


前言
在上一篇文章中我们介绍了线程池的使用,那么现在我们有个疑问:线程池到底是怎么实现的?毕竟好奇是人类的天性。那我们今天就来看看吧,扒开 他的源码,一探究竟。
1. 从 Demo 入手
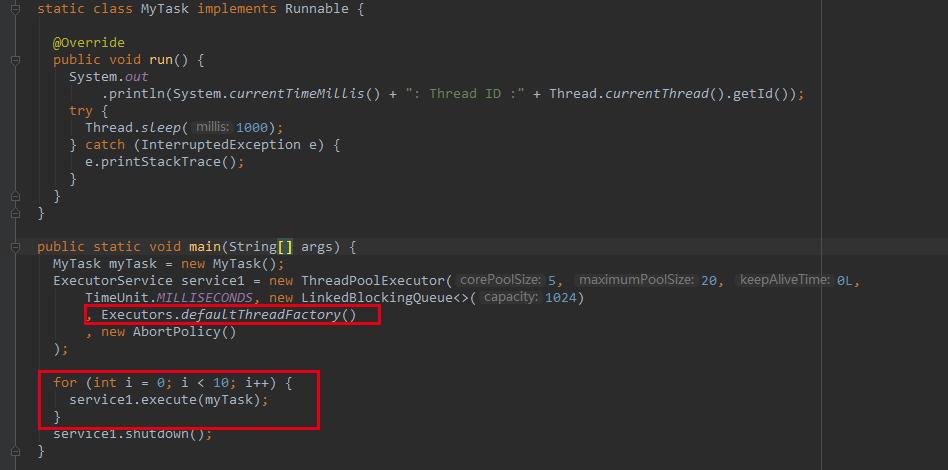
上图是个最简单的demo,我们从这个 demo 开始看源码,首先一步一步来看。
首先我们手动创建了线程池,使用了有数量限制的阻塞队列,使用了线程池工厂提供的默认线程工厂,和一个默认的拒绝策略,我们看看默认的线程工厂是如何创建的?
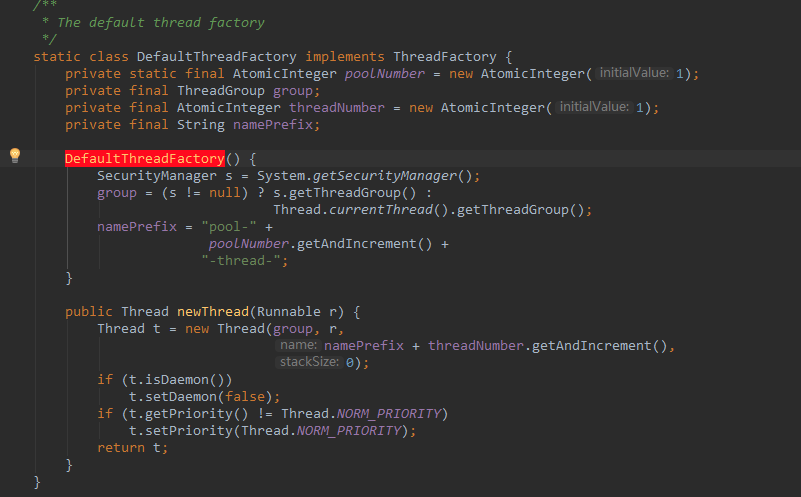
默认的线程工厂从当前线程中获取线程组,设置了默认的线程名字前缀 pool-xxx-thread-xxx,强制设置为非守护线程,强制设置为默认优先级。
然后我们看看ThreadPoolExecutor 的构造方法:

没有什么特殊的东西,主要是一些判断。
好了,那么我们看看 execute 方法是如何实现的。
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
// c = -536870911
int c = ctl.get();
// 工作线程数量小于核心线程池设定数,则创建线程。
if (workerCountOf(c) < corePoolSize) {
// 如果添加成功则直接返回
if (addWorker(command, true))
return;
// 否则再次获取活动线程数量
c = ctl.get();
}
// 如果线程池正在运行,并且添加进队列成功
if (isRunning(c) && workQueue.offer(command)) {
// 再次对线程池状态检查, 因为上面 addWorker 过了并且失败了,所以需要检查
int recheck = ctl.get();
// 如果状态不是运行状态,且从队列删除该任务成功并尝试停止线程池
if (! isRunning(recheck) && remove(command))
// 拒绝任务
reject(command);
// 如果当前工作线程数量为0(线程池已关闭),则添加一个 null 到队列中
else if (workerCountOf(recheck) == 0)
// 添加个空的任务
addWorker(null, false);
}
// 如果添加队列失败,则创建一个任务线程,如果失败,则拒绝
else if (!addWorker(command, false))
// 拒绝
reject(command);
}
}
首先,空判断。
然后判断,如果正在工作的线程小于设置的核心线程,则创建线程并返回,如果正在工作的线程数量大于等于核心线程数量,则试图将任务放入队列,如果失败,则尝试创建一个 maximumPoolSize 的任务。注意,在remove 方法中,该方法已经试图停止线程池的运行。
从这段代码中,可以看到,最重要的方法就是 addWorker 和 workQueue.offer(command) 这段代码,一个是创建线程,一个是放入队列。后者就是将任务添加到阻塞队列中。
那么我们就看看 addWorker 方法。
2. addWorker 方法-----创建线程池
private boolean addWorker(Runnable firstTask, boolean core)
该方法很长,楼主说一下这个方法的两个参数,第一个参数为 Runnable 类型,表示线程池中某个线程的第一个任务,第二个参数是如果是 true,则创建 core 核心线程,如果是 false ,则创建 maximumPoolSize 线程。这两个线程的生命周期是不同的。
楼主截取该方法中最终的代码:
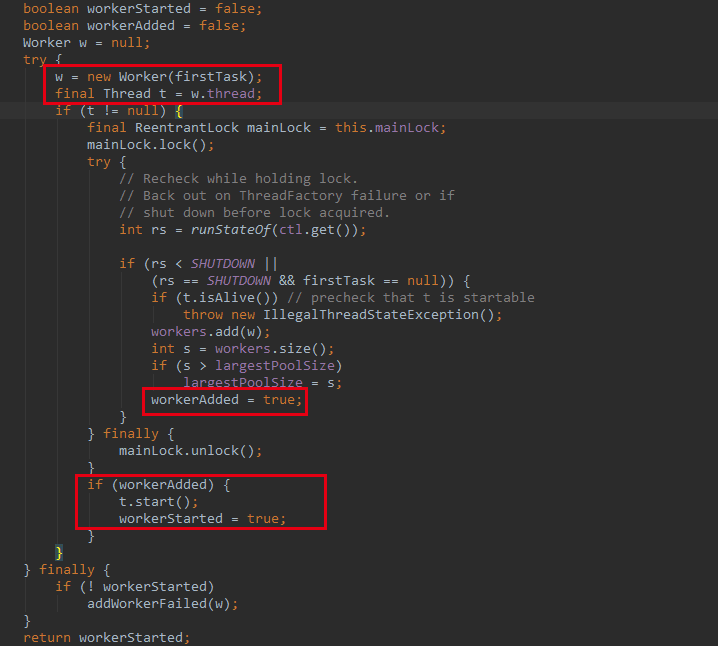
其中,在该方法中,创建一个 Worker 对象,该对象代理了任务对象,我们看看该类的构造方法:

通过线程工厂创建线程,注意,传递的是 this ,因此,在上面的代码中国,调用了 worker 对象的 thread 属性的 start 方法,实际上就是调用了该类的 run 方法。那么改类的 run 方法是怎么实现的呢?

