

如果选几个 2017 年最火的流行词,绝对有人工智能和虚拟货币。英国程序员 David Sheehan就被比特币这种颠覆性的技术以及过山车式的价格涨跌留下了深刻印象,虽然他自己一个币也没有,但还是想用机器学习技术预测一下比特币这种虚拟货币的价格。
在我(作者David Sheeran——译者注)写这篇文章之前,我到网上搜了搜,发现之前有人写过怎样用深度学习技术预测比特币价格,于是我想了想,决定除了比特币外,也预测另一种近来比较火的虚拟货币价格——以太坊,也叫以太币。
我们会使用一个长短期记忆模型(LSTM),它是深度学习模型的一种,很适合处理时序数据,或者任何有暂时性、空间性和结构性顺序的数据,比如电影、语句等等。如果你对这种模型不是很熟悉,我推荐读一下这篇博客。
因为我也想让不太懂机器学习的读者愿意看下去,所以我会尽量不放大段大段的代码,请理解一下。要是你也想这么操作一波,我把数据和代码放在了 GitHub 上,点击这里获取即可。
好了,废话不说,我们开始吧!
获取数据
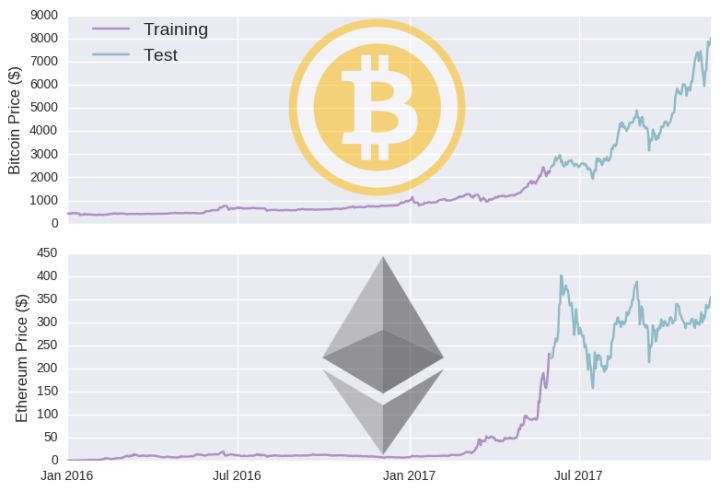
在我们搭建模型之前,我们需要获取一些数据让模型学习。在 Kaggle 上有个数据集,详细记录了过去几年比特币每分钟的价格以及其他方面的数据(我之前看的那篇预测比特币价格的教程用的也是这个数据集)。但按照每分钟的时间尺度,会有很多噪声数据,所以我们选择每天的价格。这样就会产生一个问题:我们可能收集不到足够的数据(不过我们需要几百行而不是几百万行数据)。在深度学习中,在严重缺乏数据的情况下,没有模型能取得成功。我也不想依靠静态文件,因为在将来用新数据更新模型时它们会让更新过程无比复杂。相反,我们会从虚拟货币网站和 API 中获取数据。
因为我们会将两种虚拟货币的价格混合在一个模型中,所以从一个数据源中提取数据可能是个好主意。我们会用到网站 http://coinmarketcap.com。当前我们只考虑比特币和以太坊的数据,但用这种方法再添加别的币种也不会太难。在我们导入数据前,我们必须加载一些 Python 包,让工作更容易些。
import pandas as pd
import time
import seaborn as sns
