

这个系列的目标受众是区块链开发者和CS专业同学
面对媒体对区块链相关技术的解读和吹捧,许多人一时不知所措。投资人、大公司都在FOMO(fear of missing out)的心理驱动下,争相宣布all in区块链。各路大咖坐而论道,谈论区块链技术的社会、政治、经济乃至哲学上的意义。人类对未知和不懂的东西有种天然的不安全感,作为一名开发人员,我认为克服焦虑(以及带来的投机心理)最好的方法是尽可能增加对底层的原理及实现的认知。
从技术角度来看,目前不论是比特币、以太坊,抑或是尚未正式上线的EOS、IPFS,都带有很强的实验性质,存在各种局限,而这种局限不可避免影响上层应用的开发。区块链应用也大多涉及金融、信用等重要领域,所以深入理解底层原理是对区块链开发者的一个基本要求,而不仅仅是跟着教程10分钟部署一段智能合约,特别是早期各种技术未成熟的情况下,生搬硬套稍不留心就会造成极大的损失。
本系列的第一篇文章,主要是以比特币为代表的加密货币架构(区块链1.0),和以以太坊为代表的可编程分布式信用基础设施(区块链2.0)的核心差异之一——是否支持图灵完备的语言,来看看区块链技术架构的演进。
比特币和以太坊的渊源:对币圈和链圈的人来说,Vitalik Buterin(1994年出生)是无可争议的大神。很多人可能不知道,V神作为早期比特币社区的活跃成员,一开始提议bitcoin需要开发通用的脚本语言来支持丰富功能的应用开发,但没有获得比特币开发团队的支持。于是重起炉灶,2013年发起以太坊项目,有了今天的繁荣的加密token、收藏品游戏、DAO。我们就先看看,V神不满的比特币脚本系统到底是什么样的?
Part I:比特币脚本引擎
交易
交易是在区块链世界里面有很广泛的含义,在加密货币应用中可以狭义理解为比特币额度在不同地址间的转移,即转账。转账是个历史悠久的行为,但转账技术一直在革新。 理解比特币转账模型尤其重要,因为比特币脚本引擎建立在该模型之上。
两种转账方式
1、简化下的传统中心式转账:alice(A账户)转账到bob(B账户)x元,银行需要原子化的操作balance[A]-=x,balance[B]+=x,当然隐含条件是alice完成了对A账户的认证。
2、一种解释比特币交易原理的说法:
网络中每个节点维护独立的数据库,记录着每个地址的余额,如果Alice(addressA的拥有者)想向Bob(addressB的拥有者)转账x元,她会在网络中广播出去"addressA gives X units to addressB",带上pubkeyA,用privatekeyA签名。每个节点收到后,校验成功后,在各自数据库中执行原子化操作balance[addressA]-=x,balance[addressB]+=x。(注:实际地址由pubkey生成,这里为简化省略)。
上面1在现实中占据主流,有成熟的扩展方案,但中心化不可避免带来成本、平台作恶等问题; 2的描述来自于b-money, an anonymous, distributed electronic cash system(这篇文章非常之重要,深刻影响了中本聪对比特币的设计),但在当时无法实践,因为重度依赖于一个同步、不受干扰的网络环境,否则保持一致性难度很大。而且这种分布式数据库提交问题(Byzantine Problem),现有的一致性算法paxos、raft(non-byzantine)包括pbft(byzantine)扩展性都无法支撑比特币上万的节点数。
比特币交易模型的设计
关于比特币交易模型最早来自于中本聪的 Bitcoin: A Peer-to-Peer Electronic Cash System。中本聪实际提出了两种chain,大家现在一直说的区块链(chain of blocks)是显式的数据组织方式,另一个隐式的是交易链(chain of transactions)才是比特币价值流动的链条。
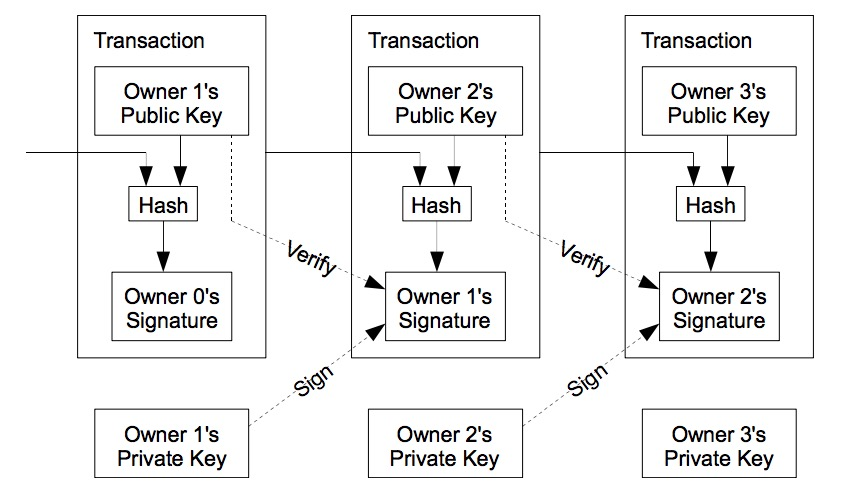
如图,最早的交易描述模型:
如果Alice(addressA的拥有者)想向Bob(addressB的拥有者)转账x元,她同样需要把这个交易签名后在网络中广播出去。不同的是,addressA的余额,并非存储在各个节点的数据库里,而是在别人给addressA转账的未花费交易输出中,即UTXO(unspent transaction output)。我们查询addressA的余额,实际得到的是所有收款地址是adressA的UTXOs的额度的求和。广播内容类似"addressA(combining UTXO1...UTXO3) gives X units to addressB",带上pubkeyA,用privatekeyA签名。 交易在网络中被确认后,Bob就会多了一个可用UTXO。如果他想花费这笔钱,需要证明自己拥有addressB对应的privatekeyB,那么Bob也用私钥签名。这样交易就成了一串签名的链条。
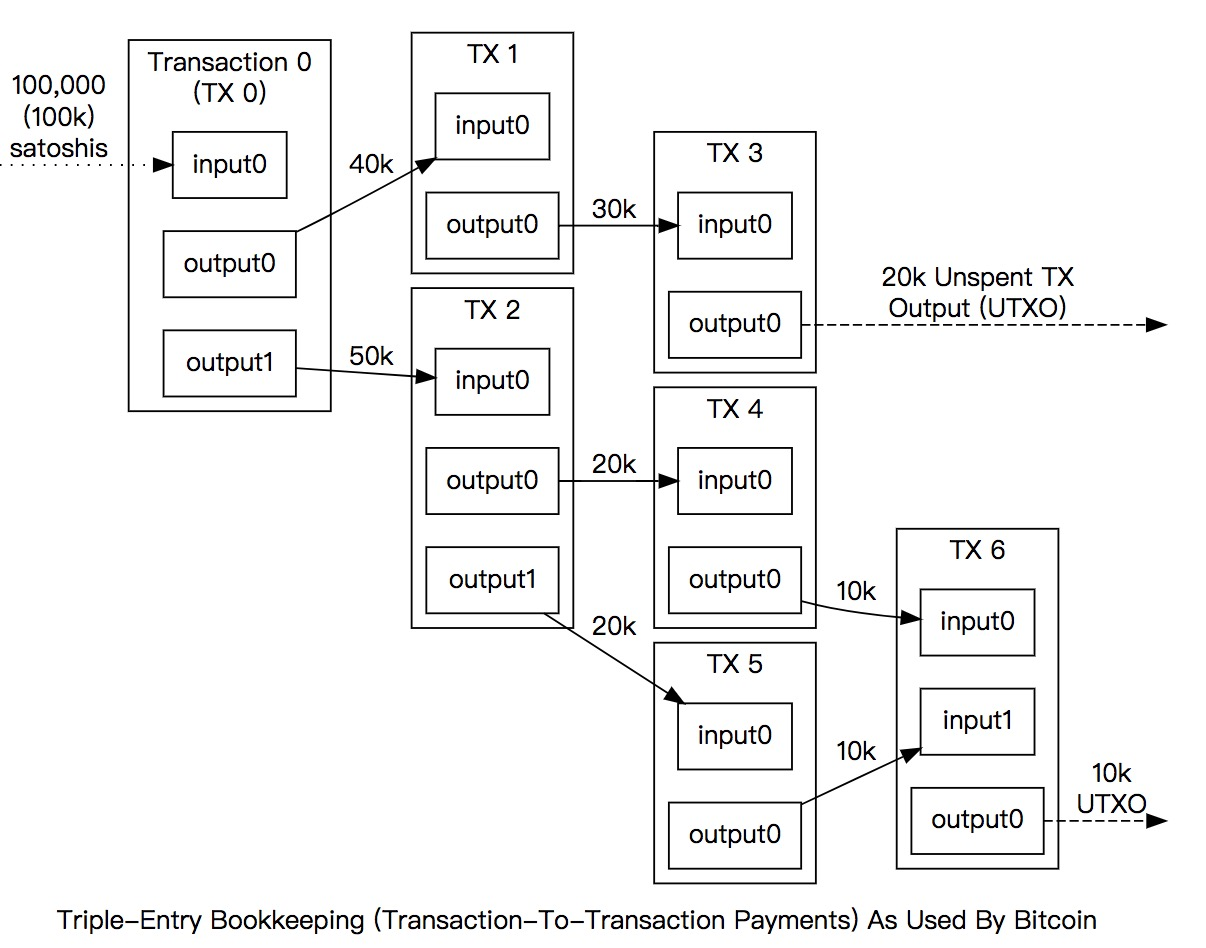
显然这里有三个问题:
1.如果任意的交易的input都需要某个之前交易的输出,那么最初比特币从哪里来?
所以在比特交易中,有种叫做coinbase的交易,就是我们所周知的挖矿奖励。比特币的产生就通过挖矿算法生成,这里的input来自于系统奖励。实际上还会校验coinbase是否是"mature"的,即该块是否经过足够的确认。在比特币中如果最终没有归入最长链,那么会作为orphan块被弃,奖励也作废。
2.判断一个交易输出是否是UTXO需要回溯整个区块链吗?
不需要,因为交易按照merkel tree的结构组织,决定了从整个区块链数据库中查询一个交易会非常低效。UTXOs专门存储在leveldb的数据库chainstate中,并且缓存在内存中。每当一个新的block生成,就会更新UTXOs集;当某个节点发生链重建现象,会回滚该过程。这里需要注意的是,UTXOs集不是待确认交易池(TxMemPool),而是所有待确认交易的input来源;UTXOs理论上也可以通过--reindex从整个区块链中重建。
3.Alice的账户余额来自于四个UTXO,分别是0.05,0.2,0.2,0.3,现在需要转帐0.6给Bob,怎么办?
