

- 原文地址:Powering PHP With JanusGraph
- 原文作者:Don Omondi
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:GanymedeNil
- 校对者:allenlongbaobao
JanusGraph 为 PHP 助力
随着 JanusGraph 的日益流行,开发者们也毫无疑问地围绕着它开发着相应的工具。在这篇来自 Compose Write Stuff 的文章中,Campus Discounts 的创始人兼首席技术官 Don Omondi 将谈到他为 JanusGraph 开发新的 PHP 库并且分享如何使用它。
在编程语言的世界中,PHP 并不需要过多介绍。它在 1995 年正式对外发布了 1.0 版本。现在 PHP 已经成为许多独角兽公司的中坚力量,而其中最为人知晓的就是 Facebook,最近像 Slack 也加入了 PHP 的阵营。截至 2017 年 9 月,W3Techs 报告称,在所有已知网站中,服务端编程语言使用了 PHP 的占了 82.8% !
在数据库的世界中,JanusGraph 虽是一位新成员,但它却有着深厚的技术底蕴,因为它建立在开源图形数据库的前任领导者 Titan 的基础上。为了提供给您一些关于图数据库的背景知识,请看图数据库简介。虽然 JanusGraph 还很年轻,但是它已经被一个知名的独角兽公司 —— Uber 使用。
所以最大的问题是,如何使用 PHP 和 JanusGraph 创建一家独角兽公司?相信我,我也希望我知道答案!但是,如果问题是如何使用 JanusGraph 来强化 PHP ?我倒是知道不止一种方法。
Gremlin-OGM PHP 库介绍
Gremlin-OGM PHP 库是 Tinkerpop 3+ 兼容的图形数据库(JanusGraph,Neo4j 等)的对象图形映射器,允许您保存数据并运行 gremlin 查询。
该库已经托管在 Packagist 上了 ,所以可以轻松的使用 Composer 安装。
composer require the-don-himself/gremlin-ogm
使用该库也很容易,因为它有大量的 PHP 注释。但是在我们开始使用它之前,让我们深入探讨一下使用像 JanusGraph 这样的图形数据库时可能遇到的一些问题以及该库如何帮助您避免它们。
注意事项
首先,具有相同名称的所有属性必须具有相同的数据类型。如果您已经在不同的数据库中有数据,比如 MySQL 或者 MongoDB ,那么您可能会遇到这种情况。
一个很好的例子就是在每个实体类或文档中称为 id 的字段。一些 ID 可能是一个整数的数据类型(1、2、3 等), 其他一些可能是字符串类型 (例如在常见问题解答库中的 ID en_1、es_1、fr_1),另外还有比如 MongoDB 的 UUID(例子 59be8696540bbb198c0065c4)。对于这些不同的数据类型使用相同属性名称的情况会引发异常。Gremlin-OGM 库会发现这样的冲突并拒绝执行。作为一种解决方法,我建议将标签与单词 id 组合; 例如,用户的标识符变为 users_id 。该库附带一个序列化程序,允许您将字段映射到虚拟属性以避免此冲突。
其次,属性(property)名称,边缘(edge)标签和顶点(vertex)标签在图中必须都是唯一的。例如,将 Vertex 标记为 tweets 并引用一个对象,然后创建一个 Edge 标记为 tweets 并引用用户操作,或者在 users Vertex 中创建一个 property tweets 来引用用户发出的推文数量。该库同样会发现这种冲突并拒绝执行。
第三,对于性能和模式的有效性,我建议确保每个元素,或者至少每个顶点包含一个唯一的属性,在该唯一属性上将创建唯一的组合索引(也称为键索引)。这确保所有元素都是唯一的,并且会提高性能,因为在顶点之间添加边缘首先需要查询它们是否先存在。该库允许您为此目的使用 @Id 注释标记属性。
最后,索引。这一点值得写一本或两本书。在 JanusGraph 中,基本上您索引的是属性(毕竟它是一个属性图),但是可以在不同的顶点和边缘上使用相同的属性名称。这样做时要非常小心。请记住第一件要注意的事情。因此,例如在默认情况下,属性 total_comments 上的索引将跨越所有顶点和边缘。查询其中total_comments 大于 5 的顶点会返回 total_comments > 5 的 users ,total_comments > 5 的博客帖子以及满足该查询的任何其他顶点的混合情况。更糟糕的情况是,一段时间后,如果您在 recipes 顶点了加一个 total_comments 属性,那么你现有的查询就会出错了。
为了防止上述潜在的问题,JanusGraph 允许您在创建索引时设置标签参数以限制其范围。我建议这样做以保持索引更小和更高性能,但这意味着您必须为每个索引提供一个唯一的名称。Gremlin-OGM 库查找任何冲突的索引名称,如果发现将拒绝执行。
如何使用 Gremlin-OGM
要开始使用 Gremlin-OGM ,我们首先需要在我们的源文件夹中创建一个名为 Graph 的目录,例如 src/Graph。在这个目录下,我们需要创建两个不同的目录:一个叫做 Vertices ,另一个叫做 Edges 。这两个目录现在将包含定义我们图表元素的PHP类。
顶点文件夹中的每个类主要使用注释描述顶点标签,关联索引和属性。对于更高级的用例,如果您使用 MongoDB 并拥有一个保存嵌入式文档的类(例如注释集合),则还可以定义最适合的嵌入边缘。
边缘文件夹中的每个类还是通过注释描述边缘标签,相关索引和属性。每个边缘类中的两个属性也可以使用注释进行标记,一个用于描述顶点从哪链接过来的,另一个用于描述顶点要链接去哪。它的使用真的很简单,但我们还是用一个实例来说明吧。
一个实际的例子:推特
Twitter和图形数据库真的是天生一对。像用户和推文这样的对象可以形成顶点,而诸如 follow ,likes ,tweeted 和 retweets 等操作可以形成边缘。请注意,边缘 tweeted 是以这种方式命名的,以避免与顶点 tweets 发生冲突。这个简单的模型的图形表示可以如下图所示。

让我们在 Graph/Vertexes 文件夹和 Graph/Edges 文件夹中创建相应的类。tweets 类可能如下所示:
<?php
namespace TheDonHimself\GremlinOGM\TwitterGraph\Graph\Vertices;
use JMS\Serializer\Annotation as Serializer;
use TheDonHimself\GremlinOGM\Annotation as Graph;
/**
* @Serializer\ExclusionPolicy("all")
* @Graph\Vertex(
* label="tweets",
* indexes={
* @Graph\Index(
* name="byTweetsIdComposite",
* type="Composite",
* unique=true,
* label_constraint=true,
* keys={
* "tweets_id"
* }
* ),
* @Graph\Index(
* name="tweetsMixed",
* type="Mixed",
* label_constraint=true,
* keys={
* "tweets_id" : "DEFAULT",
* "text" : "TEXT",
* "retweet_count" : "DEFAULT",
* "created_at" : "DEFAULT",
* "favorited" : "DEFAULT",
* "retweeted" : "DEFAULT",
* "source" : "STRING"
* }
* )
* }
* )
*/
class Tweets
{
/**
* @Serializer\Type("integer")
* @Serializer\Expose
* @Serializer\Groups({"Default"})
*/
public $id;
/**
* @Serializer\VirtualProperty
* @Serializer\Expose
* @Serializer\Type("integer")
* @Serializer\Groups({"Graph"})
* @Serializer\SerializedName("tweets_id")
* @Graph\Id
* @Graph\PropertyName("tweets_id")
* @Graph\PropertyType("Long")
* @Graph\PropertyCardinality("SINGLE")
*/
public function getVirtualId()
{
return self::getId();
}
/**
* @Serializer\Type("string")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("text")
* @Graph\PropertyType("String")
* @Graph\PropertyCardinality("SINGLE")
*/
public $text;
/**
* @Serializer\Type("integer")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("retweet_count")
* @Graph\PropertyType("Integer")
* @Graph\PropertyCardinality("SINGLE")
*/
public $retweet_count;
/**
* @Serializer\Type("boolean")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("favorited")
* @Graph\PropertyType("Boolean")
* @Graph\PropertyCardinality("SINGLE")
*/
public $favorited;
/**
* @Serializer\Type("boolean")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("retweeted")
* @Graph\PropertyType("Boolean")
* @Graph\PropertyCardinality("SINGLE")
*/
public $retweeted;
/**
* @Serializer\Type("DateTime<'', '', 'D M d H:i:s P Y'>")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("created_at")
* @Graph\PropertyType("Date")
* @Graph\PropertyCardinality("SINGLE")
*/
public $created_at;
/**
* @Serializer\Type("string")
* @Serializer\Expose
* @Serializer\Groups({"Default", "Graph"})
* @Graph\PropertyName("source")
* @Graph\PropertyType("String")
* @Graph\PropertyCardinality("SINGLE")
*/
public $source;
/**
* @Serializer\Type("TheDonHimself\GremlinOGM\TwitterGraph\Graph\Vertices\Users")
* @Serializer\Expose
* @Serializer\Groups({"Default"})
*/
public $user;
/**
* @Serializer\Type("TheDonHimself\GremlinOGM\TwitterGraph\Graph\Vertices\Tweets")
* @Serializer\Expose
* @Serializer\Groups({"Default"})
*/
public $retweeted_status;
/**
* Get id.
*
* @return int
*/
public function getId()
{
return $this->id;
}
}
Twitter API 非常具有表现力,尽管我们实际上可以保存比顶点类允许的多得多的数据。但是,对于这个示例,我们只是对几个属性感兴趣。上述注释将告诉序列化程序仅在将 Twitter API 数据反序列化为顶点类对象时填充这些字段。
为 users 顶点创建一个类似的类。完整的示例代码位于库中的 TwitterGraph 文件夹中。
在 Graph/Edges 文件夹中可以创建一个示例 Follows 边缘类,它看起来像这样:
<?php
namespace TheDonHimself\GremlinOGM\TwitterGraph\Graph\Edges;
use JMS\Serializer\Annotation as Serializer;
use TheDonHimself\GremlinOGM\Annotation as Graph;
/**
* @Serializer\ExclusionPolicy("all")
* @Graph\Edge(
* label="follows",
* multiplicity="MULTI"
* )
*/
class Follows
{
/**
* @Graph\AddEdgeFromVertex(
* targetVertex="users",
* uniquePropertyKey="users_id",
* methodsForKeyValue={"getUserVertex1Id"}
* )
*/
protected $userVertex1Id;
/**
* @Graph\AddEdgeToVertex(
* targetVertex="users",
* uniquePropertyKey="users_id",
* methodsForKeyValue={"getUserVertex2Id"}
* )
*/
protected $userVertex2Id;
public function __construct($user1_vertex_id, $user2_vertex_id)
{
$this->userVertex1Id = $user1_vertex_id;
$this->userVertex2Id = $user2_vertex_id;
}
/**
* Get User 1 Vertex ID.
*
*
* @return int
*/
public function getUserVertex1Id()
{
return $this->userVertex1Id;
}
/**
* Get User 2 Vertex ID.
*
*
* @return int
*/
public function getUserVertex2Id()
{
return $this->userVertex2Id;
}
}
为 likes,tweeted 和 retweets 边缘创建类似的类。完成后,我们可以通过运行以下命令来检查模型的有效性:
php bin/graph twittergraph:schema:check
如果抛出异常,那么我们需要先解决它们;否则,我们的模型已经设置好了,现在我们需要做的就是告诉 JanusGraph 。
JanusGraph 连接
TheDonHimself\GremlinOGM\GraphConnection 类负责初始化图形连接。您可以通过创建一个新的实例并在数组中传递一些连接选项来实现。
$options = [
'host' => 127.0.0.1,
'port' => 8182,
'username' => null,
'password' => null,
'ssl' = [
'ssl_verify_peer' => false,
'ssl_verify_peer_name' => false
],
'graph' => 'graph',
'timeout' => 10,
'emptySet' => true,
'retryAttempts' => 3,
'vendor' = [
'name' => _self',
'database' => 'janusgraph',
'version' => '0.2'
],
'twitter' => [
'consumer_key' => 'LnUQzlkWlNT4oNUh7a2rwFtwe',
'consumer_secret' => 'WCIu0YhaOUBPq11lj8psxZYobCjXpYXHxXA6rVcqbuNDYXEoP0',
'access_token' => '622225192-upvfXMpeb9a3FMhuid6oBiCRsiAokpNFgbVeeRxl',
'access_token_secret' => '9M5MnJOns2AFeZbdTeSk3R81ZVjltJCXKtxUav1MgsN7Z'
]
];
vendor 数组可以指定 vendor-specific 信息,如 gremlin 兼容的数据库、版本、服务主机名称(或 _self 本机)以及图的名称。
最终创建模型,我们将运行此命令。
php bin/graph twittergraph:schema:create
这个命令将要求一个可选的 configPath 参数,该参数是建立连接时包含 options 数组的 yaml 配置文件的位置。该库在根文件夹中有三个示例配置,janusgraph.yaml,janusgraphcompose.yaml 和 azure-cosmosdb.yaml。
上述命令将递归遍历我们的 TwitterGraph/Graph 目录并查找所有 @Graph 注释来构建模型定义。如果发现异常将被抛出;否则,它将启动一个 Graph 事务来一次提交所有属性、边缘和顶点,或者在失败时回滚。
同样的命令也会询问您是否要执行 dry run。如果指定,则不会将命令发送到 gremlin 服务器,而是将其转储到您可以检查的 command.groovy 文件中。对于Twitter示例,这 26 行是根据您的配置发送或转储的命令(如janusgraph _self 本机)。
mgmt = graph.openManagement()
text = mgmt.makePropertyKey('text').dataType(String.class).cardinality(Cardinality.SINGLE).make()
retweet_count = mgmt.makePropertyKey('retweet_count').dataType(Integer.class).cardinality(Cardinality.SINGLE).make()
retweeted = mgmt.makePropertyKey('retweeted').dataType(Boolean.class).cardinality(Cardinality.SINGLE).make()
created_at = mgmt.makePropertyKey('created_at').dataType(Date.class).cardinality(Cardinality.SINGLE).make()
source = mgmt.makePropertyKey('source').dataType(String.class).cardinality(Cardinality.SINGLE).make()
tweets_id = mgmt.makePropertyKey('tweets_id').dataType(Long.class).cardinality(Cardinality.SINGLE).make()
name = mgmt.makePropertyKey('name').dataType(String.class).cardinality(Cardinality.SINGLE).make()
screen_name = mgmt.makePropertyKey('screen_name').dataType(String.class).cardinality(Cardinality.SINGLE).make()
description = mgmt.makePropertyKey('description').dataType(String.class).cardinality(Cardinality.SINGLE).make()
followers_count = mgmt.makePropertyKey('followers_count').dataType(Integer.class).cardinality(Cardinality.SINGLE).make()
verified = mgmt.makePropertyKey('verified').dataType(Boolean.class).cardinality(Cardinality.SINGLE).make()
lang = mgmt.makePropertyKey('lang').dataType(String.class).cardinality(Cardinality.SINGLE).make()
users_id = mgmt.makePropertyKey('users_id').dataType(Long.class).cardinality(Cardinality.SINGLE).make()
tweets = mgmt.makeVertexLabel('tweets').make()
users = mgmt.makeVertexLabel('users').make()
follows = mgmt.makeEdgeLabel('follows').multiplicity(MULTI).make()
likes = mgmt.makeEdgeLabel('likes').multiplicity(MULTI).make()
retweets = mgmt.makeEdgeLabel('retweets').multiplicity(MULTI).make()
tweeted = mgmt.makeEdgeLabel('tweeted').multiplicity(ONE2MANY).make()
mgmt.buildIndex('byTweetsIdComposite', Vertex.class).addKey(tweets_id).unique().indexOnly(tweets).buildCompositeIndex()
mgmt.buildIndex('tweetsMixed',Vertex.class).addKey(tweets_id).addKey(text,Mapping.TEXT.asParameter()).addKey(retweet_count).addKey(created_at).addKey(retweeted).addKey(source,Mapping.STRING.asParameter()).indexOnly(tweets).buildMixedIndex("search")
mgmt.buildIndex('byUsersIdComposite',Vertex.class).addKey(users_id).unique().indexOnly(users).buildCompositeIndex()
mgmt.buildIndex('byScreenNameComposite',Vertex.class).addKey(screen_name).unique().indexOnly(users).buildCompositeIndex()
mgmt.buildIndex('usersMixed',Vertex.class).addKey(users_id).addKey(name,Mapping.TEXTSTRING.asParameter()).addKey(screen_name,Mapping.STRING.asParameter()).addKey(description,Mapping.TEXT.asParameter()).addKey(followers_count).addKey(created_at).addKey(verified).addKey(lang,Mapping.STRING.asParameter()).indexOnly(users).buildMixedIndex("search")
mgmt.commit()
现在我们有了一个有效的模型设置,我们需要的只是数据。Twitter API 有很好的文档关于如何请求这些数据。Gremlin-OGM 库附带了一个 twitteroauth 包 (abraham/twitteroauth) 以及一个准备好的只读 Twitter 应用程序,用于测试该库并帮助您开始使用。
从 API 中获取数据后,保持顶点非常简单。首先,将 JSON 反序列化为相应的顶点类对象。因此,例如,@TwitterDev 通过取回的 Twitter 数据 /api/users/show 将被反序列化,如图所示 var_dump() 。
object(TheDonHimself\GremlinOGM\TwitterGraph\Graph\Vertices\Users)#432 (8) {
["id"]=>
int(2244994945)
["name"]=>
string(10) "TwitterDev"
["screen_name"]=>
string(10) "TwitterDev"
["description"]=>
string(136) "Developer and Platform Relations @Twitter. We are developer advocates. We can't answer
all your questions, but we listen to all of them!"
["followers_count"]=>
int(429831)
["created_at"]=>
object(DateTime)#445 (3) {
["date"]=>
string(26) "2013-12-14 04:35:55.000000"
["timezone_type"]=>
int(1)
["timezone"]=>
string(6) "+00:00"
}
["verified"]=>
bool(true)
["lang"]=>
string(2) "en"
}
序列化的 PHP 对象现在已经开始在各自的顶点和边缘中形成。但是,我们只能将 gremlin 命令作为字符串发送,所以我们仍然需要将对象序列化为命令字符串。我们将使用一个方便命名的类GraphSerializer 来执行此操作。将反序列化的对象传递给GraphSerializer 的一个实例,该实例将处理复杂的序列化,如剥离新行,添加斜杠,将PHP DateTime 转换为 JanusGraph 所期望的格式。GraphSerializer 也优雅地处理 Geopoint 和 Geoshape 序列化。
// Get Default Serializer
$serializer = SerializerBuilder::create()->build();
// Get Twitter User
$decoded_user = $connection->get(
'users/show',
array(
'screen_name' => $twitter_handle,
'include_entities' => false,
)
);
if (404 == $connection->getLastHttpCode()) {
$output->writeln('Twitter User @'.$twitter_handle.' Does Not Exist');
return;
}
// Use default serializer to convert array from Twitter API to Users Class Object handling complex
deserialization like Date Time
$user = $serializer->fromArray($decoded_user, Users::class);
// Initiate Special Graph Serializer
$graph_serializer = new GraphSerializer();
// Use graph serializer to convert Users Class Object to array handling complex deserialization like
Geoshape
$user_array = $graph_serializer->toArray($user);
// Use graph serializer to convert array to a gremlin command string ready to be sent over
$command = $graph_serializer->toVertex($user_array);
GraphSerializer 输出将串入 Gremlin 的命令。这个字符串就准备好发送到 JanusGraph 服务器。所以在上面的例子中,它变成:
"g.addV(label, 'users', 'users_id', 2244994945, 'name', 'TwitterDev', 'screen_name', 'TwitterDev', 'description', 'Developer and Platform Relations @Twitter. We are developer advocates. We can\'t answer all your questions, but we listen to all of them!', 'followers_count', 429831, 'created_at', 1386995755000, 'verified', true, 'lang', 'en')"
保存边缘要稍微简单一点,因为它的前提是定点存在。因此,库需要知道属性键值对来查找它们。此外,边缘在图数据库中具有方向和多重性。因此,边缘要添加到顶点这非常重要。
这是 Edge 类中 @Graph\AddEdgeFromVertex 和 @Graph\AddEdgeToVertex 属性注释的用途。它们都扩展了 @Graph\AddEdge 注解来指示目标顶点类以及属性键和获取该值所需的方法数组。
假设我们已经在 Twitter API 中查询到了 tweets ,其中包含一个名为 user 的嵌入字段,用于保存 tweeter 数据。如果 users_id:5 创建了 tweets_id:7 ,则序列化的 gremlin 命令将如下所示:
if (g.V().hasLabel('users').has('users_id',5).hasNext() == true
&& g.V().hasLabel('tweets').has('tweets_id',7).hasNext() == true)
{
g.V().hasLabel('users').has('users_id',5).next().addEdge('tweeted',
g.V().hasLabel('tweets').has('tweets_id',7).next())
}
因此,两个顶点查询是一个事务,然后在users 与 tweets 之间创建两条边缘。请注意,因为一个用户可以多次发 tweet ,但每个 tweet 只能有一个拥有者,所以其重复性为 ONE2MANY。
如果边缘类具有像 tweeted_on 或 tweeted_from 这样的属性,那么库就会像顶点一样适当地序列化它们。
JanusGraph 查询
我们处理了抓取和保存的数据。数据查询也是库帮助完成的。TheDonHimself\Traversal\TraversalBuilder 类提供了几乎与 gremlin 完美匹配的本地API。例如,在 TwitterGraph 中获取用户可以实现如下。
$user_id = 12345;
$traversalBuilder = new TraversalBuilder();
$command = $traversalBuilder
->g()
->V()
->hasLabel("'users'")
->has("'users_id'", "$user_id")
->getTraversal();
获取用户时间线这样稍微复杂的例子可以通过以下方式实现。
$command = $traversalBuilder
->g()
->V()
->hasLabel("'users'")
->has("'screen_name'", "'$screen_name'")
->union(
(new TraversalBuilder())->out("'tweeted'")->getTraversal(),
(new TraversalBuilder())->out("'follows'")->out("'tweeted'")->getTraversal()
)
->order()
->by("'created_at'", 'decr')
->limit(10)
->getTraversal();
详细步骤可以在 \TheDonHimself\Traversal\Step 类中找到.
GraphQL 到 Gremlin
有一个独立的尝试 来创建一种支持 GraphQL to Gremlin 命令的标准。它处于早期阶段,只支持查询而不支持变更。既然它也是我写的,Gremlin-OGM 库当然也支持这个标准,希望随着时间的推移会有所改进。
JanusGraph 可视化
可悲的是,它没有像关系数据库,文档数据库和键值数据库那样多的 Graph Database GUI。其中Gephi,可用于通过流式插件来可视化 JanusGraph 数据和查询。与此同时,撰写有 JanusGraph 的数据浏览器,可以使用它来显示 TwitterGraph 的一些查询。
将我关注的 5 位用户可视化
def graph = ConfiguredGraphFactory.open("twitter");
def g = graph.traversal();
g.V().hasLabel('users').has('screen_name',
textRegex('(i)the_don_himself')).outE('follows').limit(5).inV().path()
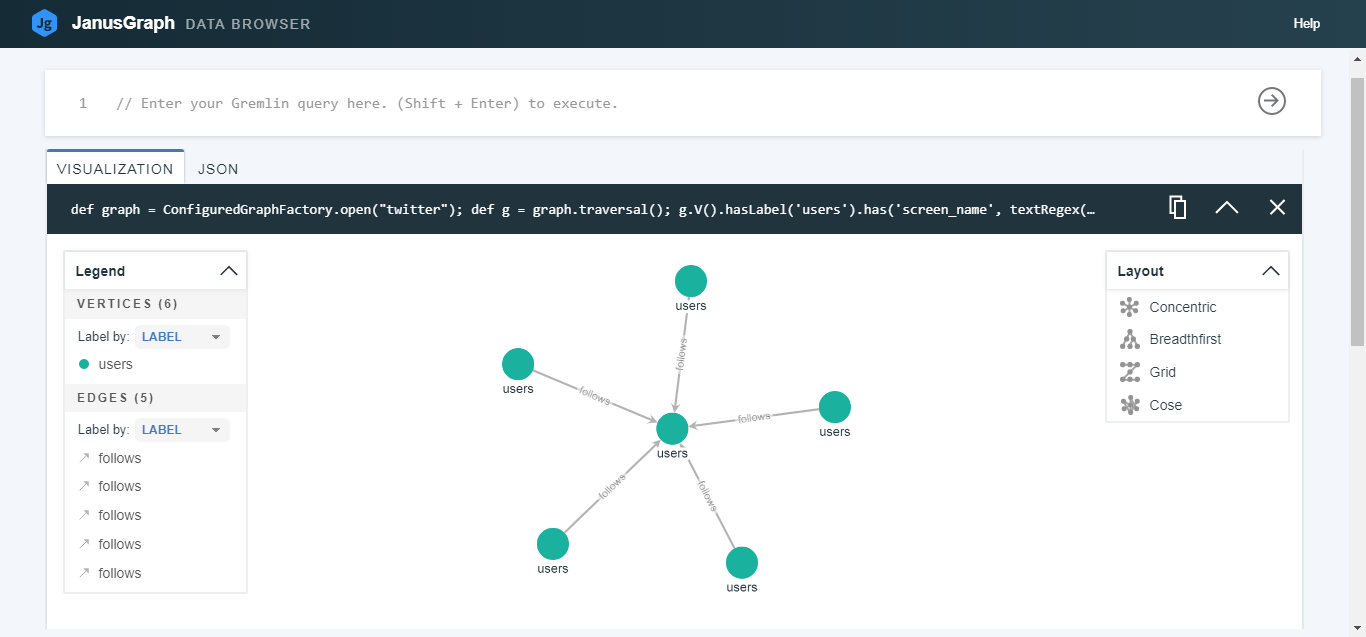
可视化 5 位关注我的用户
def graph = ConfiguredGraphFactory.open("twitter");
def g = graph.traversal();
g.V().hasLabel('users').has('screen_name',
textRegex('(i)the_don_himself')).inE('follows').limit(5).outV().path()
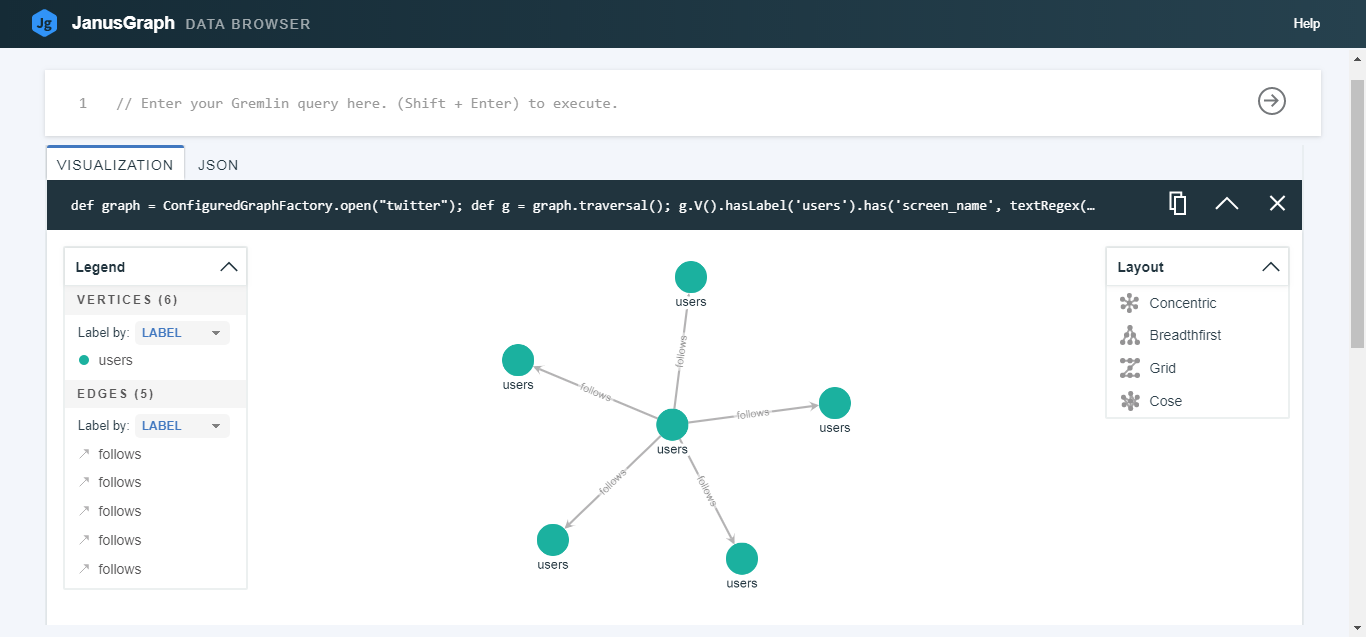
可视化我喜欢的 5 条推文
def graph = ConfiguredGraphFactory.open("twitter");
def g = graph.traversal();
g.V().hasLabel('users').has('screen_name',
textRegex('(?i)the_don_himself')).outE('likes').limit(5).inV().path()