import matplotlib.pyplot as plt
import datetime
import numpy as np
# get market info for bitcoin from the start of 2016 to the current day
bitcoin_market_info = pd.read_html("https://coinmarketcap.com/currencies/bitcoin/historical-data/?start=20130428&end="+time.strftime("%Y%m%d"))[0]
# convert the date string to the correct date format
bitcoin_market_info = bitcoin_market_info.assign(Date=pd.to_datetime(bitcoin_market_info['Date']))
# when Volume is equal to '-' convert it to 0
bitcoin_market_info.loc[bitcoin_market_info['Volume']=="-",'Volume']=0
# convert to int
bitcoin_market_info['Volume'] = bitcoin_market_info['Volume'].astype('int64')
# look at the first few rows
bitcoin_market_info.head()
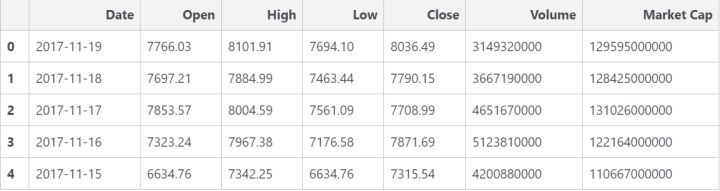
刚刚发生了什么呢?我们加载了一些 Python 包,然后导入了coinmarketcap.com 上如上所示的这种数据表格。稍微清洗一下数据后,我们就会获得上面这个比特币价格表格。在 URL 里将 bitcoin 换成 ethereum 也能得到以太坊的价格数据。
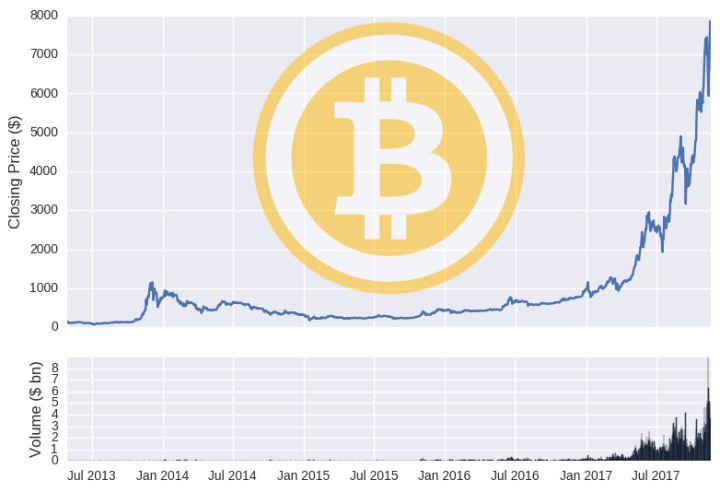
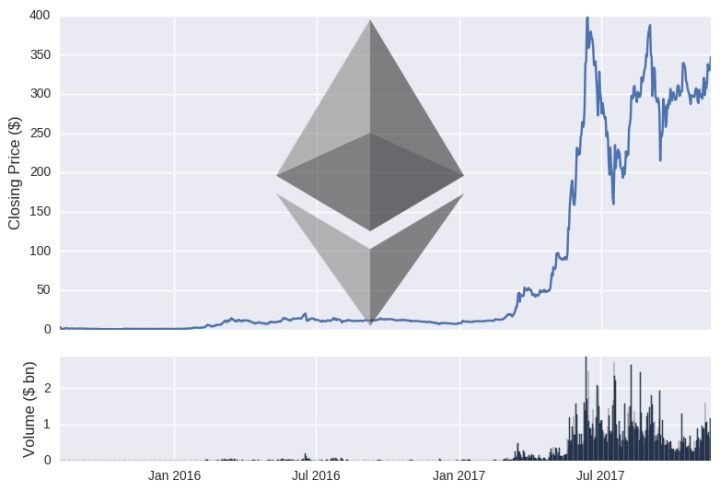
要想证明数据是准确的,我们可以绘制出两种货币价格和容量随着时间推移的变化情况:
训练,测试和随机游走
我们已经获取了一些数据,那么我们先在需要一个模型。在深度学习中,数据通常被分为训练集和测试集两部分。我们用训练集让模型进行学习,然后用测试集评估模型的性能。对于时间序列模型,我们一般对一个时间序列进行预测,然后对另一个时间序列进行测试。比如,我把截止日期设为 2017 年 6 月 1 日,那么就会用在这个日期之前的时间训练模型,用这个日期之后的数据评估模型。
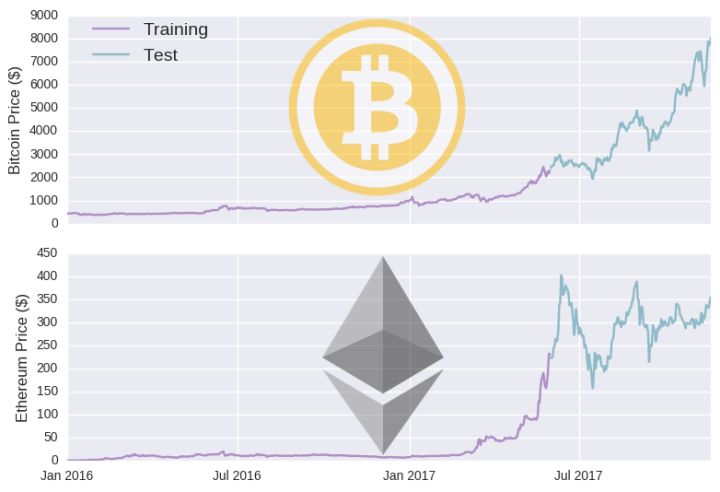
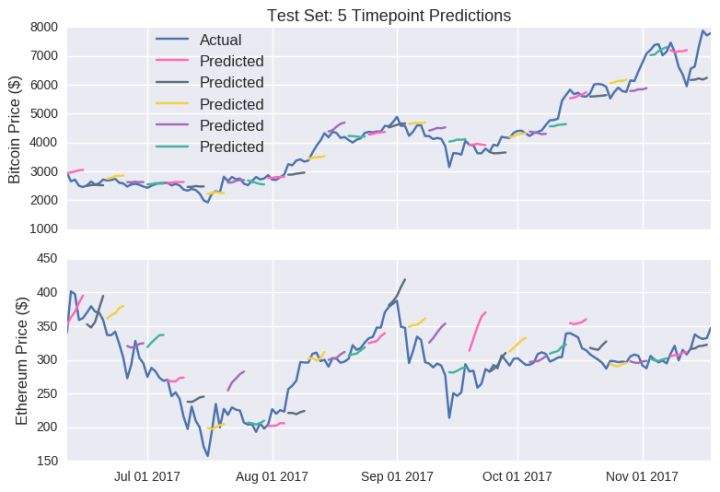
你可以看到训练时间大部分包含虚拟货币价格较低的时期。这样,训练数据或许无法代表测试数据,会损害模型泛化不可见数据的能力(你可以试着让数据更平稳些)。但干嘛让负面情况碍手碍脚呢?在使用我们的机器学习模型前,有必要讨论一个更简单些的模型。最基本的模型就是设定明天的价格等于今天的价格(我们称之为滞后模型)。我们在数学上以如下方式定义该模型:
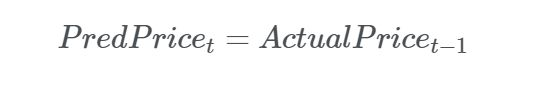
在互联网链接分析和金融股票市场中,当扩展一下这个简单的模型时,通常将价格当做随机游走(概念接近于布朗运动,是布朗运动的理想数学状态。指任何无规则行走者所带的守恒量都各自对应着一个扩散运输定律),那么在数学上可以将其进行如下定义:
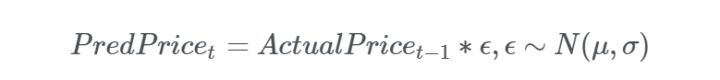
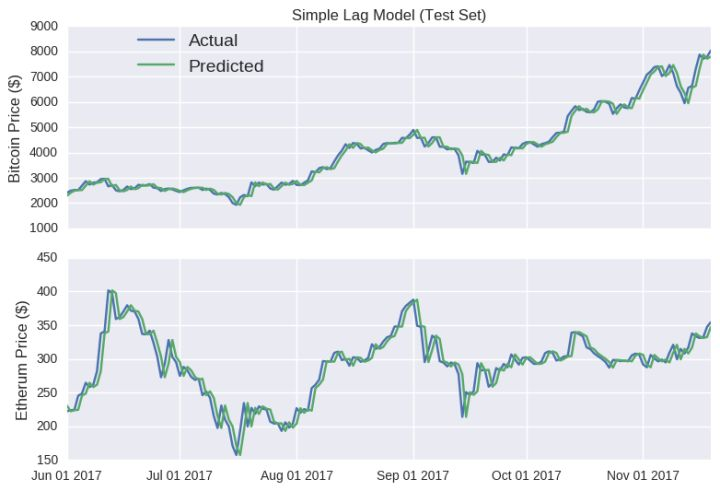
我们会从训练集中确定 μ 和 σ,将随机游走模型应用在比特币和以太坊的测试集上。
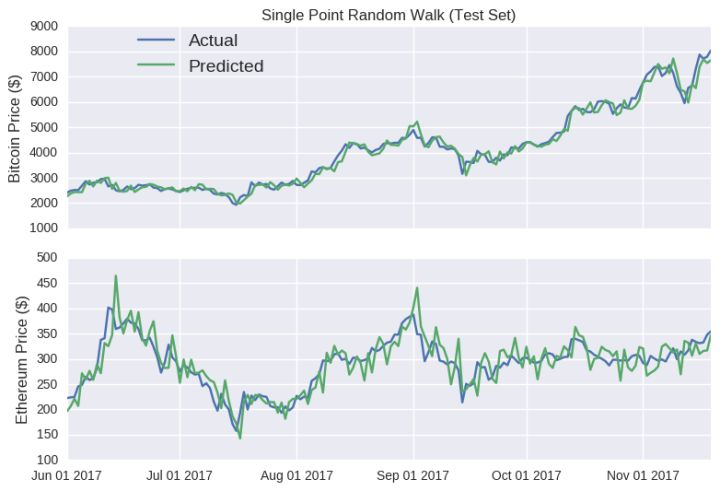
wow!看看这些预测线。除了少许部分扭曲,基本上紧贴每个虚拟货币的实际价格变动情况。模型甚至捕捉到了 6 月中旬和 8 月下旬的暴涨状况。然而正如另一篇预测比特币价格的博客中所说,只在某个点预测未来的模型常常会让人误以为它很准确,因为在接下来的预测中模型没有将误差因素考虑在内。不管误差大小如何,它在每个时间点本质上会被重置,因为输入模型的是真实价格。比特币的随机游走尤其具有误导性,因为y轴的值可以很大,这让预测线看起来很平滑。
