

本文是Android面试题整理中的一篇,结合右下角目录食用更佳,包括:
- 集合
- 内存
- 垃圾回收
集合
0. List和Set的区别
- 它们都是接口,都实现了Collection接口
- List元素可以重复,元素顺序与插入顺序相同,其子类有LinkedList和ArrayList
- Set元素不能重复,元素顺序与插入顺序不同,子类有HashSet(通过HashMap实现),LinkedHashSet,TreeSet(红黑树实现,排序的)
1. List、Map、Set三个接口存取元素时,各有什么特点?
- List继承了Collection,储存值,可以有重复值
- Set继承了Collection,储存值,不能有重复值
- Map储存健值对,可以一对一或一对多
2. List、Set、Map是否继承自Collection接口
List、Set 是,Map 不是。Map是键值对映射容器,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形
3. HashMap实现原理
- 在1.7中,HashMap采用数组+单链表的结构;1.8中,采用数组+单链表或红黑树的结构(当链表size > 8时,转换成红黑树)
- HaspMap中有两个关键的构造函数,一个是初始容量,另一个是负载因子。
- 初始容量即数组的初始大小,当map中元素个数 > 初始容量*负载因子时,HashMap调用resize()方法扩容
- 在存入数据时,对key的hashCode再次进行hash(),目的是让hash值分布均匀
- 对hash() 返回的值与容量进行与运算,确定在数组中的位置
- key可以为null,null的hash值是0
4. HashMap是怎么解决hash冲突的
- 对hashCode在调用hash()方法进行计算
- 当超过阈值时进行扩容
- 当发生冲突时使用链表或者红黑树解决冲突
5. 为什么不直接采用经过hashCode()处理的哈希码作为存储数组table的下标位置
- hashCode可能很大,数组初始容量可能很小,不匹配,所以需要: hash码 & (数组长度-1)作为数组下标
- hashCode可能分布的不均匀
6. 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突
7. 为什么说HashMap不保证有序,储存位置会随时间变化
- 通过hash值确定位置,与用户插入顺序不同
- 在达到阈值后,HashMap会调用resize方法扩容,扩容后位置发生变化
8. HashMap的时间复杂度
HashMap通过数组和链表实现,数组查找的时间复杂度是O(1),链表的时间复杂度是O(n),所以要让HashMap尽可能的块,就需要链表的长度尽可能的小,当链表长度是1是,HashMap的时间复杂度就变成了O(1);根据HashMap的实现原理,要想让链表长度尽可能的短,需要hash算法尽量减少冲突。
9. HashMap 中的 key若 Object类型, 则需实现哪些方法
hashCode和equals
10. 为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
- 它们是final的,不可变,保证了安全性
- 均已经实现了hashCode和equals方法,计算准确
11. HashMap线程安全吗
- HashMap线程不安全
- HashMap没有同步锁,举例:比如A、B两个线程同时触发扩容,HashMap容量增加2倍,并将原数据重新分配到新的位置,这个时候可能出现原链表转移到新链表时生成了环形链表,出现死循环。
12. HashMap线程安全的解决方案
- 使用Collections.synchronizedMap()方法,该方法的实现方式是使用synchronized关键字
- 使用ConcurrentHashMap,性能比Collections.synchronizedMap()更好
13. HashMap 如何删除元素
- 计算key的Hash值,找到数组中的位置,得到链表的头指针
- 遍历链表,通过equals比较key,确定是不是要找的元素
- 找到后调整链表,将该元素从链表中删除
//源码 java8
@Override public V remove(Object key) {
if (key == null) {
return removeNullKey();
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
if (prev == null) {
tab[index] = e.next;
} else {
prev.next = e.next;
}
modCount++;
size--;
postRemove(e);
return e.value;
}
}
return null;
}
14. HashMap的扩容过程
- 在初次加载时,会调用resize()进行初始化
- 当put()时,会查看当前元素个数是否大于阈值(阈值=数组长度*负载因子),当大于时,调用resize方法扩容
- 新建一个数组,扩容后的容量是原来的两倍
- 将原来的数据重新计算位置,拷贝到新的table上
15. java8 中HashMap的优化
最大变化是当链表超过一定的长度后,将链表转换成红黑树存储,在存储很多数据时,效率提升了。链表的查找复杂度是O(n),红黑树是O(log(n))
16. HashMap和HashTable的区别
- HashTable是线程安全的,而HashMap不是
- HashMap中允许存在null键和null值,而HashTable中不允许
- HashTable已经弃用,我们可以用ConcurrentHashMap等替代
17. ConcurrentHashMap实现原理
- ConcurrentHashMap是线程安全的HashMap,效率比直接加cynchronized要好
- 1.7中通过分段锁实现,读不枷锁(通过volatile保证可见性),写时给对应的分段加锁。(1.8实现原理变了)
18. ConcurrentHashMap的并发度是什么
- ConcurrentHashMap通过分段锁来实现,并发度即为段数
- 段数是ConcurrentHashMap类构造函数的一个可选参数,默认值为16
19. LinkedHashMap原理
- LinkedHashMap通过继承HashMap实现,既保留了HashMap快速查找能力,又保存了存入顺序
- LinkedHashMap重写了HashMap的Entry,通过LinkedEntry保存了存入顺序,可以理解为通过双向链表和HashMap共同实现
20. HashMap和Arraylist都是线程不安全的,怎么让他们线程安全
- 借助Collections工具类synchronizedMap和synchronizedList将其转为线程安全的
- 使用安全的类替代,如HashTable(不建议使用)或者ConcurrentHashMap替代Hashmap,用CopyOnWriteArrayList替代ArrayList
21. HashSet 是如何保证不重复的
- HashSet 是通过HashMap来实现的,内部持有一个HashMap实例
- HashSet存入的值即为HashMap的key,hashMap的value是HashSet中new 的一个Object实例,所有的value都相同
22. TreeSet 两种排序方式
- 自然排序:调用无参构造函数,添加的元素必须实现Comparable接口
- 定制排序:使用有参构造函数,传入一个Comparator实例
23. Array 和 ArrayList对比
- Array可以是基本类型和引用类型,ArrayList只能是引用类型
- Array固定大小,ArrayList长度可以动态改变
- ArrayList有很多方法可以调用,如addAll()
24. List和数组的互相转换/String转换成数组
- String[] a = list.toArray(new String[size]));
- List list = Arrays.asList(array);
- char[] char = string.toCharArray();
25. 数组在内存中是如何分配的
和引用类型一样,在栈中保存一个引用,指向堆地址
26. TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
- TreeMap和TreeSet都是通过红黑树实现的,因此要求元素都是可比较的,元素必须实现Comparable接口,该接口中有compareTo()方法。
- Collections的sort方法有两种重载形式,一种只有一个参数,要求传入的待排序元素必须实现Comparable接口;第二种有两个参数,要求传入待排序容器即Comparator实例
27. 阐述ArrayList、Vector、LinkedList的存储性能和特性。
- ArrayList 和Vector都是使用数组方式存储数据,数组方式节省空间,便与读取;但插入删除涉及数组移动,性能较差。
- Vector中的方法由于添加了synchronized修饰,因此Vector是线程安全的容器。
- LinkedList使用双向链表实现存储,占用空间大,读取慢;插入删除快
- Vector已经被遗弃,不推荐使用。为了实现线程安全的list,可以使用Collections中的synchronizedList方法将其转换成线程安全的容器后再使用
28. 什么是Java优先级队列(Priority Queue)
PriorityQueue是一个基于优先级堆的无界队列,它的元素是按照自然顺序(natural order)排序的。在创建的时候,我们可以给它提供一个负责给元素排序的比较器。PriorityQueue不允许null值,因为他们没有自然顺序,或者说他们没有任何的相关联的比较器。PriorityQueue的逻辑结构为堆(完全二叉树),物理结构为数组。最后,PriorityQueue不是线程安全的,入队和出队的时间复杂度是O(log(n))
29. List、Set、Map的遍历方式
30. 什么是Iterator(迭代器)
迭代器是一个接口,我们可以借助这个接口实现对集合的遍历,删除 扩展(迭代器实现原理):Collection继承了Iterable接口,iterable接口中有iterator方法,返回一个Iterator迭代器 -> Collection的实现类通过在内部实现自定义Iterator,在iterator时返回这个实例。
31. Iterator和ListIterator的区别是什么
- ListIterator 继承自 Iterator
- Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List
- ListIterator比Iterator增加了更多功能,例如可以双向遍历,增加元素等
32. 如何权衡是使用无序的数组还是有序的数组
- 查找多用有序数组,插入删除多用无序数组
- 解释:有序数组最大的好处在于查找的时间复杂度是O(log n),而无序数组是O(n)。有序数组的缺点是插入操作的时间复杂度是O(n),因为值大的元素需要往后移动来给新元素腾位置。相反,无序数组的插入时间复杂度是常量O(1)
33. Arrays.sort 实现原理和 Collections.sort 实现原理
- Collections.sort是通过Arrays.sort实现的。当list不为ArrayList时,先转成数组,再调用Arrays.sort
- java 8 中Array.Sort()是通过timsort(一种优化的归并排序)来实现的
34. Collection和Collections的区别
- Collection 是一个接口,Set、List都继承了该接口
- Collections 是一个工具类,该工具类可以帮我们完成对容器的判空,排序,线程安全化等。
35. 快速失败(fail-fast)和安全失败(fail-safe)
- 快速失败:在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception
- 安全失败:操作是对象的副本,这个时候原对象改变并不会对当前迭代器遍历产生影响。java.util.concurrent类下边容器都是安全失败
扩展:快速失败原理:容器内部有一个modCount,记录变化的次数,当进行遍历时,如果mocount值发生改变,责快速失败
36. 当一个集合被作为参数传递给一个函数时,如何才可以确保函数不能修改它
在作为参数传递之前,我们可以使用Collections.unmodifiableCollection(Collection c)方法创建一个只读集合,这将确保改变集合的任何操作都会抛出UnsupportedOperationException。
内存
0. 内存中的栈(stack)、堆(heap)和方法区(method area)?
- 栈:线程独有,每个线程一个栈区。保存基本数据类型,对象的引用,函数调用的现场(栈可以分为三个部分:基本类型,执行环境上下文,操作指令区(存放操作指令));优点是速度快,缺点是大小和生存周期必须是确定的
- 堆:线程共享,jvm一共一个堆区。保存对象的实例,垃圾回收器回收的是堆区的内存
- 方法区(静态区):线程共享。保存类信息、常量、静态变量、JIT编译器编译后的代码等数据,常量池是方法区的一部分。
1. Jvm内存模型
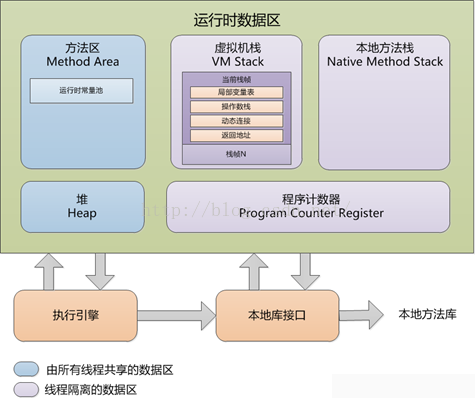
- 堆:线程共享,存放对象实例,所有的对象的内存都在这里分配。垃圾回收主要就是作用于这里的。
- java虚拟机栈:线程私有,生命周期与线程相同。每个方法执行的时候都会创建一个栈帧(stack frame)用于存放 局部变量表、操作栈、动态链接、方法出口
- native方法栈
- 程序计数器:这里记录了线程执行的字节码的行号,在分支、循环、跳转、异常、线程恢复等都依赖这个计数器。
- 方法区:线程共享的存储了每个类对象的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。
垃圾回收
0. java中存在内存泄漏吗
- java中存在内存泄漏
- java中虽然有GC帮我们自动回收内存,但是只有当实例没有引用指向它时才会被回收,若我们错误的持有了引用,没有在应当释放时释放,就会造成内存泄漏,例如在长生命周期对象持有短生命周期对象。
举例:
import java.util.Arrays;
import java.util.EmptyStackException;
public class MyStack<T> {
private T[] elements;
private int size = 0;
private static final int INIT_CAPACITY = 16;
public MyStack() {
elements = (T[]) new Object[INIT_CAPACITY];
}
public void push(T elem) {
ensureCapacity();
elements[size++] = elem;
}
public T pop() {
if(size == 0)
throw new EmptyStackException();
return elements[--size];
}
private void ensureCapacity() {
if(elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
}
分析:这里用数组实现了一个栈,但是当数据pop之后,数组里内容并没有被清空。
1. GC是什么?为什么要有GC?
- GC是垃圾收集器(Garbage Collection)的缩写,是面试中常考的点。了解GC的运行方式,对防止内存泄漏,提高运行效率等都有好处
- 垃圾收集器会自动进行内存回收,不需要程序员进行操作,System.gc() 或Runtime.getRuntime().gc() 时并不是马上进行内存回收,甚至不会进行内存回收
- 详细参见JVM的内存回收机制
2. 如何定义垃圾
- 引用计数(无法解决循环引用的问题)
- 可达性分析
3. 什么变量能作为GCRoot
- 虚拟机栈(栈帧中的本地变量表)中引用的对象;
- 方法区中的类静态属性引用的对象
- 方法区中的常量引用的对象
- 原生方法栈(Native Method Stack)中 JNI 中引用的对象。
4. 垃圾回收的方法
- 标记-清除(Mark-Sweep)法:减少停顿时间,但会造成内存碎片
- 标记-整理(Mark-Compact)法:可以解决内存碎片问题,但是会增加停顿时间
- 复制(copying)法:从一个地方拷贝到另一个地方,适合有大量回收的场景,比如新生代回收
- 分代收集:把内存区域分成不同代,根据代不同采取不同的策略
新生代(Yong Generation):存放新创建的对象,采用复制回收方法;年老代(old Generation):这些对象垃圾回收的频率较低,采用的标记整理方法,这里的垃圾回收叫做 major GC;永久代(permanent Generation):存放Java本身的一些数据,当类不再使用时,也会被回收。
5. JVM垃圾回收何时触发MinorGC等操作
- minorGc发生在年轻代,是复制回收
- 年轻代可以分为三个区域:Eden、from Survivor和to Survivor;当Eden满了的时候,触发minorGc
- Gc过程:Eden区复制到to区;from区年龄大的被移到年老区,年龄小的复制到to区;to区变成from区;
6. JVM 年轻代到年老代的晋升过程的判断条件是什么
- 在年轻代gc过程中存活的次数超过阈值
- 或者太大了直接放入年老代
- to Survivor满了,新对象直接放入老年代
- 还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于From和To空间总和的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认)
7. Full GC 触发的条件
- 调用System.gc时,系统建议执行Full GC,但是不必然执行
- 老年代或者永久代空间不足
- 其他(=-=)
8. OOM错误,stackoverflow错误,permgen space错误
- OOM 是堆内存溢出
- stackoverflow是栈内存溢出
- permgen space说的是溢出的区域在永久代
9. 内存溢出的种类
- stackoverflow:;当线程调用一个方法是,jvm压入一个新的栈帧到这个线程的栈中,只要这个方法还没返回,这个栈帧就存在。如果方法的嵌套调用层次太多(如递归调用),随着java栈中的帧的增多,最终导致这个线程的栈中的所有栈帧的大小的总和大于-Xss设置的值,而产生生StackOverflowError溢出异常
- outofmemory:
- java程序启动一个新线程时,没有足够的空间为改线程分配java栈,一个线程java栈的大小由-Xss设置决定;JVM则抛出OutOfMemoryError异常;
- java堆用于存放对象的实例,当需要为对象的实例分配内存时,而堆的占用已经达到了设置的最大值(通过-Xmx)设置最大值,则抛出OutOfMemoryError异常;
- 方法区用于存放java类的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。在类加载器加载class文件到内存中的时候,JVM会提取其中的类信息,并将这些类信息放到方法区中。当需要存储这些类信息,而方法区的内存占用又已经达到最大值(通过-XX:MaxPermSize);将会抛出OutOfMemoryError异常
参考资料
http://www.jcodecraeer.com/a/chengxusheji/java/2015/0520/2896.html 本文是Android面试题整理中的一篇,结合右下角目录食用更佳,包括:
- 集合
- 内存
- 垃圾回收
集合
0. List和Set的区别
- 它们都是接口,都实现了Collection接口
- List元素可以重复,元素顺序与插入顺序相同,其子类有LinkedList和ArrayList
- Set元素不能重复,元素顺序与插入顺序不同,子类有HashSet(通过HashMap实现),LinkedHashSet,TreeSet(红黑树实现,排序的)
1. List、Map、Set三个接口存取元素时,各有什么特点?
- List继承了Collection,储存值,可以有重复值
- Set继承了Collection,储存值,不能有重复值
- Map储存健值对,可以一对一或一对多
2. List、Set、Map是否继承自Collection接口
List、Set 是,Map 不是。Map是键值对映射容器,与List和Set有明显的区别,而Set存储的零散的元素且不允许有重复元素(数学中的集合也是如此),List是线性结构的容器,适用于按数值索引访问元素的情形
3. HashMap实现原理
- 在1.7中,HashMap采用数组+单链表的结构;1.8中,采用数组+单链表或红黑树的结构(当链表size > 8时,转换成红黑树)
- HaspMap中有两个关键的构造函数,一个是初始容量,另一个是负载因子。
- 初始容量即数组的初始大小,当map中元素个数 > 初始容量*负载因子时,HashMap调用resize()方法扩容
- 在存入数据时,对key的hashCode再次进行hash(),目的是让hash值分布均匀
- 对hash() 返回的值与容量进行与运算,确定在数组中的位置
- key可以为null,null的hash值是0
4. HashMap是怎么解决hash冲突的
- 对hashCode在调用hash()方法进行计算
- 当超过阈值时进行扩容
- 当发生冲突时使用链表或者红黑树解决冲突
5. 为什么不直接采用经过hashCode()处理的哈希码作为存储数组table的下标位置
- hashCode可能很大,数组初始容量可能很小,不匹配,所以需要: hash码 & (数组长度-1)作为数组下标
- hashCode可能分布的不均匀
6. 为什么在计算数组下标前,需对哈希码进行二次处理:扰动处理?
加大哈希码低位的随机性,使得分布更均匀,从而提高对应数组存储下标位置的随机性 & 均匀性,最终减少Hash冲突
7. 为什么说HashMap不保证有序,储存位置会随时间变化
- 通过hash值确定位置,与用户插入顺序不同
- 在达到阈值后,HashMap会调用resize方法扩容,扩容后位置发生变化
8. HashMap的时间复杂度
HashMap通过数组和链表实现,数组查找的时间复杂度是O(1),链表的时间复杂度是O(n),所以要让HashMap尽可能的块,就需要链表的长度尽可能的小,当链表长度是1是,HashMap的时间复杂度就变成了O(1);根据HashMap的实现原理,要想让链表长度尽可能的短,需要hash算法尽量减少冲突。
9. HashMap 中的 key若 Object类型, 则需实现哪些方法
hashCode和equals
10. 为什么 HashMap 中 String、Integer 这样的包装类适合作为 key 键
- 它们是final的,不可变,保证了安全性
- 均已经实现了hashCode和equals方法,计算准确
11. HashMap线程安全吗
- HashMap线程不安全
- HashMap没有同步锁,举例:比如A、B两个线程同时触发扩容,HashMap容量增加2倍,并将原数据重新分配到新的位置,这个时候可能出现原链表转移到新链表时生成了环形链表,出现死循环。
12. HashMap线程安全的解决方案
- 使用Collections.synchronizedMap()方法,该方法的实现方式是使用synchronized关键字
- 使用ConcurrentHashMap,性能比Collections.synchronizedMap()更好
13. HashMap 如何删除元素
- 计算key的Hash值,找到数组中的位置,得到链表的头指针
- 遍历链表,通过equals比较key,确定是不是要找的元素
- 找到后调整链表,将该元素从链表中删除
//源码 java8
@Override public V remove(Object key) {
if (key == null) {
return removeNullKey();
}
int hash = Collections.secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
int index = hash & (tab.length - 1);
for (HashMapEntry<K, V> e = tab[index], prev = null;
e != null; prev = e, e = e.next) {
if (e.hash == hash && key.equals(e.key)) {
if (prev == null) {
tab[index] = e.next;
} else {
prev.next = e.next;
}
modCount++;
size--;
postRemove(e);
return e.value;
}
}
return null;
}
14. HashMap的扩容过程
- 在初次加载时,会调用resize()进行初始化
- 当put()时,会查看当前元素个数是否大于阈值(阈值=数组长度*负载因子),当大于时,调用resize方法扩容
- 新建一个数组,扩容后的容量是原来的两倍
