

上一期文章我分享了一些视频播放里面的术语和基本概念。这一篇文章我会主要介绍容器(container format file)格式文件的细节,以最常见的MP4文件入手。然后会简短的介绍一个标准的播放器的启动,解析,播放流程。本篇还是以基础知识为主,虽然很枯燥,但是对视频开发的学习有非常大的好处,我自己个人的感受就是,如果在很多专有名字,概念都不熟悉的情况下,想要去阅读播放器源码会是相当困难的事情。比如Exoplayer,谷歌的分包策略就是根据播放器的组件来分包。如果不熟悉播放器的基础构建的话,连哪个部分的代码在哪个包都不知道。希望大家如果真的想进阶的话还是耐心的理解好每个基础概念。

- Mp4格式文件的构成
- Mp4头文件的构成
- 标准播放器的启动流程
- 在线视频播放的技术基础(online video streaming)
1. Mp4格式文件的构成
在上期我们大概介绍了Mp4文件的结构
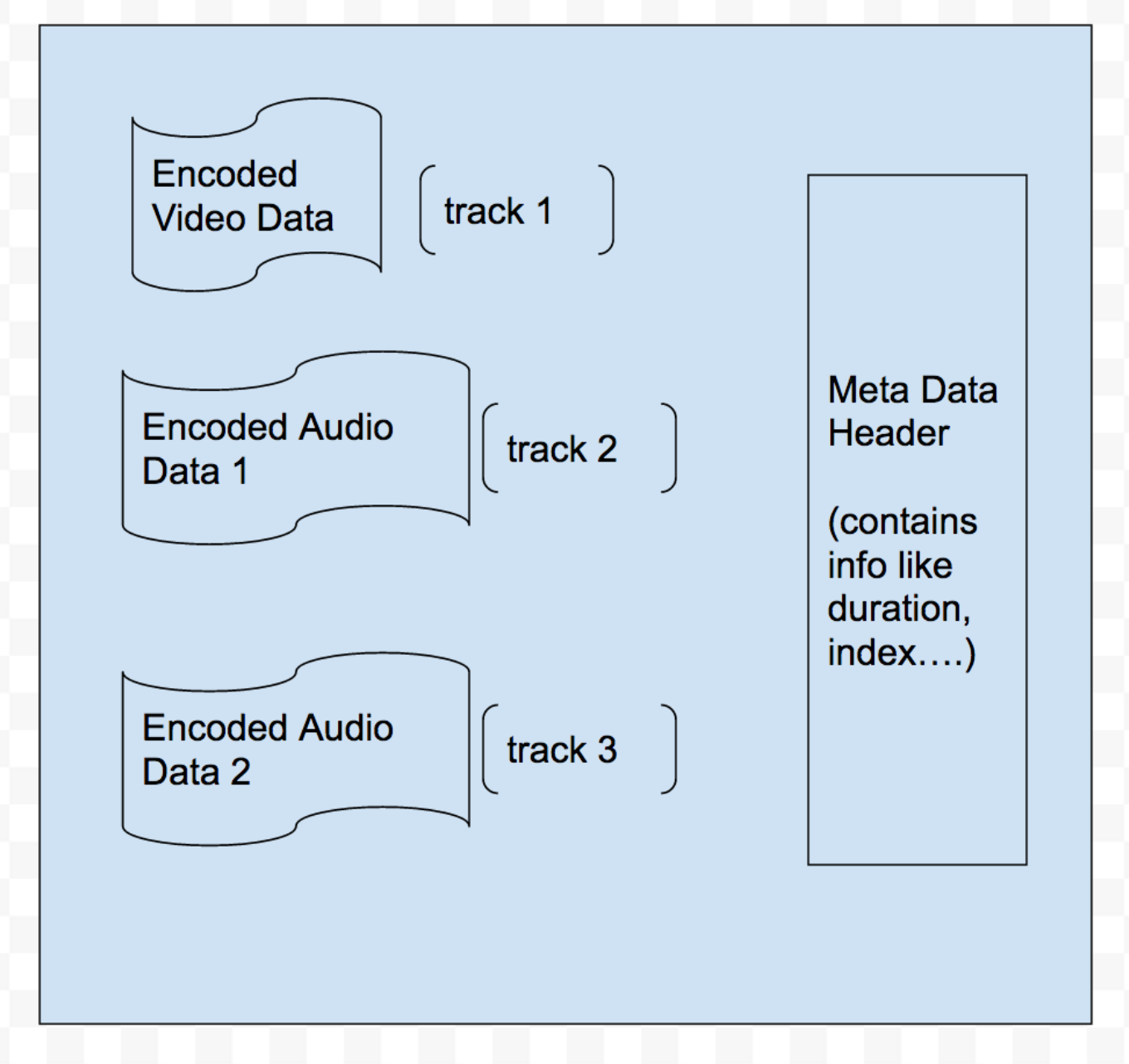
但是这样抽象的介绍可能还是比较难理解,我们深入一些。
1.1 MP4到底是个啥?
通俗的说,MP4其实是一种格式的规范,这个规范是被ISO机构认证的,也就是说,只要你通过Codec生成了一个mp4文件,那么这个文件的格式必须是按照ISO机构的规矩来。。。。既然是规范,那么我们看看到底ISO对mp4做了什么规范:
请大家打开链接->ISO的mp4文件规范
大家可能会有点懵逼,看不懂。其实这个规范很好理解,它定义了一个MP4文件里面,哪些数据应该放在什么位置(以字节为单位),哪些数据的长度是多少。我截取了一段:

大家看,上面这一段规范定义了ftyp这个头文件header所在的位置和长度(以字节为单位)。 至于这些头文件是有什么用,我在上一篇文章大概提到过,他们属于meta data的一部分。在本章我会更详细的介绍。
所以说,任何容器,包括mp4都是类似的结构化文件,只不过不同的格式文件ISO对其有严格的要求,数据的摆放顺序,排列等等不同而已。有兴趣的同学可以对比一下rmvb,mp4,mkv这些格式的要求有什么不同,优劣势各是什么。
2.Mp4头文件的构成
关于mp4文件的头文件格式(meta data),苹果官网对其进行了详细的描述(这个介绍是基于QuickTime播放器支持的mp4文件来介绍的,quciktime播放器对mp4的要求有些许不同,但是差别不大,我们可以忽略):
我们不追究太多细节,有兴趣的同学可以自己查看,我们专注于一些基础的信息。
首先,在Meta Data里面,每一个Header,头文件,我们都叫他们Atom Header(不知道咋翻译)。Atom Header分为Leaf Atom 和 Container Atom。前者代表一个连接着字符串信息的头文件,后者是一个包含了若干个子Atom的头文件,他们互相之间是有层级关系的(参考上图)。每次播放器获取了movie atom之后(moov),会根据层级关系,向下,或者向下读取相关的其他信息。每一个头文件都会对它的子头文件保存位置的引用,所以只要根据mp4文件的规范获取了最顶级的头文件moov,就可以顺势往下读取其他头文件了。
我们来看看mp4的头文件结构
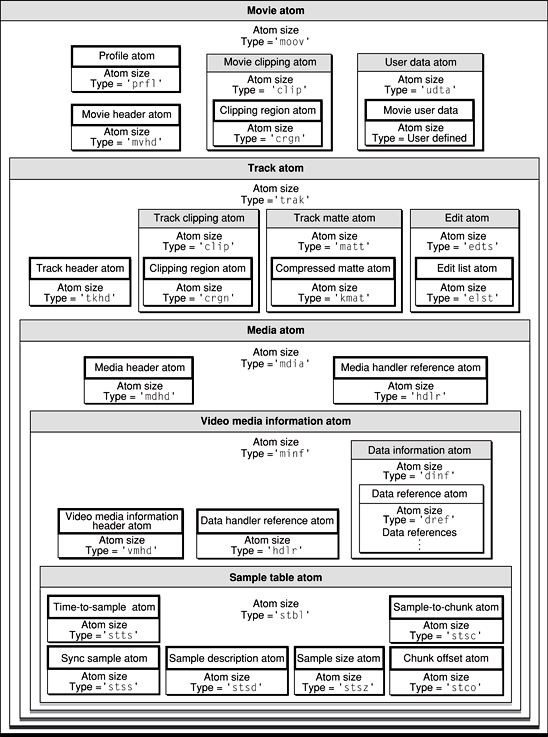
看起来很复杂,但是对于一个播放器来说,很多信息都不是必须。我们需要知道的最重要的信息是采样索引表(Sample Table Atoms).对应图中“**stbl **”这个atom header。这个索引表保存了mp4文件所有的采样(sample)与视频时间的对应关系(一般以微秒为单位),还有包括每个采样的大小,在mp4文件中的起始位置(以自己为单位)。
3.标准播放器的启动流程
那么既然我们已经知道一个容器文件的格式规范了,播放器就可以通过解析容器的头文件来控制播放(playback)了。
3.1 播放器
通常播放器由三个部分构成
- 读取器(Extractor)
- 渲染器(TrackRenderer)
- 加载控制器(Load Controller)
- 数据源(Source)
读取器负责从source文件读取数据,加载控制器负责控制读取数据的策略(比如说在线视频播放的时候缓冲策略),渲染器负责接收读取器读取的数据,并渲染到屏幕上。
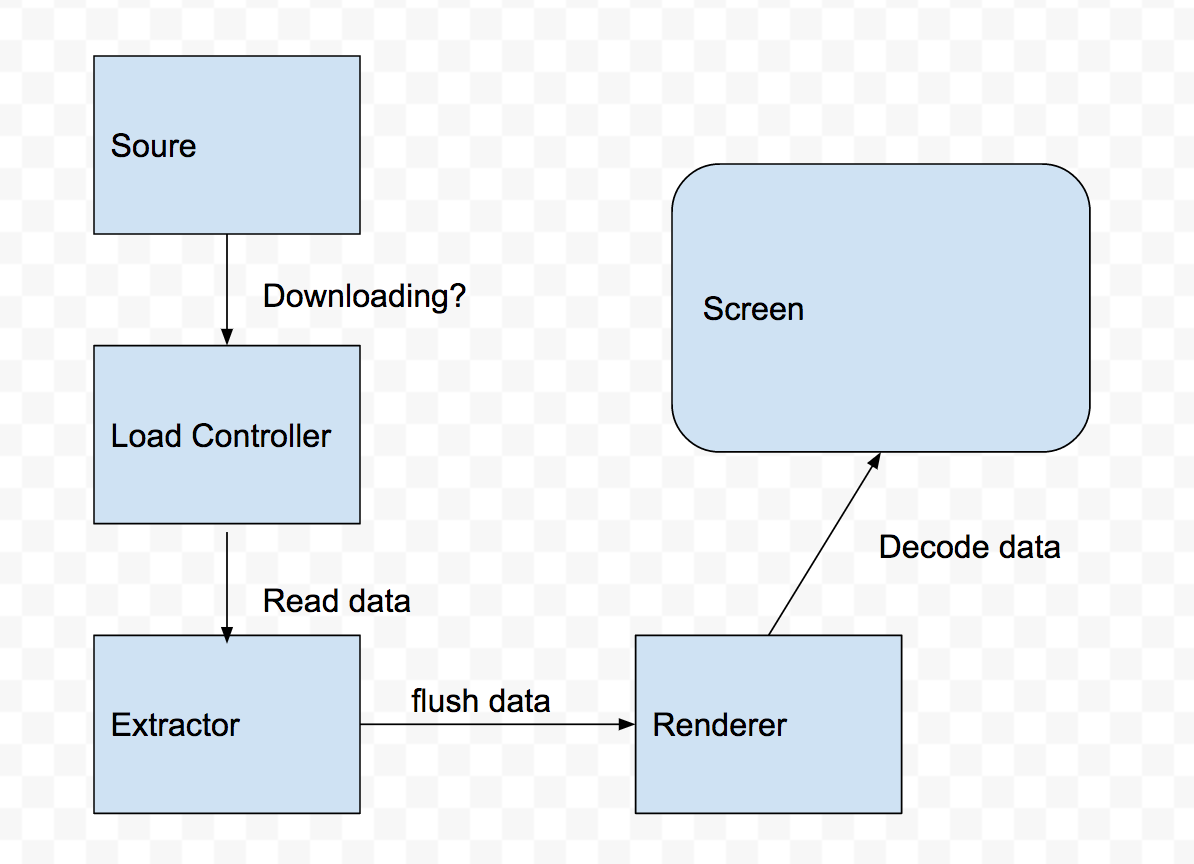
3.2 播放器的播放过程
在播放器可以把数据提交给渲染器之前,播放器需要把必需的头文件全部解析并存入内存,比如之前说的采样索引表。一般播放器在解析完毕后,会构建三个个表,一个存放时间对应采样索引,一个存放采样索引对应在mp4文件中的起始位置(以字节为单位),一个存放采样索引对应大小(以字节为单位)。以下图为例
假设播放器需要从第1微秒开始播放,那么需要把第1微秒的数据放入渲染器。所以会查找下面这三个表。
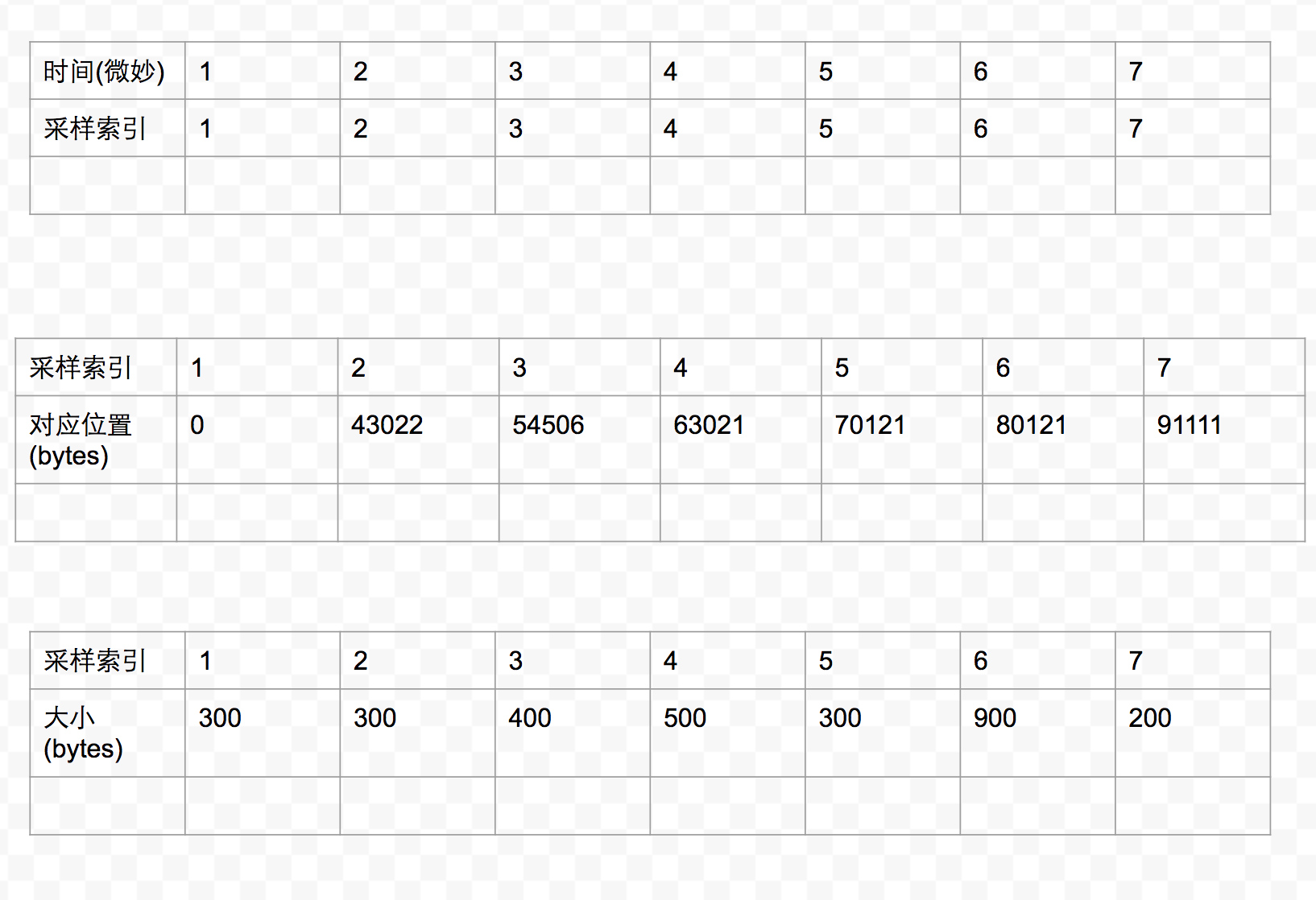