理论上Alice可以三次转,但实际上很不明智,既要多付手续费,体验也差,所以交易Input可以包括多个UTXO,如何选择UTXO组合有专门的分析;多个Input之和不一定恰好等于转账金额Output1,还需要一个找零钱refund(Output2),当然还会有手续费fee(Output3),所以交易会包括多个Output。当然对于用户来说,只需要设定转账地址、额度、手续费,组合UTXO、找零等是透明的。
注:以太坊摒弃了UTXOs模型,采用类似于bmoney的账户范式。具体原因等到介绍以太坊虚拟机设计中再分析。
做了这么多铺垫,终于可以进入比特币的脚本设计了。
Script opcodes
比特币交易由一套脚本引擎(Script)处理。这里引用bitcoin-core源码interpreter.cpp里的一段注释:
/**
* Script is a stack machine (like Forth) that evaluates a predicate
* returning a bool indicating valid or not. There are no loops.
*/
Script是一种类Forth、基于栈式模型、无状态的、非图灵完备的语言。 opcodes分为常量、流程控制、栈操作、算术运算、位运算、密码学运算、保留字等若干类,还包括3个内部使用的伪指令。下面举几个在后面的脚本中会出现的指令,全部的指令可参考官方文档和源码。
- OP_0 ... OP_16: 将字面量值压入栈中。
- OP_DUP: 将栈顶元素复制一个,压入栈中。
- OP_ADD: 弹出栈顶元素和次栈顶元素,相加后压入栈中。
- OP_EQUAL: 弹出栈顶元素和次栈顶元素,比较是否相等,相等则将1压入栈中,否则压入0。
- OP_SHA256: 弹出栈顶元素,进行sha-256加密运算,结果压入栈中。
- OP_HASH160: 弹出栈顶元素,先进行sha-256加密运算,再进行ripemd160摘要运算,结果压入栈中。值得注意的是,这是基于公钥生成address的过程的一部分。
- OP_CHECKSIG: 弹出栈顶元素和次栈顶元素,这里分别是sig和pubkey;内部有个VerifySignature函数,验证签名和公钥是否匹配。
- OP_CHECKMULSIG:栈内压入m个签名,n个公钥,逐一校验m个签名是否对应n个公钥的某个子集。
Pay-to-PubkeyHash(P2PKH)
上面Alice转载给Bob的例子,就是一个典型的P2PKH。中本聪在论文中只是给出了交易模型,下面看看更具体的实现。
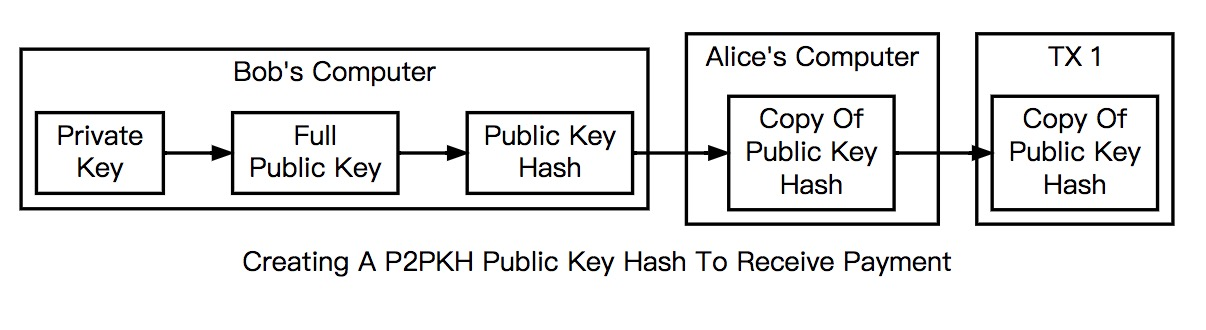
如上图,Alice在转账给Bob前,Bob需要提供一个自己的收款地址,但实际P2PKH中使用的是Public Key Hash。这里简单补充下key生成过程,如下图,私钥单向生成公钥,公钥通过OP_HASH160指令生成160位的PKH(公钥哈希),PKH可以转成更可读用户使用的地址,但编码、校验过程等是双向的。所以提供地址等价于提供PKH。
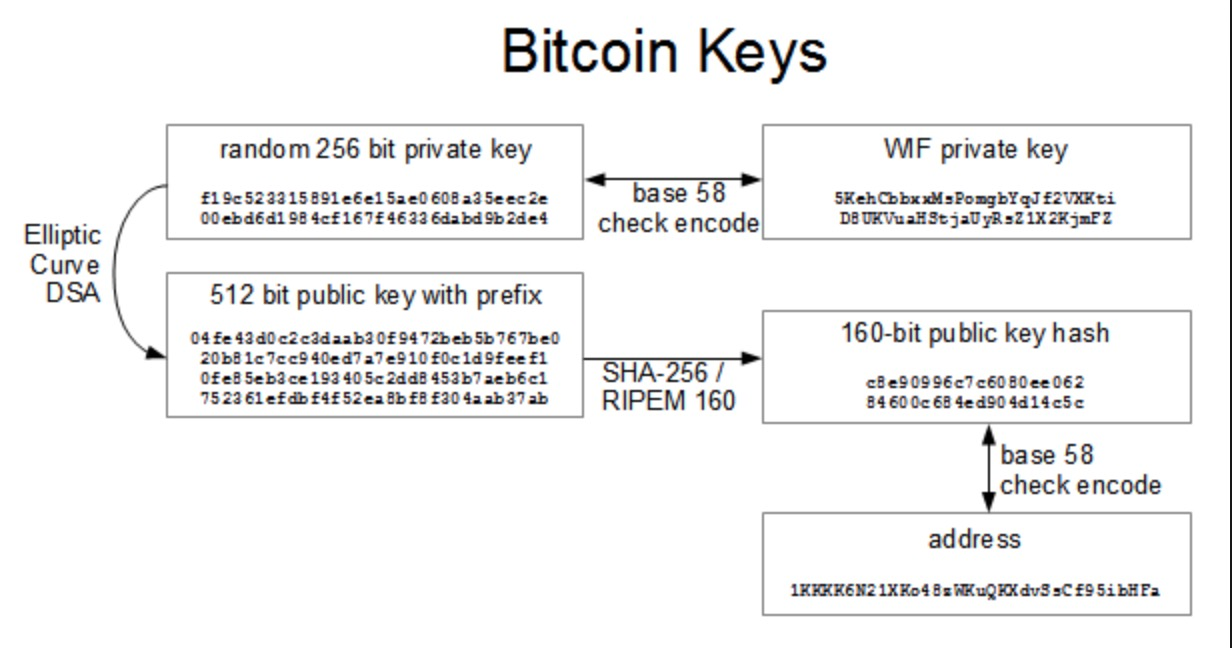
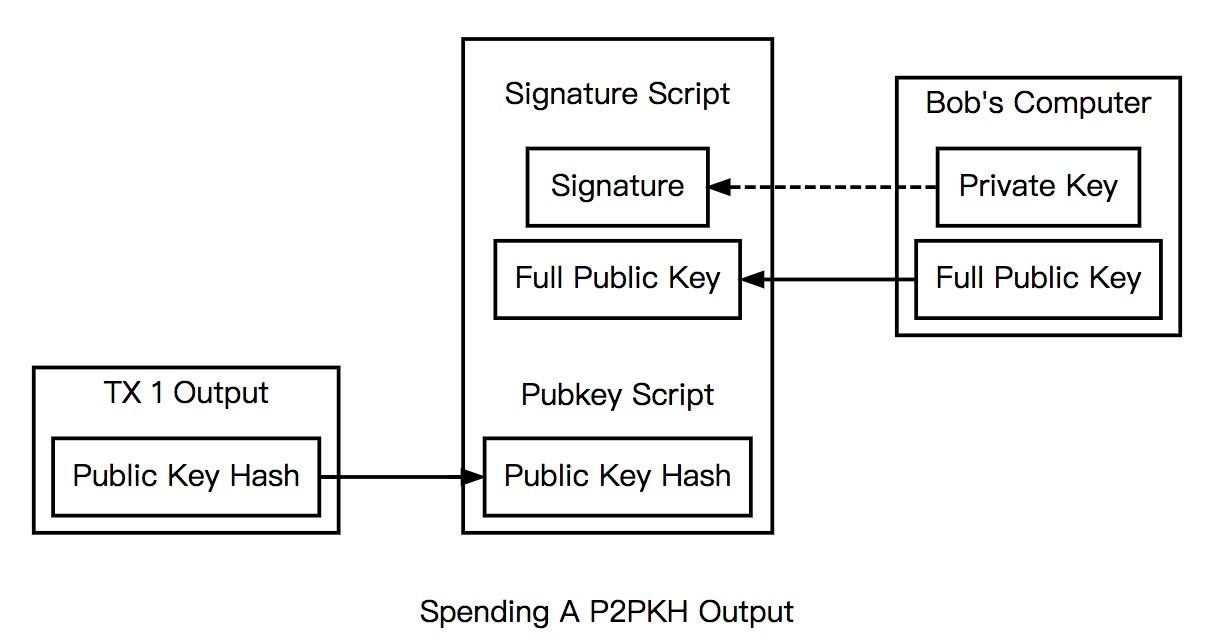
下面就是这两个脚本。
锁定脚本:
scriptPubKey: OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG
解锁脚本:
scriptSig: <sig> <pubKey>
上面包括在<>之间的为要压入栈中的数,push指令缺省。实际执行时,会将scriptSig和scriptPubkey连接起来,按照从左往右顺序运行脚本。
验证过程:
<sig> <pubKey> OP_DUP OP_HASH160 <pubKeyHash> OP_EQUALVERIFY OP_CHECKSIG
栈上的情况如下面两图所示。有汇编基础的同学,对栈式计算机模型的运作原理会很熟悉。
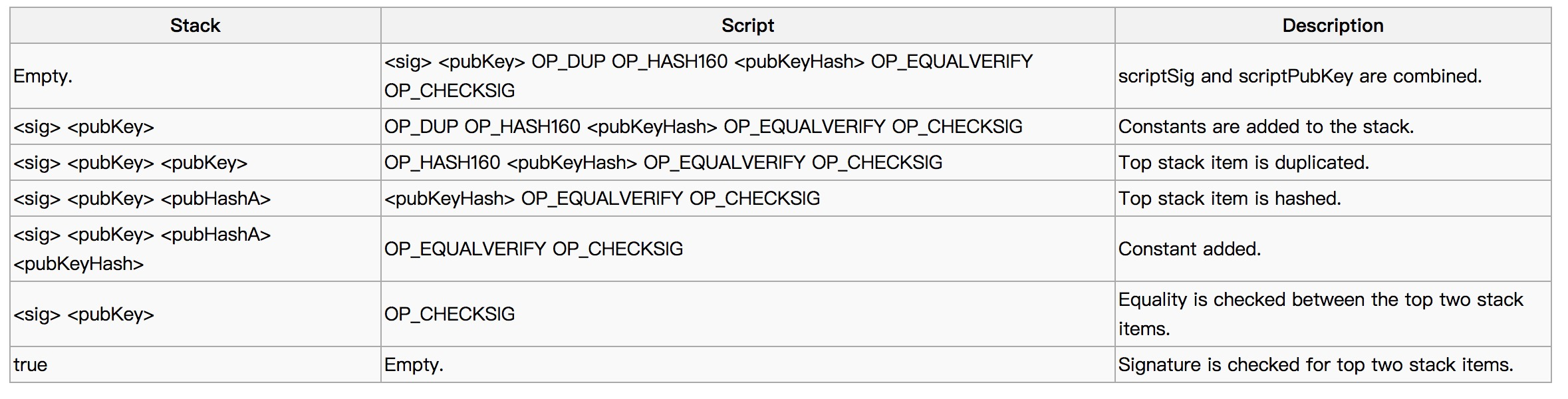
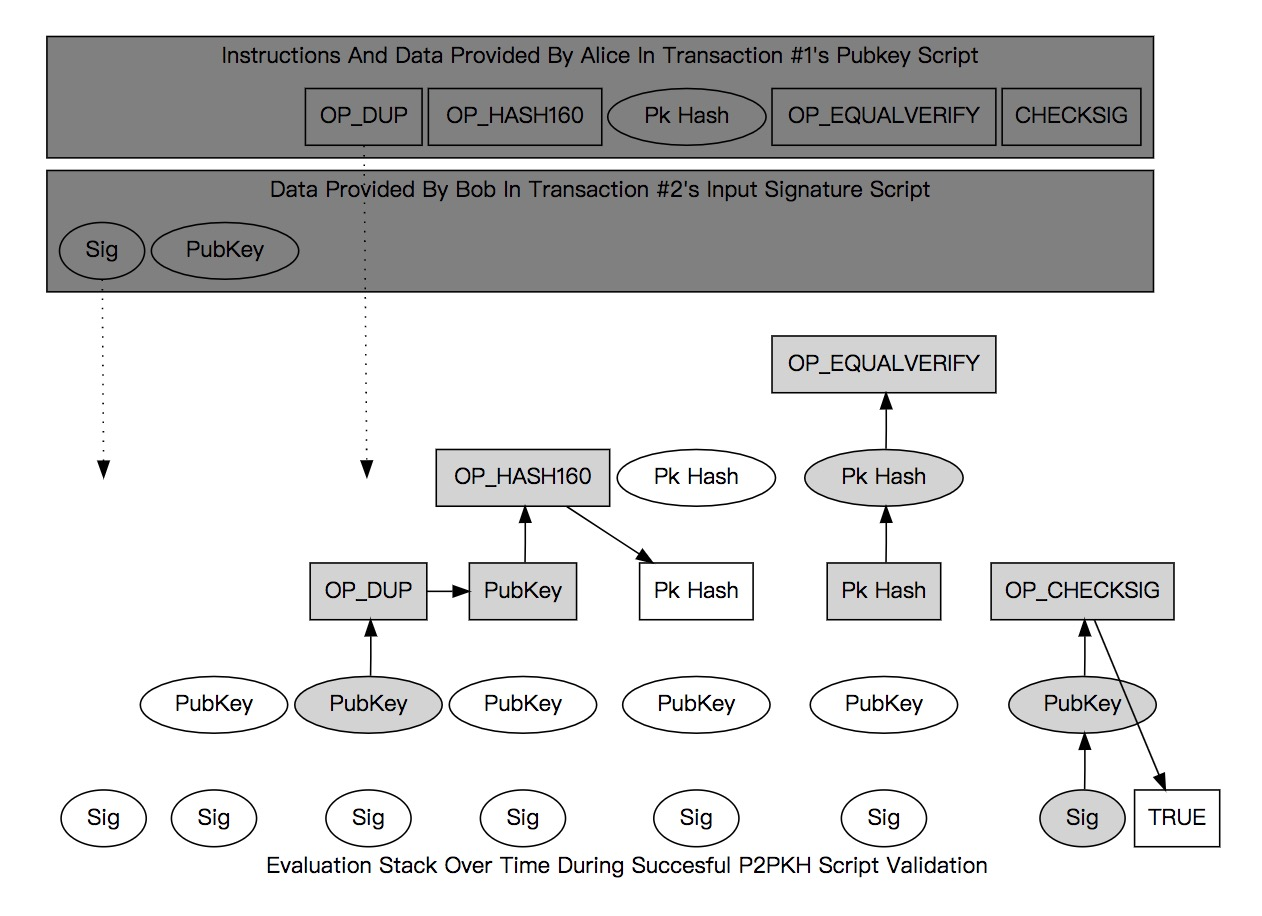
generation 奖励矿工
奖励矿工可以看作一种简化的P2PKH,区别在于交易的输入来自coinbase而不是某个UTXO。
Pay-to-Script-Hash(P2SH)
P2PKH设计比较简单,接受者Bob直接提供收款地址。实际的价值流通过程中,会涉及很多条件。为了满足更复杂的功能,BIP12中提出加入OP_EVAL指令(在程序语言设计中,eval意味着语言具备了元编程能力),并在之后由BIP16提出了更完善的交易标准P2SH。
收款方Bob需要先设计一个RedeemScript——提款脚本,再生成该脚本的Hash,提供给Alice。
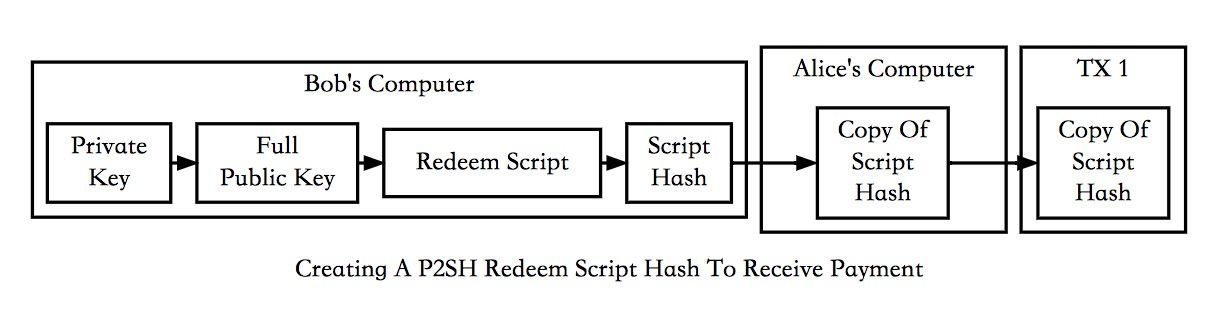
Bob如果想花费该笔UTXO,则需要提供签名和RedeemScript,校验成功后执行RedeemScript的内容,满足条件后则成功解锁。
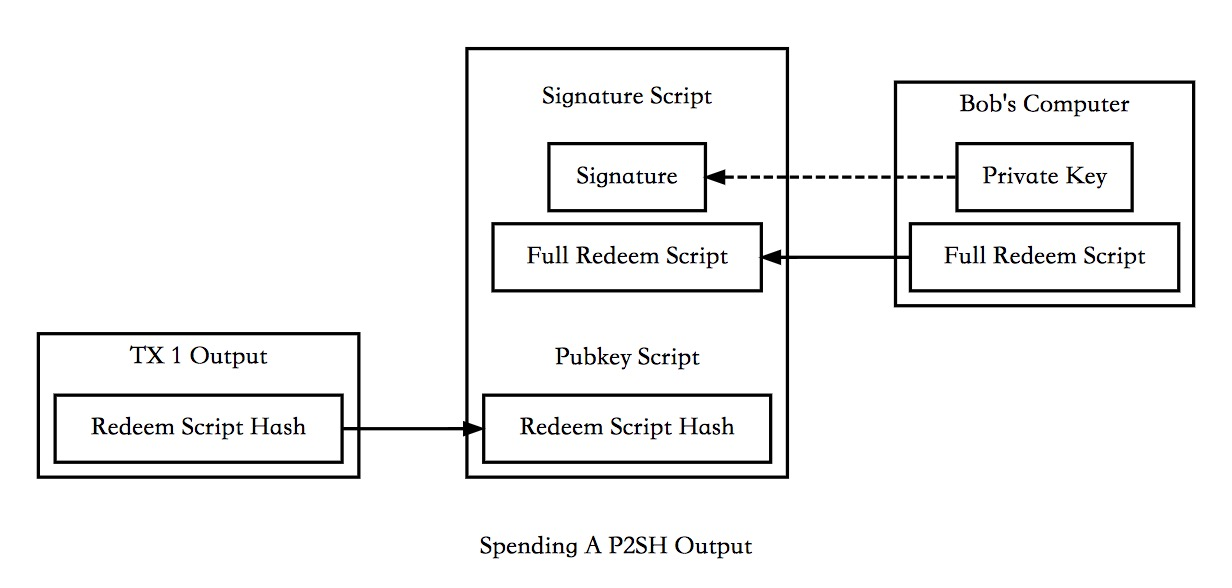
下面的redeemScript结合具体场景设计。后面结合智能合约的应用给出相应的例子。
锁定脚本:
Pubkey script: OP_HASH160 <Hash160(redeemScript)> OP_EQUAL
解锁脚本:
Signature script: <sig> [sig] [sig...] <redeemScript>
在P2SH交易中,由于Bob提供的是一段脚本的Hash,那么Alice实际上不知道这笔交易的细节,交易的具体内容需要Bob来设计。这就是所谓的*"moving the responsibility for supplying the conditions to redeem a transaction from the sender of the funds to the redeemer. They allow the sender to fund an arbitrary transaction, no matter how complicated, using a 20-byte hash"。*这在设计上也不是说没有争议的,但是在比特币的技术框架下,是一种以最小的改动支持更多的特性的路径。
比特币的智能合约
虽然一提起智能合约,人们更多会想起来以太坊。但正如前面提到的,技术发展是一脉相承。早在1997年Nick Szabó在开创性的论文 Formalizing and Securing Relationships on Public Networks中提出了智能合约的概念。比特币的脚本系统支持有限的智能合约的开发,主要通过P2SH交易实现的。
MultiSig 多重签名
BIP11提出了M-of-N多重签名交易。一个交易的解锁条件是预定指定的N个pubkey中的M个签名认证(M<=N)。P2PKH可以看作1-of-1的签名。多重签名在增加安全、托管交易等场景下十分有用。所以比特币中专门实现了OP_CHECKMULTISIG的指令。可以通过下面的脚本设计来实现。
锁定脚本:
Pubkey script: <m> <A pubkey> [B pubkey] [C pubkey...] <n> OP_CHECKMULTISIG
解锁脚本:
Signature script: OP_0 <A sig> [B sig] [C sig...]
