

提升方法
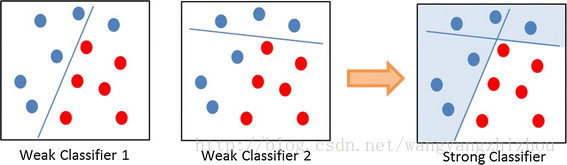
提升方法的核心思想是通过将多个效果很一般的分类器(弱分类器)组合起来综合考虑,以实现一个效果较好的分类器,这就像“三个臭皮匠赛过诸葛亮”。弱学习者学习出来的效果可能只比随机分类器效果好一点,于是有人提出用一个弱分类器集合生成一个强分类器。
因为是将弱分类器提升为强分类器,所以叫提升方法。
AdaBoost
提升方法有很多算法,最具代表性的是 AdaBoost 。AdaBoost 是 adaptive boosting 的缩写,核心思想是提高那么被前一轮弱分类分类错误的样本的权值,同时降低分类正确的样本的权值,让错误的样本能在下一轮得到更多的关注。另外,AdaBoost 最终的分类器是由多个弱分类器的线性组合,线性系数即为每个弱分类器的权重,错误率小的弱分离器的权重大,使之能在最终结果作用更大,反之错误率大的权重应该小一些。
AdaBoost基本步骤
- 样本集
,
。
- 给样本数据集中的每一个样本初始化一个权重,
,
。
- 设一共有M个分类器,
。
- 使用训练样本集数据以及其初始权重训练得到第一个分类器
。
- 计算第一个分类器的错误率,
。
- 根据上一步的错误率计算第一个分类器分配的权重,
。
- 对第一个分类器分错的样本增加权重,分对的样本减少权重,具体的权重更新公式为,
,其中
,其
。
- 有了新的样本权重后再继续训练第二个分类器
,然后再计算第二个分类器的错误率
以及第二个分类器分配的权重
,并且继续更新权重得到
。
- 重复上述操作直到分类器错误率为0,或者达到指定的迭代次数。
- 将所有弱分类器加权求和,即线性组合,
,最终的分类器为
。
关于弱分类器
adaboost 的弱分类器没有具体的标准,只要能实现分类的分类器都可以用作弱分类器,常见的可以有如下几种:
- 逻辑回归
- 简单的神经网络
- SVM
adaboost 的弱分类器必须要是同一种分类器,不能使用不同的分类器。
关于权值
adaboost 过程中涉及两类权值,一类是样本权值,另外一类是弱分类器的权值。样本权值用于标明各个样本的权重,被标明的样本在训练中有不同的重要性,它样本的所有权重加起来和为1。弱分类器权值用于标明各个分类器的权值,它其实就是最终分类器线性组合的系数,表示每个弱分类器对结果的贡献程度,弱分类器权值加起来和不一定为1。
github
https://github.com/sea-boat/MachineLearning_Lab
demo
import numpy as np
def weak_model(data, Dt):
m = data.shape[0]
pred = []
pos = None
mark = None
min_err = np.inf
for j in range(m):
pred_temp = []
sub_mark = None
lsum = np.sum(data[:j, 1])
rsum = np.sum(data[j:, 1])
if lsum < rsum:
sub_mark = -1
pred_temp.extend([-1.] * (j))
pred_temp.extend([1.] * (m - j))
else:
sub_mark = 1
pred_temp.extend([1.] * (j))
pred_temp.extend([-1.] * (m - j))
err = np.sum(1 * (data[:, 1] != pred_temp) * Dt)
if err < min_err:
min_err = err
pos = (data[:, 0][j - 1] + data[:, 0][j]) / 2
mark = sub_mark
pred = pred_temp[:]
model = [pos, mark, min_err]
return model, pred
def adaboost(data):
models = []
N = data.shape[0]
D = np.zeros(N) + 1.0 / N
M = 3
y = data[:, -1]
for t in range(M):
Dt = D[:]
model, y_ = weak_model(data, Dt)
errt = model[-1]
alpha = 0.5 * np.log((1 - errt) / errt)
Zt = np.sum([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(N)])
D = np.array([Dt[i] * np.exp(-alpha * y[i] * y_[i]) for i in range(N)]) / Zt
models.append([model, alpha])
return models
def predict(models, X):
pred = []
for x in X:
result = 0
for base in models:
alpha = base[1]
if x[0] > base[0][0]:
result -= base[0][1] * alpha
else:
result += base[0][1] * alpha
pred.append(np.sign(result))
return pred
if __name__ == "__main__":
data = np.array([[0, 1], [1, 1], [2, 1], [3, -1], [4, -1], [5, -1], [6, 1], [7, 1], [8, 1], [9, -1]],
dtype=np.float32)
models = adaboost(data)
X = data
Y = data[:, -1]
Y_ = predict(models, X)
acc = np.sum(1 * (Y == Y_)) / float(len(X))
print(acc)
-------------推荐阅读------------
------------------广告时间----------------
跟我交流,向我提问:

公众号的菜单已分为“分布式”、“机器学习”、“深度学习”、“NLP”、“Java深度”、“Java并发核心”、“JDK源码”、“Tomcat内核”等,可能有一款适合你的胃口。
欢迎关注:

