

- 原文地址:Overview of Pandas Data Types
- 原文作者:Chris Moffitt
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:stormluke
- 校对者:Starrier、luochen1992
简介
在进行数据分析时,确保使用正确的数据类型非常重要,否则可能会得到意想不到的结果或错误。对 Pandas 而言,它会在很多情况下正确地作出数据类型推断,你可以继续进行分析工作,而无需深入思考该主题。
尽管 Pandas 工作得很好,但在数据分析过程中的某个时刻,你可能需要将数据从一种类型显式转换为另一种类型。本文将讨论 Pandas 的基本数据类型(即 dtypes),它们如何映射到 python 和 numpy 数据类型,以及从一种 Pandas 类型转换为另一种类型的几个方式。
Pandas 的数据类型
数据类型本质上是编程语言用来理解如何存储和操作数据的内部结构。例如,一个程序需要理解你可以将两个数字加起来,比如 5 + 10 得到 15。或者,如果是两个字符串,比如「cat」和「hat」,你可以将它们连接(加)起来得到「cathat」。
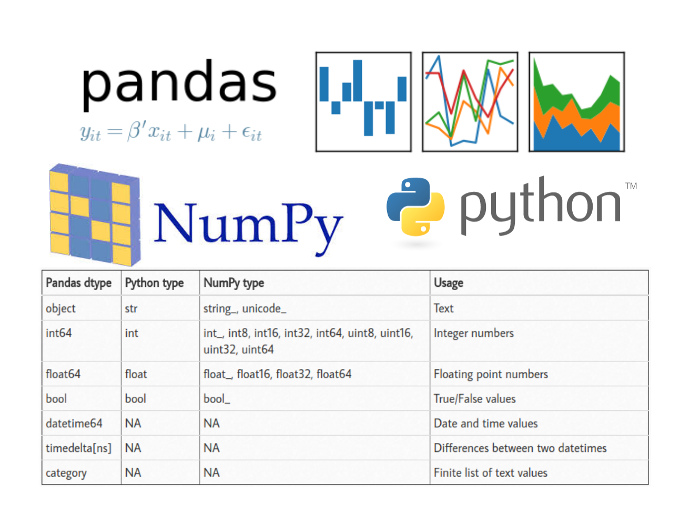
有关 Pandas 数据类型的一个可能令人困惑的地方是,Pandas、Python 和 numpy 的数据类型之间有一些重叠。下表总结了关键点:
Pandas dtype 映射:
| Pandas dtype | Python 类型 | NumPy 类型 | 用途 |
|---|---|---|---|
| object | str | string_, unicode_ | 文本 |
| int64 | int | int_, int8, int16, int32, int64, uint8, uint16, uint32, uint64 | 整数 |
| float64 | float | float_, float16, float32, float64 | 浮点数 |
| bool | bool | bool_ | 布尔值 |
| datetime64 | NA | NA | 日期时间 |
| timedelta[ns] | NA | NA | 时间差 |
| category | NA | NA | 有限长度的文本值列表 |
大多数情况下,你不必担心是否应该明确地将熊猫类型强制转换为对应的 NumPy 类型。一般来说使用 Pandas 的默认 int64 和 float64 就可以。我列出此表的唯一原因是,有时你可能会在代码行间或自己的分析过程中看到 Numpy 的类型。
对于本文,我将重点关注以下 Pandas 类型:
objectint64float64datetime64bool
如果你有兴趣,我会再写一篇文章来专门介绍 category 和 timedelta 类型。不过本文中概述的基本方法也适用于这些类型。
我们为什么关心类型?
