

去年苹果的最新产品 iPhone X 最受热议的莫过于全新的解锁功能——取代了 TouchID 的FaceID。
Apple 已经制造出了全面屏手机(虽然是备受吐槽和跟风的“刘海屏”),因此也得开发出与之对应能简单迅速地解锁手机的方法。
正当 Apple 的竞争者们还在调整指纹传感器的位置时,Apple 革新了手机解锁方式——你只需要看着手机就可以了。通过一个小巧先进的前置深度摄像头,iPhone X 可以建立一张用户脸部的 3D 图像。此外,红外摄像头也会拍摄一张用户脸部的照片以适应不同环境下光线和颜色的变化。通过深度学习,手机可以学习用户的脸部,并在每次用户举起手机时辨识出来。令人惊讶的是,Apple 宣称这项技术比 TouchID 更加安全,其错误率仅有百万分之一。

随着苹果手机推出的这项革命性技术,市面上也出现了越来越多的采用人脸解锁技术的手机,面部解锁俨然成为新的技术潮流。

那么 iPhone X 的 FaceID 背后都有哪些秘密?作为普通的开发者,我们自己能实现它吗?罗马大学人工智能专业的一位叫 Norman Di Palo 的小伙最近就不断琢磨了这个问题,最后经过一番探索后,借助深度学习技术和 Python 编程,逆向破解了这项技术。下面我们听他唠唠怎么做到的。
我(作者Norman Di Palo——译者注)对 Apple 实现 FaceID 的技术十分感兴趣——一切都是在设备上运行的,被用户脸部稍微训练一下就能在每次手机被举起时顺利地运行了。
我的关注点在于,怎样利用深度学习实现这个过程以及如何优化每个步骤。在本文,我将展示如何使用 Keras 实现类似 FaceID 的算法。我会详细解释我作出的各种架构决策并展示最终的实验结果。我使用了 Kinect,一个很流行的 RGB 和深度摄像头,它输出的结果和 iPhone X 上的前置摄像头很相似,只是设备体积要大一些。倒杯茶坐下来歇会儿,下面我们一起逆向破解 Apple 改变行业趋势的这项新功能。

理解FaceID
第一步是分析 FaceID 是怎样在 iPhone X 上工作的。iPhone X 的白皮书可以帮助我们理解 FaceID 的基本工作原理。使用 TouchID 的时候,用户需要先数次触碰传感器以记录指纹。 15 到 20 次触碰后,TouchID 就设置完成了。FaceID 也类似,用户需要先录入面部数据。过程很简单:用户只需和平时一样正向看着手机,之后缓慢转动头部以完成全方位采集。
就这么简单,FaceID 已经设置好,可以用来解锁手机了。录入过程的惊人速度可以告诉我们很多关于其背后算法的信息。比如,驱动 FaceID 的神经网络并不是只是在进行分类,我接下来会进一步解释。

对一个神经网络来说,分类意味着学习预测它看到的脸是否是用户的。因此,简单来说,它需要利用训练数据预测“是”或“否”。但和其他很多深度学习用例不同,这个方法在这里行不通。首先,神经网络需要用从用户面部新获得的数据从头开始训练模型,这需要大量的时间、计算资源和不同的人脸作为训练数据以获得反例(在迁移学习和对一个已经训练好的网络进行微调的情况下,变化是很小的)。
不仅如此,这种方法使 Apple 无法“离线”训练一个更为复杂的网络,比如先在实验室里训练网络,再把训练好的、可以直接使用的网络放到手机里。因此,我认为 FaceID 是利用了一个被 Apple“离线”训练好的类似孪生网络的卷积神经网络,将人脸映射到低维的潜在空间,再利用对比损失将不同人脸的距离最大化。这样,你就得到了一个可以进行一次性学习的架构,Apple 的 Keynote 里简要提到了这一点。我知道,可能有些看官会对很多名词感到陌生;别急,继续读下去,我会一步步解释的。

神经网络:从人脸到数字
孪生神经网络是由两个相同的神经网络组成的,这两个网络的权重也完全一样。这个架构可以计算特定的数据类型之间的距离,比如图像。你让数据通过孪生网络(或者分两步让数据通过同一个网络),网络就会将其映射到一个低维的特征空间,比如一个n维的数组,你再训练网络,使映射能够让不同类别的数据离得越远越好,相同类别的数据离得越近越好。长期来看,神经网络会学着提取最有意义的特征,将其压缩成一个数组,并建立一个有意义的映射。为了能更直观的理解,想象你需要用一个很小的向量来描述狗的品种,这样相似的狗的向量会更相近。你也许会用一个值表示狗的皮毛颜色,一个值表示狗的体型大小,另一个值表示毛发长度,等等。这样,相似的狗就会有相似的向量。很聪明,不是吗?孪生神经网络就可以替你做这件事,就像一个自编码器。
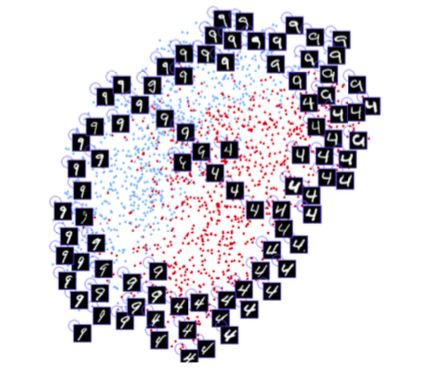
上面这幅图出自 Yann LeCun 参与发表的一篇论文,神经网络可以学习数字之间的相似性,并以 2 维为它们自动分类。这样的技术也可以应用到人脸数据上。
利用这个技术,我们可以利用大量的人脸训练出一个可以识别相似人脸的架构。只要有足够的预算和算力(就像 Apple 这样),神经网络的鲁棒性可以变得越来越强,可以处理双胞胎、对抗攻击等更困难的样本。这个方法的最后一个优点是什么呢?就是你有了一个即插即用的模型,它不需要进一步训练,只要在一开始录入时拍几张照片,计算出用户的脸在隐映射中的位置,就可以识别不同用户。(想象一下,像刚才说的那样,为一只新的狗建立代表它品种的向量,再把它储存到什么地方)此外,FaceID 可以在用户这一方适应眼镜、帽子、化妆等突然变化和面部毛发这样的缓慢变化——只需要在映射中添加参考的面部向量,再根据新的外貌进行计算。