如果使用P2SH交易,也可以设计成如下脚本。
锁定脚本:
Pubkey script: OP_HASH160 <Hash160(redeemScript)> OP_EQUAL
解锁脚本:
Signature script: OP_0 <A sig> <C sig> <redeemScript>
其中:
Redeem script: <OP_2> <A pubkey> <B pubkey> <C pubkey> <OP_3> OP_CHECKMULTISIG
Gavin Andresen写了一个2-of-3的多重签名交易的使用例子,十分详细,我就不搬运了。
Part II:以太坊虚拟机
区块链范式
Gavin Wood在黄皮书中将区块链系统抽象为基于交易的状态机:

公式(1)中S是系统内部的状态集合,f是交易状态转移函数,T是交易信息,初始状态即Gensis状态;
公式(2)中F是区块层面状态转移函数,B是区块信息;
公式(3)定义B是一系列交易的区块,每个区块都包括多个transaction;
公式(4)G是区块定稿函数,在以太坊中包括uncle块校验、奖励矿工、POW校验等。
这个数学模型不仅是以太坊的基础,也是目前大多数基于共识的去中心化交易系统的基础。
以太坊相对比特币的提升,本质体现在这个范式中的f和S。它的核心理念——具备图灵完备和不受限制的内部交易存储空间的区块链。分别对应:
- 功能强大的函数f,能够执行任何计算,比特币不支持loop;
- 状态S记录任意类型的数据(包括代码),而比特币的UTXO模型只能计算出地址的可花费额度。
数据结构
在数据存储方面,比特币通过UTXO模型计算地址余额,不鼓励用户存入其他数据;通过P2SH脚本机制,理论上可以设计各种智能合约,但受限于脚本语言的表达能力,难以支持复杂的合约开发。这种设计对于加密货币来说是合理的。
以太坊为了支持记录任意的信息、执行任意函数,需要重新设计数据结构。
Merkle Patricia Trie
以太坊中重度使用Merkle Patricia Trie组织、存储数据,下面我们会看到,这个新的数据结构是通过对哈希树和前缀树的组合创新来达到目的。
约定:下面使用MPT来代替Merkle Patricia Trie。
Merkle Tree
又称hash tree:树的每个叶子结点是某个数据块的哈希值,而每个非叶子结点是孩子结点的哈希值。如图所示,这棵树不存储Data blocks本身。在P2P网络环境中,恶意网络节点如果修改了这颗树上的数据,将无法通过校验(Merkle Proof),从而保证了数据的完整、有效性。这依赖于单向哈希加密的性质。这种性质让它广泛应用在分布式系统的数据校验中,比如IPFS、Git等。