数据类型是在你遇到错误或意外结果之前并不会关心的事情之一。不过当你将新数据加载到 Pandas 进行进一步分析时,这也是你应该检查的第一件事情。
我将使用一个非常简单的 CSV文件 来说明在 Pandas 中可能会遇到的一些常见的由数据类型导致的错误。另外,在 github 上也一个示例 notbook。
import numpy as np
import pandas as pd
df = pd.read_csv("sales_data_types.csv")
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002.0 | Quest Industries | $125,000.00 | $162500.00 | 30.00% | 500 | 1 | 10 | 2015 | Y |
| 1 | 552278.0 | Smith Plumbing | $920,000.00 | $101,2000.00 | 10.00% | 700 | 6 | 15 | 2014 | Y |
| 2 | 23477.0 | ACME Industrial | $50,000.00 | $62500.00 | 25.00% | 125 | 3 | 29 | 2016 | Y |
| 3 | 24900.0 | Brekke LTD | $350,000.00 | $490000.00 | 4.00% | 75 | 10 | 27 | 2015 | Y |
| 4 | 651029.0 | Harbor Co | $15,000.00 | $12750.00 | -15.00% | Closed | 2 | 2 | 2014 | N |
乍一看,数据没什么问题,所以我们可以尝试做一些操作来分析数据。我们来试一下把 2016 和 2017 年的销售额加起来:
df['2016'] + df['2017']
0 $125,000.00$162500.00
1 $920,000.00$101,2000.00
2 $50,000.00$62500.00
3 $350,000.00$490000.00
4 $15,000.00$12750.00
dtype: object
这看起来就不对了。我们希望将总计加在一起,但 Pandas 只是将这两个值连接在一起创建了一个长字符串。这个问题的一个线索是 dtype:object。object 在 Pandas 代表字符串,所以它执行的是字符串操作而不是数学操作。
如果我们想查看 dataframe 中的所有数据类型,使用 df.dtypes
df.dtypes
Customer Number float64
Customer Name object
2016 object
2017 object
Percent Growth object
Jan Units object
Month int64
Day int64
Year int64
Active object
dtype: object
此外,df.info() 函数可以显示更有用的信息。
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5 entries, 0 to 4
Data columns (total 10 columns):
Customer Number 5 non-null float64
Customer Name 5 non-null object
2016 5 non-null object
2017 5 non-null object
Percent Growth 5 non-null object
Jan Units 5 non-null object
Month 5 non-null int64
Day 5 non-null int64
Year 5 non-null int64
Active 5 non-null object
dtypes: float64(1), int64(3), object(6)
memory usage: 480.0+ bytes
查看自动分配的数据类型后,有几个问题:
Customer Number被归为float64但它应该是int642016和2017这两列被存储为object,但应该是float64或int64这样的数值类型Percent Growth和Jan Units也被存储为object而不是数值类型Month、Day和Year这三列应该被转换为datetime64Active列应该是布尔型
在我们清洗这些数据类型之前,要对这些数据做更多的附加分析是非常困难的。
为了在 Pandas 中转换数据类型,有三个基本选项:
- 使用
astype()来强制转换到合适的dtype - 创建一个自定义函数来转换数据
- 使用 Pandas 的函数,例如
to_numeric()或to_datetime()
使用 astype() 函数
将 Pandas 数据列转换为不同类型的最简单方法就是用 astype()。例如,要将 Customer Number 转换为整数,我们可以这样调用:
df['Customer Number'].astype('int')
0 10002
1 552278
2 23477
3 24900
4 651029
Name: Customer Number, dtype: int64
为了真正修改原始 dataframe 中的客户编号(Customer Number),记得把 astype() 函数的返回值重新赋值给 dataframe,因为 astype() 仅返回数据的副本而不原地修改。
df["Customer Number"] = df['Customer Number'].astype('int')
df.dtypes
Customer Number int64
Customer Name object
2016 object
2017 object
Percent Growth object
Jan Units object
Month int64