调用了自身的 runWorker 方法。这个方法非常的重要。
3. Worker.runWorker(Worker w) 方法-------线程池的最核心方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}
首先说该方法的主要逻辑:
- 首先执行 firstTask 的 run 方法。
- 然后循环获取阻塞队列中的任务,并调用他们的 run 方法。
- 如果线程池中的任务异常,就抛出异常并停止运行线程池。
这个方法可以说就是线程池的核心,在最开始的设定的核心任务数都是直接调用 start 方法启动线程的,启动之后,这个线程并不关闭,而是一直在阻塞队列上等待,如果有任务就执行任务的run 方法,而不是 start 方法,这点很重要。
而该方法中有几个注意的地方就是线程池留给我们扩展的,在执行任务之前,会执行 beforeExecute 方法,该方法默认为空,我们可以实现该方法,在任务执行结束后,在 finally 块中有 afterExecute 方法,同样也是空的,我们可以扩展。
楼主看到这里的代码后,大为赞叹,Doug Lea 可以说神一般的人物。
那么,线程池还有一个方法, submit 是如何实现的呢?其实核心逻辑也是 runWorker 方法,不然楼主也不会说这个方法是线程池的核心。
那我们看看 submit 方法是如何实现的。
4. submit 方法实现原理。
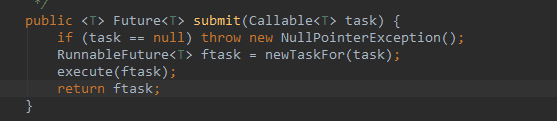
该方法最终也是走 execute 方法的,因此逻辑基本相同,不同的是什么呢?我们看看。我们看到,第二行代码创建了 一个 RunnableFuture 对象,RunnableFuture 是一个接口,具体的实现是什么呢?我们看看:

FutureTask 对象,该对象也是一个线程对象:
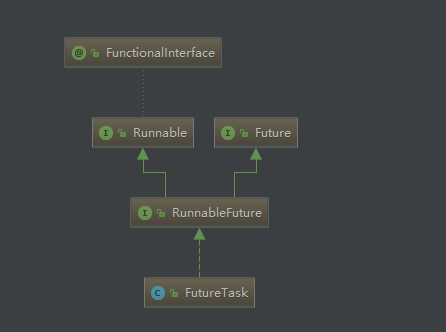
那我们就看看该方法的 run 方法。
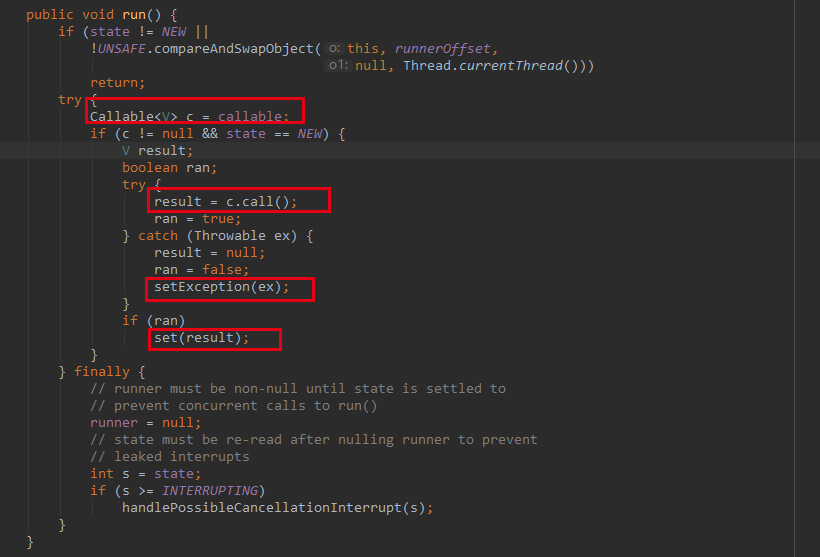
该方法核心逻辑楼主已经框起来了,其中调用了 call 方法,返回一个返回值,并在set 方法中,将返回值设置在一个变量中,如果是异常,则将异常设置在变量中。我们看看set方法:

该方法通过CAS将任务状态状态从new变成 COMPLETING,然后,设置 outcome 变量,也就是返回值。最后,调用 finishCompletion 方法,完成一些变量的清理工作。
那么,如果从submit 中获得返回值呢?这要看get方法:
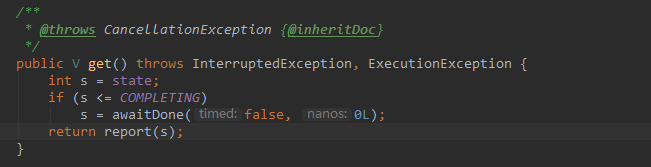
该方法会判断状态,如果状态还没有完成,那么就调用 awaitDone 方法等待,如果完成了,调用 report 返回值结果。