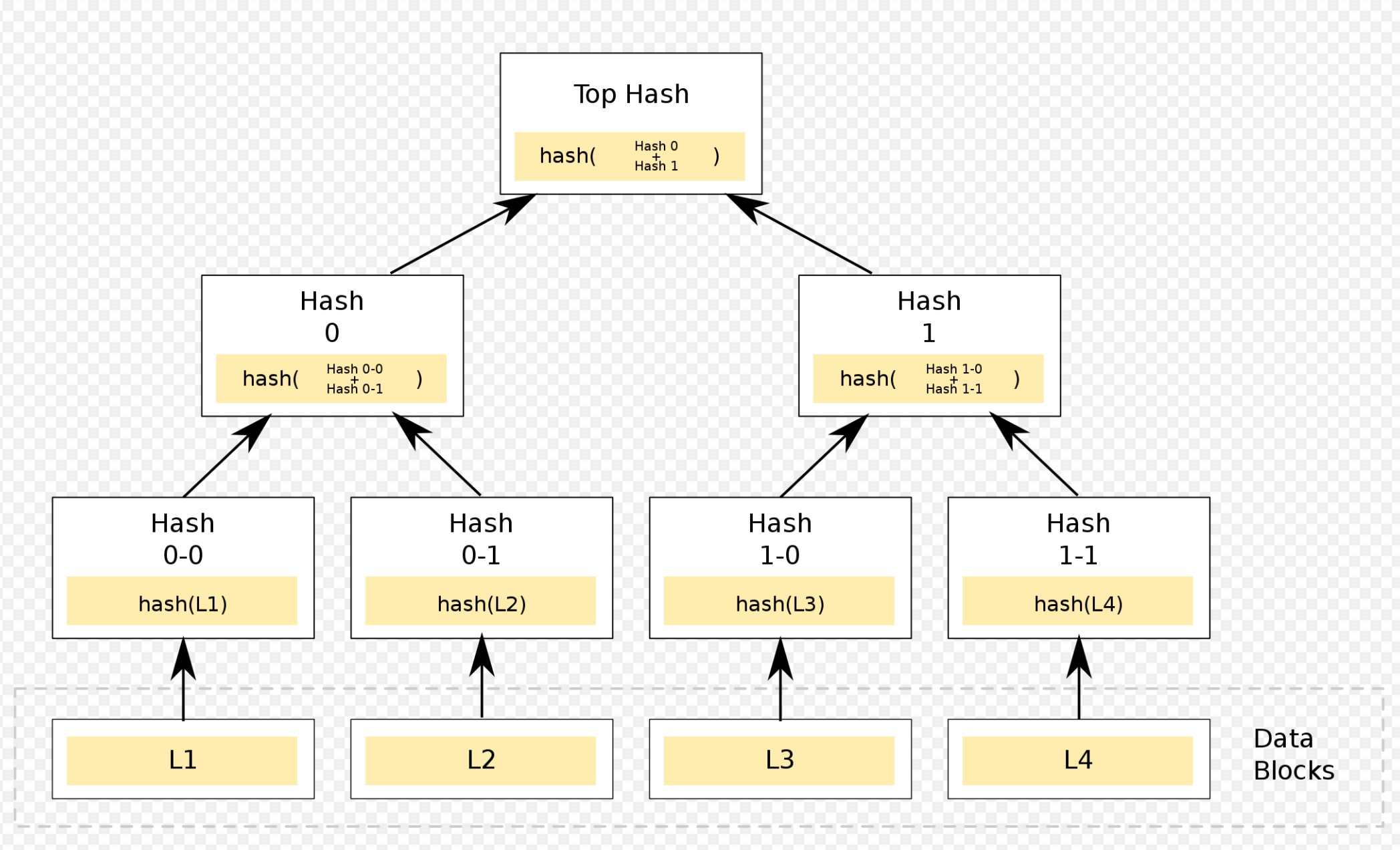
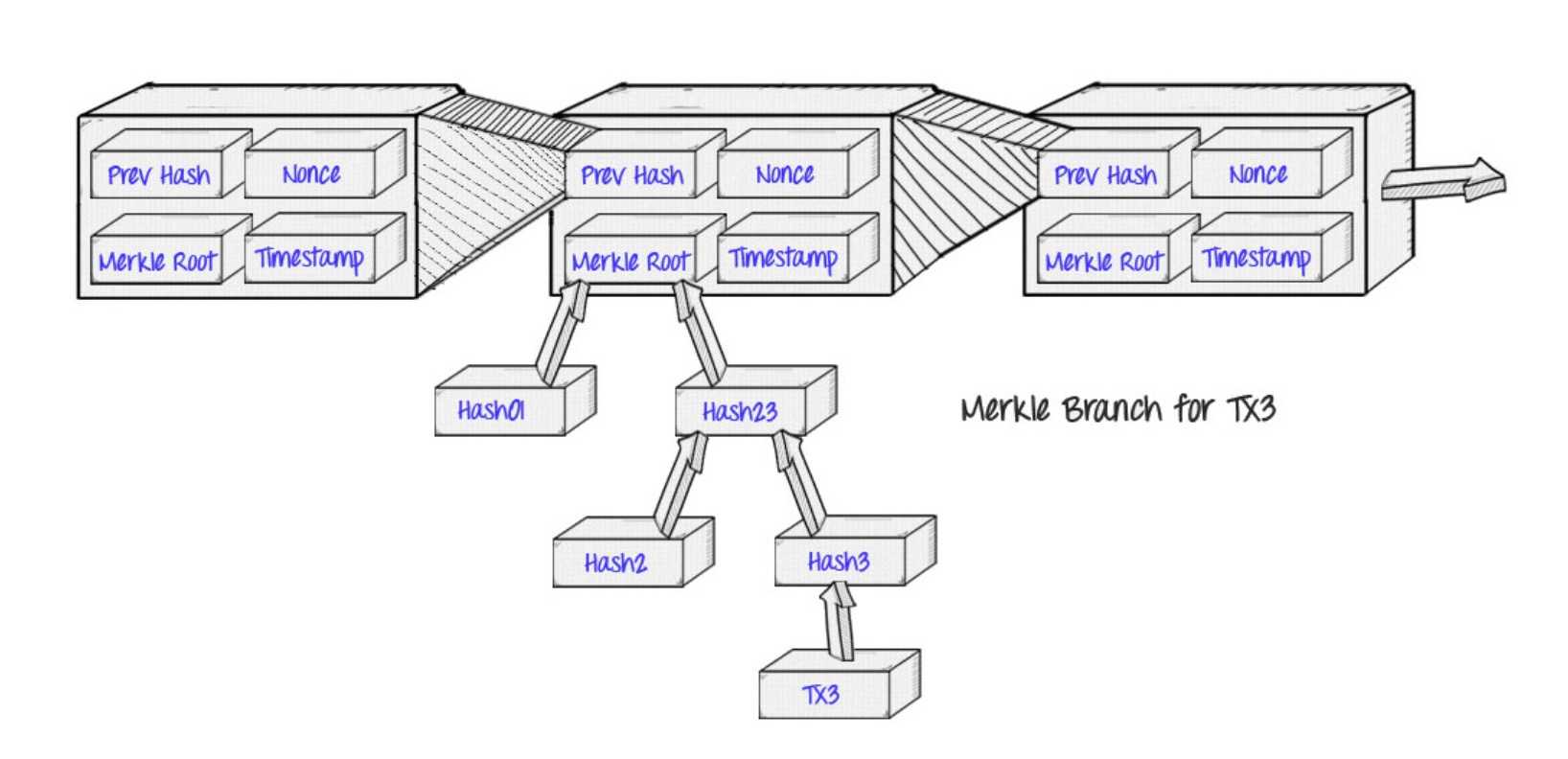
Patricia Trie
又叫Radix Trie,是前缀树的空间优化变种:如果树上某个节点是其父节点的唯一子结点,则这两个结点可以合并起来。它在这里的应用是对长整型数据的映射,由某个20bytes的以太坊地址映射到其账户,形如<Address,Account>,Address会加密编码成16进制的数字——在Patricia Trie上,表现为非叶结点连成的路径。
比如,在Patricia Trie上存储<"dog","Snoopy">,"dog"会被编码为"64 6f 67",先找到根节点,则查询路线为root->6->4->6->15->6->7->value,value也就是一个指向"Snoopy"的hash。这种方式相对hash表的好处在于不会出现冲突;但如果不做优化,查询步骤太长。
改良点
为了提高效率,以太坊对树上结点数据类型进行了专门的设计。包括以下四类结点
- null结点 代表空字符串
- branch结点 17个元素的非叶节点,形如<i0,i1...i15,v>
- leaf结点 2个元素的叶结点,形如<encodedPath,value>,encodedPath是地址加密编码后的长整型数字串的一部分
- extension结点 2个元素的非叶结点,形如<encodedPath,k>,extension的作用是把没有分叉的路径上结点合并起来,节省空间资源
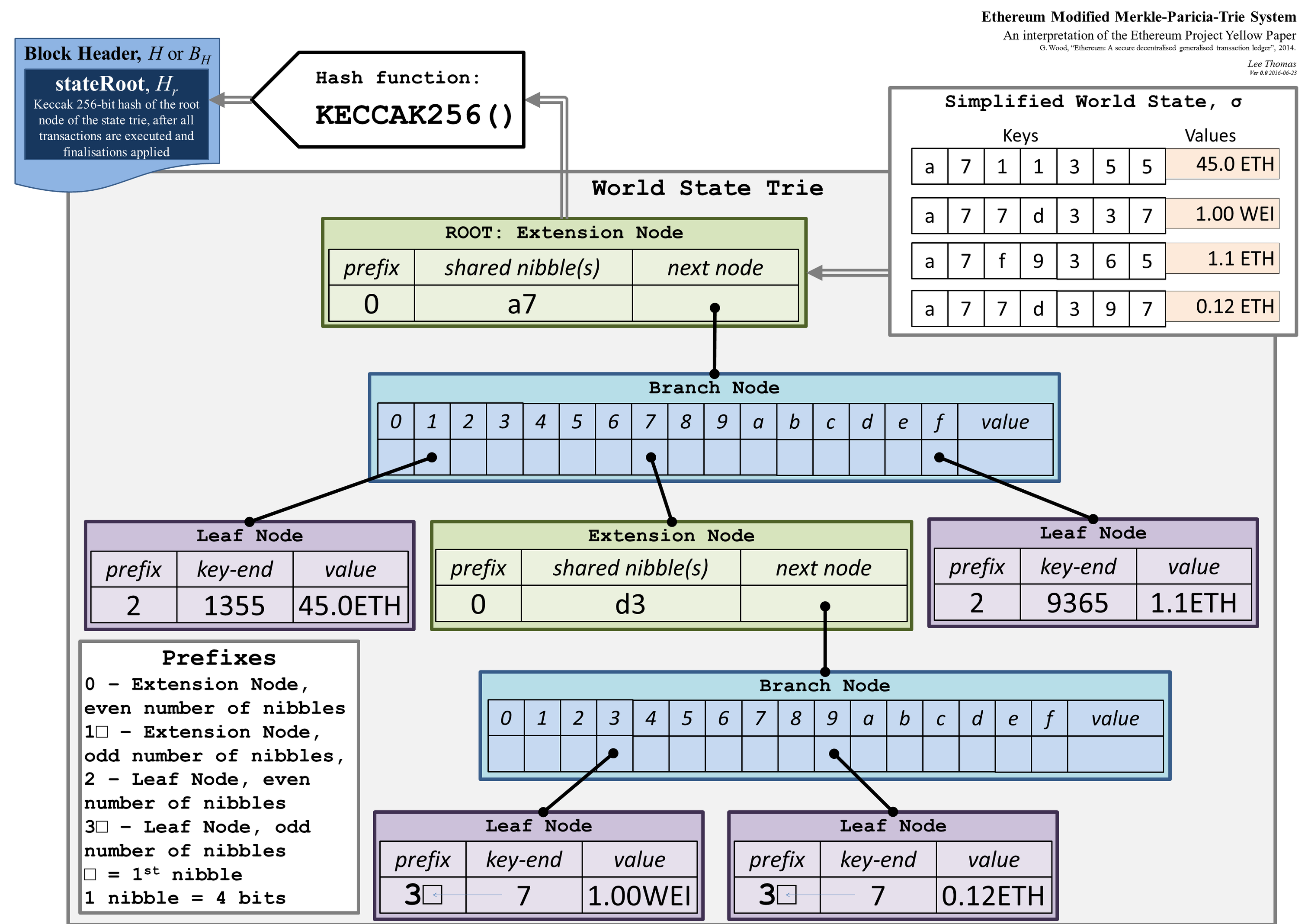
使用MPT需要有后端数据库(以太坊中使用levelDB)维护每个结点间的连接关系,这个数据库叫做状态数据库。使用MPT的好处包括:(1)这个结构的根节点是加密的且依赖于所有的内部数据,它的哈希可以用于安全性校验,这是merkle树的性质,但和merkle树不存储数据块本身不同的是,MPT树结点存储了地址数据,这是Patricia树的性质(2)允许任何一个之前状态(根部哈希已知的条件下)通过简单地改变根部哈希值而被召回。
状态
上面在解释MPT时已经介绍了状态树的概念。以太坊中的世界状态(World State)的概念,通过MPT映射存储去中心化交易系统记录的任意状态。这对应了区块链范式中的S,是以太坊设计的一个核心概念。
