

从毕业到现在第一次接触到超过30万条数据导入MySQL的场景(有点low),就是在顺丰公司接入我司EMM产品时需要将AD中的员工数据导入MySQL中,因此楼主负责的模块connector就派上了用场。在楼主的努力下,线上数据同步代码经历了从最初的将近16个小时(并且还出现其他问题这些问题,等后面慢慢细说),到最终25分钟的性能优化。
打个广告,楼主自己造的轮子,感兴趣的请点github.com/haifeiWu/li…
代码直接Jenkins打包上线
楼主负责的connector模块之前经历过的最大的数据量也仅仅是几千条,当然面对几千条数据代码也是跑的及其的快,没有啥影响,然而当第一次在顺丰的正式环境上线时,由于数据量比较大,楼主的代码又是串行执行的,事务保持的时间就相当长,也就因此出现了下面的错误信息:
Lock wait timeout exceeded; try restarting transaction
这里来说一下报这个错的解决方案,查看MySQL是否有锁
show OPEN TABLES where In_use > 0;
另外,在information_schema下面有三张表:INNODB_TRX、INNODB_LOCKS、INNODB_LOCK_WAITS(解决问题方法),通过这三张表,可以更简单地监控当前的事务并分析可能存在的问题。
比较常用的列:
- trx_id: InnoDB存储引擎内部唯一的事物ID
- trx_status: 当前事务的状态
- trx_status: 事务的开始时间
- trx_requested_lock_id: 等待事务的锁ID
- trx_wait_started: 事务等待的开始时间
- trx_weight: 事务的权重,反应一个事务修改和锁定的行数,当发现死锁需要回滚时,权重越小的值被回滚
- trx_mysql_thread_id: MySQL中的进程ID,与show processlist中的ID值相对应
- trx_query: 事务运行的SQL语句
kill 进程ID,发生上面错误的根本原因在业务逻辑代码对数据库的操作无视了大数据量的情况,比如当数据量比较大时就会出现刚刚修改完这条记录,接着再次修改就会出现上述出现的问题。
代码优化过程
使用线程池,并发执行,提高效率
由于数据量比较大,首先想到的方法是拿到数据后将数据分拆成n份,由多个线程并发执行数导入的操作。由此引出多线程的问题,在处理多线程问题时共享的数据结构像Map,List应该采用jdk提供的current包下的数据结构,另外在涉及到操作数据库的地方应该加锁,楼主用的是jdk提供的ReentrantLock。使用jdk自带的 jvisualvm,进行代码的监控进而找到最佳线程数,下面是监控的数据,
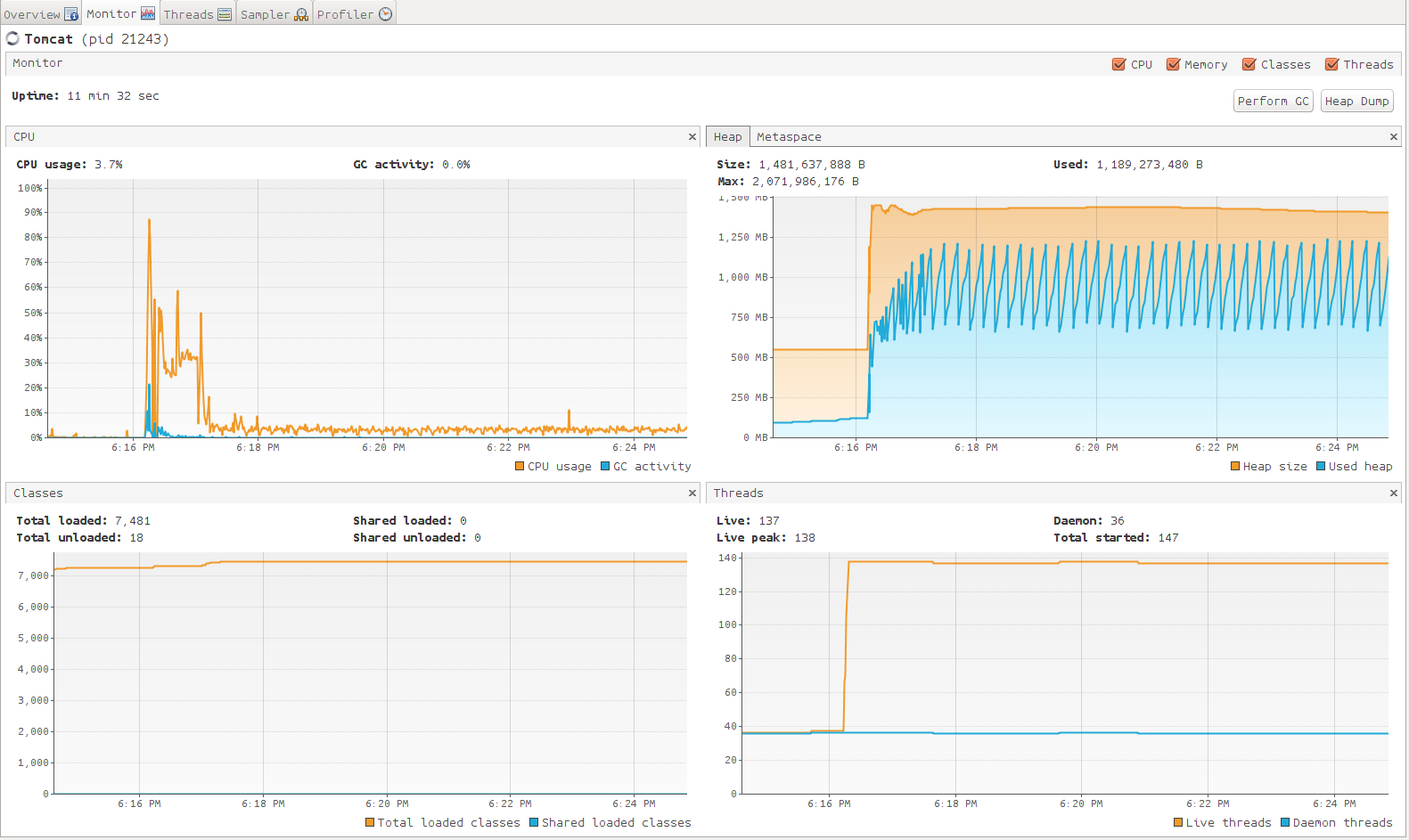
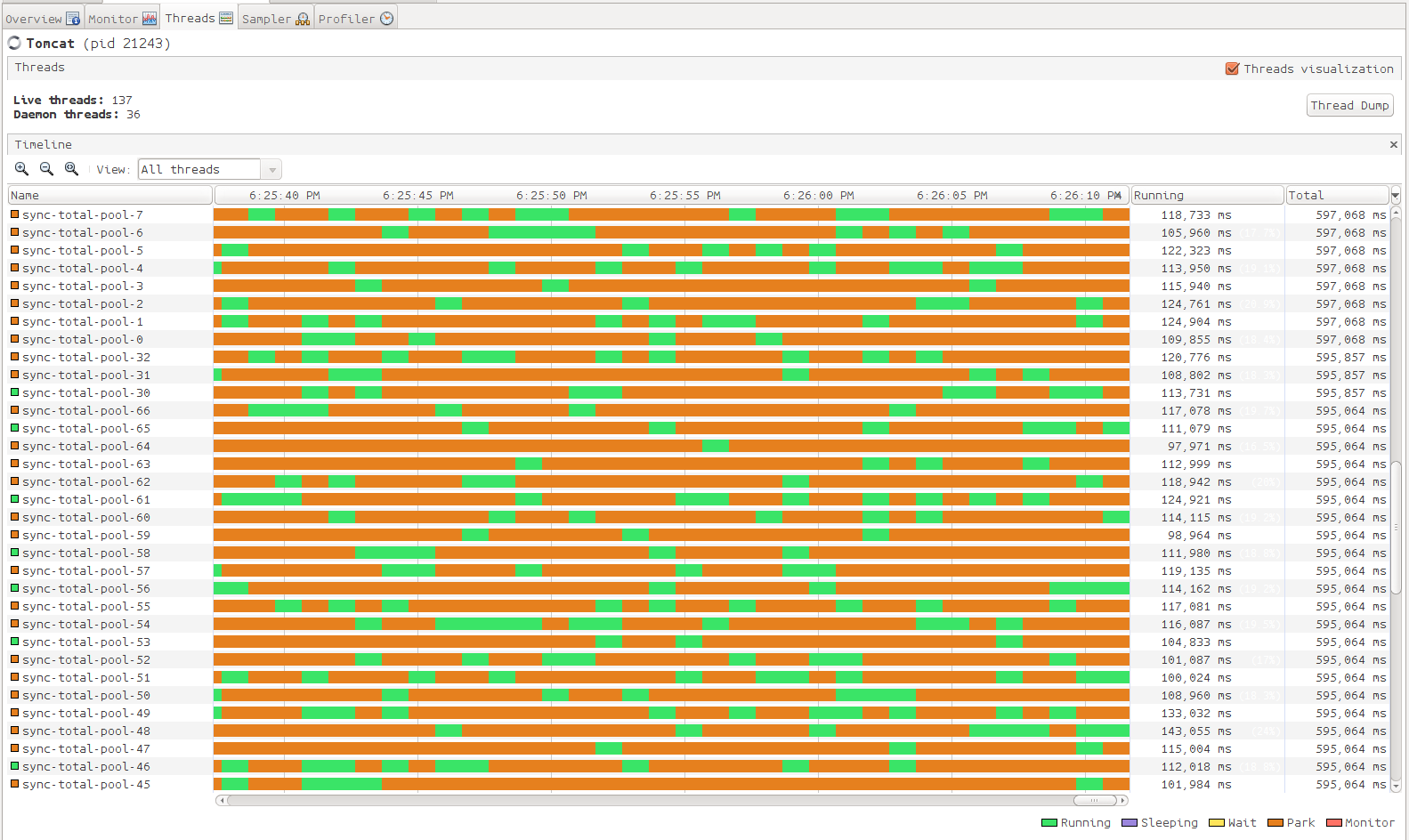
下面是线程池的创建代码
ThreadFactory namedThreadFactory = new ThreadFactoryBuilder()
.setNameFormat("demo-pool-%d").build();
ExecutorService singleThreadPool = new ThreadPoolExecutor(1, 1,0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(1024), namedThreadFactory, new ThreadPoolExecutor.AbortPolicy());
singleThreadPool.execute(()-> System.out.println(Thread.currentThread().getName()));
singleThreadPool.shutdown();
果不其然,在使用多线程之后,数据插入效率由原来的十几个小时降到了三个小时,然后并没有达到我们的预期效果,我们继续。
使用druid监控发现问题的SQL
- 配置druid监控,在应用的web.xml添加配置,并放开
/druid的拦截
<!-- druid 数据库监控 -->
<filter>
<filter-name>DruidWebStatFilter</filter-name>
<filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class>
<init-param>
<param-name>exclusions</param-name>
<param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,*.jsp,/druid/*,/download/*</param-value>
</init-param>
<init-param>
<param-name>sessionStatMaxCount</param-name>
<param-value>2000</param-value>
</init-param>
<init-param>
<param-name>sessionStatEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<param-name>principalSessionName</param-name>
<param-value>session_user_key</param-value>
</init-param>
<init-param>
