

- 原文地址:GAN with Keras: Application to Image Deblurring
- 原文作者:Raphaël Meudec
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:luochen
- 校对者:SergeyChang mingxing47
2014年,Ian Goodfellow 提出了生成对抗网络(Generative Adversarial Networks) (GAN),本文将聚焦于利用 Keras 实现基于对抗生成网络的图像去模糊模型所有的 Keras 代码都在 这里.
查看原文 scientific publication 以及 Pytorch 版本实现.
快速回顾生成对抗网络
在生成对抗网络中,两个网络互相训练。生成模型通过创造以假乱真的输入误导判别模型。判别模型则区分输入是真实的还是伪造的。
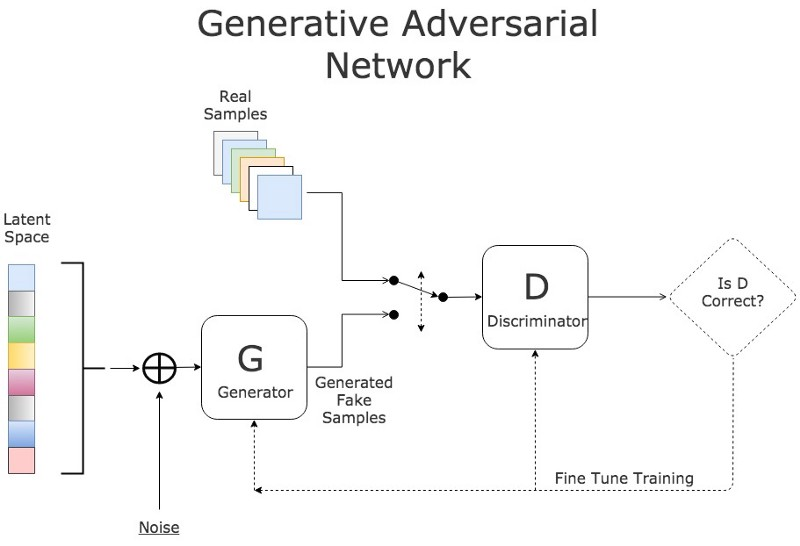
GAN 训练流程 — Source
训练有3个主要步骤:
- 使用生成模型创造基于噪声的假输入。
- 同时使用真实的和虚假的输入训练判别模型。
- 训练整个模型: 该模型是由生成模型后串接判别模型所构成的。
请注意,在第三步中,判别模型的权重不再更新。
串接两个模型网络的原因是不可能直接对生成模型输出进行反馈。我们衡量(生成模型的输出)的唯一标准是判别模型是否接受生成的样本。
这里简要回顾了 GAN 的结构。如果你觉得不容易理解,你可以参考这个 excellent introduction.
数据集
Ian Goodfellow 首先应用 GAN 模型生成 MNIST 数据。在本教程中,我们使用生成对抗网络进行图像去模糊。因此,生成模型的输入不是噪声而是模糊的图像。
数据集采用 GOPRO 数据集。您可以下载 精简版 (9GB) 或 完整版 (35GB)。它包含来自多个街景的人为模糊图像。数据集在按场景分的子文件夹里。
我们先将图片放在文件夹 A(模糊)和 B(清晰)中。这种 A 和 B 的结构与原论文 pix2pix article 一致。我写了一个 自定义脚本 去执行这个任务,按照 README 使用它。
模型
训练过程保持不变。首先,让我们看看神经网络结构!
生成模型
生成模型旨在重现清晰的图像。该网络模型是基于 残差网络(ResNet) 块(block)。它持续追踪原始模糊图像的演变。这篇文章是基于 UNet 版本的, 我还没实现过。这两种结构都适合用于图像去模糊。
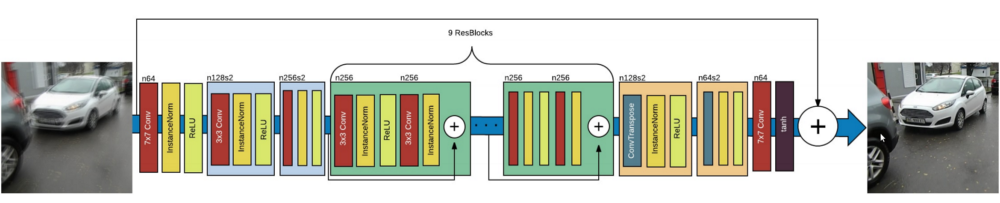
DeblurGAN 生成模型的网络结构 — Source
核心是应用于原始图像上采样的 9 个残差网络块(ResNet blocks)。让我们看看 Keras 的实现!
from keras.layers import Input, Conv2D, Activation, BatchNormalization
from keras.layers.merge import Add
from keras.layers.core import Dropout
def res_block(input, filters, kernel_size=(3,3), strides=(1,1), use_dropout=False):
"""
使用序贯(sequential) API 对 Keras Resnet 块进行实例化。
:param input: 输入张量
:param filters: 卷积核数目
:param kernel_size: 卷积核大小
:param strides: 卷积步幅大小
:param use_dropout: 布尔值,确定是否使用 dropout
:return: Keras 模型
"""
x = ReflectionPadding2D((1,1))(input)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
if use_dropout:
x = Dropout(0.5)(x)
x = ReflectionPadding2D((1,1))(x)
x = Conv2D(filters=filters,
kernel_size=kernel_size,
strides=strides,)(x)
x = BatchNormalization()(x)
# 输入和输出之间连接两个卷积层
merged = Add()([input, x])
return merged
ResNet 层基本是卷积层,添加了输入和输出以形成最终输出。
from keras.layers import Input, Activation, Add
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D, Conv2DTranspose
from keras.layers.core import Lambda
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from layer_utils import ReflectionPadding2D, res_block
ngf = 64
input_nc = 3
output_nc = 3
input_shape_generator = (256, 256, input_nc)
n_blocks_gen = 9
def generator_model():
"""构建生成模型"""
# Current version : ResNet block
inputs = Input(shape=image_shape)
x = ReflectionPadding2D((3, 3))(inputs)
x = Conv2D(filters=ngf, kernel_size=(7,7), padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# Increase filter number
n_downsampling = 2
for i in range(n_downsampling):
mult = 2**i
x = Conv2D(filters=ngf*mult*2, kernel_size=(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
# 应用 9 ResNet blocks
mult = 2**n_downsampling
