

最近刚学typescript,想着能用来做点什么,顺便也练练手,加之最近也有个想法,前提是需要解决数据来源的问题,所以尝试一下能不能用ts来写一个爬虫,然后存到数据库里面为我所用,下面就是我的实践过程
配置开发环境
全局安装typescript
npm install -g typescript
创建项目文件夹
mkdir ts-spider
进入该文件夹以后初始化项目
npm init -y
下面要安装一下项目中用到的模块
- axios (网络请求)
- cheerio (提供jQuery Selector的解析能力)
- mysql (数据库交互)
npm i --save axios cheerio mysql
相应的,要安装一下对应的类型声明模块
npm i -s @types/axios --save
npm i -s @types/cheerio --save
npm i -s @types/mysql --save
其实axios已经自带类型声明,所以不安装也是可以的
下面安装一下项目内的typescript(必须走这一步)
npm i --save typescript
用vscode打开项目,在根目录下新建一个tsconfig.json文件,加入一下配置项
{
"compilerOptions": {
"target": "ES6",
"module": "commonjs",
"noEmitOnError": true,
"noImplicitAny": true,
"experimentalDecorators": true,
"sourceMap": false,
// "sourceRoot": "./",
"outDir": "./out"
},
"exclude": [
"node_modules"
]
}
到这里我们的环境搭建算基本完成了,下面我们来测试下
开发环境测试
在项目根目录下创建一个api.ts文件,写入以下代码
import axios from 'axios'
/**网络请求 */
export const remote_get = function(url: string) {
const promise = new Promise(function (resolve, reject) {
axios.get(url).then((res: any) => {
resolve(res.data);
}, (err: any) => {
reject(err);
});
});
return promise;
}
创建一个app.ts文件,写入以下代码
import { remote_get } from './api'
const go = async () => {
let res = await remote_get('http://www.baidu.com/');
console.log(`获取到的数据为: ${res}`);
}
go();
执行一下命令
tsc
我们发现项目根目录想多了一个/out文件夹,里面是转换后的js文件
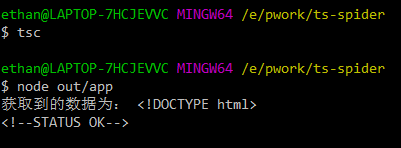
我们执行一下
node out/app
输出类似这样,就代表我们的爬虫已经爬到了这个网页,环境测试已经通过了!接下来我们尝试一下抓取其中的数据
分析网页并抓取数据
我们将app.ts重构一下,引入cheerio,开始抓取我们需要的数据,当然了,这次我们换一下目标,我们抓取一下豆瓣上面的的数据
前面也提到了cheerio提供了jQuery Selector的解析能力,关于它的具体用法,可以点击这里查看
import { remote_get } from './api'
import * as cheerio from 'cheerio'
const go = async () => {
const res: any = await remote_get('https://www.douban.com/group/szsh/discussion?start=0');
// 加载网页
const $ = cheerio.load(res);
let urls: string[] = [];
let titles: string[] = [];
// 获取网页中的数据,分别写到两个数组里面
$('.olt').find('tr').find('.title').find('a').each((index, element) => {
titles.push($(element).attr('title').trim());
urls.push($(element).attr('href').trim());
})
// 打印数组
console.log(titles, urls);
}
go();
这段代码是获取豆瓣上小组话题和对应的链接,然后写入数组里面,分别打印出来。我们跑一下代码,看看输出
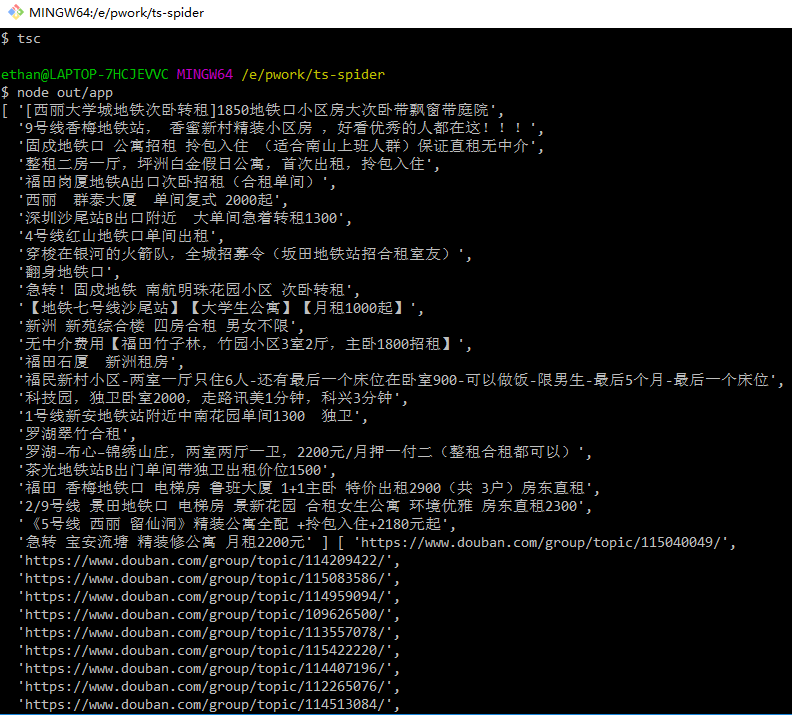
可以看到已经获取到我们想要的数据了。接下来我们尝试把这些数据写入到数据库里面
将数据写入数据库
开始的时候其实是想把数据写到MongoDB里面,但是考虑到自己对这个还不太熟,和自己手头的体验版服务器那一点点可怜的空间,最后还是放弃了,还是决定先尝试写到mysql数据库里面
我们先本地安装一个mysql数据库,安装过程就不详细说了,安装完后在本地数据库中新建一个表
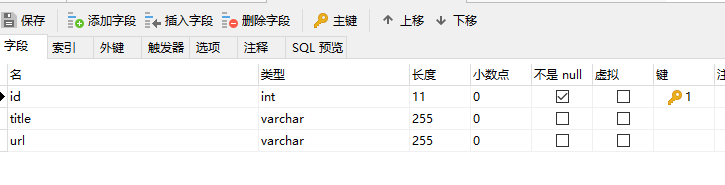
在项目根目录下添加util.ts文件,写入一下代码
import * as mysql from 'mysql'
/* 延时函数 */
export function sleep(msec: number) {
return new Promise<void>(resolve => setTimeout(resolve, msec));
}
/**
* 封装一个数据库连接的方法
* @param {string} sql SQL语句
* @param arg SQL语句插入语句的数据
* @param callback SQL语句的回调
*/
export function db(sql: string, arg: any, callback?: any) {
// 1.创建连接
const config = mysql.createConnection({
host: 'localhost', // 数据库地址
user: 'root', // 数据库名
password: '', // 数据库密码
port: 3306, // 端口号
database: 'zhufang' // 使用数据库名字
});
// 2.开始连接数据库
config.connect();
// 3.封装对数据库的增删改查操作
config.query(sql, arg, (err:any, data:any) => {
callback(err, data);
});
// 4.关闭数据库
config.end();
}
以上我们已经封装好了一个数据库连接的方法,其中包含了数据库的配置信息,下面我们修改app.ts文件,引入我们封装好的db模块,并写入数据的操作代码
import { remote_get } from './api'
import * as cheerio from 'cheerio'
import { sleep, db } from './util'
const go = async () => {
const res: any = await remote_get('https://www.douban.com/group/szsh/discussion?start=0');
// 加载网页
const $ = cheerio.load(res);
let urls: string[] = [];
let titles: string[] = [];
// 获取网页中的数据,分别写到两个数组里面
$('.olt').find('tr').find('.title').find('a').each((index, element) => {
titles.push($(element).attr('title').trim());
urls.push($(element).attr('href').trim());
})
// 打印数组
console.log(titles, urls);
// 往数据库里面写入数据
titles.map((item, index) => {
db('insert into info_list(title,url) values(?,?)', [item, urls[index]], (err: any, data: any) => {
if(data){
console.log('提交数据成功!!')
}
if (err) {
console.log('提交数据失败')
}
})
})
}
go();
这里我们往数据库中插入title数组和urls数组的数据。跑一下代码,看了输出没有问题,我们看下数据库
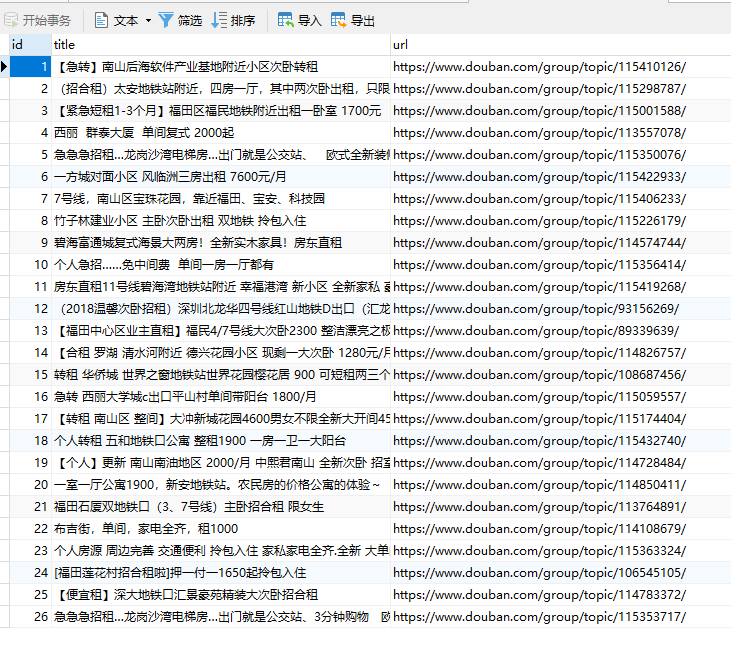
数据已经写入了!到这里我们的这次实践就告一段落
下面考虑的是爬取数据过快的延时机制,和如何分页获取数据,如何获取爬到的链接对应的详细信息,功能模块化等等,这里就不细说了
参考文档
https://cloud.tencent.com/info/d0dd52a4a2b1f90055afe4fac4dcd76b.html https://hpdell.github.io/%E7%88%AC%E8%99%AB/crawler-cheerio-ts/