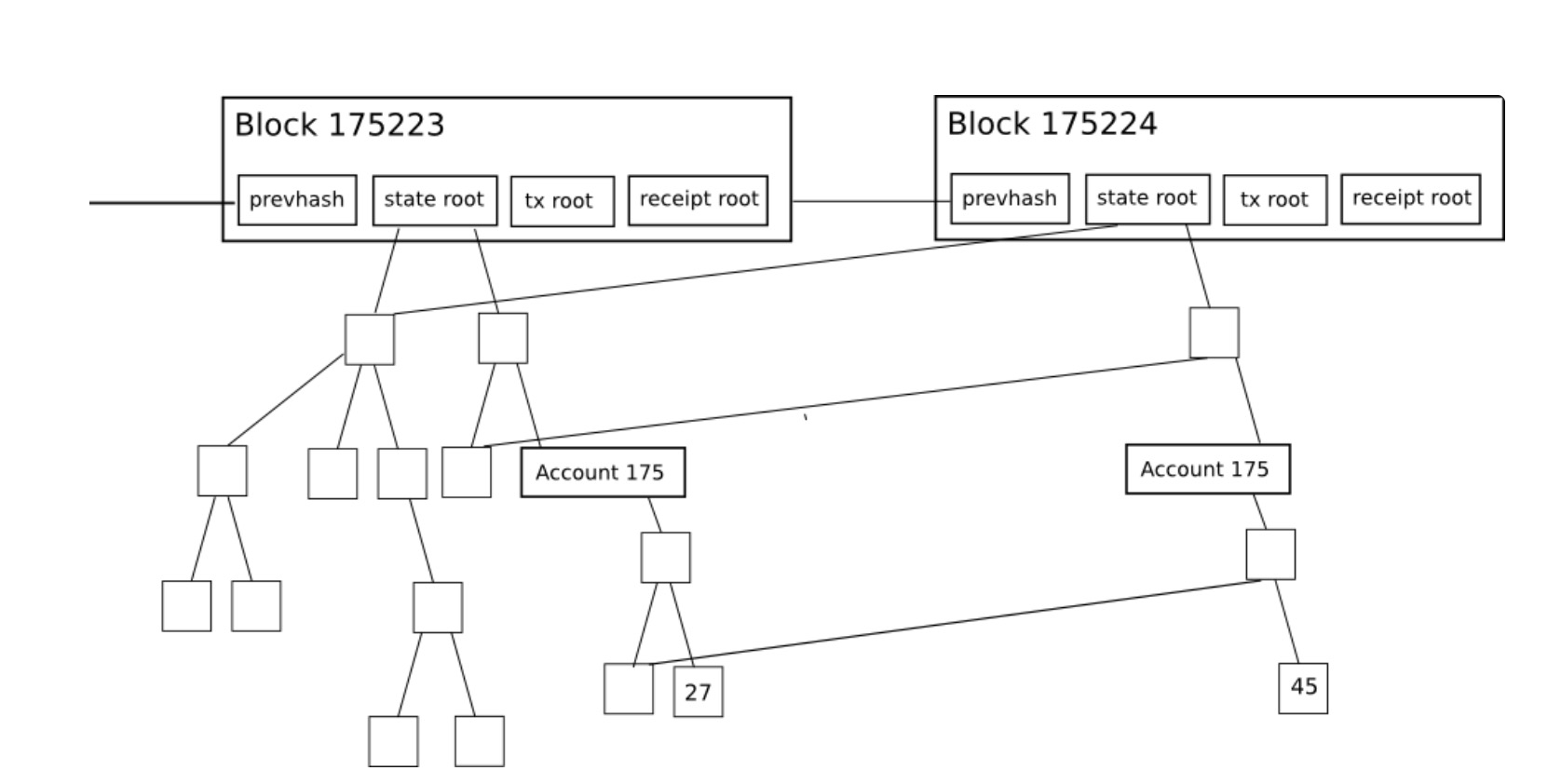
对以太坊的账户模型需要专门做个介绍。
Account
比特币使用UTXO模型计算余额,无法满足记录任意状态的需求。以太坊设计了Account模型,它会存储包括:
[nonce, balance, storageRoot, codeHash]
其中nonce是交易计数器,balance是余额信息,storageRoot对应另外一个MPT,通过它能够在数据库中检索到合约的变量信息,codeHash是代码hash值,创建后不可更改。
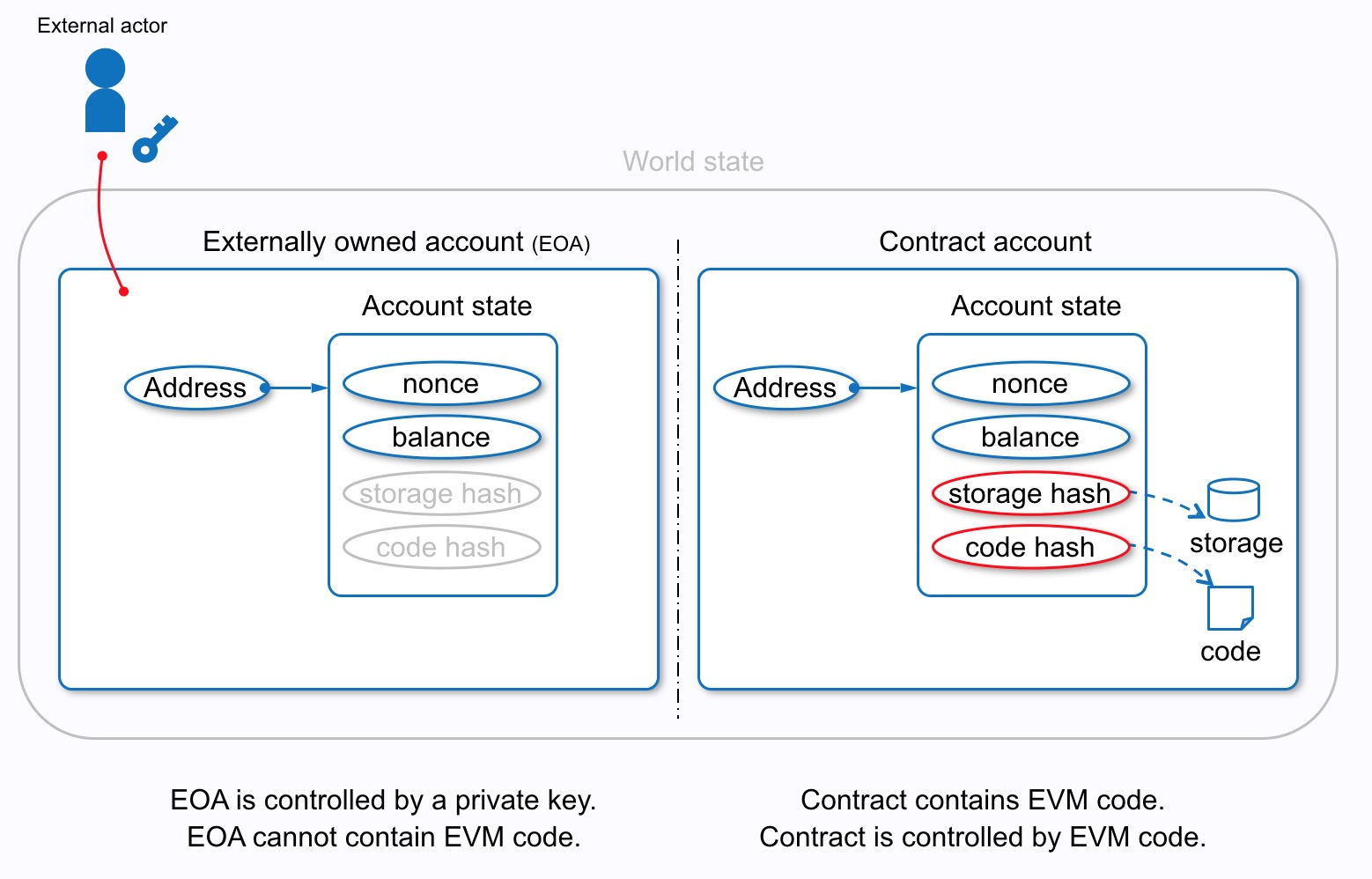
- 外部账户(externally owned accounts)
外部账户由私钥控制,对应Account模型里,storageRoot、codeHash并不存在,也就是不会存储、执行代码。如果只有外部账户,那么以太坊只能支持转账功能。 - 合约账户(contract accounts)
合约账户可以通过外部账户发起交易创建,也可以是由另一个合约账户创建。合约账户在收到消息调用时,会加载代码,通过EVM执行相应的逻辑,修改内部存储的状态。
交易
在UTXO模型下,交易本质上是(通过签名的数据)对input的解锁和对output的锁定。在Account模型下,交易分为两种:
- 创建合约,通过代码创建新的合约
- 消息调用,可以转账也可以触发合约的某个函数
两种类型的交易都包括以下字段:
[nonce,gasPrice,gasLimit,to,value,[v,r,s]]
- nonce: 账户发出交易数量
- gasPrice,gasLimit: 用于限制交易执行时间,防止程序死循环
- to:交易的接受者
- value:转账额度,如果是创建合约,就是捐赠给合约的额度
- v,r,s:交易签名相关数据,可以用来确定交易发送者
合约创建还需要:
- init:一段不限大小的字节数组表示的EVM代码,仅在合约创建时运行一次;init执行后返回body代码片段,之后的合约调用都会运行body代码内容。
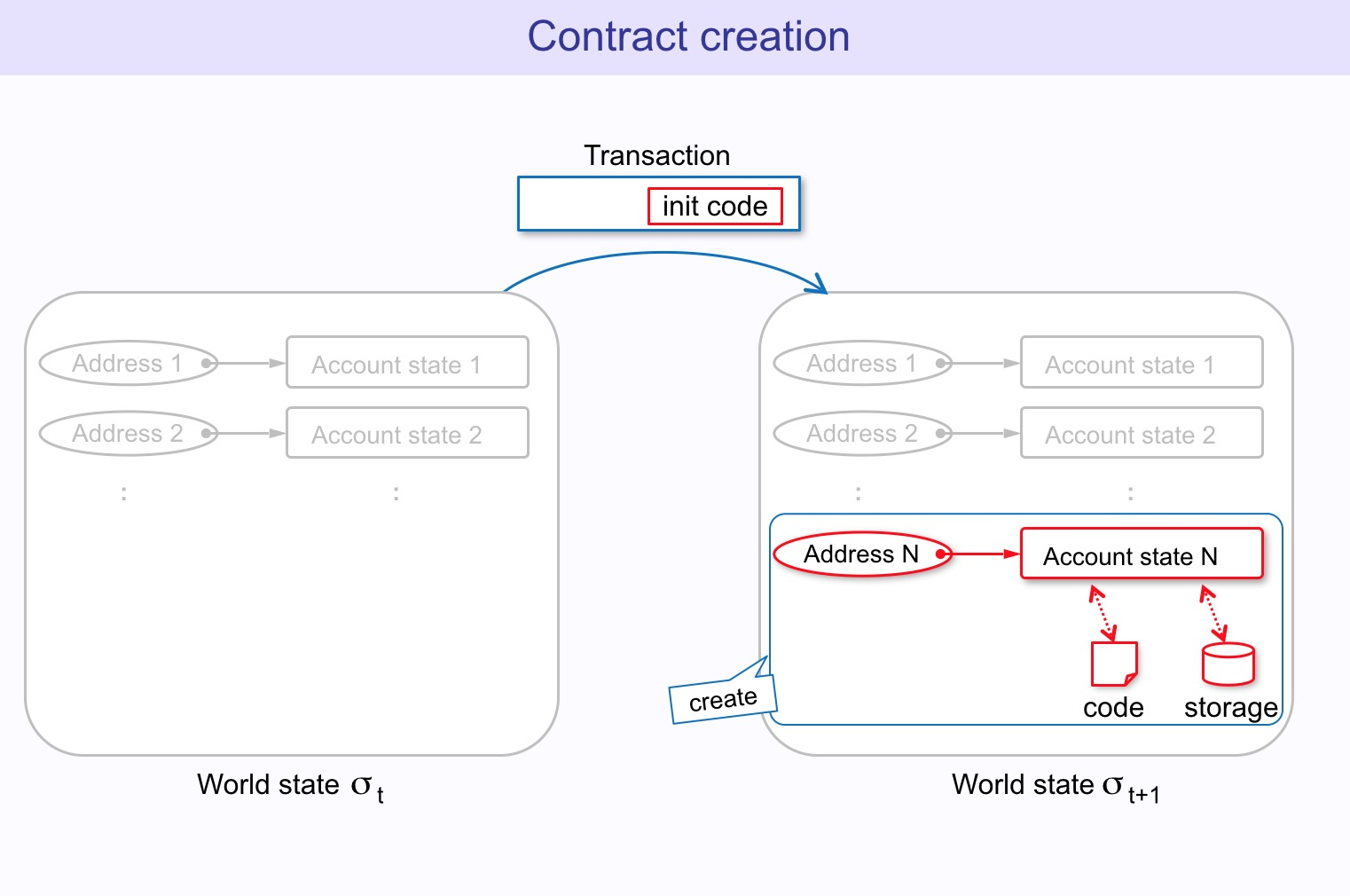
消息调用还需要:
- data:一段不限大小的字节数组,表示消息调用时的输入
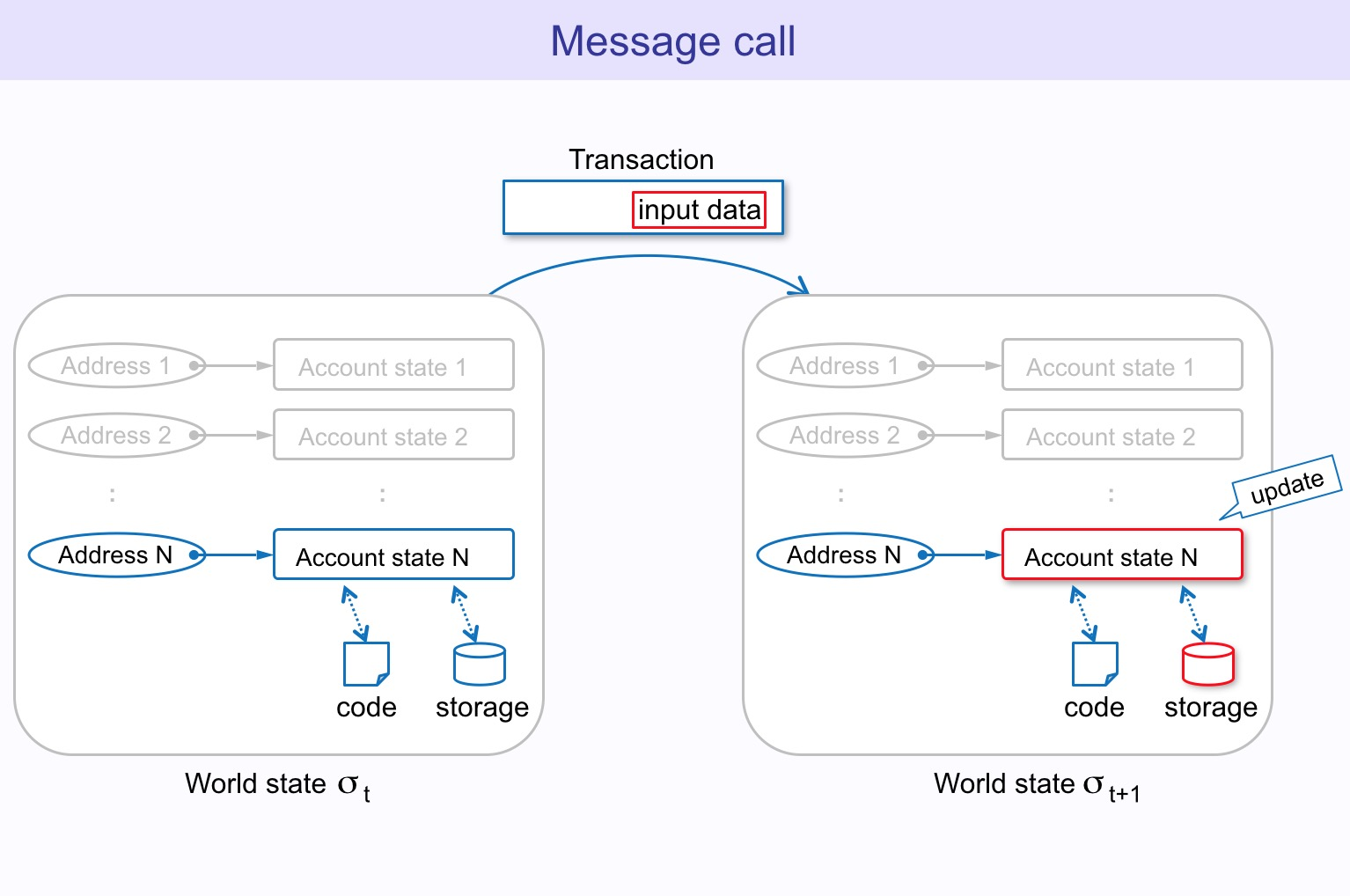
交易既可以由外部账户发起,也可以由合约发起。比如第5228886区块包含170个交易和7个内部合约交易。
区块
以太坊的区块了加入更多的数据项,相对比特币要复杂很多,但其实本质上区别不大。比如加入了叔链哈希,优化激励措施,这是为了支持挖矿协议;区块本身还会有大量的有效性验证、序列化。这些内容不在本文主题范围,不深入讨论。
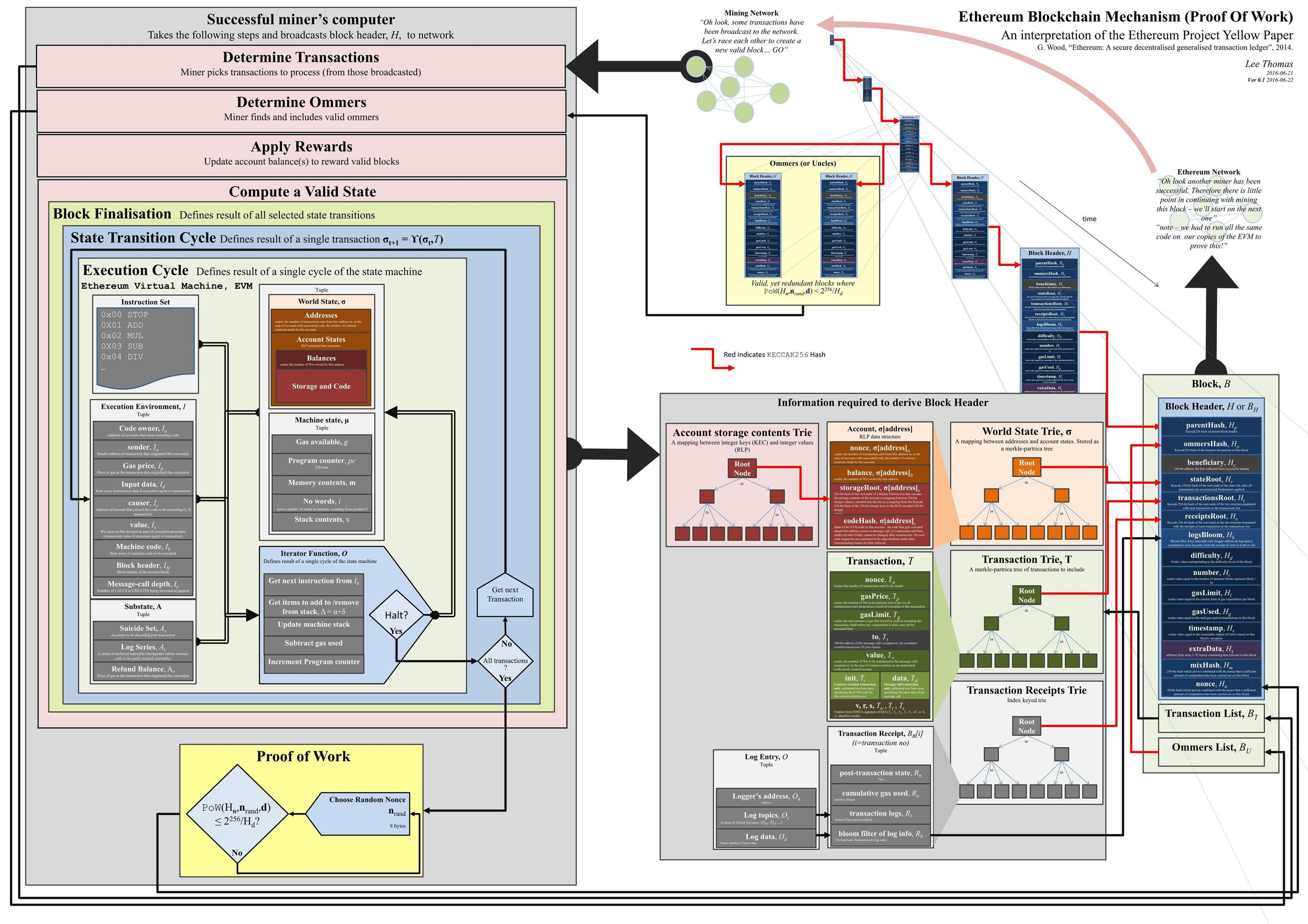
EVM设计与执行
以太坊虚拟机(Ethereum Virtual Machine)是执行以太坊的状态转移函数的运行环境。 有个简单的问题,以太坊是否可以不专门开发一款底层VM,而是复用Java、Lisp、Lua等呢?理论上是完全可以的,Corda项目就完全基于JVM平台开发。但是更多的区块链项目会选择专门开发底层设施,包括比特币的脚本引擎。以太坊官方给出的解释:
- 以太坊的VM规格更简单,而别的通用VM有很多不必要的复杂性
- 容许定制开发,比如32bytes的字
- 避免其他VM带来的外部依赖问题,可能导致安装困难
- 采用其他VM,需要做完全的安全性审查,权衡下不一定能省多少事
内存模型
EVM也是基于栈式计算机模型,但除了stack外还涉及memory和storage:
- stack 栈上元素大小为32bytes,这和一般的4bytes,8bytes不同,主要是针对以太坊运算对象多为20bytes的地址和32bytes的密码学变量;栈的大小不超过1024;栈的调用深度不超过1024,主要防止出现内存溢出。
- memory 虽然运算都在栈上进行,但临时变量可以存在memory里,memory大小不做限制
- storage 状态变量都放在storage里,不像stack和memory上的量随着EVM实例销毁消失,storage里面的数据修改后都会持久化
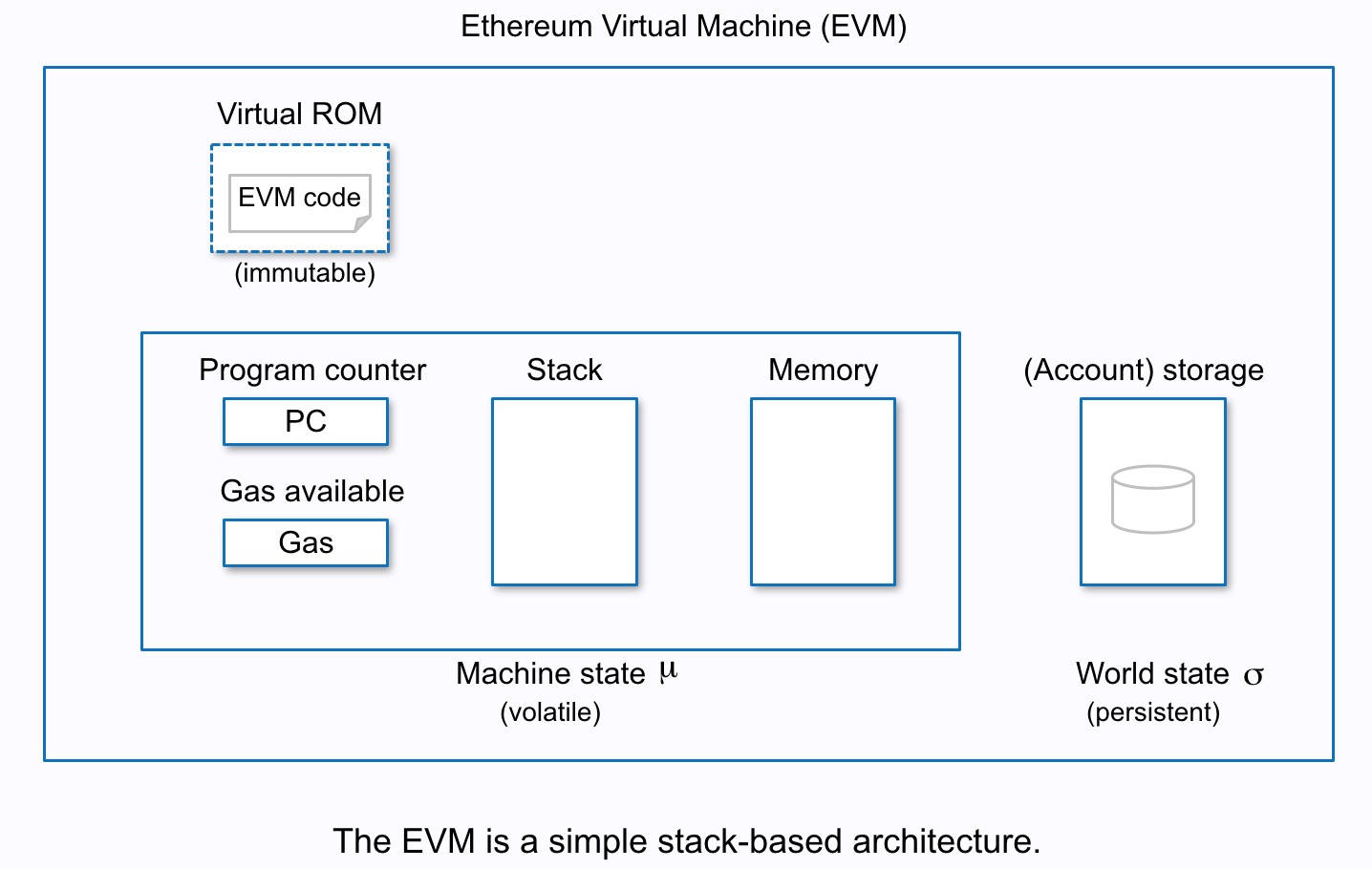
合约部署后编译成字节码存储在virtual rom中,代码是不可修改的,这对很多DAPP来说是严重的制约。一种思路是,将代码分布在不同的合约中,合约间调用通过存储在storage中的地址来进行,这样实现了实际上的合约升级操作。
执行模型
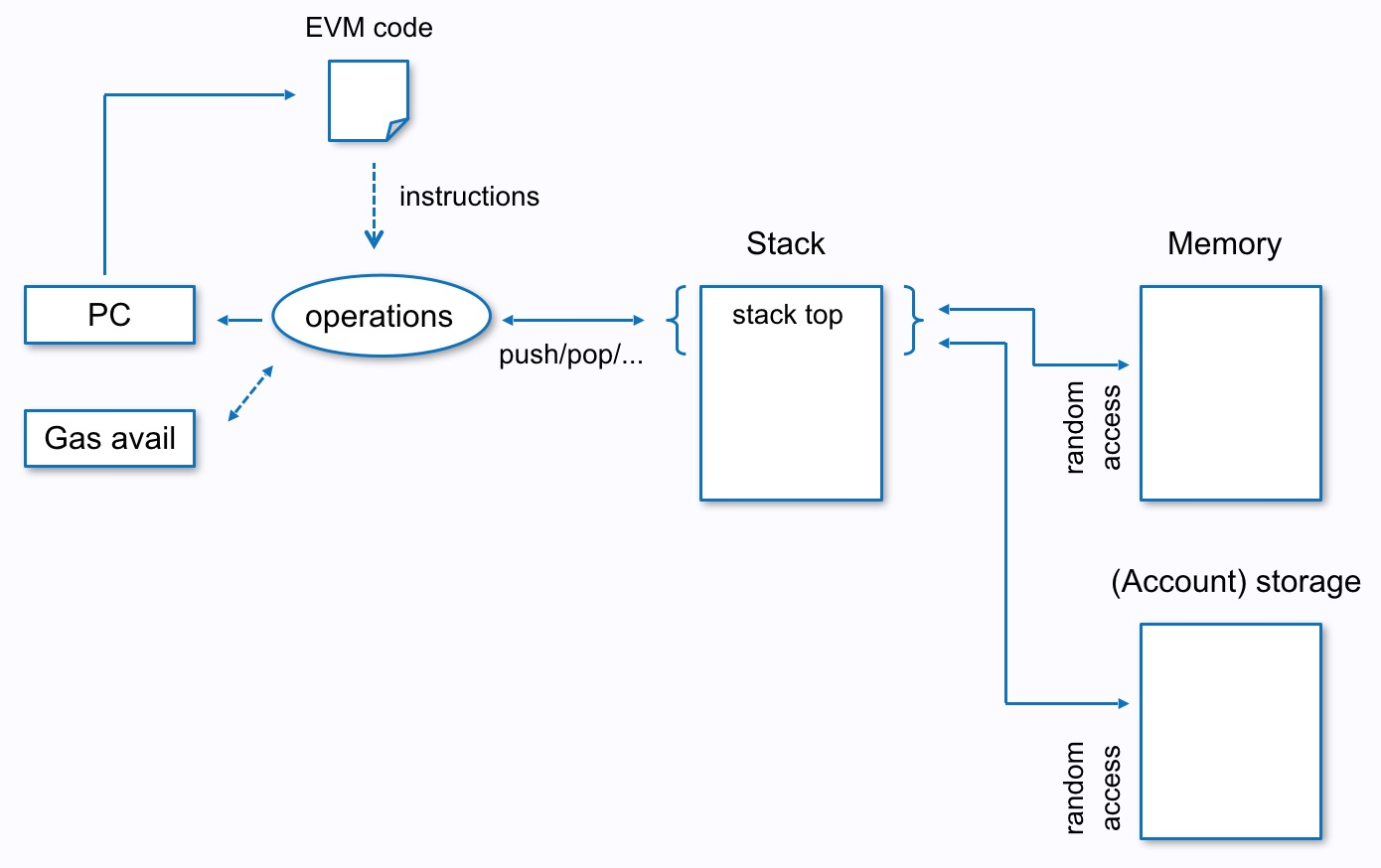
EVM准确来说是一个准图灵机,文法上它能够执行任意操作,但为了防止网络滥用、以及避免由于图灵完整性带来的安全问题,以太坊中所有操作都进行了经济学上的限制,也就是gas机制,有三种情况:
- 一般操作消耗费用,比如SLOAD,SSTORE等
- 子消息调用或者合约创建而消耗燃料,这是执行CREATE、CALL、CALLCODE费用中的一部分
