

1、简介
索引在数据库中用来提高查询的效率(类似新华字典的偏旁部首检索),可以避免全表扫描查询,索引也会占用数据库资源,避免滥用。
2、索引建立的原则
- 较频繁的作为查询条件的字段应该创建索引
- 唯一性太差的字段不适合单独创建索引,即使频繁作为查询条件
- 更新非常频繁的字段不适合创建索引(数据库会将索引数据根据算法排序,数据量大之后重新排序会占用过多资源)
- 用于索引的最好的备选数据列是那些出现在WHERE子句、join子句、ORDER BY或GROUP BY子句中的列。
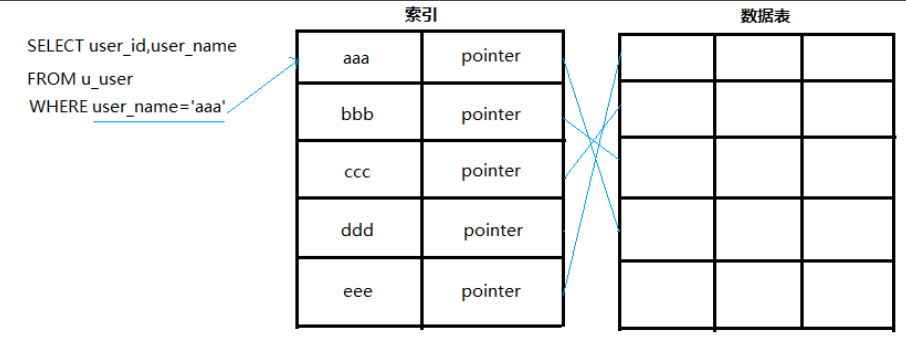
3、复合索引的建立以及最左前缀原则
唯一性太差又经常作为查询条件的字段可以建立复合索引,假设在USER表的name、salary和city数据列上建立了复合索引。索引中的数据行按照name/salary/city次序排列,所以即使你在查询中只指定了name值,或者指定name和salary值,MySQL也可以使用这个索引。因此,这个索引可以被用于搜索如下所示的数据列组合:
name,salary,city
name,city
name,salary
name
在实际使用中发现:

1)2,1也是用到了索引的,这里可能大家会疑惑违背了最左前缀原则。其实这是因为把where后条件反过来变成name='aa' and salary=300得到的查询结果是一样的。这时MySql的查询优化器会判断这条语句执行效率最高的执行顺序,最后生成真正的执行计划,所以最后MySql会以name='aa' and salary=300这种顺序查询,这就用到了索引。

2)这两种情况都用到了索引,似乎有点出乎预料。这里是因为可以直接从索引里返回查询记录,所以用到了索引全扫描,实际扫描的行数为全部行数。但并没有进行全表扫描,还是用到了索引。
4、索引类型
- 唯一索引:不允许两行具有相同的索引值(主键索引是唯一索引的特殊类型)
- 聚集索引:该索引中键值的逻辑顺序决定了表中相应行的物理顺序,每个表只能有一个
- 非聚集索引:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。 索引是通过二叉树的数据结构来描述的,可以理解为聚集索引的叶节点就是数据节点。而非聚集索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
5、执行计划explain中type类型:
- null: MySQL不访问任何表或索引,直接返回结果
- ALL:全表扫描
- index: 索引全扫描
- range: 索引范围扫描,用于<,<=,>=,between等操作
- ref: 使用非唯一索引扫描或唯一索引前缀扫描,常出现在关联查询中
- eq_ref : 类似ref,区别在于使用的是唯一索引,使用主键的关联查询
- const:使用主键查询时出现,代表系统会把匹配行中的其他列作为常数处理(最优情况)
写博客是为了加深自己的一些理解,如果有错误的地方欢迎指正,大家互相交流。