

简述: 今天带来的是Kotlin浅谈系列的第四弹,这次主要聊下Kotlin独有的新特性,Java不具备的。Kotlin是一种增加许多新功能的语言,允许编写更简洁易读的代码,这使得我们的代码更易于维护。例如使用顶层函数和属性从此消除Java中的static、中缀表达式调用和解构声明等。
- 1、为什么要用顶层函数替代Java中的static函数
- 2、顶层函数和属性的基本使用
- 3、顶层函数实质原理
- 4、顶层函数使用应注意哪些问题
- 5、一起尝尝中缀调用语法糖
- 6、中缀调用的基本使用
- 7、中缀调用实质原理
- 8、中缀调用应注意哪些问题
- 9、Kotlin中的解构声明
一、为什么要用顶层函数替代Java中的static函数
概念: 我们知道在Java中有静态函数和静态属性概念,它们一般作用就是为了提供一个全局共享访问区域和方法。我们一般的习惯的写法就是写一个类包裹一些static修饰的方法,然后在外部访问的直接利用类名.方法名访问。
问题: 我们都知道静态函数内部是不包含状态的,也就是所谓的纯函数,它的输入仅仅来自于它的参数列表,而它的输出也仅仅依赖于它参数列表。我们设想一下这样开发情景,有时候我们并不想利用实例对象来调用函数,所以我们一般会往静态函数容器类中添加静态函数,如此反复,这样无疑是让这个类容器膨胀。
解决: 在Kotlin中则认为一个函数或方法有时候并不是属于任何一个类,它可以独立存在。所以在Kotlin中类似静态函数和静态属性会去掉外层类的容器,一个函数或者属性可以直接定义在一个Kotlin文件的顶层中,在使用的地方只需要import这个函数或属性即可。如果你的代码还存在很多以"Util"后缀结尾的工具类,是时候去掉了。
二、顶层函数和属性的基本使用
在Koltin中根本不需要去定义一些没有意义包裹静态函数的容器类,它们都被顶层文件给替代。我们只需要定义一个Kotlin File,在里面定义好一些函数(注意: 不需要static关键字)。那么这些函数就可以当做静态函数来使用
创建一个顶层文件:
在顶层文件中定义一个函数:
package com.mikyou.kotlin.top
import java.math.BigDecimal
/**
* Created by mikyou on 2018/4/10.
*/
//这个顶层函数不属于任何一个类,不需要类容器,不需要static关键字
fun formateFileSize(size: Double): String {
if (size < 0) {
return "0 KB"
}
val kBSize = size / 1024
if (kBSize < 1) {
return "$size B"
}
val mBSize = kBSize / 1024
if (mBSize < 1) {
return "${BigDecimal(kBSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} KB"
}
val mGSize = mBSize / 1024
if (mGSize < 1) {
return "${BigDecimal(mBSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} MB"
}
val mTSize = mGSize / 1024
if (mTSize < 1) {
return "${BigDecimal(mGSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} GB"
}
return "${BigDecimal(mTSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} TB"
}
//测试顶层函数,实际上Kotlin中main函数和Java不一样,它可以不存在任何类容器中,可以直接定义在一个Kotlin 文件中
//另一方面也解释了Kotlin中的main函数不需要了static关键字,实际上它自己就是个顶层函数。
fun main(args: Array<String>) {
println("文件大小: ${formateFileSize(15582.0)}")
}
从以上代码可以看出定义一个顶层函数是不是很简单,那么问题来了这个formateFileSize函数定义在一个文件内部,在JVM中是怎么执行的呢?请接着往下看...
