

序
本文主要梳理下NLP系统的体系结构及流程。
NLP架构
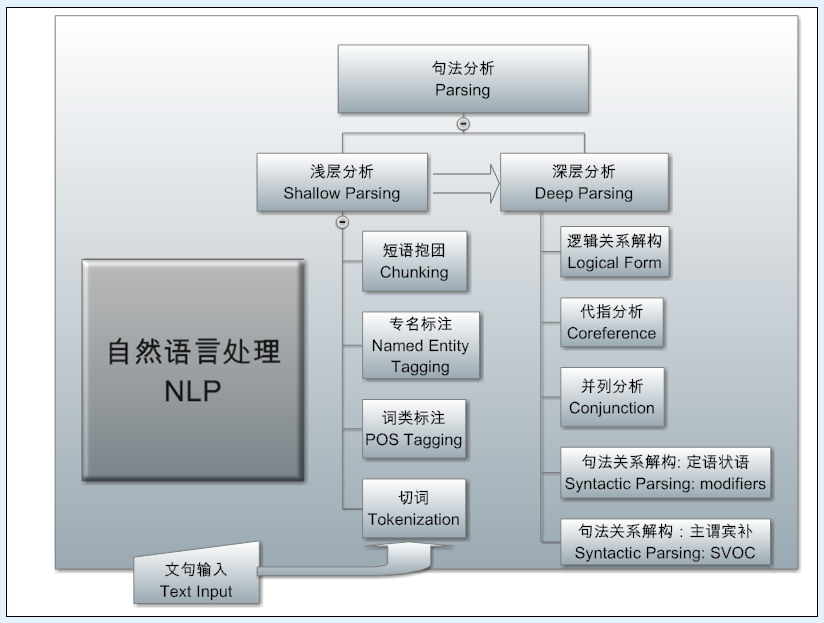
主要流程步骤
- 分/切词(
Tokenization) - 词性标注(
POS Tagging) - 语义组块(
Chunking) - 命名实体标注(
Named Entity Tagging)
前面几个主要属于nlp的浅层分析任务,即序列标注任务。
- 句法分析
- 文本/语义分析
中文分词
中文不像英文那样有空格来分词,因此在分析文本之前就必须将一连串的汉字分解成合适的词语。
分词(从句到词)技术这块主要
基于词典的分词方法(
最大匹配法、最短路径法、最大概率法),实际用的比较多的如下:
- 基于条件随机场(CRF)的中文分词算法的开源系统。
- 基于张华平NShort的中文分词算法的开源系统(
结巴分词核心算法)。
合词(
从字到词)主要用到基于字序列标注的方法。
词性标注(POS Tagging)
词性,也称为词类,是词汇的语法属性,是连接词汇到句法的桥梁。 词性标注(Part-of-Speech Tagging或POS Tagging),又称为词类标注,是指判断出在一个句子中每个词所扮演的语法角色。
这块的技术大多数使用HMM(隐马尔科夫模型)+ Viterbi算法,最大熵算法(Maximum Entropy)。目前流行的中文词性标签有两大类:北大词性标注集和宾州词性标注集。
现代汉语的词可以分为两类12种词性:一类是实词:名词、动词、形容词、数词、量词和代词;另一类是虚词:副词、介词、连词、助词、叹词和拟声词。
语义组块(Chunking)
将标注好词性的句子按句法结构把某些词聚合在一起形成比如主语、谓语、宾语等等;
语义组块最常用的方法是条件随机场(Conditional Random Fields,CRF)
命名实体标注(Named Entity Tagging)
命名实体识别用于识别文本中具有特定意义的实体,常见的实体主要包括人名、地名、机构名及其他专有名词等。命名实体识别任务还要识别出文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
这块使用到的技术就是标准的HMM模型和Viterbi算法。
句法分析
句法分析是根据给定的语法体系自动推导出句子的语法结构,分析句子所包含的语法单元和这些语法单元之间的关系,将句子转化为一棵结构化的语法树。
目前句法分析主要的理论如下:
- 短语结构语法分析
- 依存语法分析
文本/语义分析
主要包括:文本相似度分析、文本关键词提取、文本分类、内容摘要、情感倾向分析。 其中语义分析,就涉及到指代消解等技术;文本分类可以用朴素贝叶斯算法。
小结
本文主要解析了下NLP系统的体系结构及主要流程,方便后续有的放矢地深入学习。