不幸的是,单点预测在评估时序模型中相当普遍。所以通过多点预测衡量模型准确度是个更好的做法。这样以来,之前预测的误差不会被重置,而是会被计算入接下来的预测中。这样,我们在数学上这样定义:
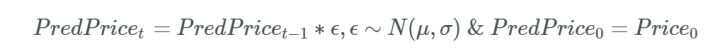
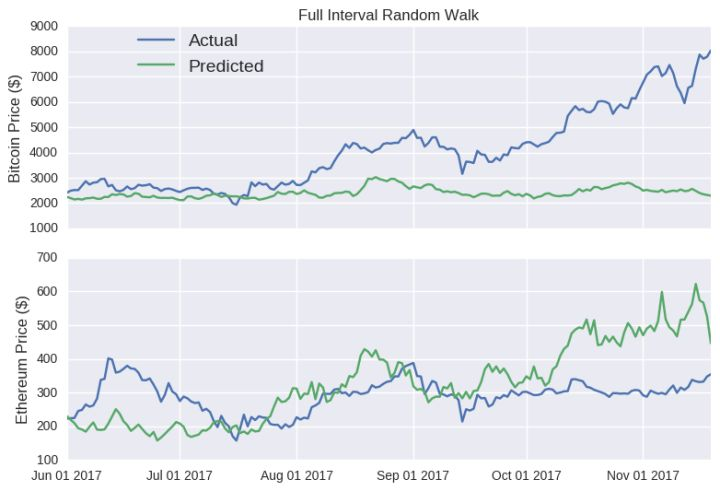
模型的预测对随机种子极其敏感。对于以太坊的预测,我选了一个完整的看起来正常的区间随机游走(如下图)。你也可以在 Jupyter Notebook 中处理下面这些随机种子值,看看情况有多糟糕。
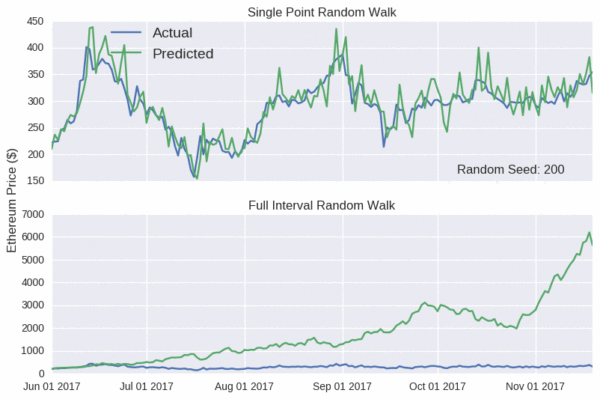
注意单点随机游走会一直看似十分准确,即便背后并无真实实体。因此,希望你对任何博客中预测出的货币价格都保持怀疑态度。想买虚拟货币的朋友别被市场预测报告给轻易忽悠了。
长短期记忆模型(LSTM)
在前文说过,我们会用长短期记忆模型。但我们没必要从头开始自己搭建一个模型,现在有不少应用了多种深度学习算法的开源框架可供我们使用(比如 TensorFlow,Keras,PyTorch等)。我选的是 Keras,因为我发现它很适合像我这种水平不牛的人。如果你对 Keras 不熟悉,可以看看我写的 这篇教程,或者其他人的教程都行。
我创建了一个新的数据框架叫做 model_data。我将移出了之前的一些列(开盘价,每日最高价和最低价),重新表示了一些新列。Close_off_high 代表了当天收盘价和最高价之间的差额,其中值 -1 和 1 表示当天收盘价分别等于最低价和最高价。volatility列是指被开盘价分开的最低价和最高价的不同。你可能也注意到model_data是按照最早时间到最近时间的顺序排列的。我们实际上并不需要日期列了,因为不需要再向模型中输入这项信息。
model_data.head()
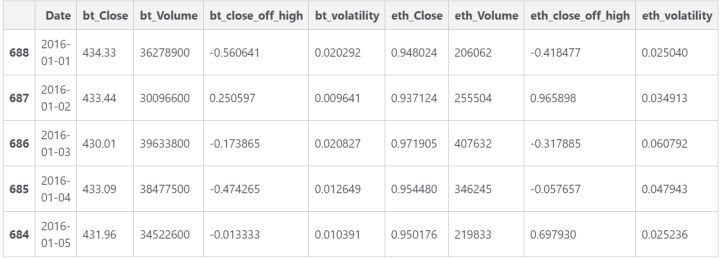