- 内存使用消耗费用,与所需要的32bytes的字数量成正比
下图展示了EVM执行的内部流程,从EVM code中取指令,所有的操作在Stack上进行,Memory作为临时的变量存储,storage是账户状态。执行受到gas avail限制。
现在结合EVM我们再来看看之前介绍的交易的执行细节。正如区块链范式定义的,T是以太坊状态转移函数,也是以太坊最复杂的部分。所有的交易在执行前,都需要先经过内部的有效性验证:
- 交易是RLP格式数据,没有多余的后缀字节;
- 交易的签名是有效的;
- 交易的随机数是有效的;
- 燃料上限不小于实际交易过程中用的燃料;
- 发送者账户的余额至少大于费用v0,需要提前支付;
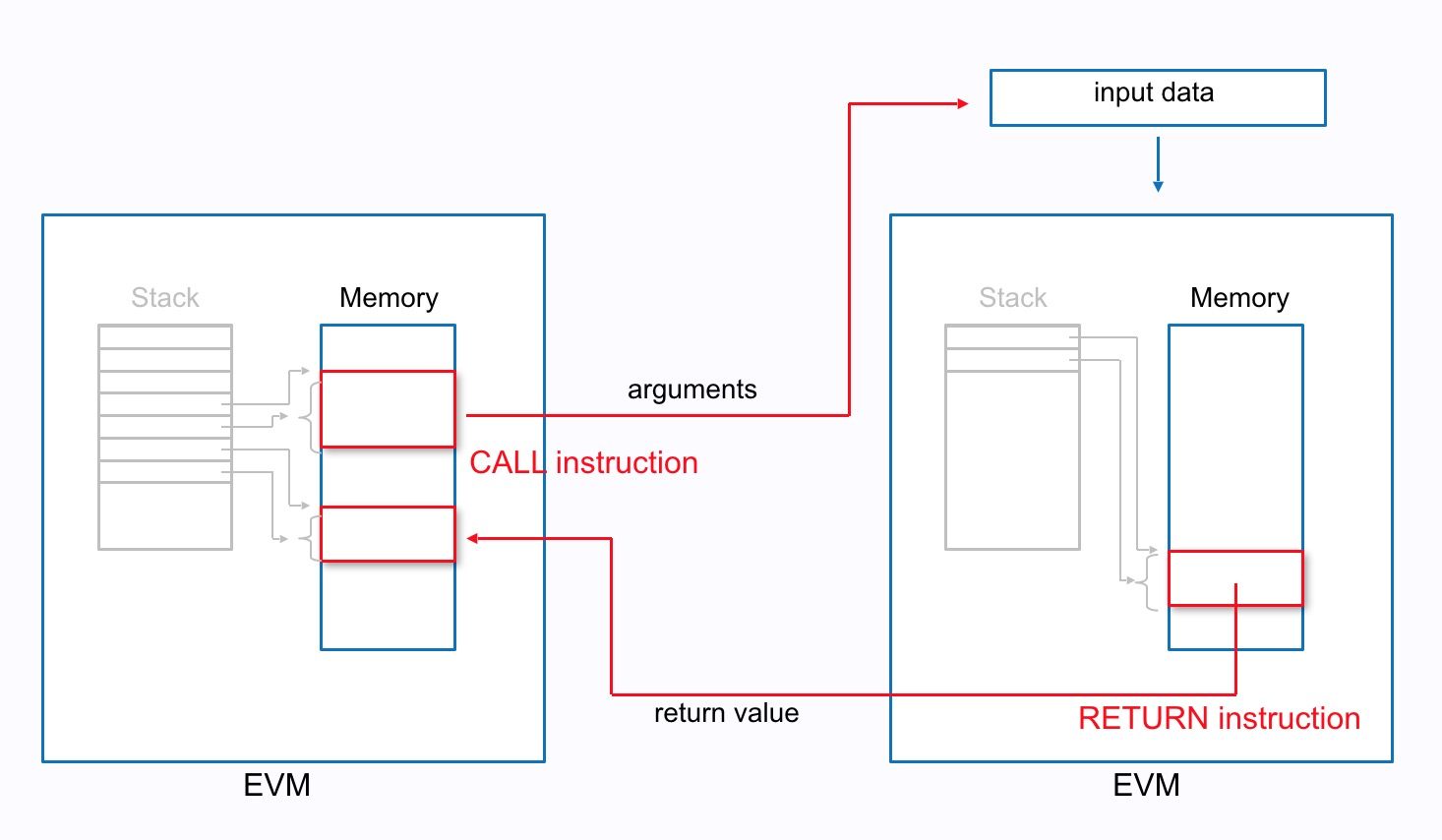
下图是消息调用的过程,每个交易可能会形成很深的调用栈,交易内部由不同的合约之间的调用。调用通过CALL指令,参数和返回值通过memory传递。
错误处理
EVM在合约执行时会发生若干种错误:
- 燃料不足
- 无效指令
- 缺少栈数据
- 指令JUMP JUMPI的目标地址无效
- 新栈大小大于1024
- 栈调用深度超过1024
EVM的错误处理有个简单的原则,叫做revert-state-and-consume-all-gas,即状态恢复到交易执行前的checkpoint,但消耗的gas不会再退还。虚拟机把错误全看作是代码出错,不作特定的错误处理。
EVM分析工具
关于EVM分析的工具可以参考Ethereum Virtual Machine (EVM) Awesome List
类EVM的图灵完备虚拟机(WIP)
完整的EVM规格是很复杂的,但具备一定的汇编基础和简化模型的能力,实现一个类EVM的虚拟机是可以尝试的挑战。等有空我再把自己的实现放上来吧。有兴趣的同学可以自己动手试试。
参考
1.A Next-Generation Smart Contract and Decentralized Application Platform
2.ETHEREUM: A SECURE DECENTRALISED GENERALISED TRANSACTION LEDGER
3.Design Rationale
4.Stack Exchange: Ethereum block architecture
5.Go Ethereum
6.evm-illustrated
7.Diving Into The Ethereum VM