<param-name>profileEnable</param-name>
<param-value>true</param-value>
</init-param>
</filter>
<filter-mapping>
<filter-name>DruidWebStatFilter</filter-name>
<url-pattern>/*</url-pattern>
</filter-mapping>
<servlet>
<servlet-name>DruidStatView</servlet-name>
<servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class>
<!--<init-param>
<param-name>allow</param-name>
<param-value>*.*.*.*</param-value>
</init-param>-->
<init-param>
<!-- 允许清空统计数据 -->
<param-name>resetEnable</param-name>
<param-value>true</param-value>
</init-param>
<init-param>
<!-- 用户名 -->
<param-name>loginUsername</param-name>
<param-value>druid</param-value>
</init-param>
<init-param>
<!-- 密码 -->
<param-name>loginPassword</param-name>
<param-value>druid</param-value>
</init-param>
</servlet>
<servlet-mapping>
<servlet-name>DruidStatView</servlet-name>
<url-pattern>/druid/*</url-pattern>
</servlet-mapping>
- 配置数据库连接池
<!-- 数据源配置, 使用 BoneCP 数据库连接池 -->
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource" init-method="init" destroy-method="close">
<!-- 数据源驱动类可不写,Druid默认会自动根据URL识别DriverClass -->
<property name="driverClassName" value="${jdbc.driver}" />
<!-- 基本属性 url、user、password -->
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