用 Keras 实现 FaceID
对于所有的机器学习项目来说,首先需要的就是数据。建立我们自己的数据集需要时间和很多人的合作,是比较有挑战的。因此,我在网上找到了一个看起来很合适的 RGB-D 人脸数据集。这个数据集由一系列人们面朝不同方向,做出不同表情的 RGB-D 图片组成,就像 iPhone X 的用例一样。
如果想看到最后的实现,可以去我的 Github 库,里面有一个Jupyter Notebook。
另外,我在Colab Notebook也实验过,你可以试试看。
我基于 SqueezeNet 建立了一个卷积神经网络,输入是 RGB-D 人脸图像,即 4 通道图像,输出是两个嵌套之间的距离。神经网络是根据对比损失函数训练的,以减小同一个人的图像之间的距离,加大不同人的图像之间的距离。
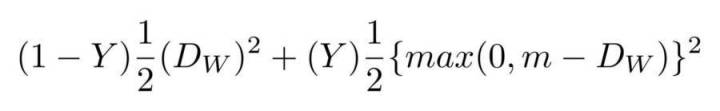
图为损失对比函数。
经过一些训练,神经网络能够把人脸映射为 128 维的数组,这样同一个人的图像会组在一起,并远离其他人的图像。这意味着,解锁的时候,神经网络只需要计算解锁时拍下的照片和录入时储存下来的照片的距离。如果这个距离低于某个阈值(阈值越小越安全),设备就解锁。
我利用 T-分布随机近邻嵌入将 128 维的嵌套空间在 2 维空间可视化。每个颜色代表了一个人:如你所见,神经网络学会了把这些照片紧密的组在一起。(在使用 T-分布随机近邻嵌入的情况下,集群之间的距离是无意义的)使用 PCA 降维算法时也会出现很有意思的图像。
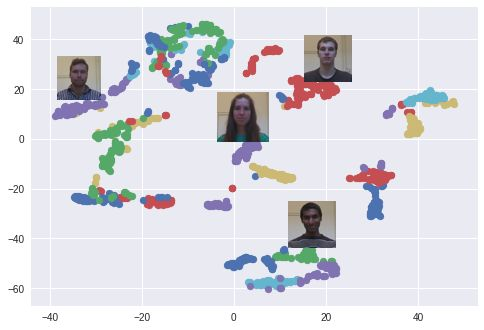
图为用t-SNE创建的嵌套空间中的人脸照片群集。
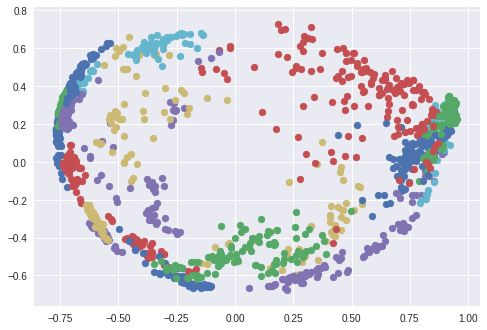
图为用PCA创建的嵌套空间中的人脸照片群集。
实验!启动!
我们现在可以模拟一个 FaceID 的循环,来看看这个模型运行得怎么样了:首先,录入用户的脸;之后是解锁,用户的脸应当可以成功解锁设备而其他人的脸则不行。如前所述,区别在于神经网络计算出来的试图解锁设备的脸和录入时的脸的距离是否小于某一个阈值。
我们先从录入开始:我从数据库中提取了一系列同一个人的照片并模拟了设置面部识别的过程。设备会计算每个姿态的嵌套,并储存在本地。

图为模拟FaceID录入人脸数据。

图为深度摄像头看到的人脸数据录入过程。
当同一个用户试图解锁设备时,同一个用户的不同姿态和表情的距离较低,平均大概在 0.3 左右。

图为嵌套空间中同一人物的脸部距离
而不同人的 RGB-D 图像的距离则平均有 1.1。

图为嵌套空间中不同人物的脸部距离
因此,将阈值设置在 0.4 左右就可以防止陌生人解锁你的设备了。
结语
在这篇博文中,我基于人脸嵌套和孪生卷积神经网络,借助 Keras 和 Python 实现了 FaceID 人脸解锁的概念验证。希望本文对你有所帮助和启发,相关的 Python 代码你也都可以在这里找到。
对于本文所用的 Keras 工具及其提供有哪些深度神经网络模块,可以看看我站的简明教程。