- 将原来的数据重新计算位置,拷贝到新的table上
15. java8 中HashMap的优化
最大变化是当链表超过一定的长度后,将链表转换成红黑树存储,在存储很多数据时,效率提升了。链表的查找复杂度是O(n),红黑树是O(log(n))
16. HashMap和HashTable的区别
- HashTable是线程安全的,而HashMap不是
- HashMap中允许存在null键和null值,而HashTable中不允许
- HashTable已经弃用,我们可以用ConcurrentHashMap等替代
17. ConcurrentHashMap实现原理
- ConcurrentHashMap是线程安全的HashMap,效率比直接加cynchronized要好
- 1.7中通过分段锁实现,读不枷锁(通过volatile保证可见性),写时给对应的分段加锁。(1.8实现原理变了)
18. ConcurrentHashMap的并发度是什么
- ConcurrentHashMap通过分段锁来实现,并发度即为段数
- 段数是ConcurrentHashMap类构造函数的一个可选参数,默认值为16
19. LinkedHashMap原理
- LinkedHashMap通过继承HashMap实现,既保留了HashMap快速查找能力,又保存了存入顺序
- LinkedHashMap重写了HashMap的Entry,通过LinkedEntry保存了存入顺序,可以理解为通过双向链表和HashMap共同实现
20. HashMap和Arraylist都是线程不安全的,怎么让他们线程安全
- 借助Collections工具类synchronizedMap和synchronizedList将其转为线程安全的
- 使用安全的类替代,如HashTable(不建议使用)或者ConcurrentHashMap替代Hashmap,用CopyOnWriteArrayList替代ArrayList
21. HashSet 是如何保证不重复的
- HashSet 是通过HashMap来实现的,内部持有一个HashMap实例
- HashSet存入的值即为HashMap的key,hashMap的value是HashSet中new 的一个Object实例,所有的value都相同
22. TreeSet 两种排序方式
- 自然排序:调用无参构造函数,添加的元素必须实现Comparable接口
- 定制排序:使用有参构造函数,传入一个Comparator实例
23. Array 和 ArrayList对比
- Array可以是基本类型和引用类型,ArrayList只能是引用类型
- Array固定大小,ArrayList长度可以动态改变
- ArrayList有很多方法可以调用,如addAll()
24. List和数组的互相转换/String转换成数组
- String[] a = list.toArray(new String[size]));
- List list = Arrays.asList(array);
- char[] char = string.toCharArray();
25. 数组在内存中是如何分配的
和引用类型一样,在栈中保存一个引用,指向堆地址
26. TreeMap和TreeSet在排序时如何比较元素?Collections工具类中的sort()方法如何比较元素?
- TreeMap和TreeSet都是通过红黑树实现的,因此要求元素都是可比较的,元素必须实现Comparable接口,该接口中有compareTo()方法。
- Collections的sort方法有两种重载形式,一种只有一个参数,要求传入的待排序元素必须实现Comparable接口;第二种有两个参数,要求传入待排序容器即Comparator实例
27. 阐述ArrayList、Vector、LinkedList的存储性能和特性。
- ArrayList 和Vector都是使用数组方式存储数据,数组方式节省空间,便与读取;但插入删除涉及数组移动,性能较差。
- Vector中的方法由于添加了synchronized修饰,因此Vector是线程安全的容器。
- LinkedList使用双向链表实现存储,占用空间大,读取慢;插入删除快
- Vector已经被遗弃,不推荐使用。为了实现线程安全的list,可以使用Collections中的synchronizedList方法将其转换成线程安全的容器后再使用
28. 什么是Java优先级队列(Priority Queue)
PriorityQueue是一个基于优先级堆的无界队列,它的元素是按照自然顺序(natural order)排序的。在创建的时候,我们可以给它提供一个负责给元素排序的比较器。PriorityQueue不允许null值,因为他们没有自然顺序,或者说他们没有任何的相关联的比较器。PriorityQueue的逻辑结构为堆(完全二叉树),物理结构为数组。最后,PriorityQueue不是线程安全的,入队和出队的时间复杂度是O(log(n))
29. List、Set、Map的遍历方式
30. 什么是Iterator(迭代器)
迭代器是一个接口,我们可以借助这个接口实现对集合的遍历,删除 扩展(迭代器实现原理):Collection继承了Iterable接口,iterable接口中有iterator方法,返回一个Iterator迭代器 -> Collection的实现类通过在内部实现自定义Iterator,在iterator时返回这个实例。
31. Iterator和ListIterator的区别是什么
- ListIterator 继承自 Iterator
- Iterator可用来遍历Set和List集合,但是ListIterator只能用来遍历List
- ListIterator比Iterator增加了更多功能,例如可以双向遍历,增加元素等
32. 如何权衡是使用无序的数组还是有序的数组
- 查找多用有序数组,插入删除多用无序数组
- 解释:有序数组最大的好处在于查找的时间复杂度是O(log n),而无序数组是O(n)。有序数组的缺点是插入操作的时间复杂度是O(n),因为值大的元素需要往后移动来给新元素腾位置。相反,无序数组的插入时间复杂度是常量O(1)
33. Arrays.sort 实现原理和 Collections.sort 实现原理
- Collections.sort是通过Arrays.sort实现的。当list不为ArrayList时,先转成数组,再调用Arrays.sort
- java 8 中Array.Sort()是通过timsort(一种优化的归并排序)来实现的
34. Collection和Collections的区别
- Collection 是一个接口,Set、List都继承了该接口
- Collections 是一个工具类,该工具类可以帮我们完成对容器的判空,排序,线程安全化等。
35. 快速失败(fail-fast)和安全失败(fail-safe)
- 快速失败:在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception
- 安全失败:操作是对象的副本,这个时候原对象改变并不会对当前迭代器遍历产生影响。java.util.concurrent类下边容器都是安全失败
扩展:快速失败原理:容器内部有一个modCount,记录变化的次数,当进行遍历时,如果mocount值发生改变,责快速失败
36. 当一个集合被作为参数传递给一个函数时,如何才可以确保函数不能修改它
在作为参数传递之前,我们可以使用Collections.unmodifiableCollection(Collection c)方法创建一个只读集合,这将确保改变集合的任何操作都会抛出UnsupportedOperationException。
内存
0. 内存中的栈(stack)、堆(heap)和方法区(method area)?
- 栈:线程独有,每个线程一个栈区。保存基本数据类型,对象的引用,函数调用的现场(栈可以分为三个部分:基本类型,执行环境上下文,操作指令区(存放操作指令));优点是速度快,缺点是大小和生存周期必须是确定的
- 堆:线程共享,jvm一共一个堆区。保存对象的实例,垃圾回收器回收的是堆区的内存
- 方法区(静态区):线程共享。保存类信息、常量、静态变量、JIT编译器编译后的代码等数据,常量池是方法区的一部分。
1. Jvm内存模型
- 堆:线程共享,存放对象实例,所有的对象的内存都在这里分配。垃圾回收主要就是作用于这里的。
- java虚拟机栈:线程私有,生命周期与线程相同。每个方法执行的时候都会创建一个栈帧(stack frame)用于存放 局部变量表、操作栈、动态链接、方法出口
- native方法栈
- 程序计数器:这里记录了线程执行的字节码的行号,在分支、循环、跳转、异常、线程恢复等都依赖这个计数器。
- 方法区:线程共享的存储了每个类对象的信息(包括类的名称、方法信息、字段信息)、静态变量、常量以及编译器编译后的代码等。
垃圾回收
0. java中存在内存泄漏吗
- java中存在内存泄漏
- java中虽然有GC帮我们自动回收内存,但是只有当实例没有引用指向它时才会被回收,若我们错误的持有了引用,没有在应当释放时释放,就会造成内存泄漏,例如在长生命周期对象持有短生命周期对象。
举例:
import java.util.Arrays;
import java.util.EmptyStackException;
public class MyStack<T> {
private T[] elements;
private int size = 0;
private static final int INIT_CAPACITY = 16;
public MyStack() {
elements = (T[]) new Object[INIT_CAPACITY];
}
public void push(T elem) {
ensureCapacity();
elements[size++] = elem;
}
public T pop() {
if(size == 0)
throw new EmptyStackException();
return elements[--size];
}
private void ensureCapacity() {
if(elements.length == size) {
elements = Arrays.copyOf(elements, 2 * size + 1);
}
}
}
分析:这里用数组实现了一个栈,但是当数据pop之后,数组里内容并没有被清空。
1. GC是什么?为什么要有GC?
- GC是垃圾收集器(Garbage Collection)的缩写,是面试中常考的点。了解GC的运行方式,对防止内存泄漏,提高运行效率等都有好处
- 垃圾收集器会自动进行内存回收,不需要程序员进行操作,System.gc() 或Runtime.getRuntime().gc() 时并不是马上进行内存回收,甚至不会进行内存回收
- 详细参见JVM的内存回收机制
2. 如何定义垃圾
- 引用计数(无法解决循环引用的问题)
- 可达性分析
3. 什么变量能作为GCRoot
- 虚拟机栈(栈帧中的本地变量表)中引用的对象;
- 方法区中的类静态属性引用的对象
- 方法区中的常量引用的对象
- 原生方法栈(Native Method Stack)中 JNI 中引用的对象。
4. 垃圾回收的方法
- 标记-清除(Mark-Sweep)法:减少停顿时间,但会造成内存碎片
- 标记-整理(Mark-Compact)法:可以解决内存碎片问题,但是会增加停顿时间
- 复制(copying)法:从一个地方拷贝到另一个地方,适合有大量回收的场景,比如新生代回收
- 分代收集:把内存区域分成不同代,根据代不同采取不同的策略
新生代(Yong Generation):存放新创建的对象,采用复制回收方法;年老代(old Generation):这些对象垃圾回收的频率较低,采用的标记整理方法,这里的垃圾回收叫做 major GC;永久代(permanent Generation):存放Java本身的一些数据,当类不再使用时,也会被回收。
5. JVM垃圾回收何时触发MinorGC等操作
- minorGc发生在年轻代,是复制回收
- 年轻代可以分为三个区域:Eden、from Survivor和to Survivor;当Eden满了的时候,触发minorGc
- Gc过程:Eden区复制到to区;from区年龄大的被移到年老区,年龄小的复制到to区;to区变成from区;
6. JVM 年轻代到年老代的晋升过程的判断条件是什么
- 在年轻代gc过程中存活的次数超过阈值
- 或者太大了直接放入年老代
- to Survivor满了,新对象直接放入老年代
- 还有一种情况,如果在From空间中,相同年龄所有对象的大小总和大于From和To空间总和的一半,那么年龄大于等于该年龄的对象就会被移动到老年代,而不用等到15岁(默认)
7. Full GC 触发的条件
- 调用System.gc时,系统建议执行Full GC,但是不必然执行
- 老年代或者永久代空间不足
- 其他(=-=)
8. OOM错误,stackoverflow错误,permgen space错误
- OOM 是堆内存溢出
- stackoverflow是栈内存溢出
- permgen space说的是溢出的区域在永久代
9. 内存溢出的种类
- stackoverflow:;当线程调用一个方法是,jvm压入一个新的栈帧到这个线程的栈中,只要这个方法还没返回,这个栈帧就存在。如果方法的嵌套调用层次太多(如递归调用),随着java栈中的帧的增多,最终导致这个线程的栈中的所有栈帧的大小的总和大于-Xss设置的值,而产生生StackOverflowError溢出异常
- outofmemory:
- java程序启动一个新线程时,没有足够的空间为改线程分配java栈,一个线程java栈的大小由-Xss设置决定;JVM则抛出OutOfMemoryError异常;
- java堆用于存放对象的实例,当需要为对象的实例分配内存时,而堆的占用已经达到了设置的最大值(通过-Xmx)设置最大值,则抛出OutOfMemoryError异常;
- 方法区用于存放java类的相关信息,如类名、访问修饰符、常量池、字段描述、方法描述等。在类加载器加载class文件到内存中的时候,JVM会提取其中的类信息,并将这些类信息放到方法区中。当需要存储这些类信息,而方法区的内存占用又已经达到最大值(通过-XX:MaxPermSize);将会抛出OutOfMemoryError异常
参考资料
http://www.jcodecraeer.com/a/chengxusheji/java/2015/0520/2896.html