for i in range(n_blocks_gen):
x = res_block(x, ngf*mult, use_dropout=True)
# 减少卷积核到3个 (RGB)
for i in range(n_downsampling):
mult = 2**(n_downsampling - i)
x = Conv2DTranspose(filters=int(ngf * mult / 2), kernel_size=(3,3), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = ReflectionPadding2D((3,3))(x)
x = Conv2D(filters=output_nc, kernel_size=(7,7), padding='valid')(x)
x = Activation('tanh')(x)
# Add direct connection from input to output and recenter to [-1, 1]
outputs = Add()([x, inputs])
outputs = Lambda(lambda z: z/2)(outputs)
model = Model(inputs=inputs, outputs=outputs, name='Generator')
return model
Keras 实现生成模型
按计划,9 个 ResNet 块应用于输入的上采样版本。我们添加从输入端到输出端的连接并除以 2 以保持标准化的输出。
这就是生成模型,让我们看看判别模型。
判别模型
判别模型的目标是确定输入图像是否是人造的。因此,判别模型的结构是卷积的,并且输出是单一值。
from keras.layers import Input
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.convolutional import Conv2D
from keras.layers.core import Dense, Flatten
from keras.layers.normalization import BatchNormalization
from keras.models import Model
ndf = 64
output_nc = 3
input_shape_discriminator = (256, 256, output_nc)
def discriminator_model():
"""构建判别模型."""
n_layers, use_sigmoid = 3, False
inputs = Input(shape=input_shape_discriminator)
x = Conv2D(filters=ndf, kernel_size=(4,4), strides=2, padding='same')(inputs)
x = LeakyReLU(0.2)(x)
nf_mult, nf_mult_prev = 1, 1
for n in range(n_layers):
nf_mult_prev, nf_mult = nf_mult, min(2**n, 8)
x = Conv2D(filters=ndf*nf_mult, kernel_size=(4,4), strides=2, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.2)(x)
nf_mult_prev, nf_mult = nf_mult, min(2**n_layers, 8)
x = Conv2D(filters=ndf*nf_mult, kernel_size=(4,4), strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = LeakyReLU(0.2)(x)
x = Conv2D(filters=1, kernel_size=(4,4), strides=1, padding='same')(x)
if use_sigmoid:
x = Activation('sigmoid')(x)
x = Flatten()(x)
x = Dense(1024, activation='tanh')(x)
x = Dense(1, activation='sigmoid')(x)
model = Model(inputs=inputs, outputs=x, name='Discriminator')
return model
Keras实现判别模型
最后一步是构建完整模型。这个 GAN 的 特殊性在于输入是真实图像而不是噪声。因此,我们能获得生成模型输出的直接反馈。
from keras.layers import Input
from keras.models import Model
def generator_containing_discriminator_multiple_outputs(generator, discriminator):
inputs = Input(shape=image_shape)
generated_images = generator(inputs)
outputs = discriminator(generated_images)
model = Model(inputs=inputs, outputs=[generated_images, outputs])
return model
让我们看看如何通过使用两个损失函数来充分利用这种特殊性。
训练
损失函数
我们在两个层级抽取损失值,一个是在生成模型的末端,另一个在整个模型的末端。
首先是直接根据生成模型的输出计算感知损失(perceptual loss)。该损失值确保了 GAN 模型是面向去模糊任务的。它比较了VGG的 第一个卷积输出。
import keras.backend as K
from keras.applications.vgg16 import VGG16
from keras.models import Model
image_shape = (256, 256, 3)
def perceptual_loss(y_true, y_pred):
vgg = VGG16(include_top=False, weights='imagenet', input_shape=image_shape)