<!-- 配置初始化大小、最小、最大 -->
<property name="initialSize" value="${jdbc.pool.init}" />
<property name="minIdle" value="${jdbc.pool.minIdle}" />
<property name="maxActive" value="${jdbc.pool.maxActive}" />
<!-- 配置获取连接等待超时的时间 -->
<property name="maxWait" value="60000" />
<!-- 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒 -->
<property name="timeBetweenEvictionRunsMillis" value="60000" />
<!-- 配置一个连接在池中最小生存的时间,单位是毫秒 -->
<property name="minEvictableIdleTimeMillis" value="300000" />
<property name="validationQuery" value="${jdbc.testSql}" />
<property name="testWhileIdle" value="true" />
<property name="testOnBorrow" value="true" />
<property name="testOnReturn" value="false" />
<!-- 配置监控统计拦截的filters -->
<property name="filters" value="stat" />
</bean>
- 访问http://ip/xxx/druid,输入用户名,密码登录就会看到下面的图
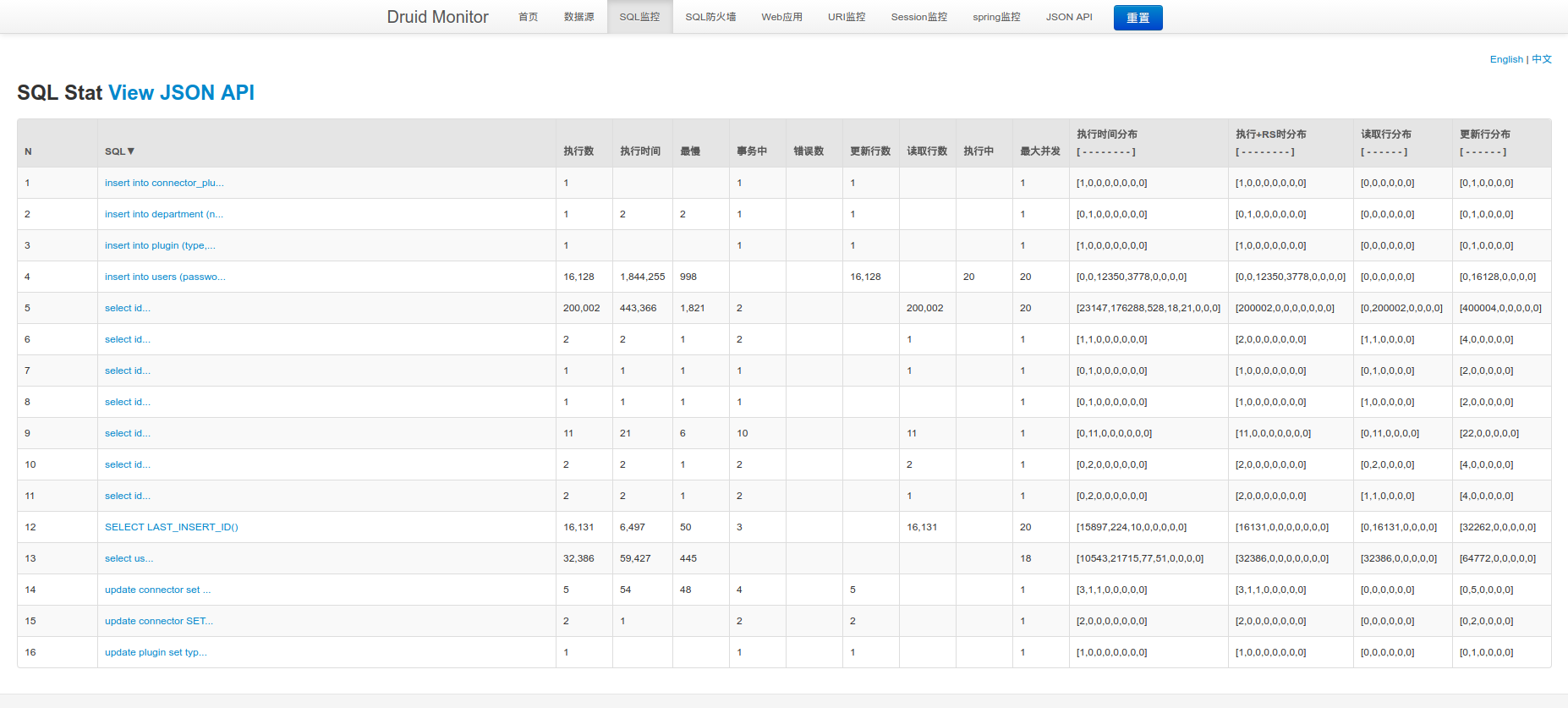
- 使用druid的SQL监控发现问题SQL语句,优化SQL
通过命令查看程序的gc情况
通过命令jstat -gc pid 来查看程序的gc情况,下面是楼主程序数据同步完成之后的gc情况

这里写代码片S0C、S1C、S0U、S1U:Survivor 0/1区容量(Capacity)和使用量(Used)
EC、EU:Eden区容量和使用量
OC、OU:年老代容量和使用量
PC、PU:永久代容量和使用量
YGC、YGT:年轻代GC次数和GC耗时
FGC、FGCT:Full GC次数和Full GC耗时
小结
通过上面的优化过程,楼主的connector的数据同居效率也由小时级下降到了分钟级,同步30+万的时间可以在25分钟内完成。经此一役,楼主算是收获满满。抱着虔诚的心态学习,不浮不躁,快乐成长。
