

- 原文地址:Open-sourcing a 10x reduction in Apache Cassandra tail latency
- 原文作者:Instagram Engineering
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:stormluke
- 校对者:allenlongbaobao
在 Instagram,我们的数据库是全球最大的 Apache Cassandra 部署之一。我们于 2012 年开始用 Cassandra 取代 Redis,来支持欺诈检测、信息流和 Direct 收件箱等产品需求。最初我们在 AWS 环境中运行 Cassandra 集群,但当其他 Instagram 服务迁移到 Facebook 的基础设施上时,我们也迁过去了。对我们来说 Cassandra 的可靠性和可用性体验都很不错,但是在读取延迟上仍有改进空间。
去年,Instagram 的 Cassandra 团队开始致力于一个项目,目标是显著减少 Cassandra 的读取延迟,我们称之为 Rocksandra。在这篇文章中,我将介绍该项目的动机、我们克服的挑战以及在内部环境和公共云环境中的性能指标。
动机
在 Instagram 我们大量使用 Apache Cassandra 作为通用的键值存储服务。大部分 Instagram 的 Cassandra 请求都是实时(Online)的,为了向巨量的 Instagram 用户提供可靠和快速的用户体验,我们对这些指标的 SLA(服务等级协议,Service Level Agreement)非常严格。
Instagram 维护 5-9 秒的可靠性 SLA,这意味着在任何时候,请求失败率应该小于 0.001%。为了提高性能,我们实时监控不同 Cassandra 集群的吞吐量和延迟,尤其是 P99 读取延迟。
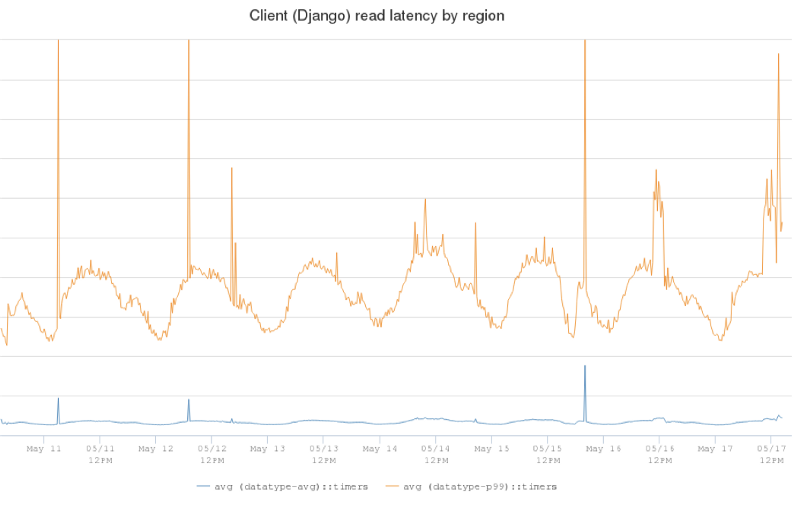
下图展示了生产环境中的一个 Cassandra 集群的客户端延迟。蓝线是平均读取延迟(5ms),橙线是 P99 读取延迟(在 25ms 到 60ms 的范围内,并随着客户端流量变化而变动)。
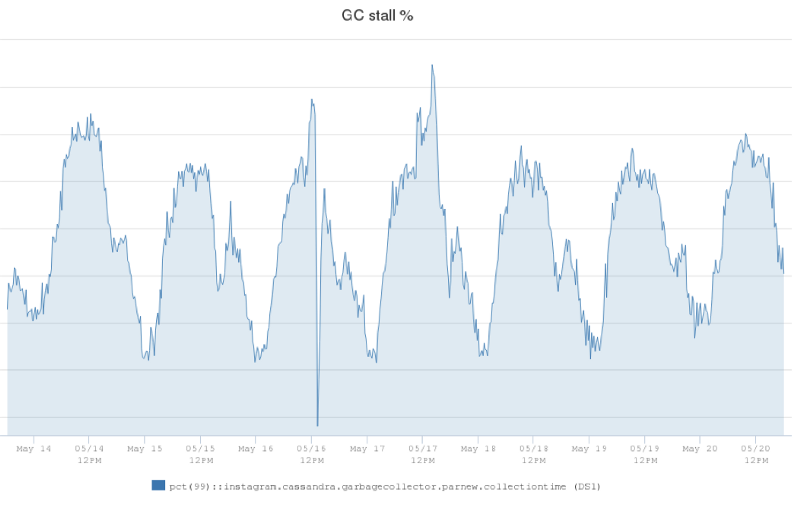
经过调查,我们发现 JVM 垃圾收集器(GC)对延迟峰值作出了很大贡献。我们定义了一个叫做 GC 暂停(GC stall)百分比的度量标准,用于度量 Cassandra 服务器在 stop-the-world GC(新生代 GC)并且无法响应客户端请求时所占时间百分比。这是另一张图,显示了我们生产环境 Cassandra 服务器的 GC 暂停百分比。在流量最小的时间段内,这一比例为 1.25%,在高峰时段可以高达 2.5%。
该图显示 Cassandra 服务器会把 2.5% 的运行时间用于垃圾收集,而不是响应客户端请求。GC 开销显然对我们的 P99 延迟有很大影响,所以如果能够降低 GC 暂停百分比,也就能够显著降低 P99 延迟。
解决方案
Apache Cassandra 是一个分布式数据库,它使用自己以 Java 编写的基于 LSM 树的存储引擎。我们发现存储引擎中的某些组件,例如 memtable、压缩、读/写的代码路径等等,在 Java 堆中创建了很多对象,并给 JVM 增加了很多开销。为了减少存储引擎带来的 GC 问题,我们考虑了不同的方法,最终决定开发一个 C++ 存储引擎来替代现有的引擎。
我们不想从头开始构建新的存储引擎,因此决定在 RocksDB 之上构建新的存储引擎。
RocksDB 是一款开源的高性能嵌入式数据库,用于处理键值数据。它用 C++ 编写,并且提供了 C++、C 和 Java 的官方 API。RocksDB 针对性能进行了优化,尤其是针对 SSD 这样的快速存储设备。它在业界被广泛用作 MySQL、mongoDB 和其他流行数据库的存储引擎。
挑战
在 RocksDB 上构建新的存储引擎时,我们克服了三个主要挑战。
第一个挑战是 Cassandra 的架构不支持可插拔的存储引擎,就是说现有的存储引擎与数据库中的其他组件耦合在一起。为了在大量重构和快速迭代之间找到平衡,我们定义了一个新的存储引擎 API,包括最常见的读/写和流接口。通过这种方式,我们可以在 API 后面构建新的存储引擎,并将其插入到 Cassandra 内部的相关代码路径中。
其次,Cassandra 支持丰富的数据类型和表模式,而 RocksDB 只提供纯粹的键值接口。我们仔细地定义了编码/解码算法,以便在 RocksDB 的数据结构之上支持 Cassandra 的数据模型,并支持与原始 Cassandra 相同的查询语义。
第三个挑战是流接口。流传输是像 Cassandra 这样的分布式数据库的重要组成部分。我们新增或移除 Cassandra 集群中的节点时,Cassandra 需要在不同节点之间传输数据以平衡集群中的负载。现有的流传输实现是基于当前存储引擎中的内部细节的。因此,我们必须将它们分离开,建立一个抽象层,并使用 RocksDB API 重新实现流传输。为了提高流吞吐量,目前我们先将数据写入到 temp sst 文件,然后使用 RocksDB ingest file API 将它们一次性批量加载到 RocksDB 中。
性能指标
经过大约一年的开发和测试,我们已经完成了第一个版本的实现,并成功在 Instagram 内部将其推广部署到多个 Cassandra 集群。在我们的其中一个生产集群中,P99 读取延迟从 60ms 降至 20ms。我们还观察到,该群集上的 GC 暂停从 2.5% 下降到 0.3%,足足减小了 10 倍!
我们还想验证 Rocksandra 在公共云环境中是否会表现良好。我们使用三个 i3.8 xlarge EC2 实例在 AWS 环境中配置 Cassandra 集群,每个实例都有 32 个 CPU 核心,244GB 内存以及 4 个 nvme 闪存磁盘组成的 raid0。
我们使用 NDBench 作为基准测试框架,并使用这个框架中默认的表模式:
TABLE emp (
emp_uname text PRIMARY KEY,
emp_dept text,
emp_first text,
emp_last text`
)
我们预加载了 2.5 亿行每行 6KB 的数据到数据库中(每个服务器在磁盘上存储大约 500GB 数据),并在 NDBench 中配置了 128 个读取端和 128 个写入端。
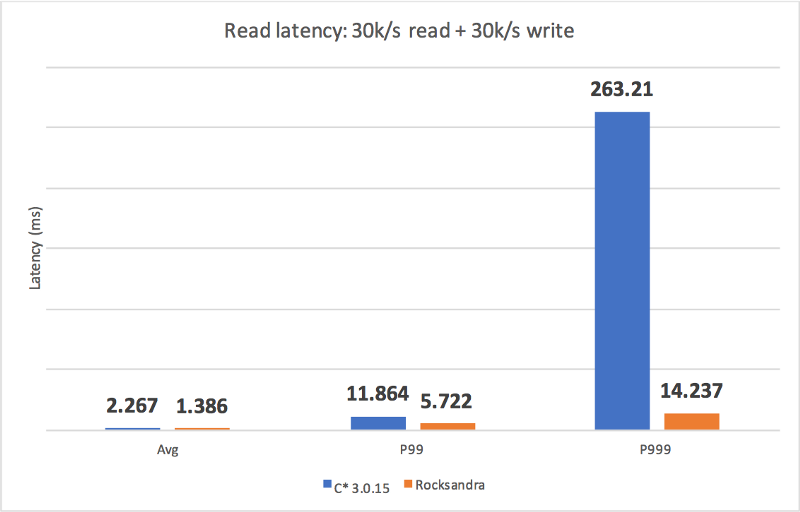
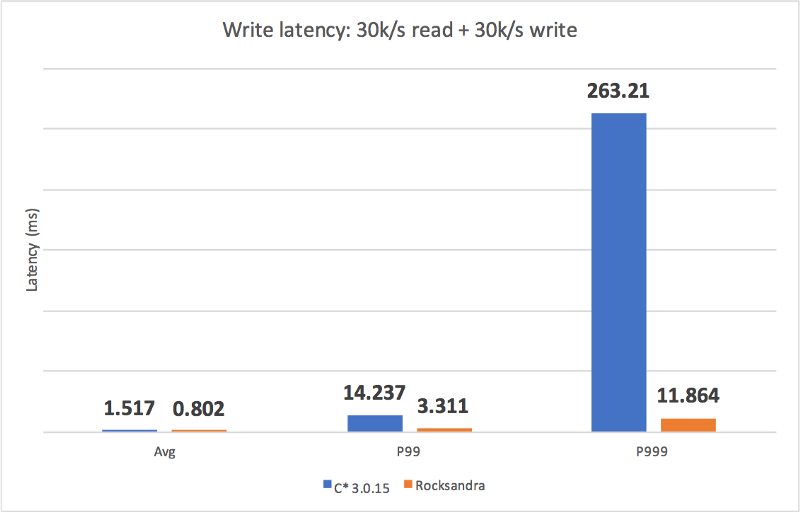
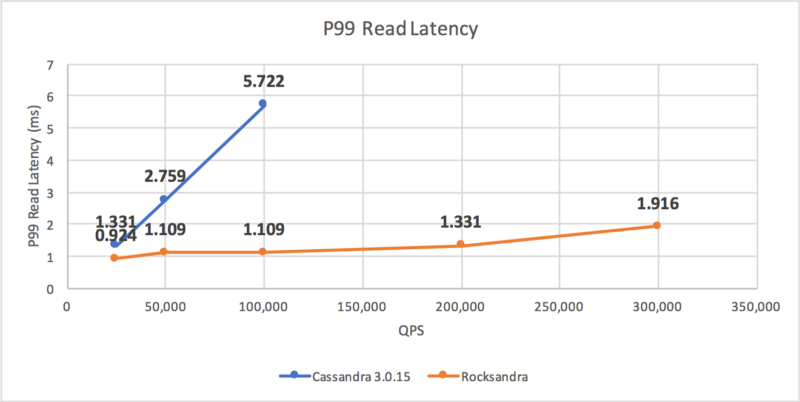
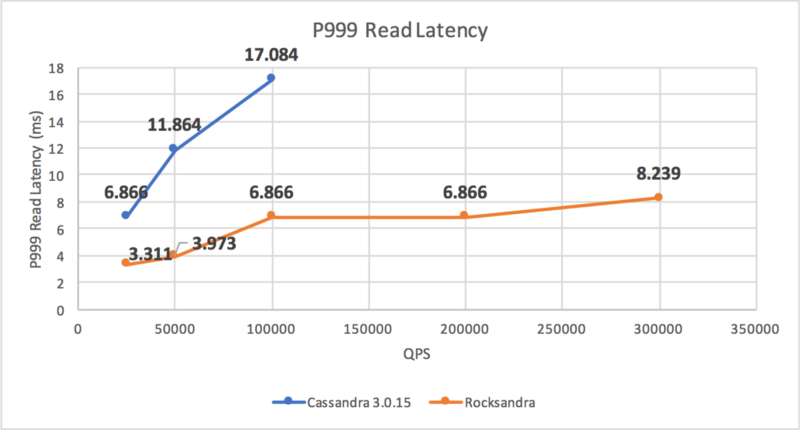
我们测试了不同的负载并测量了平均/P99/P999的读/写延迟。如你所见,Rocksandra 提供了更低且更稳定的尾部读/写延迟。
我们还测试了只读负载,并观察到在相似的 P99 读取延迟(2ms)下,Rocksandra 可以提供 10 倍的读取吞吐量(Rocksandra 为 300K/s,C* 3.0 为 30K/s)。
展望
我们已经开源了 Rocksandra 代码库 和 基准测试框架,你可以从 Github 上下载并在自己的环境中尝试!请让我们知道它的表现。
作为下一步,我们正在积极开发更多的 C* 功能支持,如二级索引,数据修复等等。我们还在开发一个 C* 可插拔存储引擎架构,将我们的工作回馈给 Apache Cassandra 社区。
如果您身处湾区,并有兴趣了解更多关于 Cassandra 开发的信息,请参加我们的下一次 聚会活动。
Dikang Gu 是 Instagram 的一名基础架构工程师
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
