

前言
最近在做自然语言理解处理相关的东西,主要是信息抽取方面的需求,由于没有好的公开数据集用作训练及测试,于是只能先自己去权威平台上爬取收集数据,所以这就涉及到了爬虫。
关于语言
写爬虫用什么语言?由于我较熟且常用的大语言是 java、c++ 和 python。所以用这三种语言写爬虫其实都可以很快写出来,之前写爬虫较多用 java,现在觉得在小项目且要求快速实现的场景下用 python 效率还是很高的,毕竟python有很多工具包而且本身就是一门表达能力很强的语言。而如果对性能比较看重可以C++,较大大型企业级项目看中可扩展可维护则可以java。另外大点的项目也要综合考虑下分布式集群方面。
scrapy解决普通需求
python中一般常用Scrapy框架来实现爬虫,上手很容易,通过scrapy startproject mySpider生成项目结构,如下,
D:\>scrapy startproject mySpider
New Scrapy project 'mySpider', using template directory ..
You can start your first spider with:
cd mySpider
scrapy genspider example example.com
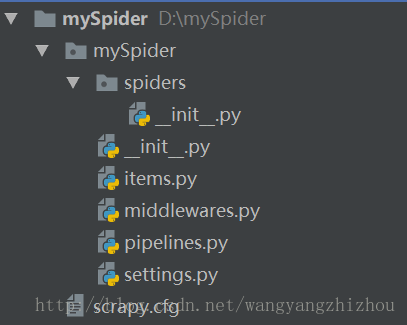
然后根据需要编写,
items.py中定义字段spiders目录下编写爬虫pipelines.py存储数据- 其他需求
以上完了直接scrapy crawl my_spider就开始爬。
遇到有js怎么办
现在很多网站都会需要执行js逻辑段,很多时候不执行js的逻辑就无法爬取,比如有些用js生成访问key等等,这时一般有三个思路解决:
- 硬翻译,就是死啃js源码,看懂逻辑后再翻译成爬虫语言实现一遍。
- 使用js执行引擎库,很多语言都有js引擎库,这时就把js逻辑交由库来实现,省掉了自己去搞js逻辑的工作,效果很理想。这种方式效率高,但有时有些网站访问需要的参数很多而且获取很麻烦,用这种方式代价较大。
- 调浏览器方式,这种方式其实是完全模拟了人工操作,它需要打开浏览器,然后通过脚本自动操作页面上的各个元素,从而实现抓取数据,比如让他自动翻页,自动下载等。这种方式效率明显低,但它基本不用自己去研究里面的各种参数,实现代价小。工具比如有selenium。
小结
在语言方面,在实现方式上面,根据不同的人,根据不同的工程需求及场景都是可以有不同的选择,这些都需要我们自己去思考然后选择一个适合该项目的方案。切忌手上有一个锤子就哪里看起来都像钉子。
-------------推荐阅读------------
------------------广告时间----------------
公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
鄙人的新书《Tomcat内核设计剖析》已经在京东销售了,有需要的朋友可以购买。感谢各位朋友。
欢迎关注:

