

Java List 容器源码分析的补充
之前我们通过分析源码的方式学习了 ArrayList 以及 LinkedList 的使用方法。但是在分析源码之余,总免不了去网上查找一些相关资料,站在前人的肩膀上,发现前两篇文章多多少少有些遗漏的地方,比如跟 ArrayList 很相似的 Vector 还没有提及过,所以本文想从面试中对于 List 相关问题出发,来填一填之前的坑,并对 List 家族中的实现类成员的异同点试着做出总结。
- Vector 介绍及与 ArrayList 的区别
- ArrayList 与 LinkedList 的区别
- Stack 类的介绍及实现一个简单的 Stack
- SynchronizedList 与 Vector的区别
Vector 介绍
Vector 是一个相当古老的 Java 容器类,始于 JDK 1.0,并在 JDK 1.2 时代对其进行修改,使其实现了 List 和 Collection 。从作用上来看,Vector 和 ArrayList 很相似,都是内部维护了一个可以动态变换长度的数组。但是他们的扩容机制却不相同。对于 Vector 的源码大部分都和 ArrayList 差不多,这里简单看下 Vector 的构造函数,以及 Vector 的扩容机制。
Vector 的构造函数可以指定内部数组的初始容量和扩容系数,如果不指定初始容量默认初始容量为 10,但是不同于 ArrayList 的是它在创建的时候就分配了容量为10的内存空间,而 ArrayList 则是在第一次调用 add 的时候才生成一个容量为 10 数组。
public Vector() {
this(10);//创建一个容量为 10 的数组。
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
// 此方法在 JDK 1.2 后添加
public Vector(Collection<? extends E> c) {
elementData = c.toArray();//创建与参数集合长度相同的数组
elementCount = elementData.length;
// c.toArray might (incorrectly) not return Object[] (see 6260652)
if (elementData.getClass() != Object[].class)
elementData = Arrays.copyOf(elementData, elementCount, Object[].class);
}
对于 Vector的扩容机制,我们只需要看下内部的 grow 方法源码:
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 如果我们没有指定扩容系数,那么 newCapacity = 2 * oldCapacity
// 如果我们指定了扩容系数,那么每次增加指定的容量
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
由上边的方法结合我们的构造函数,我们便可知道 Vector 的需要扩容的时候,首先会判断 capacityIncrement 即在构造的 Vector 的时候时候指定了扩容系数,如果指定了则按照指定的系数来扩大容量,扩大后新的容量为 oldCapacity + capacityIncrement,如果没有指定capacityIncrement的大小,则默认扩大原来容量的一倍,这点不同于 ArrayList 的 0.5 倍长度。
对于 Vector 与 ArrayList 的区别最重要的一点是 Vector所有的访问内部数组的方法都带有synchronized ,这意味着 Vector 是线程安全的,而ArrayList 并没有这样的特性。
对于 Vector 而言,除了 for 循环,高级 for 循环,迭代的迭代方法外,还可以调用 elements() 返回一个 Enumeration 。
Enumeration 是一个接口,其内部只有两个方法hasMoreElements 和 nextElement,看上去和迭代器很相似,但是并没迭代器的 add remove,只能作用于遍历。
public interface Enumeration<E> {
boolean hasMoreElements();
E nextElement();
}
// Vector 的 elements 方法。
public Enumeration<E> elements() {
return new Enumeration<E>() {
int count = 0;
public boolean hasMoreElements() {
return count < elementCount;
}
public E nextElement() {
synchronized (Vector.this) {
if (count < elementCount) {
return elementData(count++);
}
}
throw new NoSuchElementException("Vector Enumeration");
}
};
}
使用方法:
Vector<String> vector = new Vector<>();
vector.add("1");
vector.add("2");
vector.add("3");
Enumeration<String> elements = vector.elements();
while (elements.hasMoreElements()){
System.out.print(elements.nextElement() + " ");
}
事实上,这个接口也是很古老的一个接口,JDK 为了适配老版本,我们可以调用类似 Enumeration<String> enumeration = Collections.enumeration(list); 来返回一个Enumeration 。其原理就是调用对应的迭代器的方法。
// Collections.enumeration 方法
public static <T> Enumeration<T> enumeration(final Collection<T> c) {
return new Enumeration<T>() {
// 构造对应的集合的迭代器
private final Iterator<T> i = c.iterator();
// 调用迭代器的 hasNext
public boolean hasMoreElements() {
return i.hasNext();
}
// 调用迭代器的 next
public T nextElement() {
return i.next();
}
};
}
Vector 与 ArrayList 的比较
Vector与ArrayList底层都是数组数据结构,都维护着一个动态长度的数组。Vector对扩容机制在没有通过构造指定扩大系数的时候,默认增长现有数组长度的一倍。而ArrayList则是扩大现有数组长度的一半长度。Vector是线程安全的, 而ArrayList不是线程安全的,在不涉及多线程操作的时候ArrayList要比Vector效率高- 对于
Vector而言,除了 for 循环,高级 for 循环,迭代器的迭代方法外,还可以调用elements()返回一个Enumeration来遍历内部元素。
ArrayList 与 LinkedList 的区别
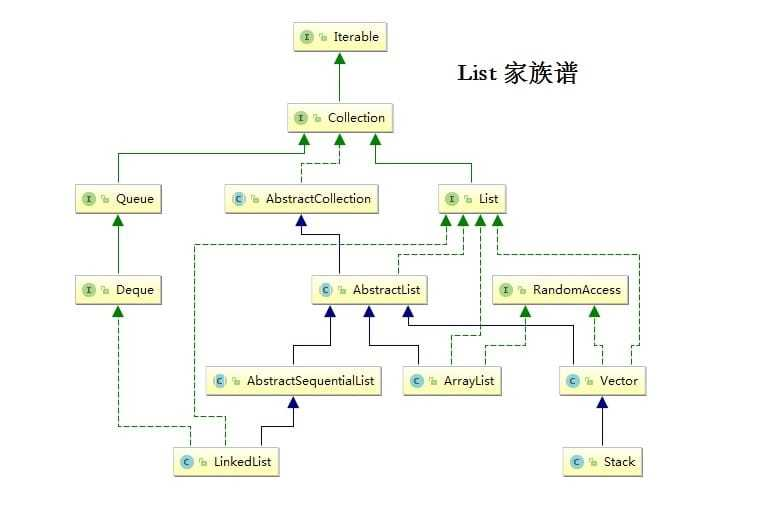
我们先回过头来看下,这两个 List 的继承体系有什么不同:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable
可以看出 LinkedList 没有实现 RandomAccess 接口,我们知道RandomAccess 是一个空的标记接口,标志着实现类具有随机快速访问的特点。那么我们有必要重新认识下这个接口,根据 RandomAccess 的 Java API 说明:
公共接口 RandomAccess 标记接口用于List实现,以表明它们支持快速(通常是恒定时间)的随机访问。该接口的主要目的是允许通用算法改变其行为,以便在应用于随机或顺序访问列表时提供良好的性能。
我们可以意识到,随机访问和顺序访问之间的区别往往是模糊的。例如,如果列表很大时,某些 List 实现提供渐进的访问时间,但实际上是固定的访问时间,这样的 List 实现通常应该实现这个接口。作为一个经验法则, 如果对于典型的类实例,List实现应该实现这个接口:
for(int i = 0,n = list.size(); i <n; i ++)
list.get(ⅰ);
比这个循环运行得更快:
for(Iterator i = list.iterator(); i.hasNext();)
i.next();
上述 API 说有一个经验法则,如果 for 遍历某个 List 实现类的时候要比迭代器遍历运行的快,就需要实现 RandomAccess 随机快速访问接口,标识这个容器支持随机快速访问。通过这个理论我们可以猜测,LinkedList 不具有随机快速访问的特性,换句话说LinkedList 的 for 循环遍历要比 迭代器遍历慢。下面我们来测试一下:
private static void loopList(List<Integer> list) {
long startTime = System.currentTimeMillis();
for (int i = 0; i < list.size(); i++) {
list.get(i);
}
System.out.println(list.getClass().getSimpleName() + "使用普通for循环遍历时间为" +
(System.currentTimeMillis() - startTime) + "ms");
startTime = System.currentTimeMillis();
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
iterator.next();
}
System.out.println(list.getClass().getSimpleName() + "使用iterator 循环遍历时间为" +
(System.currentTimeMillis() - startTime) + "ms");
}
public static void main(String[] args){
//测试 10000个整数的访问速度
List<Integer> arrayList = new ArrayList<Integer>(10000);
List<Integer> linkedList = new LinkedList<Integer>();
for (int i = 0; i < 10000; i++){
arrayList.add(i);
linkedList.add(i);
}
loopList(arrayList);
loopList(linkedList);
System.out.println();
}
我们来看下输出结果:
ArrayList使用普通for循环遍历时间为6ms
ArrayList使用iterator 循环遍历时间为4ms
LinkedList使用普通for循环遍历时间为133ms
LinkedList使用iterator 循环遍历时间为2ms
可以看出 LinkedList 的 for循环的确耗费时间很长,其实这并不难理解,结合上一篇我们分析 LinkedList 的源码的时候,看到的 get(int index)方法 :
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
node 方法内部根据 index 和 size/2 的大小作比较,来区分是从双链表的头节点开始寻找 index 位置的节点还是从尾部开始寻找,内部仍是 for 循环,而基于数组数据结构的 ArrayList 则不同了,在数组创建的时候,就可以很方便的通过索引去获取指定位置的元素了。所以 ArrayList 具有随机快速访问能力,而LinkedList没有。所以我们在使用 LinkedList 应尽量避免使用 for 循环去遍历。
至此我们可以对 LinkedList 和 ArrayList 的区别做出总结:
-
ArrayList是底层采用数组结构,存储空间是连续的。查询快,增删需要进行数组元素拷贝过程,当删除元素位置比较靠前的时候性能较低。 -
LinkedList底层是采用双向链表数据结构,每个节点都包含自己的前一个节点和后一个节点的信息,存储空间可以不是连续的。增删块,查询慢。 -
ArrayList和LinkedList都是线程不安全的。而Vector是线程安全的 -
尽量不要使用 for 循环去遍历一个
LinkedList集合,而是用迭代器或者高级 for。
Stack 介绍
由开始的继承体系可以知道 Stack 继承自 Vector,也就是 Stack 拥有 Vector 所有的增删改查方法。但是我们一说 Stack 肯定就是指栈这中数据接口。
我们先来看下栈的定义:
栈(stack)又名堆栈,它是一种运算受限的线性表。其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
简单来说,栈这种数据结构有一个约定,就是向栈中添加元素和从栈中取出元素只允许在栈顶进行,而且先入栈的元素总是后取出。 我们可以用数组和链表来实现栈的这种数据结构的操作。
一般来说对于栈有一下几种操作:
- push 入栈
- pop 出栈
- peek 查询栈顶
- empty 栈是否为空
Java 中的 Stack 容器是以数组为底层结构来实现栈的操作的,通过调用 Vector 对应的添加删除方法来实现入栈出站操作。
// 入栈
public E push(E item) {
addElement(item);//调用 Vector 定义的 addElement 方法
return item;
}
// 出栈
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);//调用 Vector 定义的 removeElementAt 数组末尾的元素的方法
return obj;
}
// 查询栈顶元素
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);//查询数组最后一个元素。
}
上边简单介绍了 Java 容器中的 Stack 实现,但是事实上官方并不推荐在使用这些陈旧的集合容器类。对于栈从数据结构上而言,相对于线性表,其实现也存在,顺序存储(数组),非连续存储(链表)的实现方法。而我们上一篇文章最后看到的 LinkedList 是可以取代 Stack来进行栈操作的。
最近在一个技术群里,有一位美团大佬说他面试了一个位 Android 开发者,考察了一下这个 Android 开发者对于栈的理解,考察的题目是自己实现一个简单栈,这个栈包含基本的peek ,push,pop 操作,结果不知道为何那个面试的人没有写出来,最终被 pass 掉了。所以在分析完 Stack 后,我决定自己手动尝试写一下这个面试题。我觉得我是面试官,如果回答者只写出了出栈入栈的操作方法应该算是不及格的,面试官关注的应该是在写 push 操作的时候有没有考虑过 StackOverFlow 也就是栈满的情况。
public class SimpleStack<E> {
//默认容量
private static final int DEFAULT_CAPACITY = 10;
//栈中存放元素的数组
private Object[] elements;
//栈中元素的个数
private int size = 0;
//栈顶指针
private int top;
public SimpleStack() {
this(DEFAULT_CAPACITY);
}
public SimpleStack(int initialCapacity) {
elements = new Object[initialCapacity];
top = -1;
}
public boolean isEmpty() {
return size == 0;
}
public int size() {
return size;
}
@SuppressWarnings("unchecked")
public E pop() throws Exception {
if (isEmpty()) {
throw new EmptyStackException();
}
E element = (E) elements[top];
elements[top--] = null;
size--;
return element;
}
@SuppressWarnings("unchecked")
public E peek() throws Exception {
if (isEmpty()) {
throw new Exception("当前栈为空");
}
return (E) elements[top];
}
public void push(E element) throws Exception {
//添加之前确保容量是否满足条件
ensureCapacity(size + 1);
elements[size++] = element;
top++;
}
private void ensureCapacity(int minSize) {
if (minSize - elements.length > 0) {
grow();
}
}
private void grow() {
int oldLength = elements.length;
// 更新容量操作 扩充为原来的1.5倍 这里也可以选择其他方案
int newLength = oldLength + (oldLength >> 1);
elements = Arrays.copyOf(elements, newLength);
}
}
同步 vs 非同步
对于 Vector 和 Stack 从源码上他们在对应的增删改查方法上都使用
synchronized关键字修饰了方法,这也就代表这个方法是同步方法,线程安全的。而 ArrayList 和 LinkedList 并不是线程安全的。不过我们在介绍 ArrayList 和 LinkedList 的时候提及到了我们可以使用Collections 的静态方法,将一个 List 转化为线程同步的 List:
List<Integer> synchronizedArrayList = Collections.synchronizedList(arrayList);
List<Integer> synchronizedLinkedList = Collections.synchronizedList(linkedList);
那么这里又有一道面试题是这样问的:
请简述一下
Vector和SynchronizedList区别,
SynchronizedList 即Collections.synchronizedList(arrayList); 后生成的List 类型,它本身是 Collections 一个内部类。
我们来看下他的源码:
static class SynchronizedList<E>
extends SynchronizedCollection<E>
implements List<E> {
private static final long serialVersionUID = -7754090372962971524L;
final List<E> list;
SynchronizedList(List<E> list) {
super(list);
this.list = list;
}
SynchronizedList(List<E> list, Object mutex) {
super(list, mutex);
this.list = list;
}
.....
}
对于 SynchronizedList 构造可以看到有一个 Object 的参数,但是看到 mutex 这个单词应该就明白了这个参数的含义了,就是同步锁,其实我们点击 super 方法可以看到,单个参数的构造函数锁就是其对象自身。
SynchronizedCollection(Collection<E> c) {
this.c = Objects.requireNonNull(c);
mutex = this;
}
SynchronizedCollection(Collection<E> c, Object mutex) {
this.c = Objects.requireNonNull(c);
this.mutex = Objects.requireNonNull(mutex);
}
接下来我们看看增删改查方法吧:
public E get(int index) {
synchronized (mutex) {return list.get(index);}
}
public E set(int index, E element) {
synchronized (mutex) {return list.set(index, element);}
}
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
public E remove(int index) {
synchronized (mutex) {return list.remove(index);}
}
public int indexOf(Object o) {
synchronized (mutex) {return list.indexOf(o);}
}
public int lastIndexOf(Object o) {
synchronized (mutex) {return list.lastIndexOf(o);}
}
public boolean addAll(int index, Collection<? extends E> c) {
synchronized (mutex) {return list.addAll(index, c);}
}
//注意这里没加 synchronized(mutex)
public ListIterator<E> listIterator() {
return list.listIterator(); // Must be manually synched by user
}
public ListIterator<E> listIterator(int index) {
return list.listIterator(index); // Must be manually synched by user
}
可以很清楚的看到,让一个集合变成线程安全的,Collocations 只是包装了参数集合的增删改查方法,加了同步的限制。与 Vector 相比可以看出来,两者第一个区别在于是同步方法还是同步代码块,对于这两个区别如下:
- 同步代码块在锁定的范围上可能比同步方法要小,一般来说锁的范围大小和性能是成反比的。
- 同步块可以更加精确的控制锁的作用域(锁的作用域就是从锁被获取到其被释放的时间),同步方法的锁的作用域就是整个方法。
由上述两个方法看出来,``Collections.synchronizedList(arrayList);生成的同步集合看起来更高效一些,其实这种差异在 Vector 和 ArrayList上体现的很不明显,因为其 add 方法内部实现大致相同。而从构造参数上来看Vector不能像SynchronizedList` 一样指定加锁对象。
而我们也看到了 SynchronizedList 并没有给迭代器进行加锁,但是翻看 Vector 的迭代器方法确实枷锁的,所以我们在使用SynchronizedList的的迭代器的时候需要手动做同步处理:
synchronized (list) {
Iterator i = list.iterator(); // Must be in synchronized block
while (i.hasNext())
foo(i.next());
}
至此我们可以总结出 SynchronizedList与 Vector的三点差异:
SynchronizedList作为一个包装类,有很好的扩展和兼容功能。可以将所有的List的子类转成线程安全的类。- 使用
SynchronizedList的获取迭代器,进行遍历时要手动进行同步处理,而Vector不需要。 SynchronizedList可以通过参数指定锁定的对象,而Vector只能是对象本身。
总结
本文是继 ArrayList 和 LinkedList 源码分析完成后,针对List 这个家族进行的补充。我们分析了
Vector和ArrayList的区别。ArrayList和LinkedList的区别,引出了RandomAccess这个接口的定义,论证了LinkedList使用 for 循环遍历是低效的。Stack继承自Vector,操作也是线程安全的,但是同样比较老旧。而后分析了实现一个简单的Stack类的面试题。- 最后我们从线程安全方面总结了
SynchronizedList与Vector的三点差异。
这些知识貌似都是面试官爱问的问题,也是平时工作中容易忽略的问题。通过这篇文章做出相应总结,以备不时之需。
