boat/TextAnalyzer/tree/master/src/main/java/com/seaboat/text/analyzer/tagging
-------------推荐阅读------------
------------------广告时间----------------
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
欢迎关注:

