

说明
学习ARKit前,需要先学习SceneKit,参考SceneKit系列文章目录
UI界面/3D模型调试
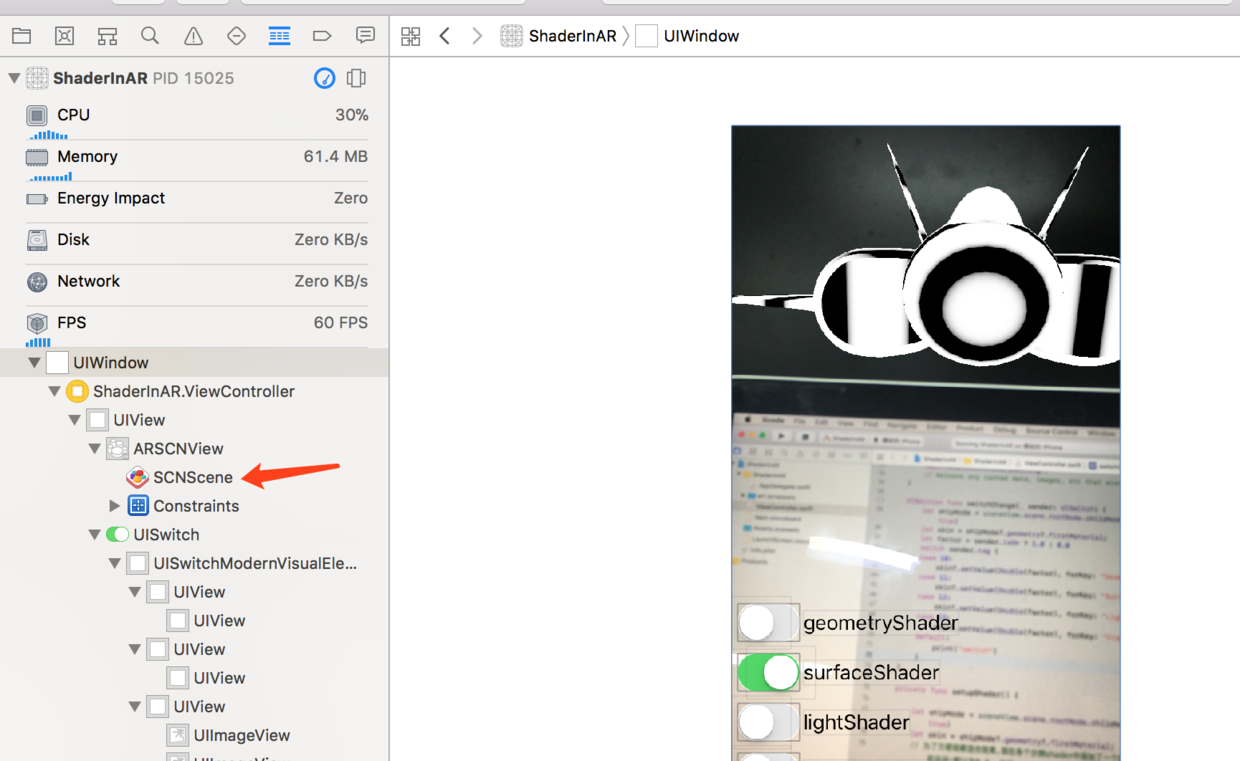
界面与模型调试仍然是使用View Debuger,进入调试状态后可看到图层状态
点击3D图层,会进入3D模型编辑器,显示的是实时状态的模型
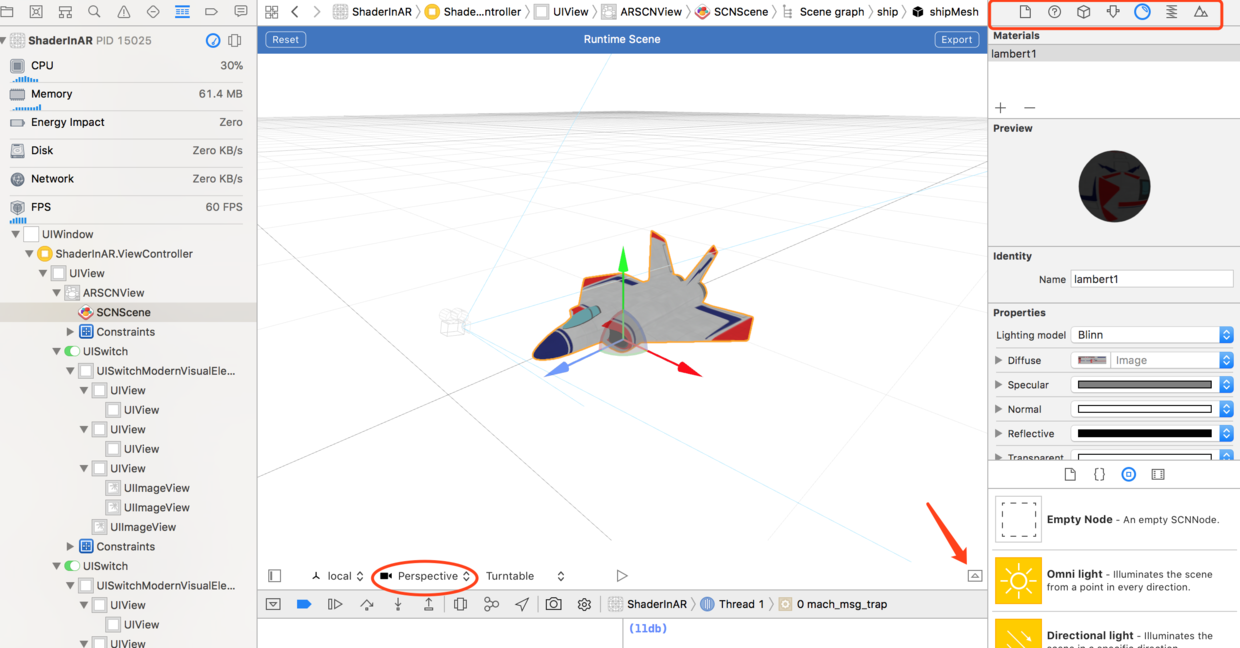
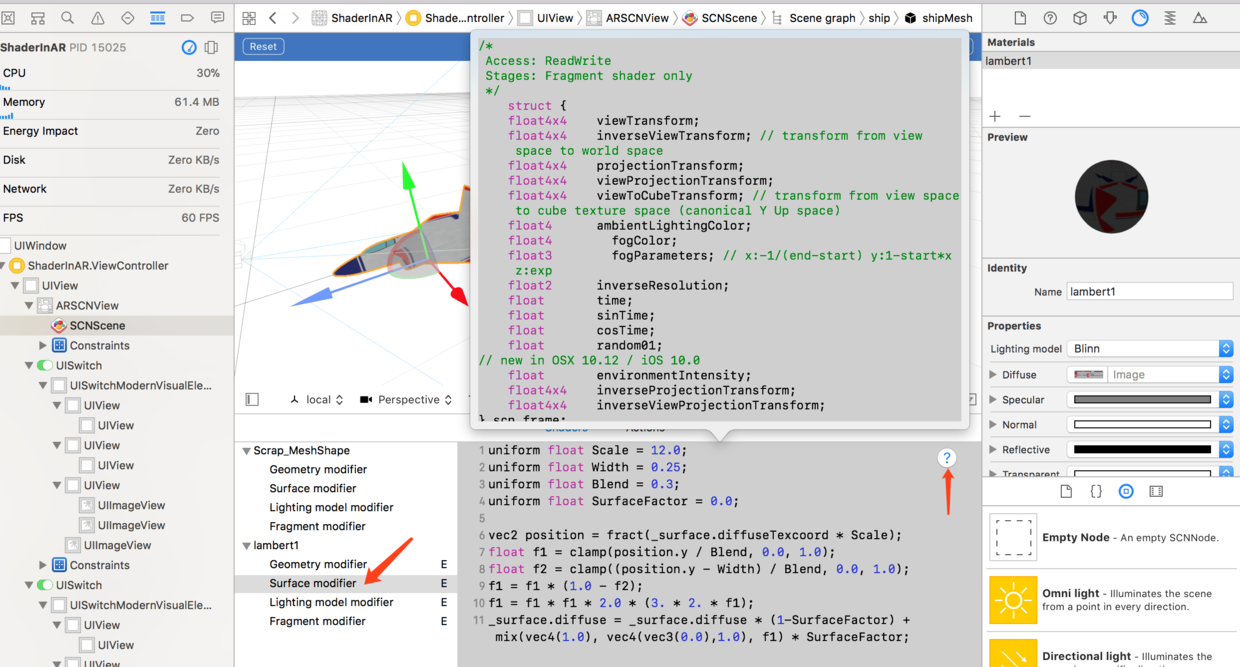
右侧可以调整材质等信息,点击右下角的按钮,可以查看Shader和Action,选中可以查看我们使用的Shader,再点击问号可查看参数输入:
性能调试
性能调试分为实时查看(用Gauge),与录制分析(用Instruments)
FPS Gauge
FPS Gauge不仅是实时的,还能显示负载的分类
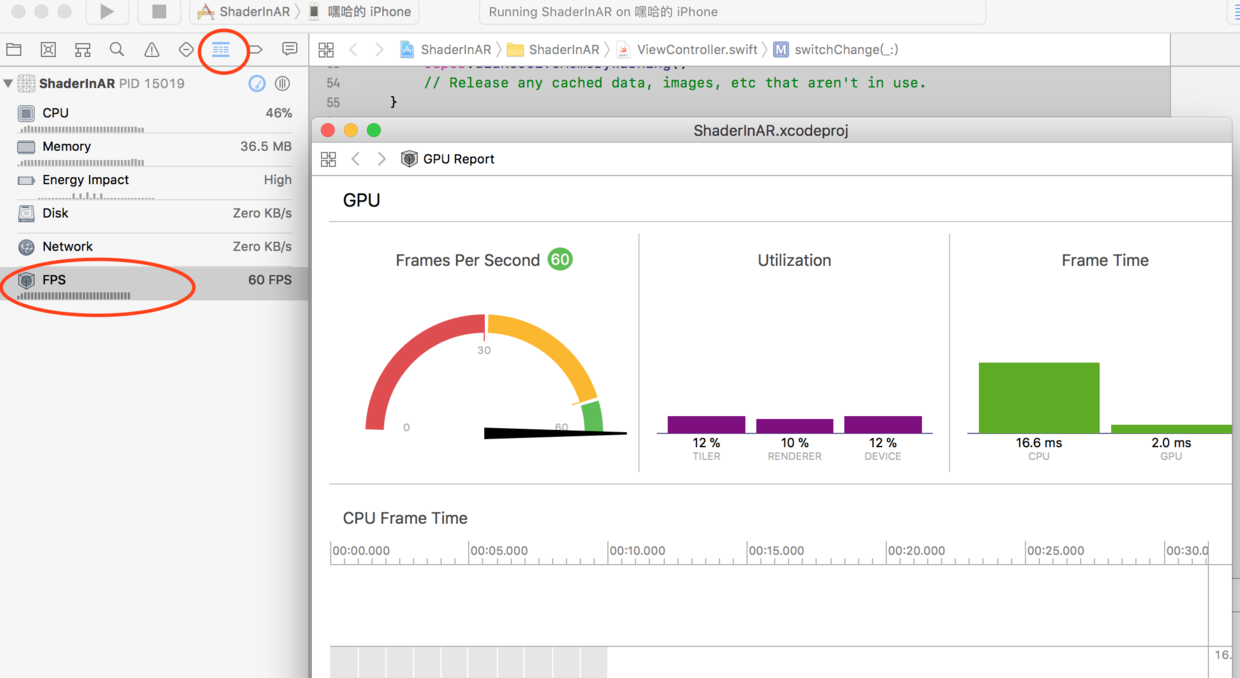
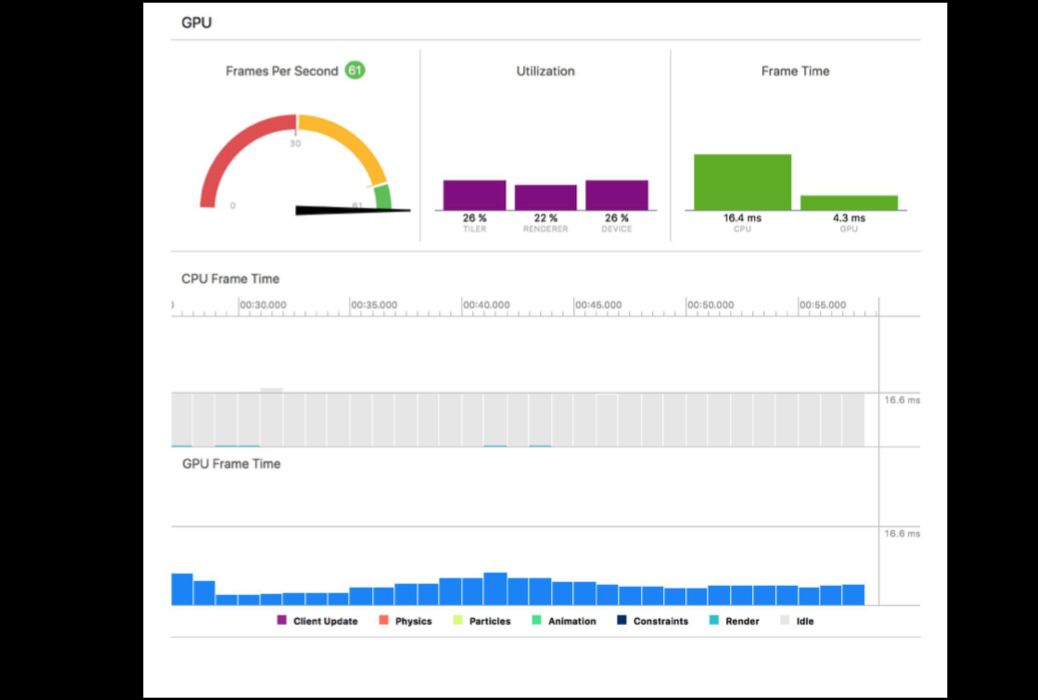
Instruments->SceneKit
一般先使用SceneKit工具分析,可以精确到每帧,但需要先录制一段;分析问题找到原因后再处理,或使用Metal System Trace再分析Metal程序
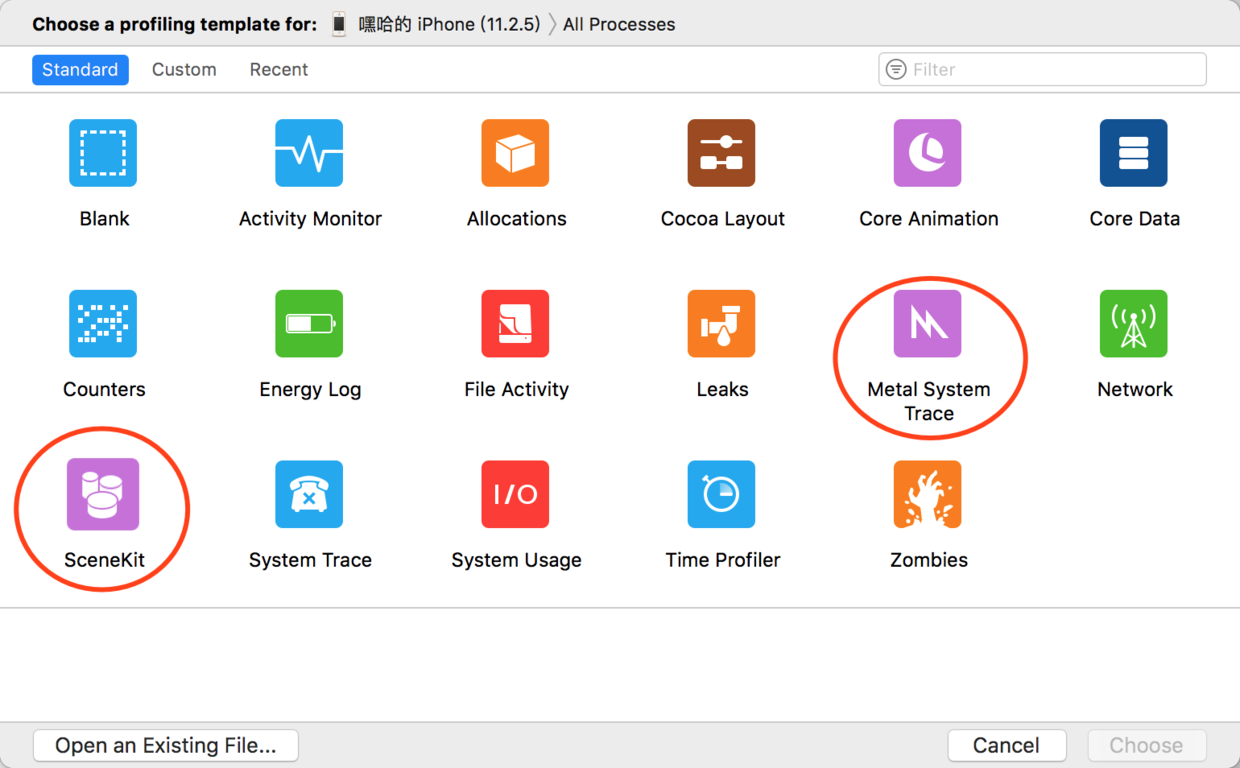
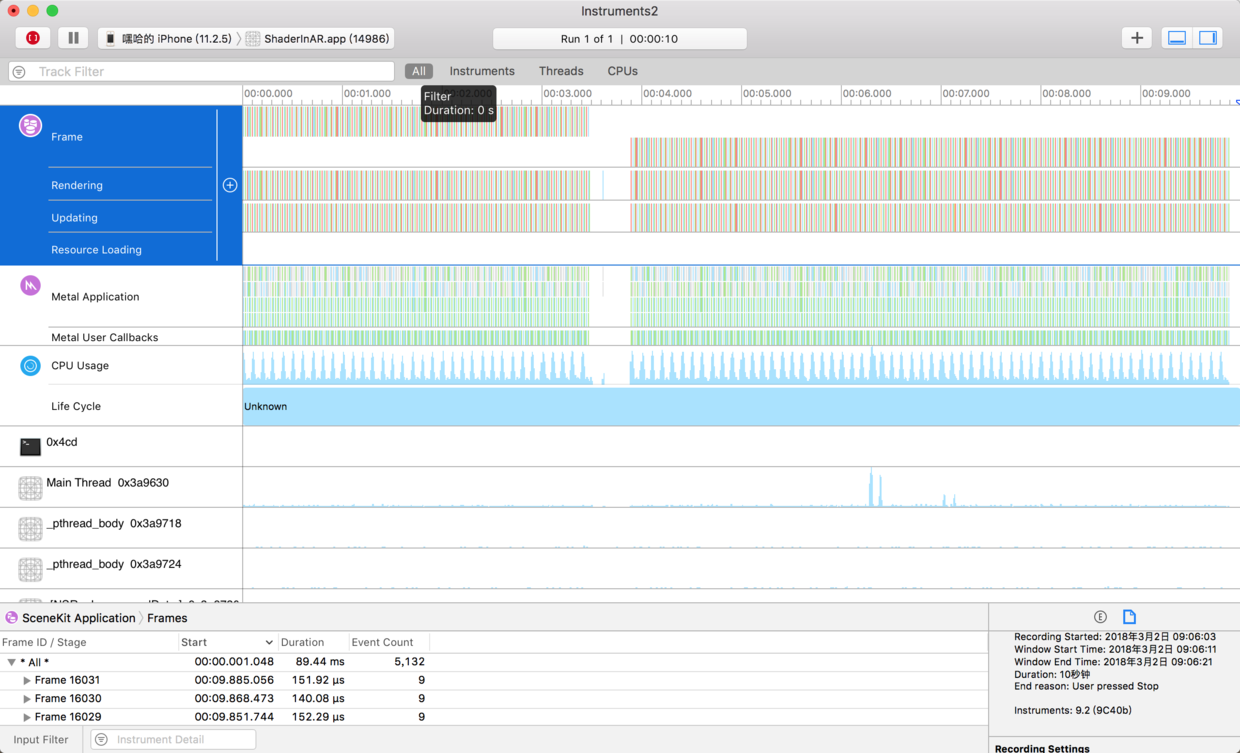
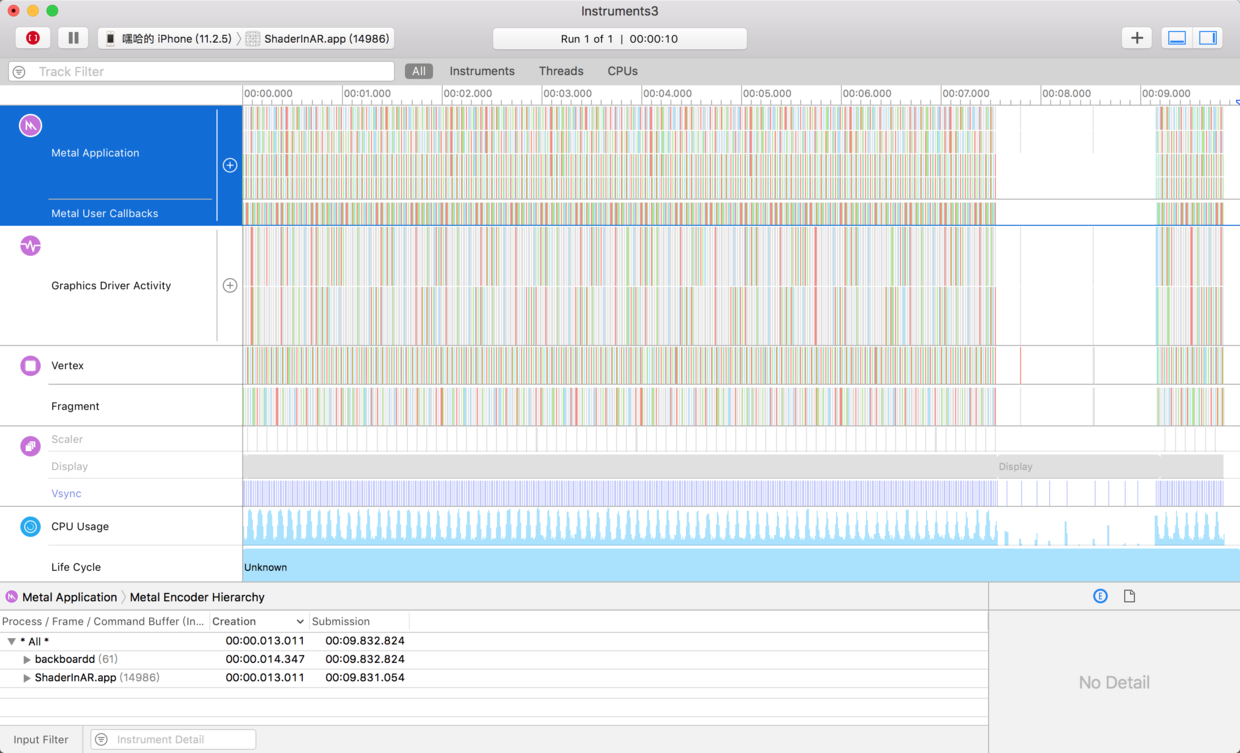
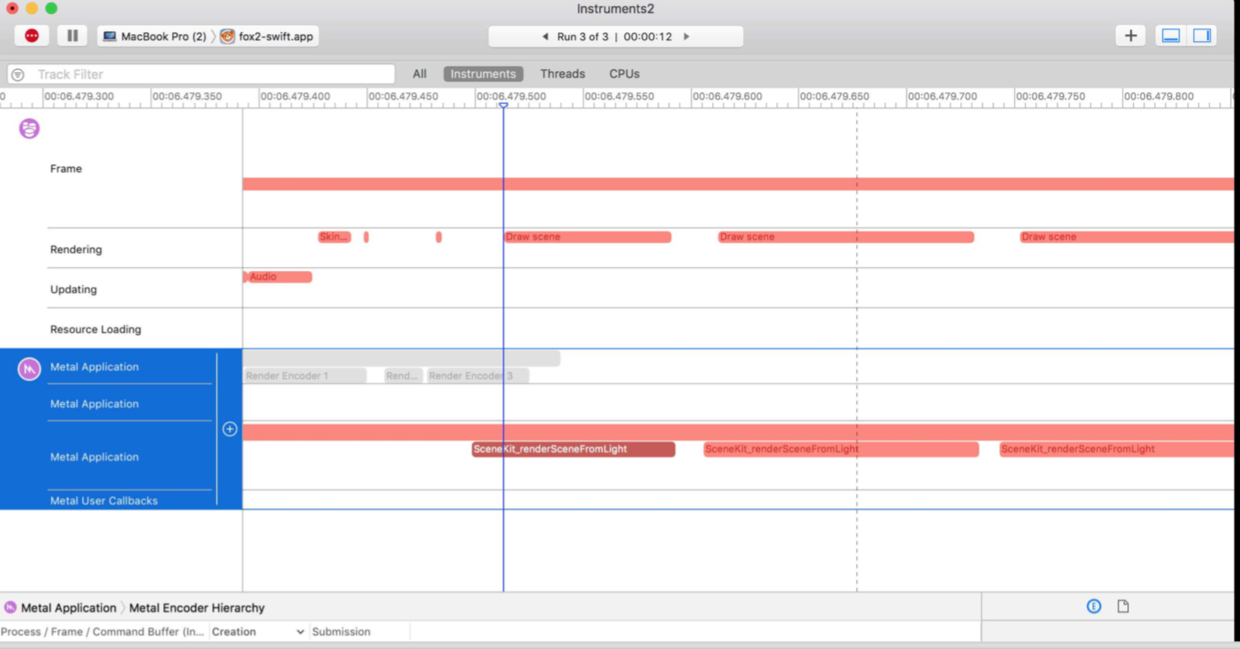
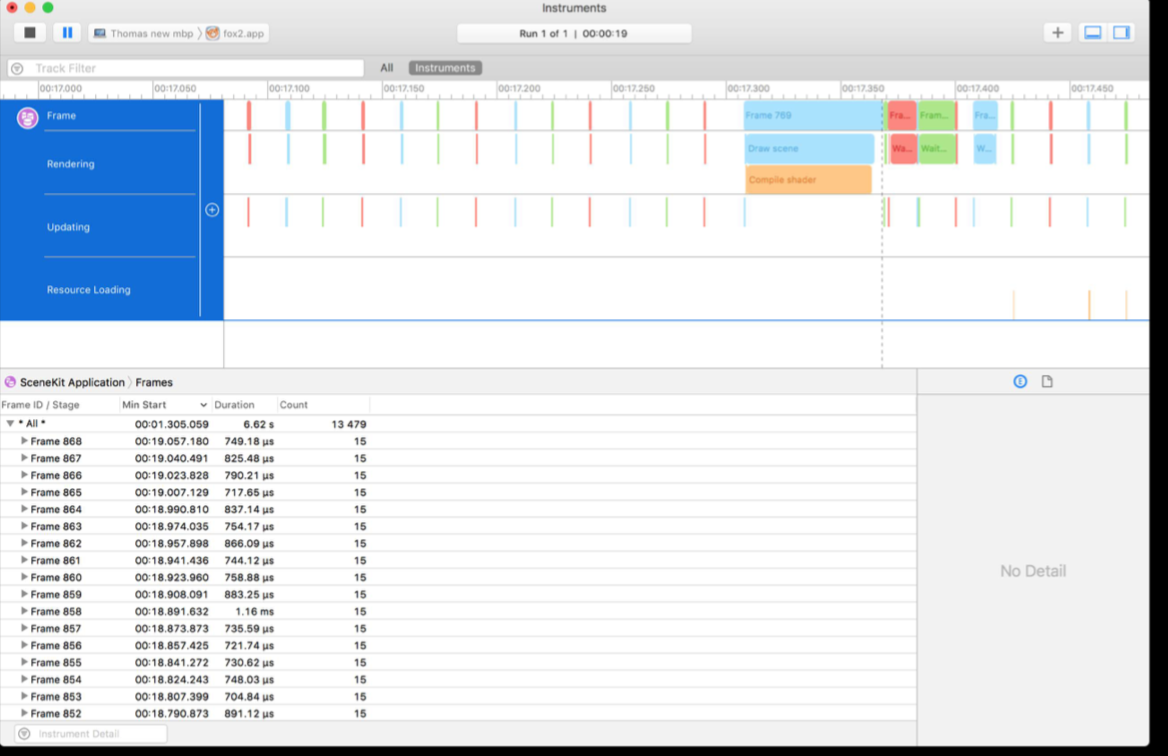
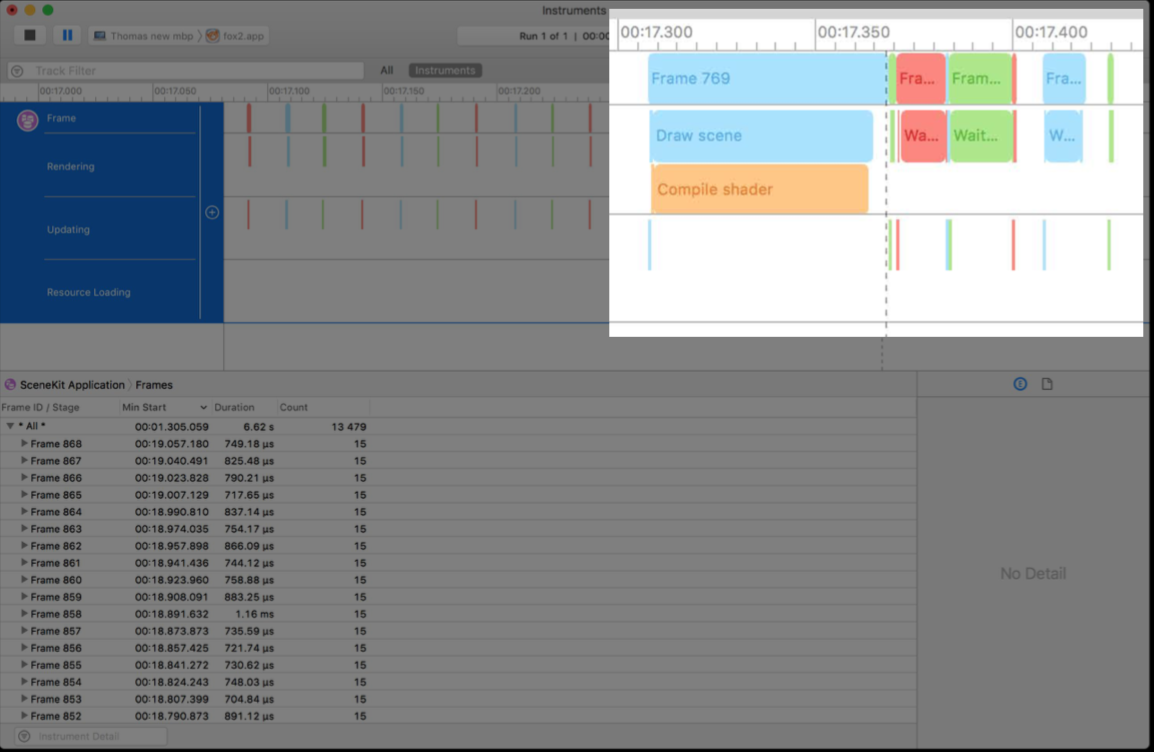
例如,苹果官方的例子中,先用SceneKit工具分析出问题出在Metal代码上,再用
Metal System Trace分析出问题出在Shader编译太慢上.对应的解决方法是:提前编译Shader.
Metal2高级调试
本部分内容来自于WWDC2017中的Metal 2 Optimization and Debugging
示例程序的代码苹果貌似没有全部提供,反正我在苹果文档库中只找到了一个示例MetalDeferredLighting.
Metal Frame Debugger(Metal帧调试器)
其实就是对原来的GPU Frame Debugger的增强,使用方法还是和原来一样,在运行中点击下方工具栏中的照相机图标捕捉Frame,现在长按也可以弹出菜单显示更多内容了.
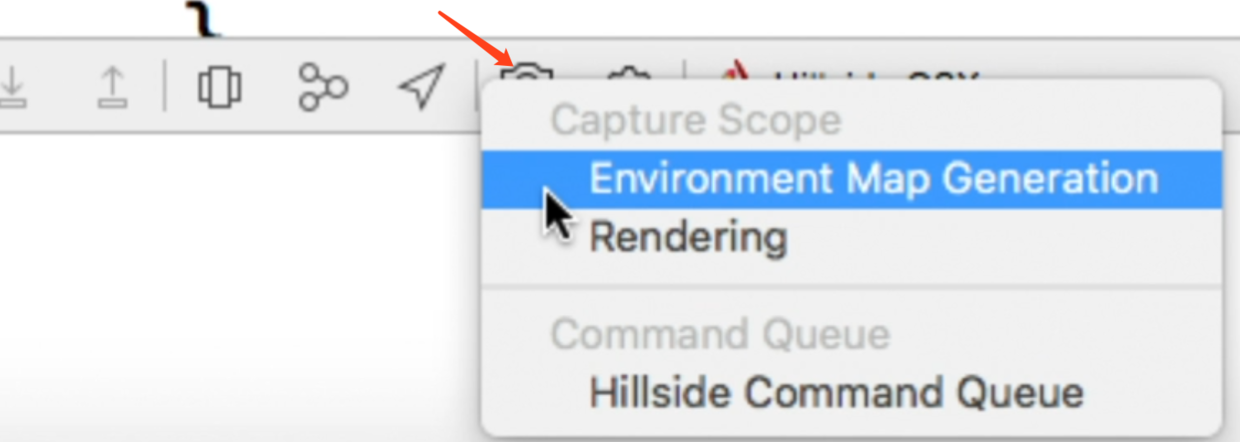
原有功能:
- Fully featured frame debugger :全功能的帧调试器
- Navigate through your workload :浏览工作负载
- Inspect state and resource :检查状态和资源
- Debug graphics and compute :调试图形和计算
- Integrated into Xcode :整合进Xcode
新增了一些功能:
- Improved Capture Performance :改进性能,提升10倍速度
- Full Metal 2 Support :全面支持Metal 2
- Raster order groups :光栅顺序组
- Sampler arrays :采样器数组
- Viewport arrays :视口数组
- New pixel formats :新像素格式
- New vertex array formats :新顶点数组格式
- Argument buffers :参数缓存器
- VR Support :支持VR(macOS上,如SteamVR)
- Improved Capture Workflow :改进捕捉流程
- Metal Quick Looks :Metal预览(也可以用在神经网络CNN中查看相关数据)
- Advanced Filtering :高级搜索过滤
- Pixel Inspection :像素检查
- Inspect Vertex Attribute Outputs :顶点属性输出检查
下面让我们结合一个Demo来演示新增功能的使用. 首先,运行一下,这是一个有问题的程序,注意雪花附近出现了异常

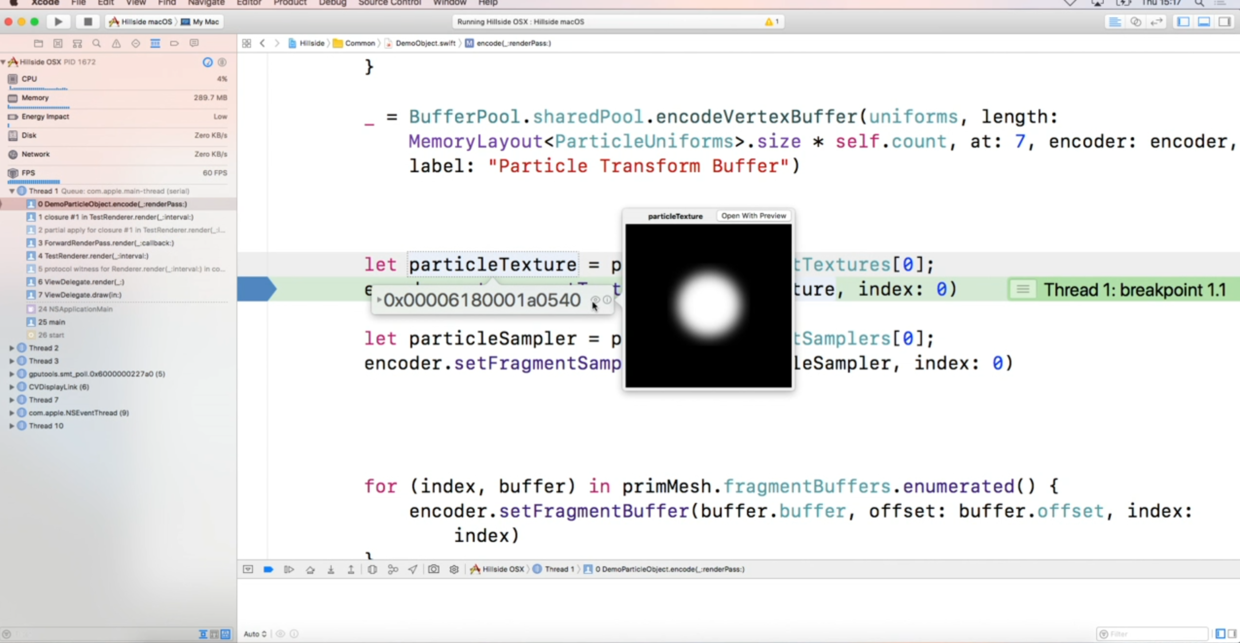
接着开始调试,先看纹理本身有没有异常,在对应位置打断点,就可以直接预览GPU上的纹理,非常方便:
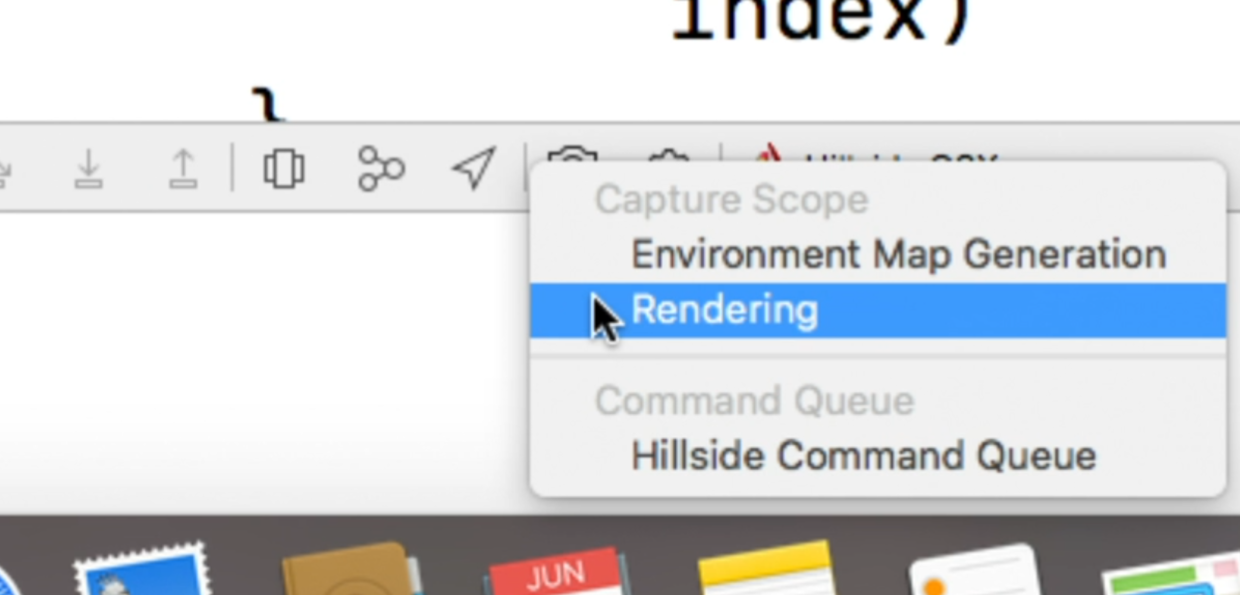
Rendering,进入了Metal Frame Debuger中:
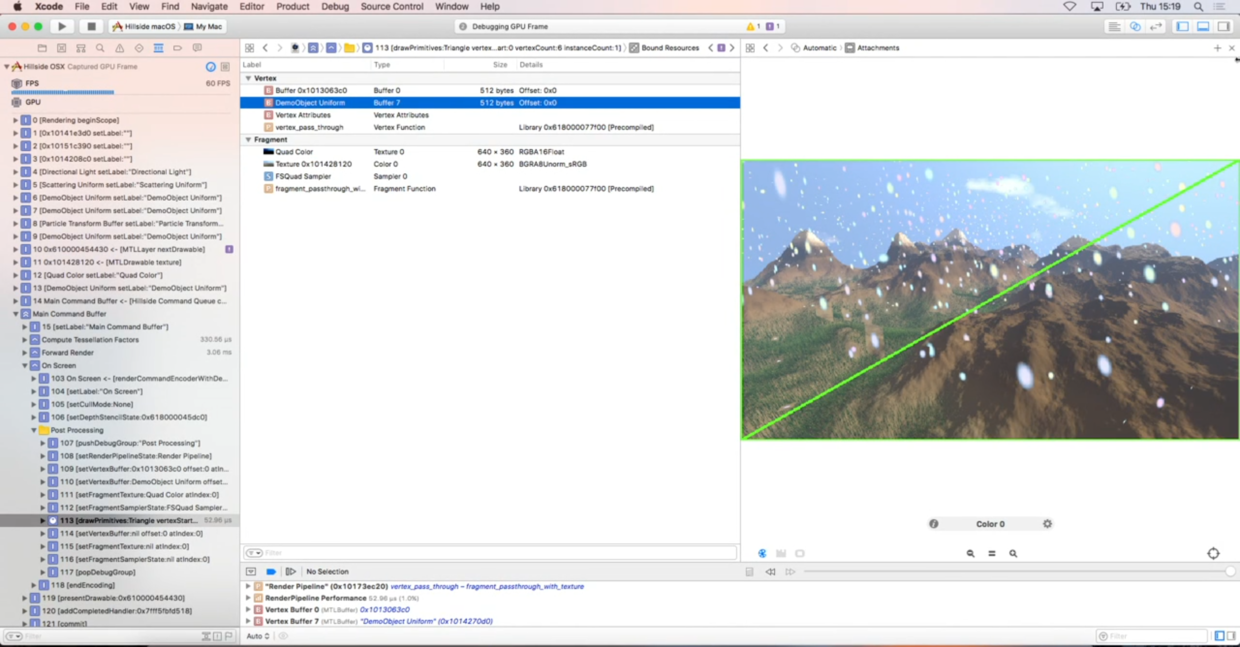
要找到绘制雪花颗粒(particle)的地方,可以在左下角使用高级搜索,添加条件Forward Render和Particle,搜索结果中只有一个API满足要求,点击这个搜索结果,显示详情:
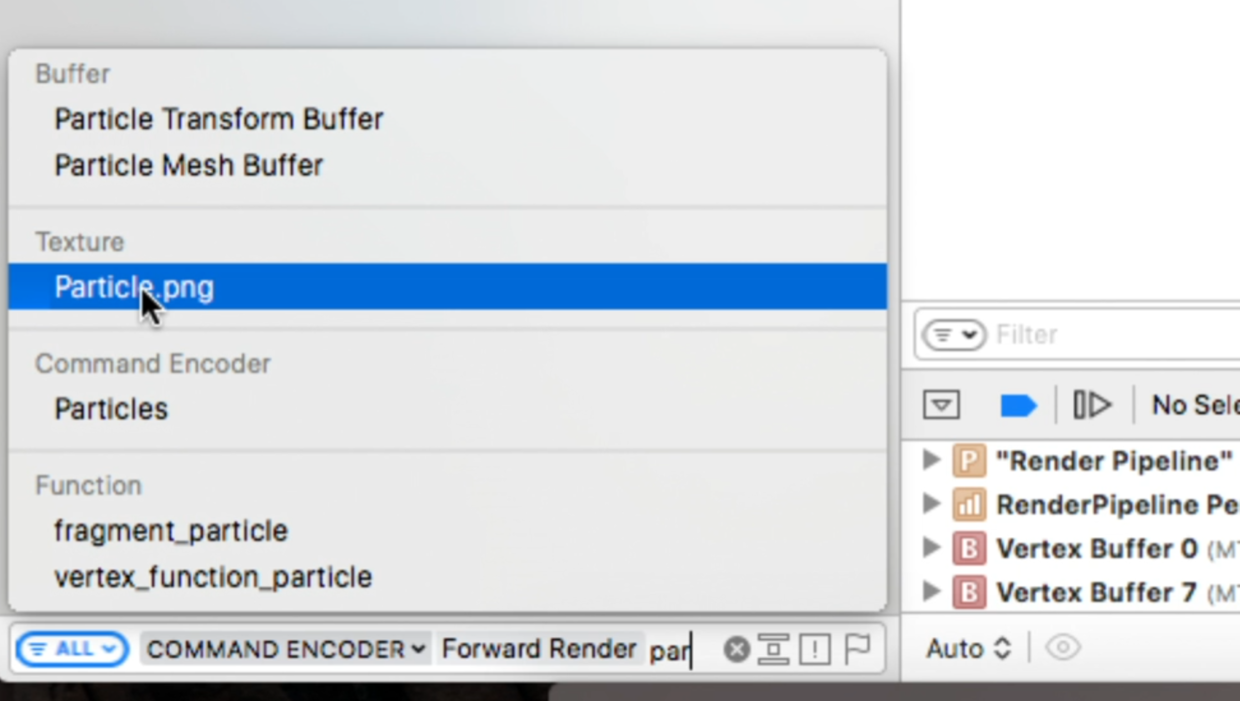
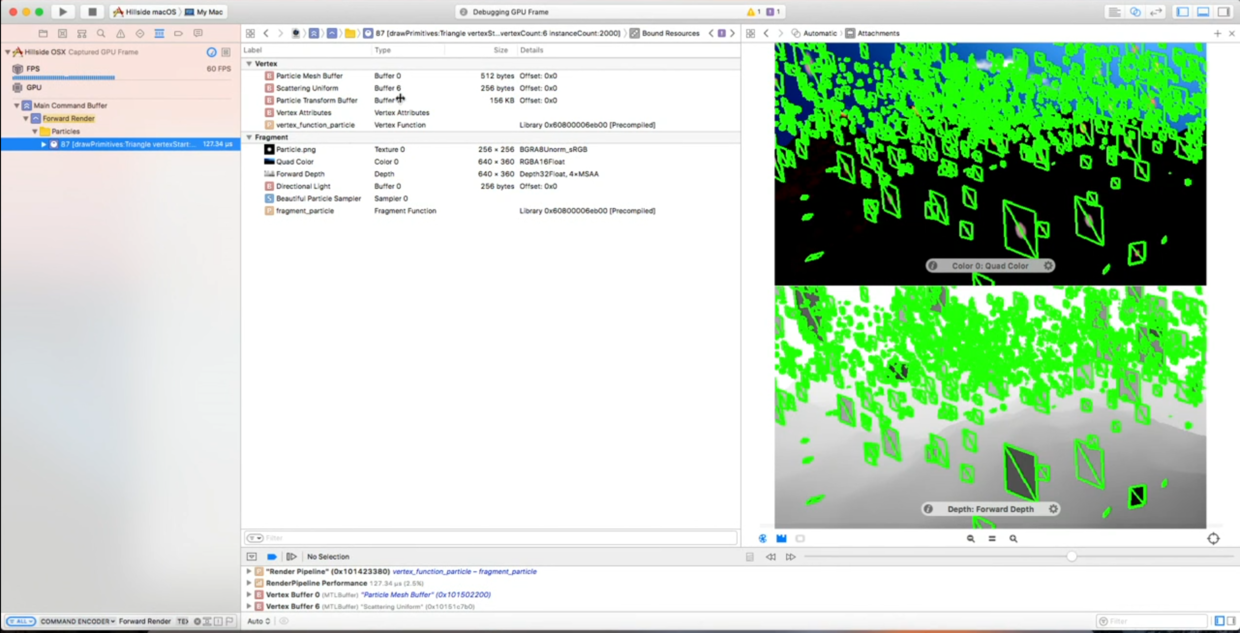
看看顶点数据是不是有问题,双击Vertex Attributes查看顶点的输入输出数据
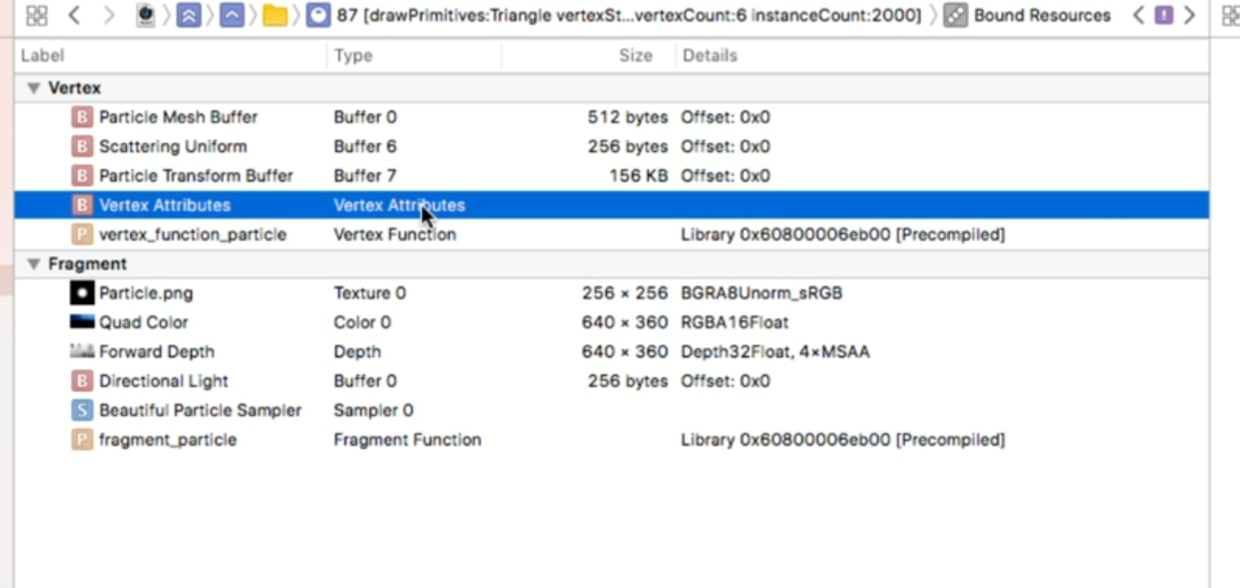
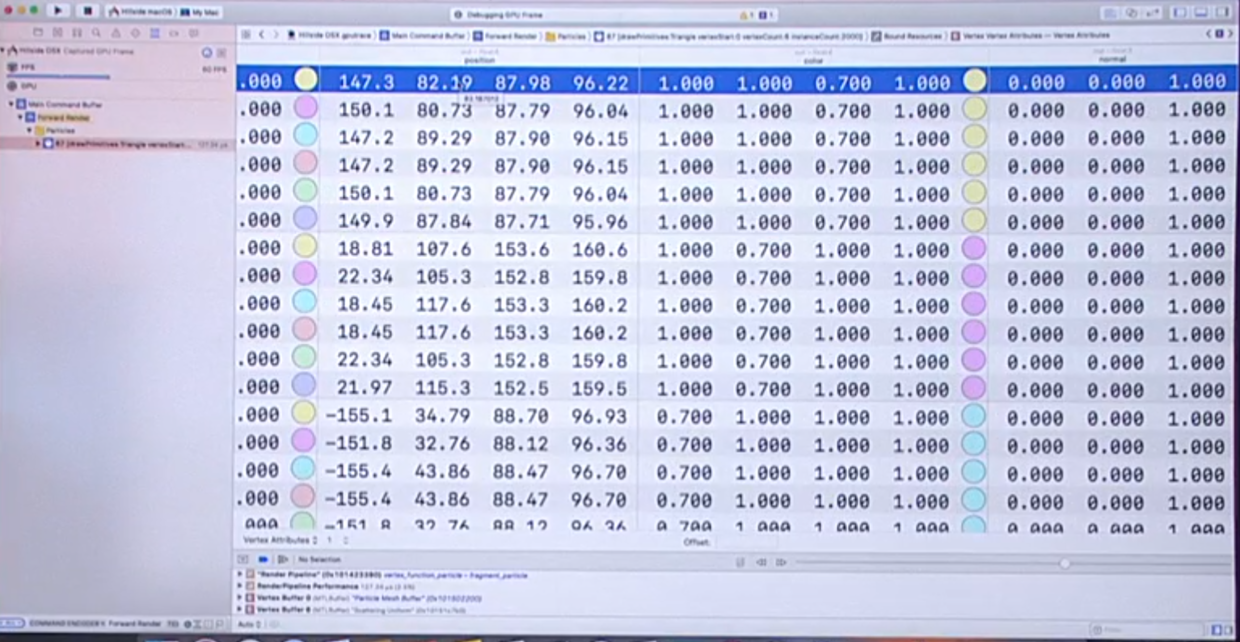
数据看起来没有肉眼可见的异常,估计应该是正常的.再找别的原因. 先回到左侧导航栏搜索结果中,展开当前API调用涉及的所有资源,选中Attachments,打开右下角的像素检查器:
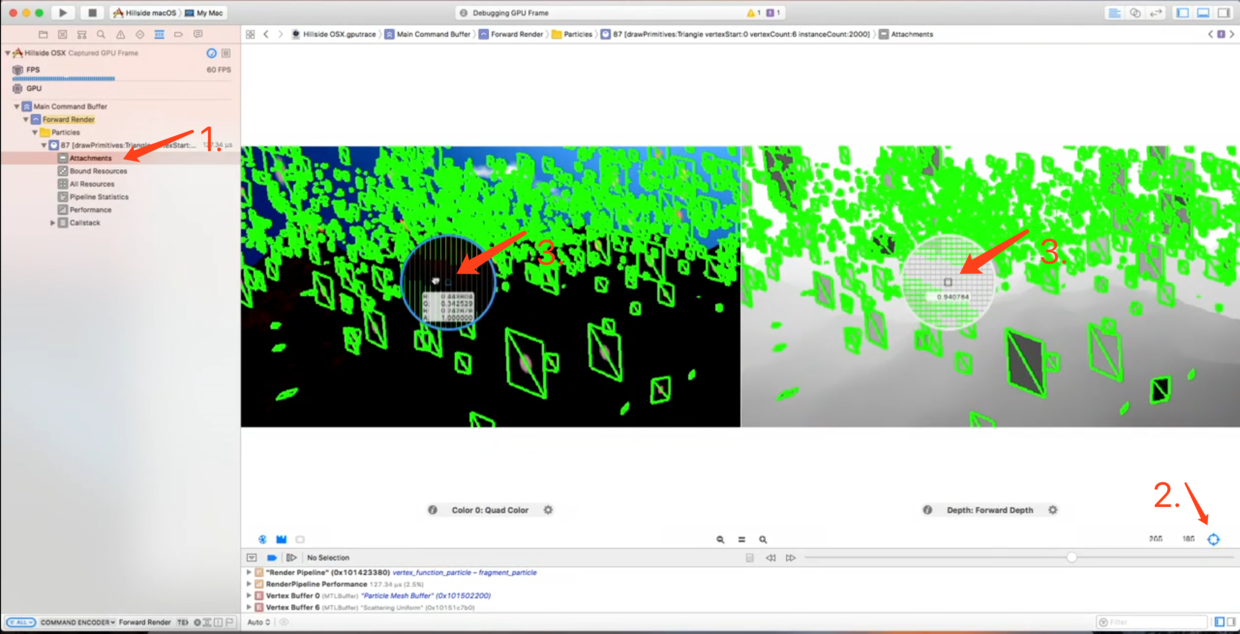
两张图:左边是渲染目标的色彩图,右侧是渲染目标的深度图,移动圆形的像素检查器Pixel Inspector来检查像素级的问题.


经过查找,我们发现右侧的深度图上,雪花边缘附近的深度值不一致,这就是bug所在,正常情况下particle不应该写入深度值到深度缓冲器depth buffer中.
修复这个bug即可,此处略过...
GPU Shader Profiler
这是集成在Metal Frame Debugger中的Shader分析利器,可以分析出编译后的Shader哪里有性能问题.例如:
Metal Pipeline Statistics(Metal管线统计)
这个工具也是集成在Metal Frame Debugger中的Shader分析利器.功能如下:
-
Per-shader metrics:每个着色器节奏 编译器产生的统计数据:
- Instruction count :指令数
- Instruction mix :指令组合
- Register usage :寄存器使用
- Occupancy :占用率
-
Compiler remarks :编译器评价 能避免以下情况出现:
- Slow math usage:低效的数学运算
- Register spills:寄存器泄露
- Stack usage:栈的使用(GPU用栈储存或读取会造成负担,如shader使用了可变数组)
- Other optimization opportunities:其他可优化情况
还是通过一个Demo来演示
打开项目运行,点击相机图标,进入帧调试器,切换显示方式,找到Pipeline Statistics界面中:
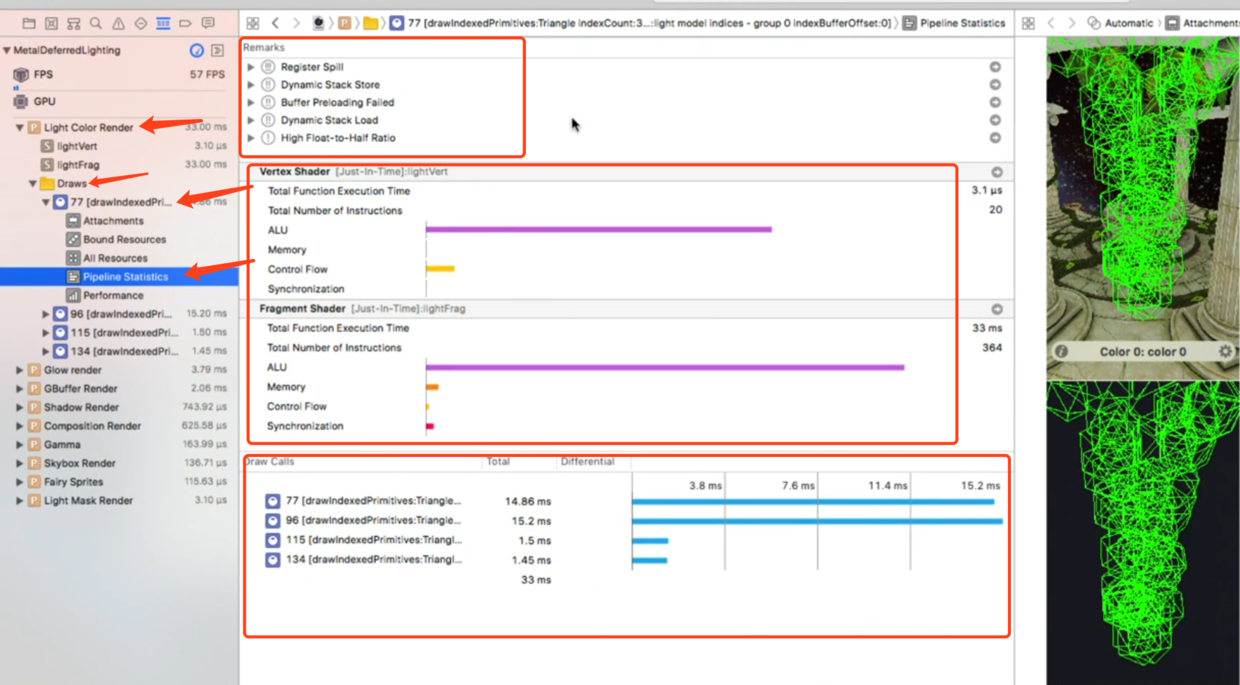
中间的上方显示出编译器给出的优化建议,我们先处理和栈相关的第2个和第4个,双击进入shader中:
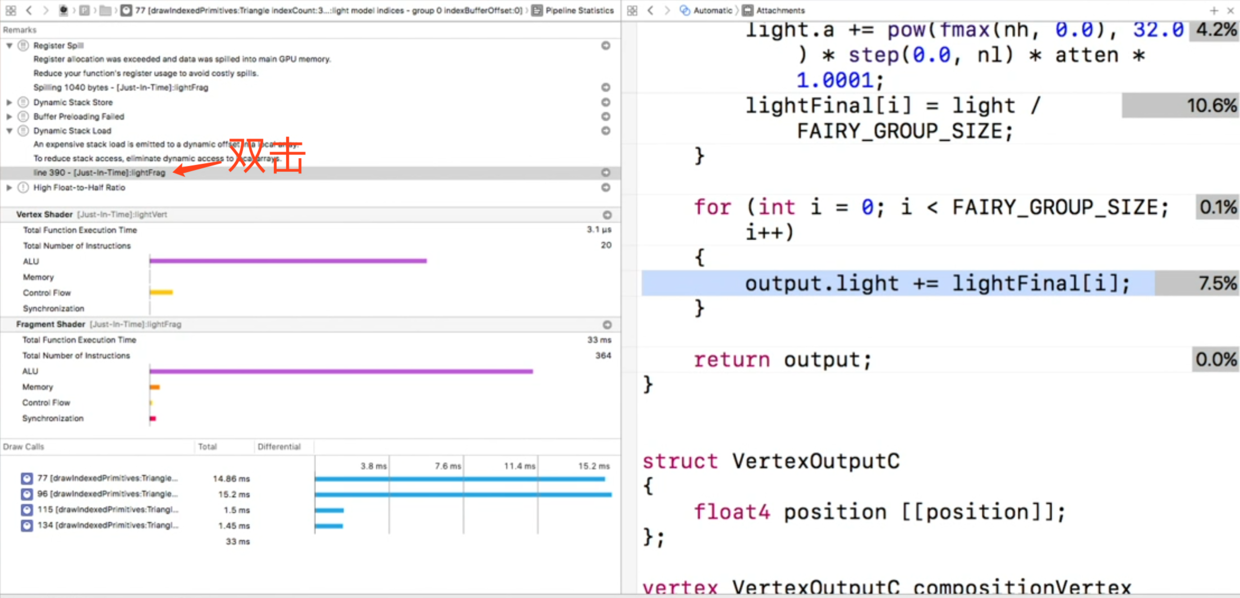
部分代码如下,发现其中的可变数组会造成影响:
//问题代码
float3 v = in.v_view * (scene_z / in.v_view.z);
// Now, we have everything we need to calculate our view-space lighting vectors.
FragOutput output;
output.light = float4(0);
output.albedo = gBuffers.albedo;
output.normal = gBuffers.normal;
output.depth = gBuffers.depth;
float4 lightingFinal[FAIRY_GROUP_SIZE];
for(int i = 0; i < FAIRY_GROUP_SIZE; i++) {
lightingFinal[i] = float4(0);
float3 l = (lightData->view_light_position.xyz - v);
float n_ls = dot(n, n);
float v_ls = dot(v, v);
float l_ls = dot(l, l);
float3 h = (l * rsqrt(l_ls / v_ls) - v);
float h_ls = dot(h, h);
float nl = dot(n, l) * rsqrt(n_ls * l_ls);
float nh = dot(n, h) * rsqrt(n_ls * h_ls);
float d_atten = sqrt(l_ls);
float atten = fmax(1.0 - d_atten / lightData->light_color_radius.w, 0.0);
float diffuse = fmax(nl, 0.0) * atten;
float4 light = gBuffers.light;
light.rgb += lightData->light_color_radius.xyz * diffuse;
light.a += pow(fmax(nh, 0.0), 32.0) * step(0.0, nl) * atten * 1.0001;
lightingFinal[i] = light / FAIRY_GROUP_SIZE;
}
for(int i = 0; i < FAIRY_GROUP_SIZE; i++) {
output.light += lightingFinal[i];
}
return output;
修改代码,移除数组相关代码,直接计算光线最终值:
//改后代码,移除lightingFinal数组相关代码
float3 v = in.v_view * (scene_z / in.v_view.z);
// Now, we have everything we need to calculate our view-space lighting vectors.
FragOutput output;
output.light = float4(0);
output.albedo = gBuffers.albedo;
output.normal = gBuffers.normal;
output.depth = gBuffers.depth;
for(int i = 0; i < FAIRY_GROUP_SIZE; i++) {
float3 l = (lightData->view_light_position.xyz - v);
float n_ls = dot(n, n);
float v_ls = dot(v, v);
float l_ls = dot(l, l);
float3 h = (l * rsqrt(l_ls / v_ls) - v);
float h_ls = dot(h, h);
float nl = dot(n, l) * rsqrt(n_ls * l_ls);
float nh = dot(n, h) * rsqrt(n_ls * h_ls);
float d_atten = sqrt(l_ls);
float atten = fmax(1.0 - d_atten / lightData->light_color_radius.w, 0.0);
float diffuse = fmax(nl, 0.0) * atten;
float4 light = gBuffers.light;
light.rgb += lightData->light_color_radius.xyz * diffuse;
light.a += pow(fmax(nh, 0.0), 32.0) * step(0.0, nl) * atten * 1.0001;
output.light += light / FAIRY_GROUP_SIZE;
}
return output;
点击按钮,重新加载Shader,各项数值已减小:
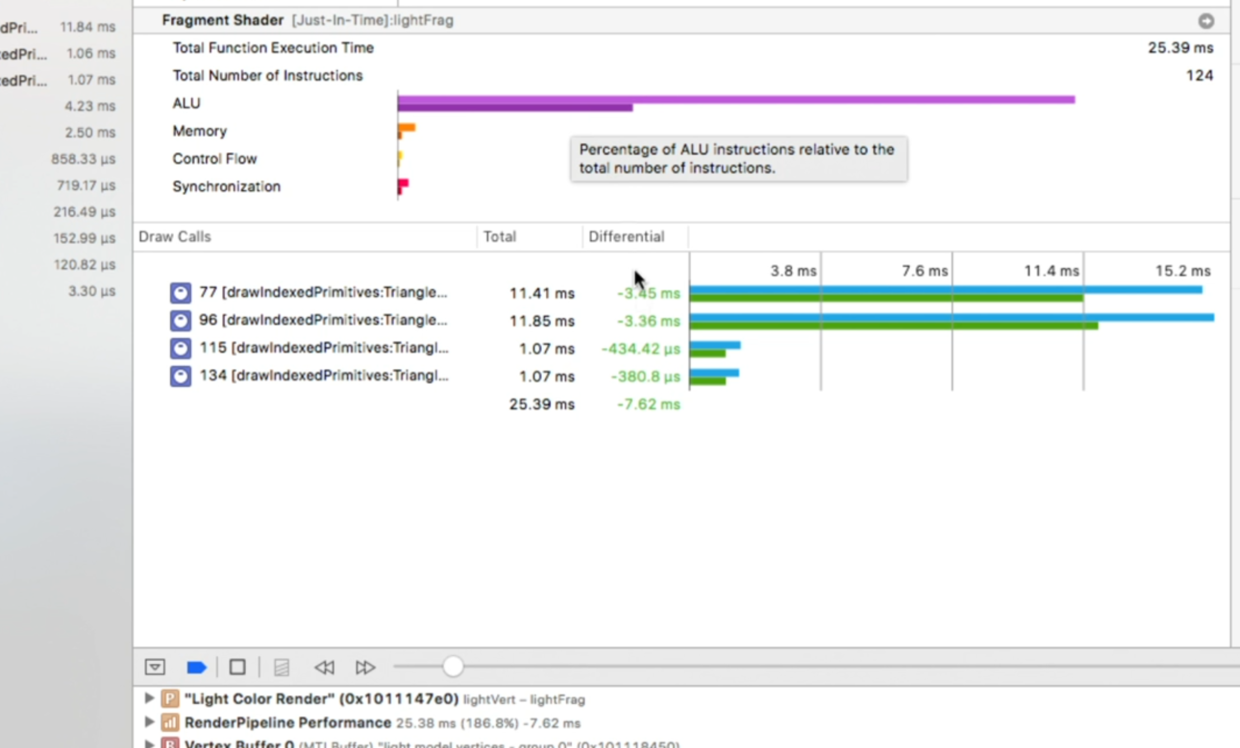
GPU Counter Profiling(GPU计数分析)
这个工具也是集成在Metal Frame Debugger中的,但并不针对于Shader.功能有图形化列表展示和瓶颈分析:
还是分析一个Demo,运行捕捉,进入帧调试器,选中GPU展示GPU Counter Profiling界面:
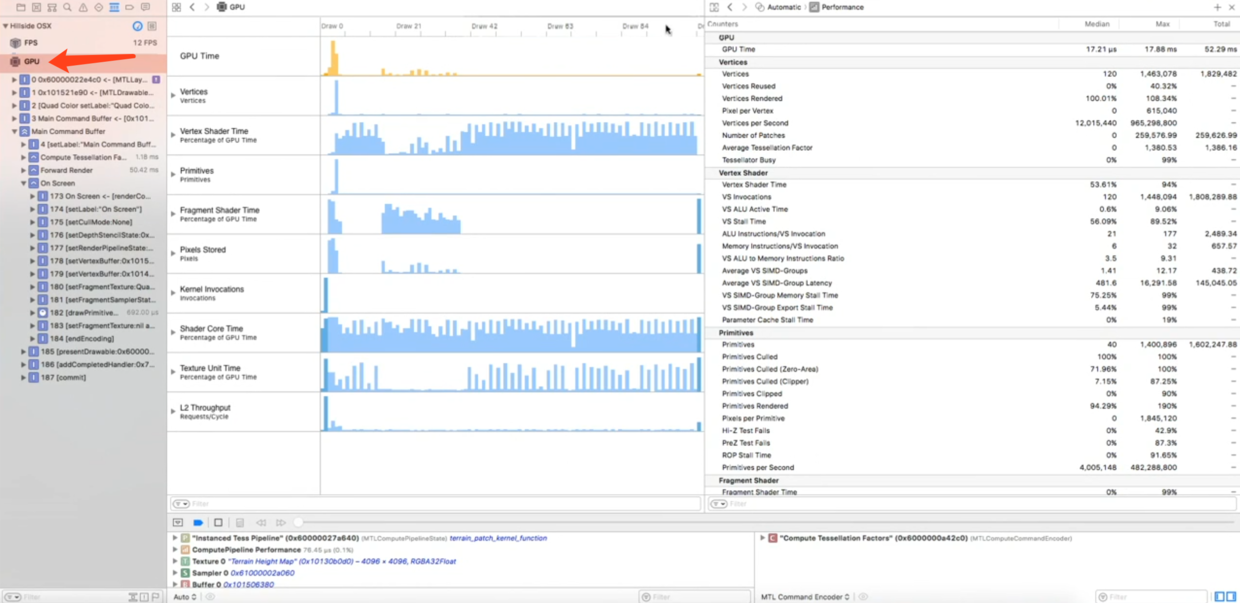
先看左侧图形化列表,双指放大,选中启动时的最高峰:
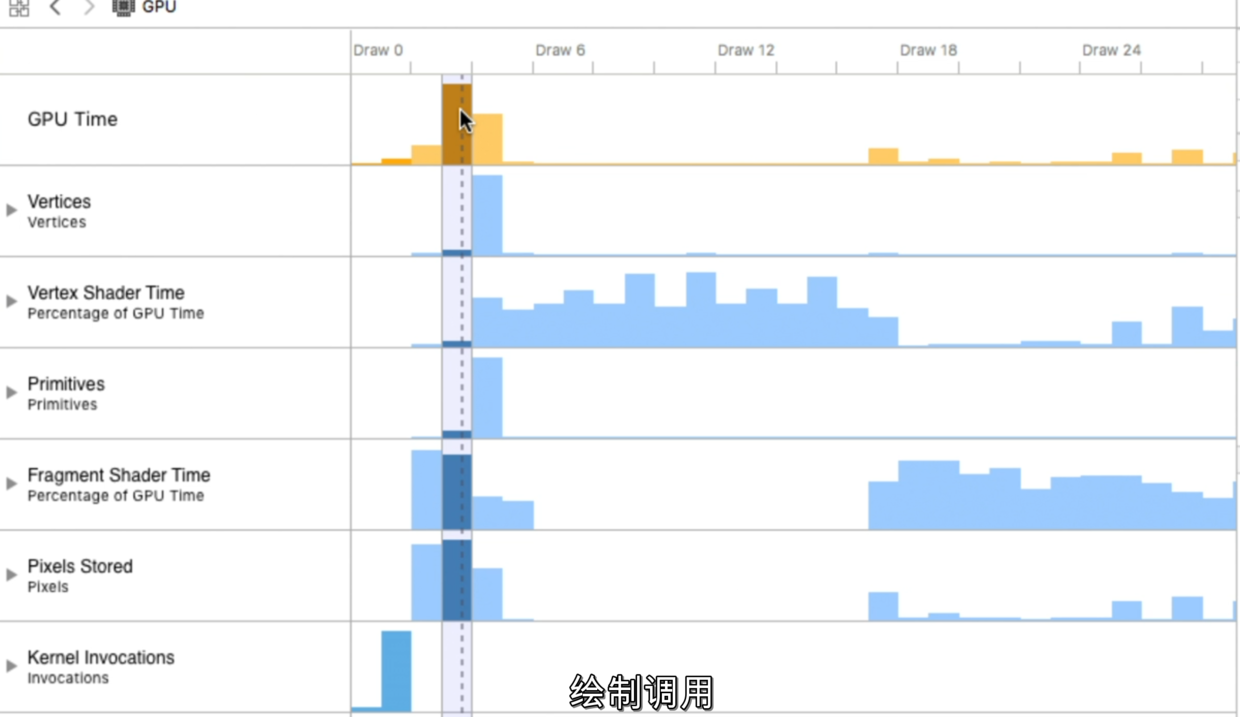
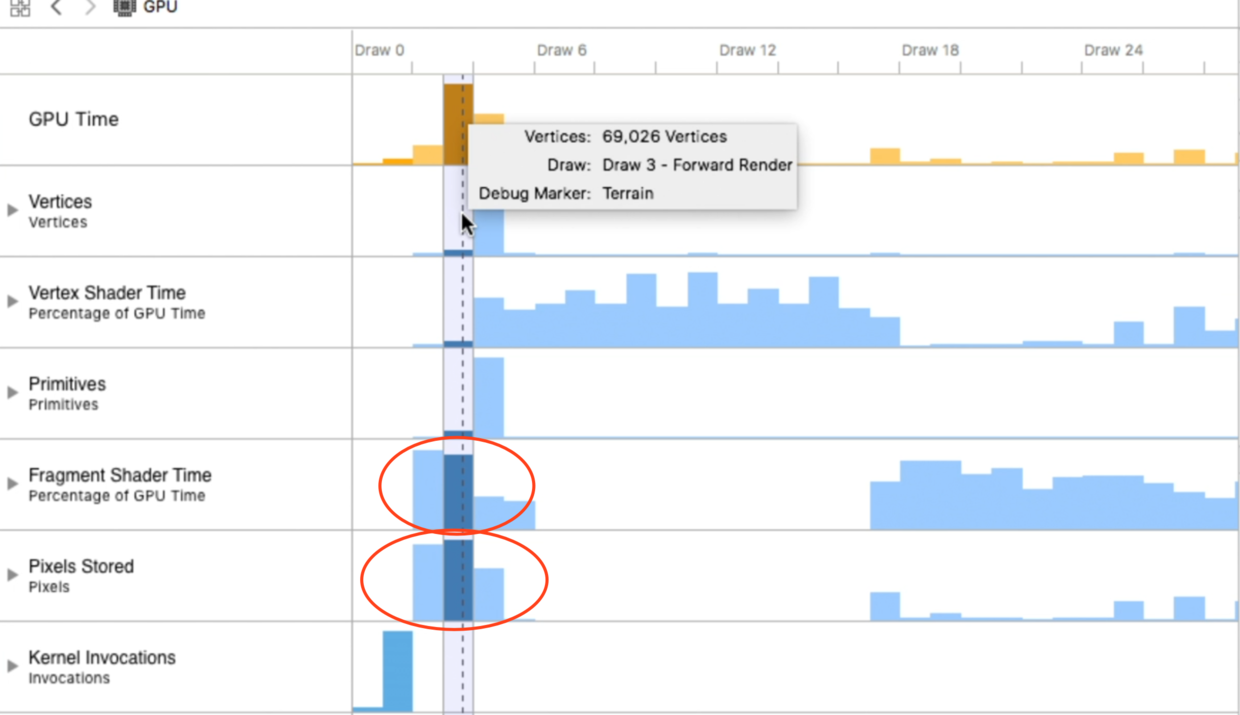
我们发现问题出在Fragment Shader Time和Pixels Stored上面,先展开第一个Fragment Shader Time进行分析:
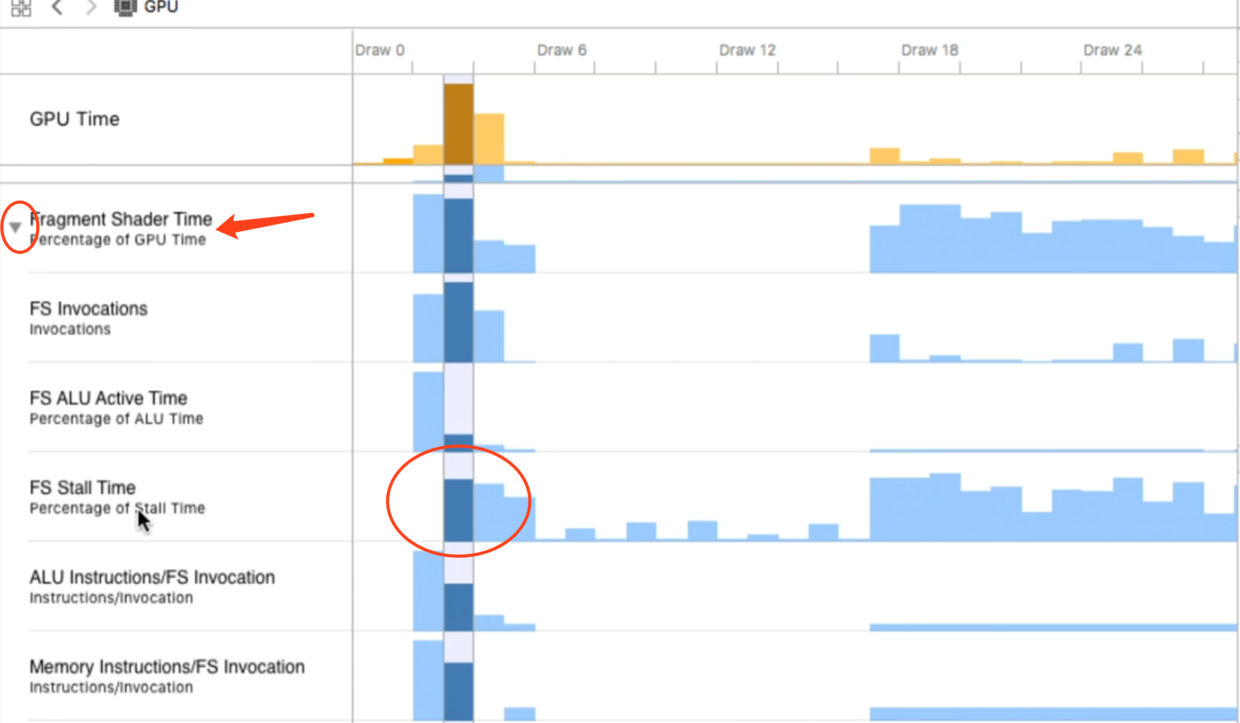
发现FS Stall Time很高,说明等待的时间非常长,这一般是由于从内存中读取图片或数据造成的.向下滚动查看纹理缓存的情况:
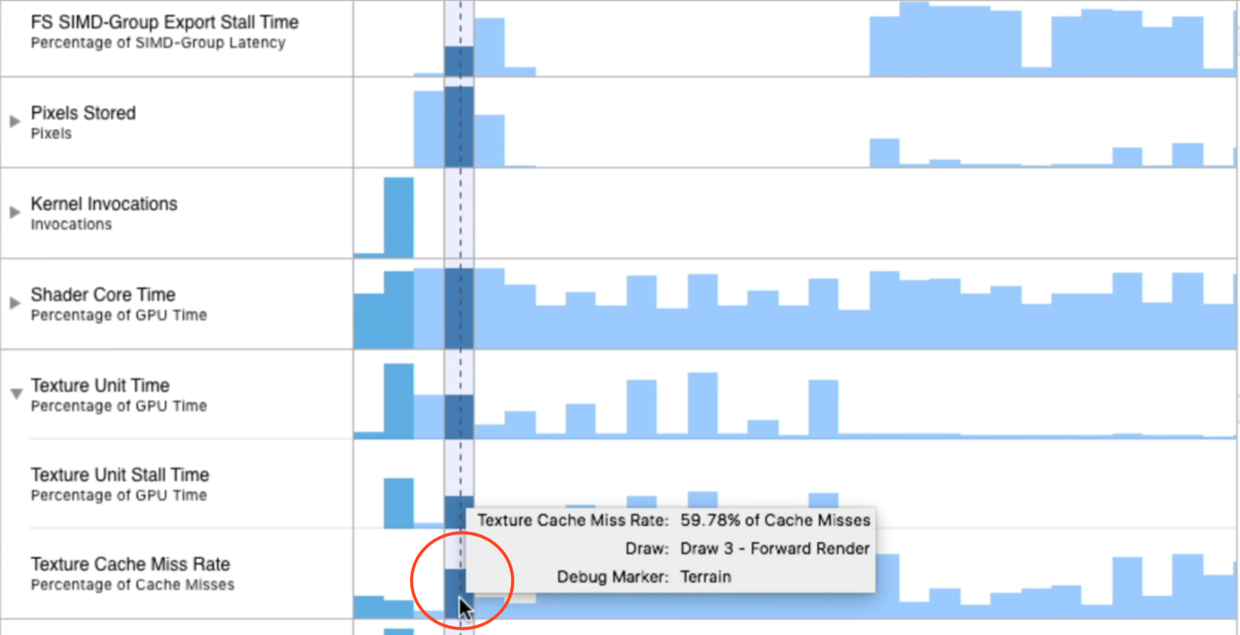
看到Texture Cache Miss Rate很高,也就说明纹理命中率只有不到40%,所以需要不断从内存中读取纹理,造成性能问题.这也解释了为什么前面Pixels Stored也很高.
具体哪里出现了问题,还需要看右侧的瓶颈分析数据表:
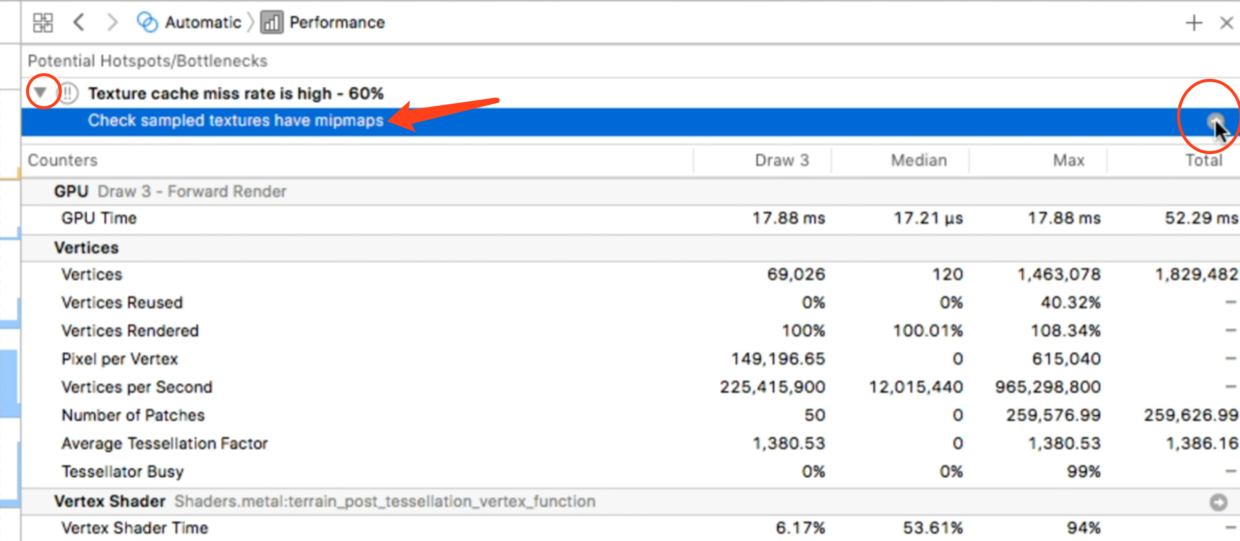
提示纹理可能没有mipmaps,点击右侧箭头:
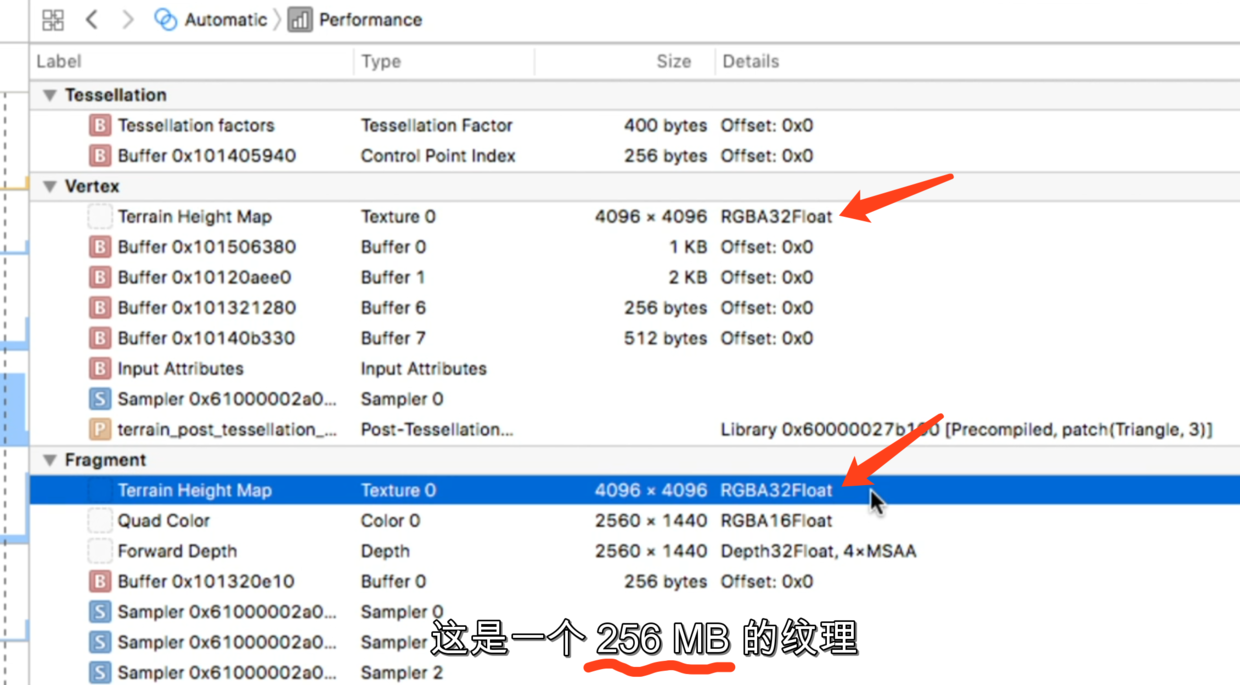
原来是加载了一个256M的高度地图,造成了缓存被大量占用,缓存命中率低,不断从内存读取图片,GPU不断等待.
原因找到!!
最后
Metal相关的调试技巧也适用于苹果的机器学习框架(基于Metal)中.学习相关技巧,受益很多.
由于水平所限,本文第二部分的高级调试基本是照搬苹果WWDC2017的演讲,具体在自己的项目中使用时,因为不同平台(macOS/iOS/tvOS),不同技术(SceneKit/SpriteKit,Metal/OpenGLES)还是会有一些不同的限制. 当然,最大限制还是在于自己是否足够了解图形学的相关知识,对此我深感力不从心,需要学习更多相关基础.