看见了刚刚设置的 outcome 变量,如果状态正常,则直接返回,如果状态为取消,则抛出异常,其余情况也抛出异常。
我们回到 awaitDone 方法,看看该方法如何等待的。
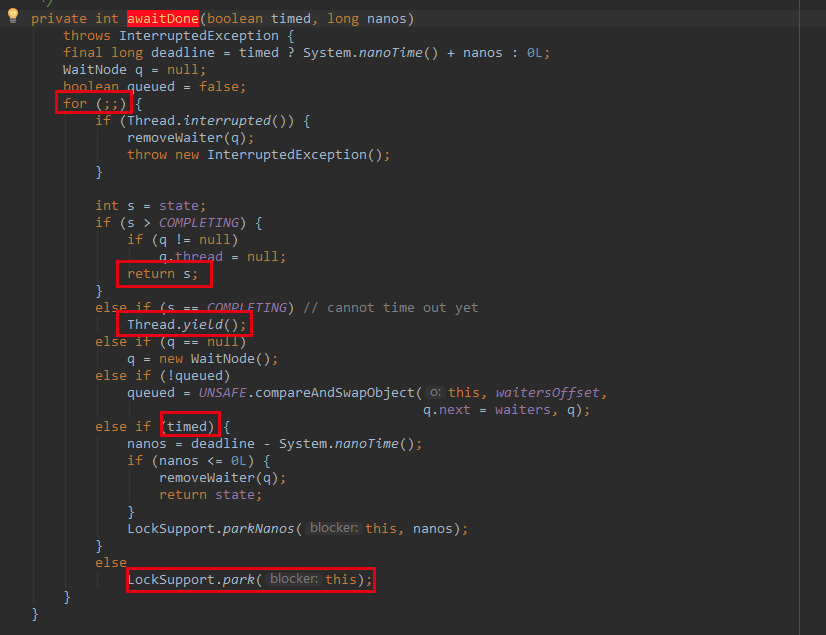
该方法有一个死循环,直到有一个确定的状态返回,如果状态大于 COMPLETING ,也就是 成功了,就返回该状态,如果正在进行中,则让出CPU时间片进行等待。如果都不是,则让该线程阻塞等待。在哪里唤醒呢?在 finishCompletion 方法中会唤醒该线程。
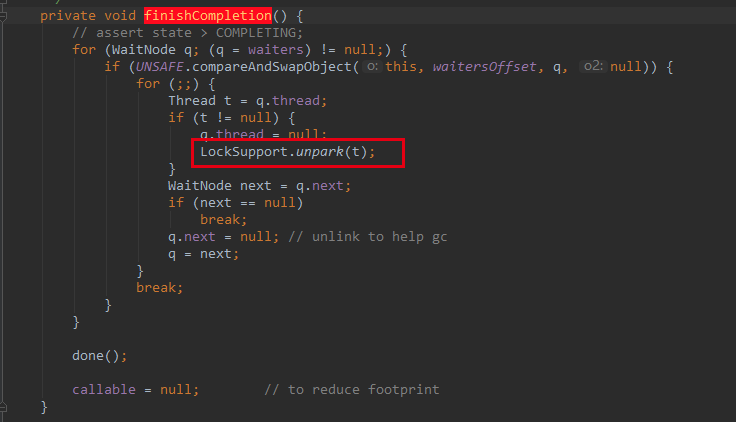
该方法循环了等待线程链表的链表,并唤醒链表中的每个线程。
还有一个需要的注意的地方就是,在任务执行完毕会执行 done 方法,JDK 默认是空的,我们可以扩展该方法。比如 Spring 的并发包 org.springframework.util.concurrent 就有2个类重写了该方法。
5. 总结
好了,到这里,线程池的基本实现原理我们知道了,也解开了楼主一直以来的疑惑,可以说,线程池的核心方法就是 runWorker 方法 配合 阻塞队列,当线程启动后,就从队列中取出队列中的任务,执行任务的 run 方法。可以说设计的非常巧妙。而回调线程 callback 也是通过该方法,JDK 封装了 FutureTask 类来执行他们的 call 方法。
good luck!!!!