通过表1,我们知道该微秒对应第1个采样(sample),从第一个和第二个表我们知道,第1个采样的数据范围(在mp4文件内)是从第0字节到300(0+300)字节,那么播放器就会去读取这个范围的数据并且放入渲染器中进行渲染。
同时,加载器会基于当前已经缓存的数据,决定是否还需要不停的读取数据进入内存。一般来说每个播放器都有默认的缓存值,也会有一个基准线,只有当缓存足够数据才能放进渲染器进行渲染。
最后同理,当我们拖动滑动控制器(SeekBar)想快进的时候,我们和第一步一样,通过我们想滑动的时间获取采样的索引,再重新开始读取数据。
综上所述,播放器在正式播放视频文件之前,必须要把头文件全部读取并解析(这会是一段非常耗时的程序),这也是在线视频播放的等待时间的瓶颈。在接下来的章节我会介绍自适应视频播放(Adaptive Streaming),这个技术的发明使得了分段式mp4文件(Fragmented Mp4)技术得以诞生,大大的减少了在线视频播放的等待时间。
4.在线视频播放的技术基础(online video streaming)
在线视频的播放其实和播放本地视频的局别就是Extractor读取的Source,数据源不一样,在线播放需要下载数据到内存,再交由Extractor读取分析。但是既然是在线视频播放,我们肯定不能把整个容器文件下载到内存或者硬盘再开始解析播放。我们希望能控制下载的进度,比如我当前在看第10s的视频内容,所以我只想缓存/下载视频内容到第20s的位置。
我们俗称的渐进式下载(Progressive Downloading)就解决了这一难题。
说的好像是很吓人的黑科技啊!!!!