loss_model = Model(inputs=vgg.input, outputs=vgg.get_layer('block3_conv3').output)
loss_model.trainable = False
return K.mean(K.square(loss_model(y_true) - loss_model(y_pred)))
第二个损失值是计算整个模型的输出 Wasserstein loss。它是 两张图像之间的平均差异。它以改善对抗生成网络收敛性而闻名.
import keras.backend as K
def wasserstein_loss(y_true, y_pred):
return K.mean(y_true*y_pred)
训练过程
第一步是载入数据以及初始化模型。我们使用自定义函数载入数据集以及为模型添加 Adam 优化器。我们通过设置 Keras 可训练选项以防止判别模型进行训练。
# 载入数据集
data = load_images('./images/train', n_images)
y_train, x_train = data['B'], data['A']
# 初始化模型
g = generator_model()
d = discriminator_model()
d_on_g = generator_containing_discriminator_multiple_outputs(g, d)
# 初始化优化器
g_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
d_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
d_on_g_opt = Adam(lr=1E-4, beta_1=0.9, beta_2=0.999, epsilon=1e-08)
# 编译模型
d.trainable = True
d.compile(optimizer=d_opt, loss=wasserstein_loss)
d.trainable = False
loss = [perceptual_loss, wasserstein_loss]
loss_weights = [100, 1]
d_on_g.compile(optimizer=d_on_g_opt, loss=loss, loss_weights=loss_weights)
d.trainable = True
然后,我们启动迭代,同时将数据集按批量划分。
for epoch in range(epoch_num):
print('epoch: {}/{}'.format(epoch, epoch_num))
print('batches: {}'.format(x_train.shape[0] / batch_size))
# 将图像随机划入不同批次
permutated_indexes = np.random.permutation(x_train.shape[0])
for index in range(int(x_train.shape[0] / batch_size)):
batch_indexes = permutated_indexes[index*batch_size:(index+1)*batch_size]
image_blur_batch = x_train[batch_indexes]
image_full_batch = y_train[batch_indexes]
最后,我们根据两种损失先后训练生成模型和判别模型。我们用生成模型产生假输入。我们训练判别模型来区分虚假和真实输入,然后我们训练整个模型。
for epoch in range(epoch_num):
for index in range(batches):
# [Batch Preparation]
# 生成假输入
generated_images = g.predict(x=image_blur_batch, batch_size=batch_size)
# 在真假输入上训练多次判别模型
for _ in range(critic_updates):
d_loss_real = d.train_on_batch(image_full_batch, output_true_batch)
d_loss_fake = d.train_on_batch(generated_images, output_false_batch)
d_loss = 0.5 * np.add(d_loss_fake, d_loss_real)
d.trainable = False
# Train generator only on discriminator's decision and generated images
d_on_g_loss = d_on_g.train_on_batch(image_blur_batch, [image_full_batch, output_true_batch])
d.trainable = True
你可以参考 Github 看整个循环!
一些材料
我在 Deep Learning AMI (version 3.0) 中使用了 AWS Instance (p2.xlarge) 在 GOPRO 数据集 精简版下,训练时间约为5小时(50 次迭代)。
图像去模糊结果

从左到右: 原始图像、模糊图像、GAN 输出
上面的输出是我们 Keras Deblur GAN 的结果。即使在严重模糊的情况下,网络也能够减少并形成更令人信服的图像。车灯更清晰,树枝更清晰。

左: GOPRO 测试图像, 右: GAN 输出.
一个限制是图像上的诱导模式,这可能是由于使用 VGG 作为损失而引起的。

左: GOPRO 测试图像, 右: GAN 输出.
我希望你喜欢这篇关于利用生成对抗模型进行图像去模糊的文章。欢迎发表评论,关注我们或 与我联系.
如果您对计算机视觉感兴趣,可以看看我们以前写的一篇文章 Keras 实现基于内容的图像检索。以下是生成对抗网络的资源列表。

左:GOPRO 测试图像,右:GAN 输出。
生成对抗网络的资源列表。
-
NIPS 2016: 对抗生成网络(Generative Adversarial Networks) by Ian Goodfellow
-
对抗生成网络资源列表 by deeplearning4j
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