我们的长短期记忆模型会使用之前的数据(比特币和以太坊的都有)预测每种货币第二天的收盘价。我们必须决定模型需要获取之前多少天的数据。这个随意,我选择的是 10 天,因为 10 是个很好的整数。我们创建一个小型数据框架,包含连续 10 天的数据(称为窗口),所以第一个窗口会包含训练集的第 0-9 行(Python 是零索引),第二个窗口是 1-10 行,以此类推。选择一个小型窗口意味着我们可以将更多的窗口输入到模型中。下降趋势是指模型可能没有足够的信息来检测复杂的长期行为(如果出现这种情况)。
深度学习模型不喜欢输入数据大幅变动。仔细看这些数据列,一些值介乎 -1 和 1 之间,而其它值则是百万规模。我们需要将数据正常化,所以我们的输入数据比较一致。通常,你会想让值在 -1 和 1 之间。Off_high 列和 volatility 列和之前一样好。对于剩余的列,和其它人的做法一样,我们会将输入数据正常化为窗口中的第一个值。
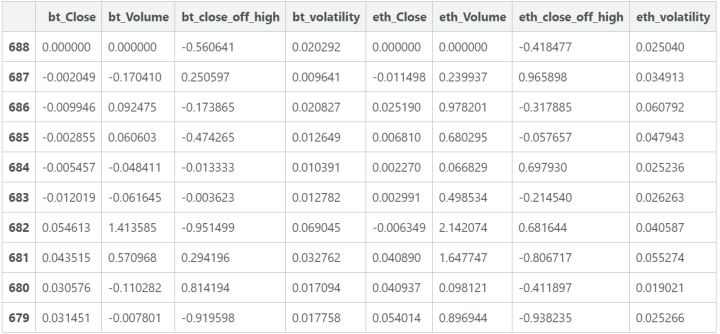
这个表格表示我们的长短期记忆模型输入的一个例子(我们实际上有几百个类似的表格)。我们已经将一些列正常化,因此它们的值在第一个时间点都等于0,所以我们的目标是预测在该时间点的价格变化情况。我们现在准备好搭建LSTM模型了。用Keras搭建模型非常快速,将几个部件放在一起就行。我曾详细写了篇教程,可以参考。
# import the relevant Keras modules
from keras.models import Sequential
from keras.layers import Activation, Dense
from keras.layers import LSTM
from keras.layers import Dropout
def build_model(inputs, output_size, neurons, activ_func = "linear",
dropout =0.25, loss="mae", optimizer="adam"):
model = Sequential()
model.add(LSTM(neurons, input_shape=(inputs.shape[1], inputs.shape[2])))
model.add(Dropout(dropout))
model.add(Dense(units=output_size))
model.add(Activation(activ_func))
model.compile(loss=loss, optimizer=optimizer)
return model
因而,build_model 函数构建了一个空的模型(model = Sequential),添加了一个 LSTM层。为了适应我们的输入(n x m 表格,其中 n 和 m 表示时间点/行和列的数值),该 LSTM层经过了调整。函数还包含神经网络的一些特征,如 dropout 和激活函数等。现在,我们只需指明放入 LSTM 层中的神经元的数量(我选择的是 20 个),以及训练模型用的数据数量。
# random seed for reproducibility
np.random.seed(202)
# initialise model architecture
eth_model = build_model(LSTM_training_inputs, output_size=1, neurons = 20)
# model output is next price normalised to 10th previous closing price
LSTM_training_outputs = (training_set['eth_Close'][window_len:].values/training_set['eth_Close'][:-window_len].values)-1
# train model on data
# note: eth_history contains information on the training error per epoch
eth_history = eth_model.fit(LSTM_training_inputs, LSTM_training_outputs,
epochs=50, batch_size=1, verbose=2, shuffle=True)
#eth_preds = np.loadtxt('eth_preds.txt')
Epoch 50/50
6s - loss: 0.0625
现在我们已经搭建好了一个可以预测第二天以太坊收盘价的 LSTM 模型。我们看看它性能如何。我们首先用训练集检测它的性能(即 2017 年 6 月之前的数据)。代码下方的数字表示在第 50 次训练迭代(或 epoch)后,模型在训练集上的平均绝对误差。我们不看其中的变化了,我们可以看看模型输出的每天收盘价。
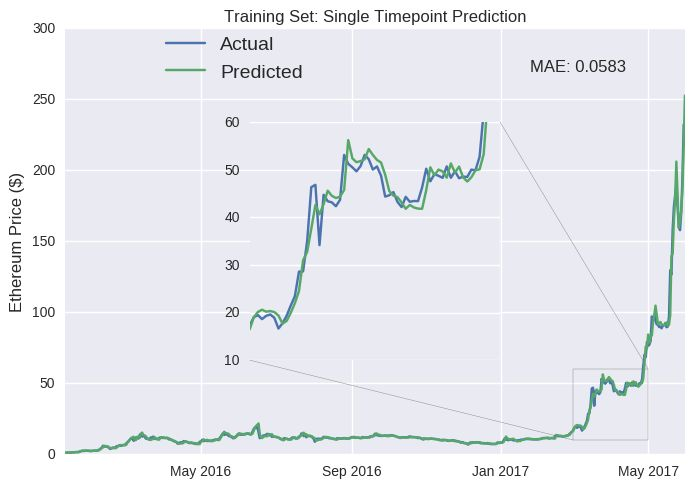
对于模型如此高的准确率,我们不应感到太惊讶。模型能获取其误差的来源,然后自行修正。实际上,要想实现几乎零误差训练也不是很难。只需添加几百个神经元训练上几千个 epoch 就行。我们更感兴趣的是模型在测试集上的表现,因为这代表了模型面临新数据时的预测效果。
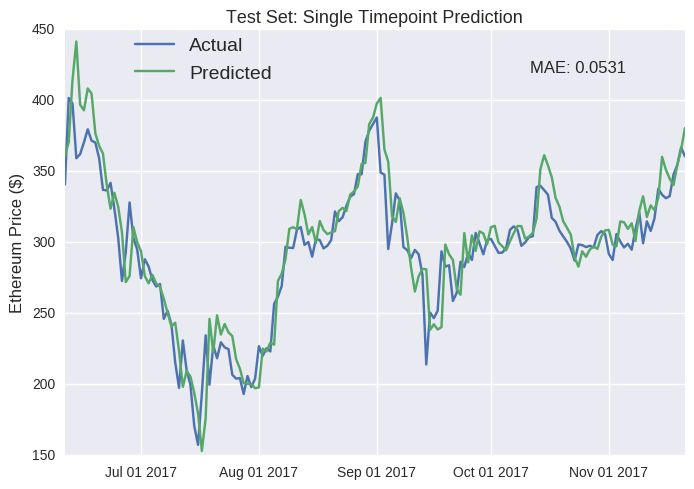
撇开我们上文说的单点预测的误导性不谈,我们搭建的这个 LSTM 模型好像在新数据上表现的还不错。最明显的错误之处是它没能检测出价格突然增高后不可避免的要下降的情况(比如 6 月中旬和 10 月)。实际上,这是个持续性的错误,只是在这些峰值处更加明显。预测的价格和第二天的价格基本上一致(例如七月中旬的价格下降)。另外,模型似乎系统性地高估了以太坊的未来价格,因为预测线始终在实际价格线的上方。我怀疑这是因为训练集代表的时间段正值以太坊价格飞涨,因此模型预估这个趋势会一直持续。我们也可以针对比特币的测试集,搭建一个相同的 LSTM 模型预测比特币的价格,如下图所示:
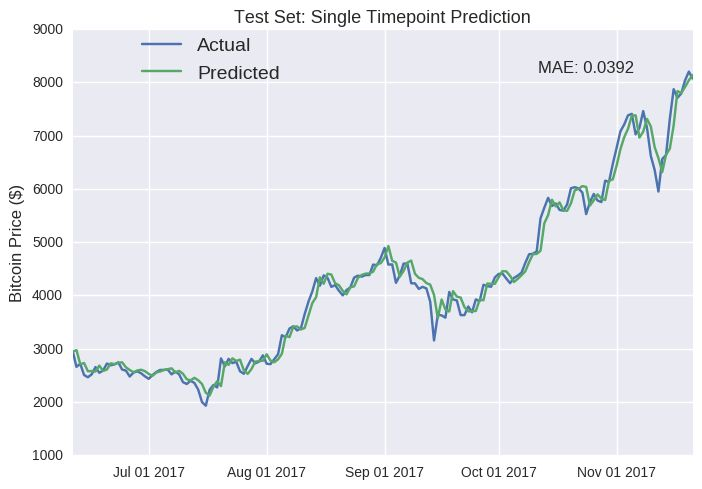
点击这里获取全部代码。
我前面强调过,单点预测具有误导性。那么在仔细看看,你会注意到预测值有规律地反应了之前的值(如十月份)。我们的深度学习 LSTM 模型在部分地方再生了一个顺序为 p 的自回归模型,在这些地方,未来的值就是之前 p 值的加权和。我们可以在数学上将自回归模型进行如下定义:
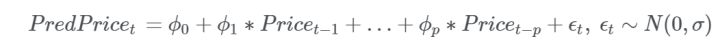
这样以来模型的预测很明显不如单点预测那么令人满意(令人满意可能就...)。但是,我很高兴这个模型返回了一些很细微的举动(例如以太坊这张图的第二条线)。模型没有简单地预测价格朝同一个方向发展,所以我们有理由对模型持乐观态度。