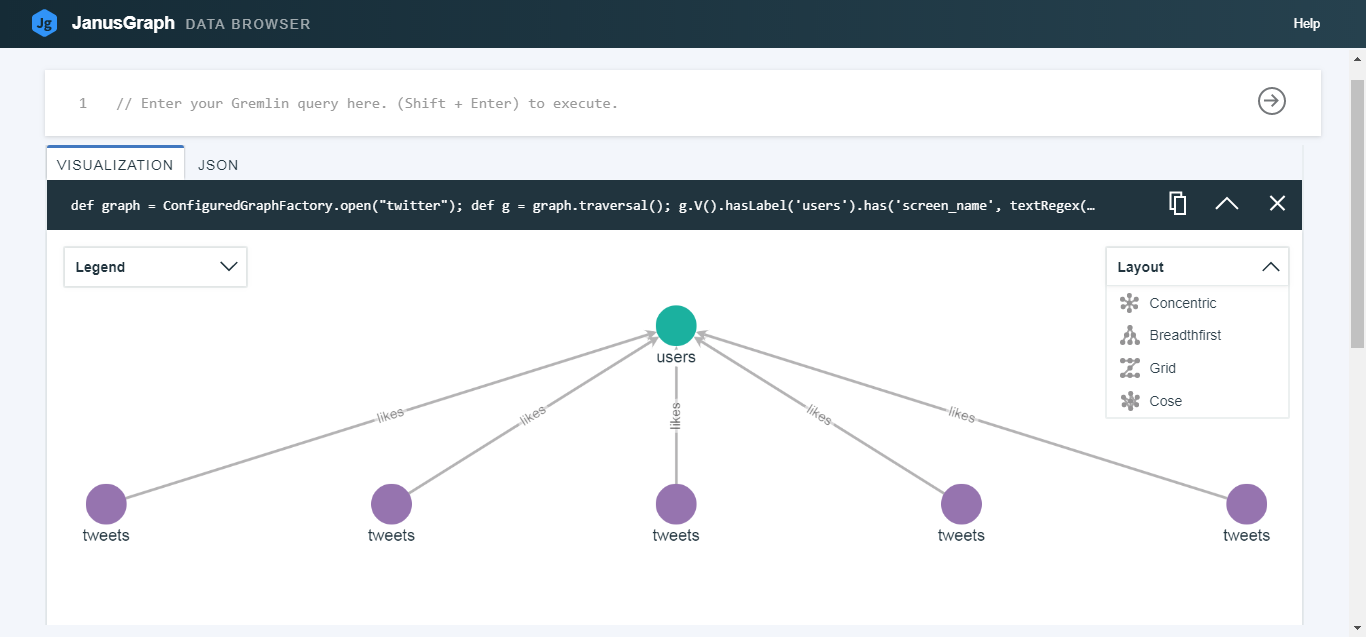
可视化任意 5 条转推以及原推
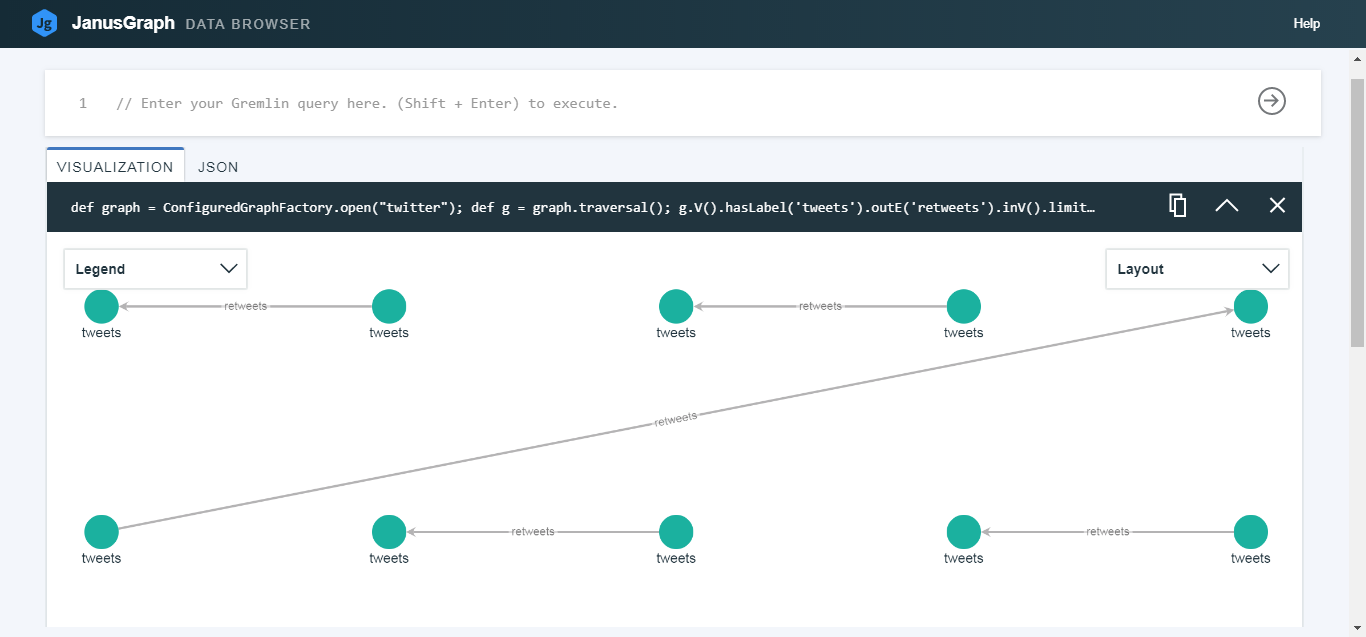
def graph = ConfiguredGraphFactory.open("twitter");
def g = graph.traversal();
g.V().hasLabel('tweets').outE('retweets').inV().limit(5).path()
现在您拥有了它。一个功能强大、考虑周到、操作简单的库,它可帮助您在几分钟内开始使用 PHP 操作 JanusGraph 。如果您使用了令人惊叹的 Symfony 框架,那么您的运气会更好。即将发行的软件包 Gremlin-OGM-Bundle 将帮助您将数据从 RDBMS 或 MongoDB 复制到 Tinkerpop 3+ 兼容图形数据库中。请享用!
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