Day int64
Year int64
Active object
dtype: object
以下是客户编号(Customer Number)为整数的新 dataframe:
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002 | Quest Industries | $125,000.00 | $162500.00 | 30.00% | 500 | 1 | 10 | 2015 | Y |
| 1 | 552278 | Smith Plumbing | $920,000.00 | $101,2000.00 | 10.00% | 700 | 6 | 15 | 2014 | Y |
| 2 | 23477 | ACME Industrial | $50,000.00 | $62500.00 | 25.00% | 125 | 3 | 29 | 2016 | Y |
| 3 | 24900 | Brekke LTD | $350,000.00 | $490000.00 | 4.00% | 75 | 10 | 27 | 2015 | Y |
| 4 | 651029 | Harbor Co | $15,000.00 | $12750.00 | -15.00% | Closed | 2 | 2 | 2014 | N |
这一切看起来不错,并且似乎很简单。让我们尝试对 2016 列做同样的事情并将其转换为浮点数:
df['2016'].astype('float')
ValueError Traceback (most recent call last)
<ipython-input-45-999869d577b0> in <module>()
----> 1 df['2016'].astype('float')
[一些错误信息]
ValueError: could not convert string to float: '$15,000.00'
以类似的方式,我们可以尝试将 Jan Units 列转换为整数:
df['Jan Units'].astype('int')
ValueError Traceback (most recent call last)
<ipython-input-44-31333711e4a4> in <module>()
----> 1 df['Jan Units'].astype('int')
[一些错误信息]
ValueError: invalid literal for int() with base 10: 'Closed'
这两个都返回 ValueError 异常,这意味着转换不起作用。
在这两个例子中,数据都包含不能被解释为数字的值。在销售额(2016)列中,数据包括货币符号以及每个值中的逗号。在 Jan Units 列中,最后一个值是 "Closed",它不是一个数字;所以我们得到了异常。
到目前为止,astype() 作为工具看起来并不怎么好。我们在 Active 列中再试一次。
df['Active'].astype('bool')
0 True
1 True
2 True
3 True
4 True
Name: Active, dtype: bool
第一眼,这看起来不错,但经过仔细检查,存在一个大问题。所有的值都被解释为 True,但最后一个客户有一个 N 的活动(Active)标志,所以这并不正确。
这一节的重点是 astype() 只有在下列情况下才能工作:
- 数据是干净的,可以简单地解释为一个数字
- 你想要将一个数值转换为一个字符串对象
如果数据具有非数字字符或它们间不同质(homogeneous),那么 astype() 并不是类型转换的好选择。你需要进行额外的变换才能完成正确的类型转换。
自定义转换函数
由于该数据转换稍微复杂一些,因此我们可以构建一个自定义函数,将其应用于每个值并转换为适当的数据类型。
对于货币转换(这个特定的数据集),下面是一个我们可以使用的简单函数:
def convert_currency(val):
"""
Convert the string number value to a float
- Remove $
- Remove commas
- Convert to float type
"""
new_val = val.replace(',','').replace('$', '')
return float(new_val)
该代码使用python的字符串函数去掉 $ 和 ,,然后将该值转换为浮点数。在这个特定情况下,我们可以将值转换为整数,但我选择在这种情况下使用浮点数。
我也怀疑有人会建议我们对货币使用 Decimal 类型。这不是 Pandas 的本地数据类型,所以我故意坚持使用 float 方式。
另外值得注意的是,该函数将数字转换为 python 的 float,但 Pandas 内部将其转换为 float64。正如前面提到的,我建议你允许 Pandas 在确定合适的时候将其转换为特定的大小 float 或 int。你不需要尝试将其转换为更小或更大的字节大小,除非你真的知道为什么需要那样做。
现在,我们可以使用 Pandas 的 apply 函数将其应用于 2016 列中的所有值。
df['2016'].apply(convert_currency)
0 125000.0
1 920000.0
2 50000.0
3 350000.0
4 15000.0
Name: 2016, dtype: float64
成功!所有的值都显示为 float64,我们可以完成所需要的所有数学计算了。
我确信有经验的读者会问为什么我不使用 lambda 函数?在回答之前,先看下我们可以在一行中使用 lambda 函数完成的操作:
df['2016'].apply(lambda x: x.replace('$', '').replace(',', '')).astype('float')
使用 lambda,我们可以将代码简化为一行,这是非常有效的方法。但我对这种方法有三个主要的意见:
- 如果你只是在学习 Python / Pandas,或者如果将来会有 Python 新人来维护代码,我认为更长的函数的可读性更好。主要原因是它可以包含注释,也可以分解为若干步骤。lambda 函数对于新手来说更难以掌握。
- 其次,如果你打算在多个列上重复使用这个函数,复制长长的 lambda 函数并不方便。
- 最后,使用函数可以在使用
read_csv()时轻松清洗数据。我将在文章结尾处介绍具体的使用方法。
有些人也可能会争辩说,其他基于 lambda 的方法比自定义函数的性能有所提高。但为了教导新手,我认为函数方法更好。
以下是使用 convert_currency 函数转换两个销售(2016 / 2017)列中数据的完整示例。
df['2016'] = df['2016'].apply(convert_currency)
df['2017'] = df['2017'].apply(convert_currency)
df.dtypes
Customer Number int64
Customer Name object
2016 float64
2017 float64
Percent Growth object
Jan Units object
Month int64
Day int64
Year int64
Active object
dtype: object
有关使用 lambda 和函数的另一个例子,我们可以看看修复 Percent Growth 列的过程。
使用 lambda:
df['Percent Growth'].apply(lambda x: x.replace('%', '')).astype('float') / 100
用自定义函数做同样的事情:
def convert_percent(val):
"""
Convert the percentage string to an actual floating point percent
- Remove %
- Divide by 100 to make decimal
"""
new_val = val.replace('%', '')
return float(new_val) / 100
df['Percent Growth'].apply(convert_percent)
两者返回的值相同:
0 0.30
1 0.10
2 0.25
3 0.04
4 -0.15
Name: Percent Growth, dtype: float64
我将介绍的最后一个自定义函数是使用 np.where() 将活动(Active)列转换为布尔值。有很多方法来解决这个特定的问题。np.where() 方法对于很多类型的问题都很有用,所以我选择在这里介绍它。
其基本思想是使用 np.where() 函数将所有 Y 值转换为 True,其他所有值为 False
df["Active"] = np.where(df["Active"] == "Y", True, False)
其结果如下 dataframe:
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002.0 | Quest Industries | $125,000.00 | $162500.00 | 30.00% | 500 | 1 | 10 | 2015 | True |
| 1 | 552278.0 | Smith Plumbing | $920,000.00 | $101,2000.00 | 10.00% | 700 | 6 | 15 | 2014 | True |
| 2 | 23477.0 | ACME Industrial | $50,000.00 | $62500.00 | 25.00% | 125 | 3 | 29 | 2016 | True |
| 3 | 24900.0 | Brekke LTD | $350,000.00 | $490000.00 | 4.00% | 75 | 10 | 27 | 2015 | True |
| 4 | 651029.0 | Harbor Co | $15,000.00 | $12750.00 | -15.00% | Closed | 2 | 2 | 2014 | False |
dtype 被正确地设置为了 bool。
df.dtypes
Customer Number float64
Customer Name object
2016 object
2017 object
Percent Growth object
Jan Units object
Month int64
Day int64
Year int64
Active bool
dtype: object
无论你选择使用 lambda 函数,还是创建一个更标准的 Python 函数,或者是使用其他方法(如 np.where),这些方法都非常灵活,并且可以根据你自己独特的数据需求进行定制。
Pandas 辅助函数
Pandas 在直白的 astype() 函数和复杂的自定义函数之间有一个中间地带。这些辅助函数对于某些数据类型转换非常有用。
如果你顺序读下来,你会注意到我没有对日期列或 Jan Units 列做任何事情。这两种列都可以使用 Pandas 的内置函数(如 pd.to_numeric() 和 pd.to_datetime())进行转换。
Jan Units 转换出现问题的原因是列中包含一个非数字值。如果我们尝试使用 astype(),我们会得到一个错误(如前所述)。pd.to_numeric() 函数可以更优雅地处理这些值:
pd.to_numeric(df['Jan Units'], errors='coerce')
0 500.0
1 700.0
2 125.0
3 75.0
4 NaN
Name: Jan Units, dtype: float64
这里有几个值得注意的地方。首先,该函数轻松地处理了数据并创建了一个 float64 列。 此外,它会用 NaN 值替换无效的 Closed 值,因为我们配置了 errors=coerce。我们可以将 Nan 留在那里,也可以使用 fillna(0) 来用 0 填充:
pd.to_numeric(df['Jan Units'], errors='coerce').fillna(0)
0 500.0
1 700.0
2 125.0
3 75.0
4 0.0
Name: Jan Units, dtype: float64
我最终介绍的转换是将单独的月份、日期和年份列转换为到一个 datetime 类型的列。Pandas 的 pd.to_datetime() 函数 可定制性很好,但默认情况下也十分明智。
pd.to_datetime(df[['Month', 'Day', 'Year']])
0 2015-01-10
1 2014-06-15
2 2016-03-29
3 2015-10-27
4 2014-02-02
dtype: datetime64[ns]
在这种情况下,函数将这些列组合成适当 datateime64 dtype 的新列。
我们需要确保将这些值赋值回 dataframe:
df["Start_Date"] = pd.to_datetime(df[['Month', 'Day', 'Year']])
df["Jan Units"] = pd.to_numeric(df['Jan Units'], errors='coerce').fillna(0)
| Customer Number | Customer Name | 2016 | 2017 | Percent Growth | Jan Units | Month | Day | Year | Active | Start_Date | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10002 | Quest Industries | 125000.0 | 162500.0 | 0.30 | 500.0 | 1 | 10 | 2015 | True | 2015-01-10 |
| 1 | 552278 | Smith Plumbing | 920000.0 | 1012000.0 | 0.10 | 700.0 | 6 | 15 | 2014 | True | 2014-06-15 |
| 2 | 23477 | ACME Industrial | 50000.0 | 62500.0 | 0.25 | 125.0 | 3 | 29 | 2016 | True | 2016-03-29 |
| 3 | 24900 | Brekke LTD | 350000.0 | 490000.0 | 0.04 | 75.0 | 10 | 27 | 2015 | True | 2015-10-27 |
| 4 | 651029 | Harbor Co | 15000.0 | 12750.0 | -0.15 | NaN | 2 | 2 | 2014 | False | 2014-02-02 |
现在数据已正确转换为我们需要的所有类型:
df.dtypes
Customer Number int64
Customer Name object
2016 float64
2017 float64
Percent Growth float64
Jan Units float64
Month int64
Day int64
Year int64
Active bool
Start_Date datetime64[ns]
Dataframe 已准备好进行分析!
把它们放在一起
在数据采集过程中应该尽早地使用 astype() 和自定义转换函数。如果你有一个打算重复处理的数据文件,并且它总是以相同的格式存储,你可以定义在读取数据时需要应用的 dtype 和 converters。将 dtype 视为对数据执行 astype() 很有帮助。converters 参数允许你将函数应用到各种输入列,类似于上面介绍的方法。
需要注意的是,只能使用 dtype 或 converter 函数中的一种来应用于指定的列。如果你尝试将两者应用于同一列,则会跳过 dtype。
下面是一个简化的例子,它在数据读入 dataframe 时完成几乎所有的转换:
df_2 = pd.read_csv("sales_data_types.csv",
dtype={'Customer Number': 'int'},
converters={'2016': convert_currency,
'2017': convert_currency,
'Percent Growth': convert_percent,
'Jan Units': lambda x: pd.to_numeric(x, errors='coerce'),
'Active': lambda x: np.where(x == "Y", True, False)
})
df_2.dtypes
Customer Number int64
Customer Name object
2016 float64
2017 float64
Percent Growth float64
Jan Units float64
Month int64
Day int64
Year int64
Active object
dtype: object
正如前面提到的,我选择了包含用于转换数据的 lambda 示例和函数示例。唯一无法被应用在这里的函数就是那个用来将 Month、Day 和 Year 三列转换到 datetime 列的函数。不过,这仍是一个强大的可以帮助改进数据处理流程的约定。
总结
探索新数据集的第一步是确保数据类型设置正确。大部分时间 Pandas 都会做出合理推论,但数据集中有很多细微差别,因此知道如何使用 Pandas 中的各种数据转换选项非常重要。如果你有任何其他建议,或者有兴趣探索 category 数据类型,请随时在下面发表评论。
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