其实就是HTTP1.1协议支持的分段式下载而已。。。。。
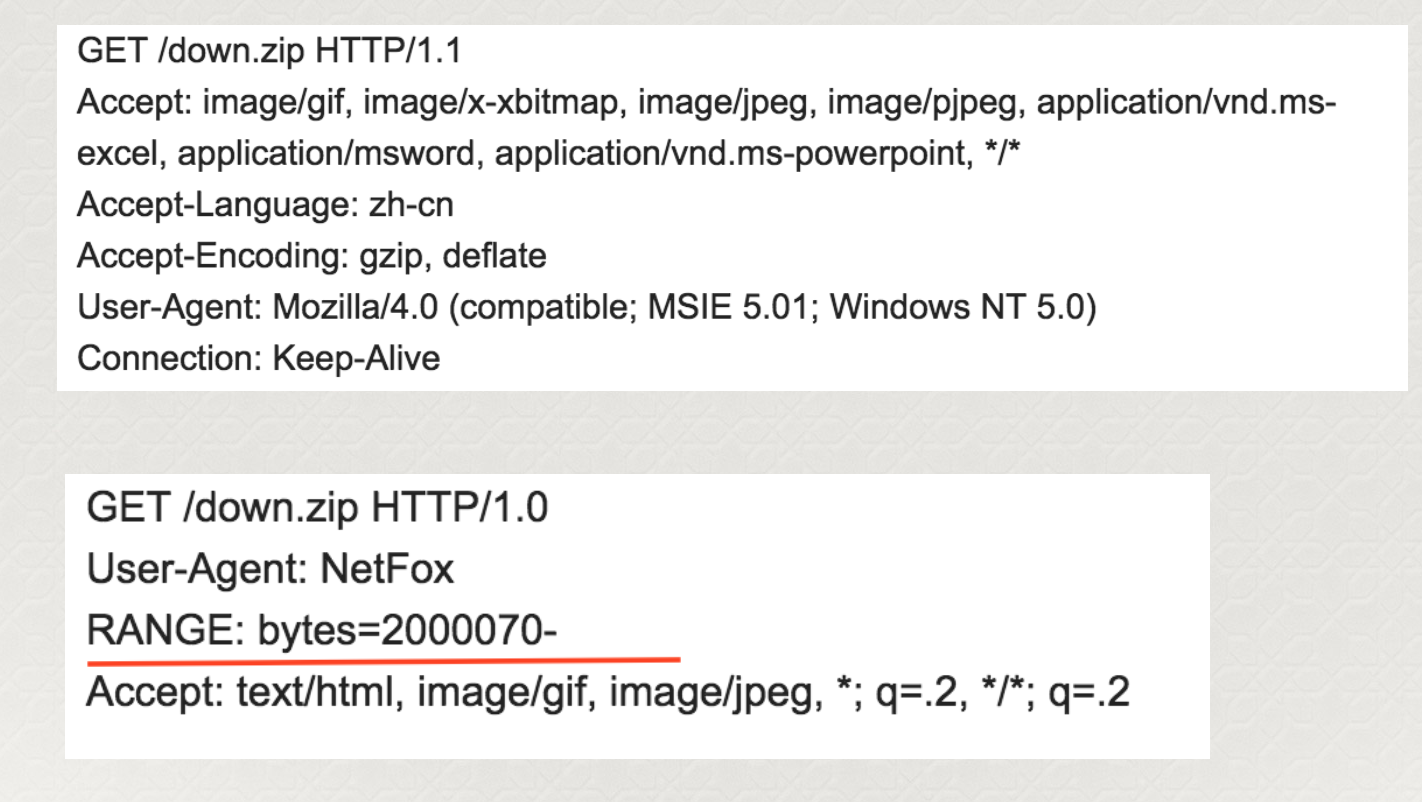
在HTTP请求里面假如一个叫RANGE的header,放入起始字节和结束字节,就可以只下载对应部分的数据,这一header的支持也是各种下载软件实现断点下载的基础。每次断网的时候记录下来已经下载的数据的字节数,下次再下载的时候从字节数+1处重新下载并且写入原有文件就可以了。
分割线
所以这次分享就结束啦,下一期分享我会开始进入正题,在安卓平台里面,对视频播放的支持,像api啊等等,以及其变迁历史。

周末愉快!