三、顶层函数实质原理
通过以上例子我们思考一下顶层函数在JVM中是怎么运行的,如果你仅仅是在Kotlin中使用这些顶层函数,那么可以不用细究。但是如果你是Java和Kotlin混合开发模式,那么你就有必要深入内部原理。我们都知道Kotlin和Java互操作性是很强的,所以就衍生出了一个问题:在Kotlin中定义的顶层函数,在Java可以调用吗?答案肯定是可以的。怎么调用的,请接着看。
要想知道内部调用原理很简单,我们只需要把上面例子代码反编译成Java代码就一目了然了。这里科普一下反编译Kotlin代码步骤,因为这是查看Kotlin语法糖背后实质很好的方法。
步骤一: 确认IDE安装好了Kotlin Plugin
步骤二: 在IDE中打开你需要查看反编译的代码文件,然后打开顶部的"Tools",选择"Kotlin",再选择"Show Kotlin ByteCode"
步骤三: 左边是Kotlin的源码,右边是Kotlin的ByteCode
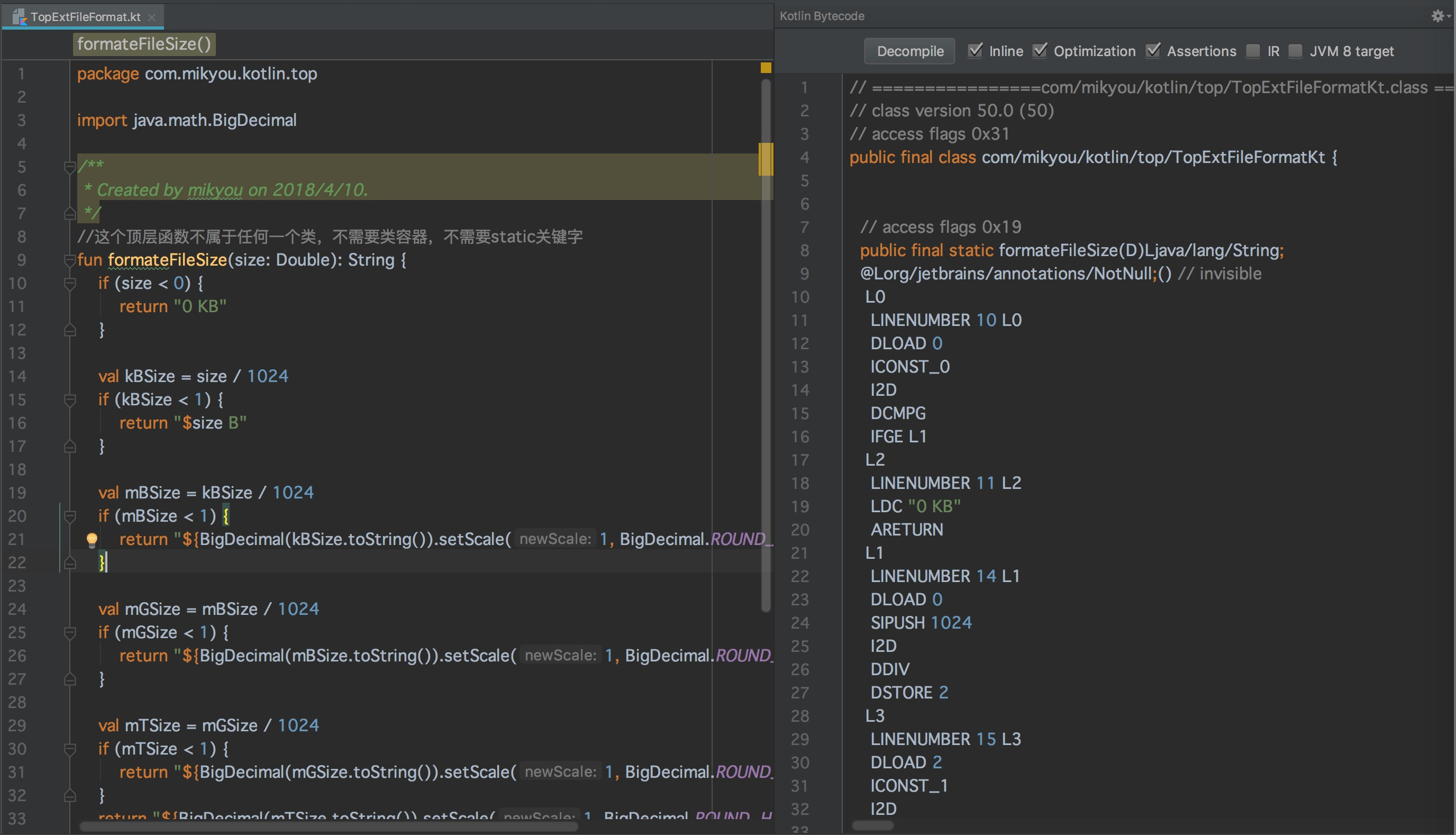
步骤四: 点击右侧“Decompile”
package com.mikyou.kotlin.top;
import java.math.BigDecimal;
import kotlin.Metadata;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
@Metadata(
mv = {1, 1, 9},
bv = {1, 0, 2},
k = 2,
d1 = {"\u0000\u001c\n\u0000\n\u0002\u0010\u000e\n\u0000\n\u0002\u0010\u0006\n\u0000\n\u0002\u0010\u0002\n\u0000\n\u0002\u0010\u0011\n\u0002\b\u0002\u001a\u000e\u0010\u0000\u001a\u00020\u00012\u0006\u0010\u0002\u001a\u00020\u0003\u001a\u0019\u0010\u0004\u001a\u00020\u00052\f\u0010\u0006\u001a\b\u0012\u0004\u0012\u00020\u00010\u0007¢\u0006\u0002\u0010\b¨\u0006\t"},
d2 = {"formateFileSize", "", "size", "", "main", "", "args", "", "([Ljava/lang/String;)V", "production sources for module Function"}
)
public final class TopExtFileFormatKt {//一般以文件名+"Kt"后缀作为容器类名
@NotNull
public static final String formateFileSize(double size) {//顶层函数反编译成Java中静态函数
if(size < (double)0) {
return "0 KB";
} else {
double kBSize = size / (double)1024;
if(kBSize < (double)1) {
return "" + size + " B";
} else {
double mBSize = kBSize / (double)1024;
if(mBSize < (double)1) {
return "" + (new BigDecimal(String.valueOf(kBSize))).setScale(1, 4).toPlainString() + " KB";
} else {
double mGSize = mBSize / (double)1024;
if(mGSize < (double)1) {
return "" + (new BigDecimal(String.valueOf(mBSize))).setScale(1, 4).toPlainString() + " MB";
} else {
double mTSize = mGSize / (double)1024;
return mTSize < (double)1?"" + (new BigDecimal(String.valueOf(mGSize))).setScale(1, 4).toPlainString() + " GB":"" + (new BigDecimal(String.valueOf(mTSize))).setScale(1, 4).toPlainString() + " TB";
}
}
}
}
}
public static final void main(@NotNull String[] args) {//顶层函数反编译成Java中静态函数
Intrinsics.checkParameterIsNotNull(args, "args");
String var1 = "文件大小: " + formateFileSize(15582.0D);
System.out.println(var1);
}
}
通过以上的代码可以总结出两点内容:
- 1、顶层文件会反编译成一个容器类。(类名一般默认就是顶层文件名+"Kt"后缀,注意容器类名可以自定义)
- 2、顶层函数会反编译成一个static静态函数,如代码中的formateFileSize和main函数
想必到这里你大概猜到了Java中如何调用Kotlin中的顶层函数了吧。调用方式很简单,就是利用反编译生成的类作为静态函数容器类直接调用对应的函数
package com.mikyou.kotlin.top;
/**
* Created by mikyou on 2018/4/10.
*/
public class TopExtTest {
public static void main(String[] args) {
System.out.println("文件大小: " + TopExtFileFormatKt.formateFileSize(1343553));// Java中调用Kotlin中定义顶层函数,一般是顶层文件名+"Kt"后缀作为静态函数的类名调用相应函数
}
}
四、顶层函数使用应注意的问题
Kotlin中的顶层函数反编译成的Java中的容器类名一般是顶层文件名+“Kt”后缀作为类名,但是也是可以自定义的。也就是说顶层文件名和生成容器类名没有必然的联系。通过Kotlin中的@file: JvmName("自定义生成类名")注解就可以自动生成对应Java调用类名,注意需要放在文件顶部,在package声明的前面
//通过@file: JvmName("FileFormatUtil")注解,将生成的类名修改为FileFormatUtil,并且调用的时候直接调用FileFormatUtil.formateFileSize()即可
//放在文件顶部,在package声明的前面
@file: JvmName("FileFormatUtil")
package com.mikyou.kotlin.top
import java.math.BigDecimal
/**
* Created by mikyou on 2018/4/10.
*/
//这个顶层函数不属于任何一个类,不需要类容器,不需要static关键字
fun formateFileSize(size: Double): String {
if (size < 0) {
return "0 KB"
}
val kBSize = size / 1024
if (kBSize < 1) {
return "$size B"
}
val mBSize = kBSize / 1024
if (mBSize < 1) {
return "${BigDecimal(kBSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} KB"
}
val mGSize = mBSize / 1024
if (mGSize < 1) {
return "${BigDecimal(mBSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} MB"
}
val mTSize = mGSize / 1024
if (mTSize < 1) {
return "${BigDecimal(mGSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} GB"
}
return "${BigDecimal(mTSize.toString()).setScale(1, BigDecimal.ROUND_HALF_UP).toPlainString()} TB"
}
//测试顶层函数,实际上Kotlin中main函数和Java不一样,它可以不存在任何类容器中,可以直接定义在一个Kotlin 文件中
//另一方面也解释了Kotlin中的main函数不需要了static关键字,实际上它自己就是个顶层函数。
fun main(args: Array<String>) {
println("文件大小: ${formateFileSize(15582.0)}")
}
然后我们再来一起看看反编译成Java代码变成什么样了
package com.mikyou.kotlin.top;
import java.math.BigDecimal;
import kotlin.Metadata;
import kotlin.jvm.JvmName;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
@Metadata(
mv = {1, 1, 9},
bv = {1, 0, 2},
k = 2,
d1 = {"\u0000\u001c\n\u0000\n\u0002\u0010\u000e\n\u0000\n\u0002\u0010\u0006\n\u0000\n\u0002\u0010\u0002\n\u0000\n\u0002\u0010\u0011\n\u0002\b\u0002\u001a\u000e\u0010\u0000\u001a\u00020\u00012\u0006\u0010\u0002\u001a\u00020\u0003\u001a\u0019\u0010\u0004\u001a\u00020\u00052\f\u0010\u0006\u001a\b\u0012\u0004\u0012\u00020\u00010\u0007¢\u0006\u0002\u0010\b¨\u0006\t"},
d2 = {"formateFileSize", "", "size", "", "main", "", "args", "", "([Ljava/lang/String;)V", "production sources for module Function"}
)
@JvmName(//注意这里多了注解
name = "FileFormatUtil"
)
public final class FileFormatUtil {//这里生成的类名就是注解中自定义生成的类名了
@NotNull
public static final String formateFileSize(double size) {
if(size < (double)0) {
return "0 KB";
} else {
double kBSize = size / (double)1024;
if(kBSize < (double)1) {
return "" + size + " B";
} else {
double mBSize = kBSize / (double)1024;
if(mBSize < (double)1) {
return "" + (new BigDecimal(String.valueOf(kBSize))).setScale(1, 4).toPlainString() + " KB";
} else {
double mGSize = mBSize / (double)1024;
if(mGSize < (double)1) {
return "" + (new BigDecimal(String.valueOf(mBSize))).setScale(1, 4).toPlainString() + " MB";
} else {
double mTSize = mGSize / (double)1024;
return mTSize < (double)1?"" + (new BigDecimal(String.valueOf(mGSize))).setScale(1, 4).toPlainString() + " GB":"" + (new BigDecimal(String.valueOf(mTSize))).setScale(1, 4).toPlainString() + " TB";
}
}
}
}
}
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
String var1 = "文件大小: " + formateFileSize(15582.0D);
System.out.println(var1);
}
}
这样Java调用自定义类名顶层函数就更加自然,一般建议使用注解修改类名,这样在Java层调用还是我们习惯工具类的命名,完全无法感知这个函数是来自Java中还是Kotlin中定义的,做到完全透明。
package com.mikyou.kotlin.top;
/**
* Created by mikyou on 2018/4/10.
*/
public class TopExtTest {
public static void main(String[] args) {
System.out.println("文件大小: " + FileFormatUtil.formateFileSize(1343553));// Java中调用Kotlin中定义顶层函数,如果自定义生成类名,直接用定义类名调用。
}
}
五、一起尝尝中缀调用语法糖
中缀调用看起来是很高级概念,实际上原理很简单,但是它在语法层面简化了很多,更方便以及更容易理解,让我们写代码会更加接近自然语言。我个人理解中缀调用实际上就是把原来只有一个参数的函数调用简化成两个操作直接使用类似中缀运算符调用,省略了类名或者对象名+"."+函数名调用方式。废话不多说,直接发波糖
- 例子一 初始化map
package com.mikyou.kotlin.infix
/**
* Created by mikyou on 2018/4/10.
*/
//普通利用Pair()初始化一个map
fun main(args: Array<String>) {
val map = mapOf(Pair(1, "A"), Pair(2, "B"), Pair(3, "C"))
map.forEach { key, value ->
println("key: $key value:$value")
}
}
//利用to函数初始化一个map
fun main(args: Array<String>) {
val map = mapOf(1.to("A"), 2.to("B"), 3.to("C"))
map.forEach { key, value ->
println("key: $key value:$value")
}
}
//利用to函数中缀调用初始化一个map
fun main(args: Array<String>) {
val map = mapOf(1 to "A", 2 to "B", 3 to "C")//to实际上一个返回Pair对象的函数,不是属于map结构内部的运算符,但是to在语法层面使用很像中缀运算符调用
map.forEach { key, value ->
println("key: $key value:$value")
}
}
- 例子二 字符串比较
//普通使用字符串对比调用StringUtils.equals(strA, strB)
fun main(args: Array<String>) {
val strA = "A"
val strB = "B"
if (StringUtils.equals(strA, strB)) {//这里对比字符串是了apache中的StringUtils
println("str is the same")
} else {
println("str is the different")
}
}
//利用中缀调用sameAs对比两个字符串
fun main(args: Array<String>) {
val strA = "A"
val strB = "B"
if (strA sameAs strB) {//中缀调用 sameAs
println("str is the same")
} else {
println("str is the different")
}
}
- 例子三 判断一个元素是否在集合中
//普通调用集合contains方法判断元素是否在集合中
fun main(args: Array<String>) {
val list = listOf(1, 3, 5, 7, 9)
val element = 2
if (list.contains(element)) {
println("element: $element is into list")
} else {
println("element: $element is not into list")
}
}
//利用中缀调用into判断元素是否在集合中
fun main(args: Array<String>) {
val list = listOf(1, 3, 5, 7, 9)
val element = 2
if (element into list) {//中缀调用,这样的写法,会更加接近我们自然语言的表达,更容易理解
println("element: $element is into list")
} else {
println("element: $element is not into list")
}
}
六、中缀调用的基本使用
中缀调用使用非常简单,准确来说它使用类似加减乘除运算操作符的使用。调用结构: A (中缀函数名) B 例如: element into list
七、中缀调用实质原理
7.1 to函数系统内置中缀调用
- 源码分析
public infix fun <A, B> A.to(that: B): Pair<A, B> = Pair(this, that)
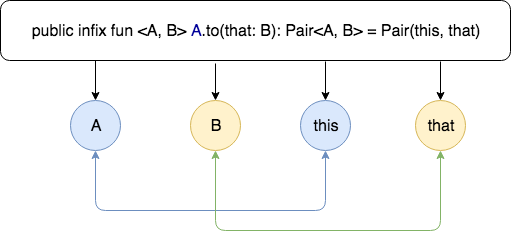
分析: 使用infix关键字修饰的函数,传入A,B两个泛型对象,“A.to(B)”结构,是一种特殊结构暂时把它叫做带接收者的结构,以至于后面的this就是指代A,并且函数的参数只有一个,返回的是一个Pair对象,this指代A,that就是传入的B类型对象。
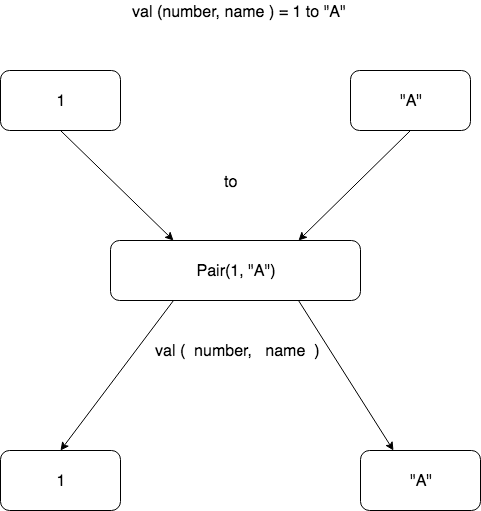
- to函数创建Pair对象,然后可以用解构声明展开
7.2 into函数自定义中缀调用
- 源码分析
infix fun <T> T.into(other: Collection<T>): Boolean = other.contains(this)
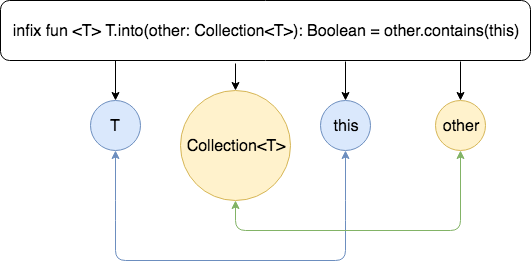
分析: 使用infix关键字修饰的函数,泛型T对象元素是否存在于泛型T集合之中。“T.into(Collection<T>)”结构,实际也是一种带接收者结构,this也就是指代了into函数前面调用T类型对象。
八、中缀调用应注意哪些问题
-
1、前面所讲to, into,sameAs实际上就是函数调用,如果把infix关键字去掉,那么也就纯粹按照函数调用方式来。比如1.to("A"), element.into(list)等,只有加了中缀调用的关键字infix后,才可以使用简单的中缀调用例如 1 to "A", element into list等
-
2、并不是所有的函数都能写成中缀调用,中缀调用首先必须满足一个条件就是函数的参数只有一个。然后再看这个函数的参与者是不是只有两个元素,这两个元素可以是两个数,可以是两个对象,可以是集合等。
九、Kotlin中的解构声明
9.1 解构声明概述
解构声明是把一个对象看成一组单独的变量,有时候我们把一个对象看成一组单独的变量管理会变得更加简单。注意: 支持解构声明的对象的类必须是数据类(使用data关键字修饰的类),因为只有data class才会生成对应的component()方法(这个会在后续中讲解到),data class中的每个属性都会有对应的component()方法对应
9.2 解构声明基本使用
- 先定义一个data class
package com.mikyou.kotlin.destruct
/**
* Created by mikyou on 2018/4/10.
*/
data class Student(var name: String, var age: Int, var grade: Double)
- 解构声明调用
package com.mikyou.kotlin.destruct
/**
* Created by mikyou on 2018/4/10.
*/
fun main(args: Array<String>) {
val student = Student("mikyou", 18, 99.0)
val (name, age, grade) = student//将一个student对象解构成一组3个单独的变量
println("my name is $name , I'm $age years old, I get $grade score")//解构后的3个变量可以脱离对象,直接单独使用
}
9.3 解构声明实质原理
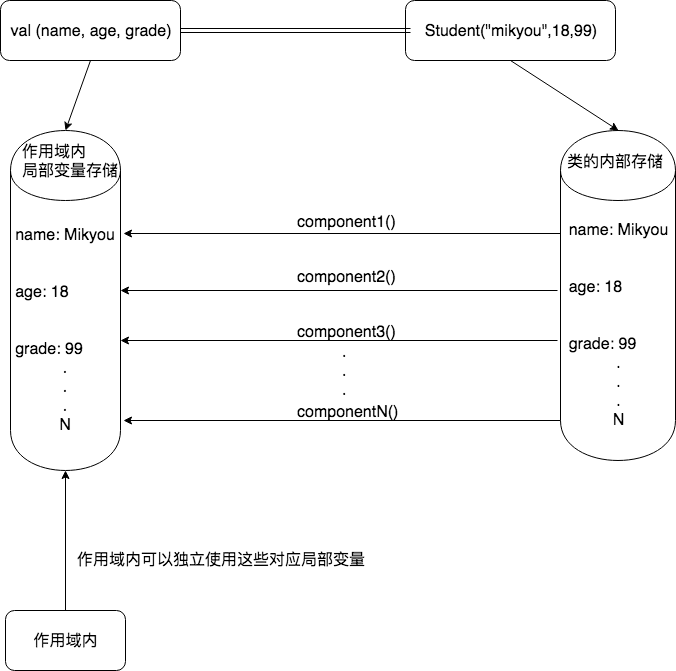
解构声明实际上就是将对象中所有属性,解构成一组属性变量,而且这些变量可以单独使用,为什么可以单独使用,是因为每个属性值的获得最后都编译成通过调用与之对应的component()方法,每个component()方法对应着类中每个属性的值,然后在作用域定义各自属性局部变量,这些局部变量存储着各自对应属性的值,所以看起来变量可以单独使用,实际上使用的是局部变量。如下反编译成的Java代码
package com.mikyou.kotlin.destruct;
import kotlin.Metadata;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
@Metadata(
mv = {1, 1, 9},
bv = {1, 0, 2},
k = 2,
d1 = {"\u0000\u0014\n\u0000\n\u0002\u0010\u0002\n\u0000\n\u0002\u0010\u0011\n\u0002\u0010\u000e\n\u0002\b\u0002\u001a\u0019\u0010\u0000\u001a\u00020\u00012\f\u0010\u0002\u001a\b\u0012\u0004\u0012\u00020\u00040\u0003¢\u0006\u0002\u0010\u0005¨\u0006\u0006"},
d2 = {"main", "", "args", "", "", "([Ljava/lang/String;)V", "production sources for module Function"}
)
public final class DestructTestKt {
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
Student student = new Student("mikyou", 18, 99.0D);
String name = student.component1();//对应的component1()方法,返回对应就是Student中name属性,并赋值给创建局部变量name
int age = student.component2();//对应的component2()方法,返回对应就是Student中age属性, 并赋值给创建局部变量age
double grade = student.component3();//对应的component3()方法,返回对应就是Student中属性,并赋值给创建局部变量grade
String var6 = "my name is " + name + " , I'm " + age + " years old, I get " + grade + " score";
System.out.println(var6);//注意: 这里单独使用的name, age, grade实际上是局部变量
}
}
9.4 解构声明应注意的问题
- 1、解构声明中解构对象的属性是可选的,也就是并不是要求该对象中所有属性都需要解构,也就是可选择需要解构的属性。可以使用下划线"_"省略不需要解构的属性也可以不写改属性直接忽略。注意: 虽然两者作用是一样的,但是最后生成component()方法不一样,使用下划线的会占用compoent1()方法,age直接从component2()开始生成, 直接不写name,age会从component1()方法开始生成。例如
下划线_ 忽略name属性例子
package com.mikyou.kotlin.destruct
/**
* Created by mikyou on 2018/4/10.
*/
fun main(args: Array<String>) {
val student = Student("mikyou", 18, 99.0)
val (_, age, grade) = student//下划线_ 忽略name属性
println("I'm $age years old, I get $grade score")//解构后的3个变量可以脱离对象,直接单独使用
}
//下划线_ 忽略name属性 反编译后Java代码
package com.mikyou.kotlin.destruct;
import kotlin.Metadata;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
@Metadata(
mv = {1, 1, 9},
bv = {1, 0, 2},
k = 2,
d1 = {"\u0000\u0014\n\u0000\n\u0002\u0010\u0002\n\u0000\n\u0002\u0010\u0011\n\u0002\u0010\u000e\n\u0002\b\u0002\u001a\u0019\u0010\u0000\u001a\u00020\u00012\f\u0010\u0002\u001a\b\u0012\u0004\u0012\u00020\u00040\u0003¢\u0006\u0002\u0010\u0005¨\u0006\u0006"},
d2 = {"main", "", "args", "", "", "([Ljava/lang/String;)V", "production sources for module Function"}
)
public final class DestructTestKt {
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
Student student = new Student("mikyou", 18, 99.0D);
int age = student.component2();//name会占用component1()方法,但是没有生成,所以age从component2()方法开始
double grade = student.component3();
String var5 = "I'm " + age + " years old, I get " + grade + " score";
System.out.println(var5);
}
}
直接不写name属性例子
package com.mikyou.kotlin.destruct
/**
* Created by mikyou on 2018/4/10.
*/
fun main(args: Array<String>) {
val student = Student("mikyou", 18, 99.0)
val (age, grade) = student//直接不写name属性
println("I'm $age years old, I get $grade score")//解构后的3个变量可以脱离对象,直接单独使用
}
//直接不写name属性 反编译后Java代码
package com.mikyou.kotlin.destruct;
import kotlin.Metadata;
import kotlin.jvm.internal.Intrinsics;
import org.jetbrains.annotations.NotNull;
@Metadata(
mv = {1, 1, 9},
bv = {1, 0, 2},
k = 2,
d1 = {"\u0000\u0014\n\u0000\n\u0002\u0010\u0002\n\u0000\n\u0002\u0010\u0011\n\u0002\u0010\u000e\n\u0002\b\u0002\u001a\u0019\u0010\u0000\u001a\u00020\u00012\f\u0010\u0002\u001a\b\u0012\u0004\u0012\u00020\u00040\u0003¢\u0006\u0002\u0010\u0005¨\u0006\u0006"},
d2 = {"main", "", "args", "", "", "([Ljava/lang/String;)V", "production sources for module Function"}
)
public final class DestructTestKt {
public static final void main(@NotNull String[] args) {
Intrinsics.checkParameterIsNotNull(args, "args");
Student student = new Student("mikyou", 18, 99.0D);
String age = student.component1();//直接不写name,然后age从component
int grade = student.component2();
String var4 = "I'm " + age + " years old, I get " + grade + " score";
System.out.println(var4);
}
}
- 2、解构声明的对象类型一定是data class,普通的class是不会生成对应的component的方法。

欢迎关注Kotlin开发者联盟,这里有最新Kotlin技术文章,每周会不定期翻译一篇Kotlin国外技术文章。如果你也喜欢Kotlin,欢迎加入我们~~~