再回到单点预测部分,我们的深度学习神经网络看起来还不错,但是无聊的随机游走模型也很棒。和随机游走模型一样,LSTM 模型对选择的随机种子非常敏感(模型权重开始时随机设置)。所以,如果我们想比较这两个模型的话,我们可以让每个模型运行多次,比如 25 次,对模型误差有个估计。这个误差可以计算为测试集中实际收盘价和预测收盘价之间的差额。
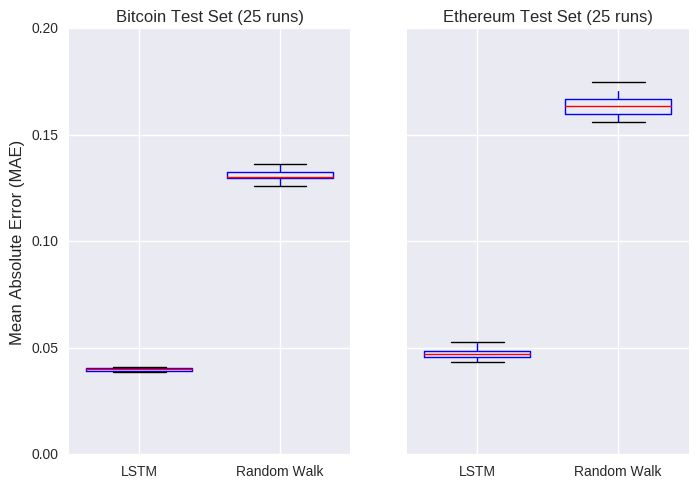
或许 AI 还是值得夸奖一番的!!这些图标显示了每个模型迭代 25 次后,在测试集上的误差。LSTM 模型对比特币和以太坊的预测误差分别为 4% 和 5% ,彻底碾压随机游走模型。
只想打败随机游走模型太 low 了。我们可以将 LSTM 模型和更多的时序模型进行比较。比如自回归模型,ARIMA,加权平均法等。这个任务我们留给以后再做,你也可以自己试试。 再说一下,希望谈到用深度学习预测虚拟货币价格时,大家都能保持一个怀疑的态度,因为技术并不是完美的。
提醒:不应将本文视为投资建议,也希望大家不要轻易靠这种方法投资虚拟货币,本文只是分享我自己对于如何用深度学习技术预测虚拟货币价格的一个思路。理财有风险,投资需谨慎,有涨就有跌,请量力而行。
总结
我们收集了一些虚拟货币的数据,将其输入一个超酷的长短期记忆模型中。不幸的是,模型的预测几乎只是重复之前的值。我们怎样能让模型更完善些呢?
-
改变损失函数:平均绝对误差并不真的鼓励我们去冒险。例如,在绝对平方误差情况下,LSTM 模型会被迫将检测峰值视为更重要的事情。而且,更适合模型的损失函数会让模型不再那么保守。
-
抑制过于保守的自回归模型:这能激励深度学习算法去探索更有趣或更冒险的模型。这一步说起来容易,做起来难!
-
获取更多更好的数据:即便靠单单过去的价格就能很好地预测未来价格,我们还可以添加其它一些能提升模型预测能力的数据特征。这样,LSTM模型就不必只依赖过去的价格数据了,可能还能解锁更复杂的功能的。这一步可能是最值得尝试但也最难的部分。
如果你想自己从头创建一个LSTM模型,可以点击这里获取所有 Python 代码。
感谢阅读!
