


这篇文章也发在我的博客,欢迎围观😄
人工智能主要研究领域
摘自Russell & Norvig的经典教材《人工智能
自然语言处理(natural language processing)
知识表示(knowledge representation)
自动推理(automated reasoning)
机器学习(machine learning)
计算机视觉(computer vision)
机器人学 (robotics)
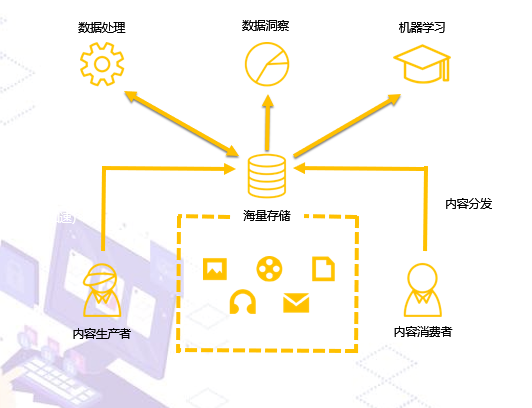
AI主要应用的生活场景
- 智能音箱一类的生活助手,主要是使用语音识别
- 图像识别,例如自动驾驶、AI加持的拍照算法、动态行为分析等
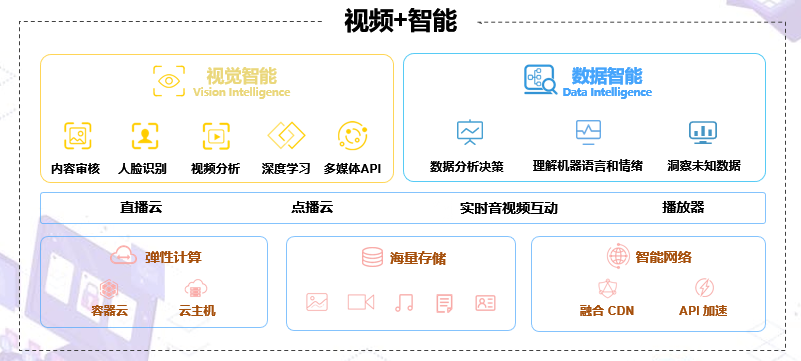
七牛云的AI应用
1. 视频上传后AI识别人脸
2. AI鉴黄、反暴恐

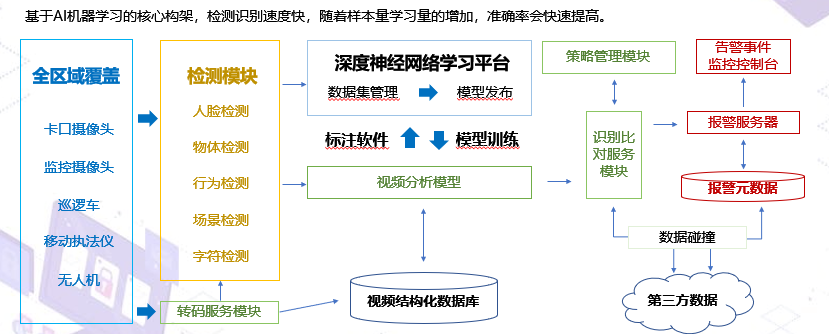
5. 对视频进行描述
6. 对视频进行分割定位
快速入门
给初学者的建议
- 不要等到掌握所有的相关数学知识再开始
矩阵/张量,特征值分解,行列式,范数...
概率分布,独立,贝叶斯,最大似然估计...
线性优化,梯度下降、牛顿法...
导数、偏微分,链式法则,矩阵求导...
信息论、数值计算...
- 不要收集过多的学习资料
- 动手X3
机器学习速览
机器学习是什么?
机器学习就是,利用学习算法,从数据中产生模型
Spam filters, Search ranking, Click through rate predict, Recommendations, Speech recognition,Machine translation, Face detection, Image classification......
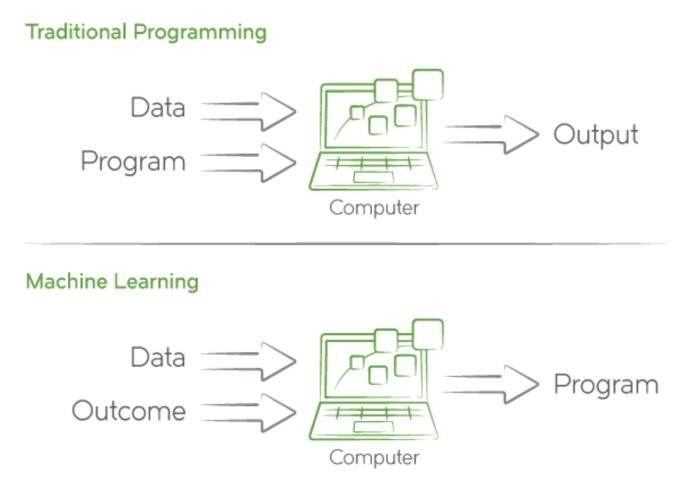
- 传统编程: 数据 + 程序 => 输出结果
- 机器学习: 数据 + 输出结果 ====> 学习模型
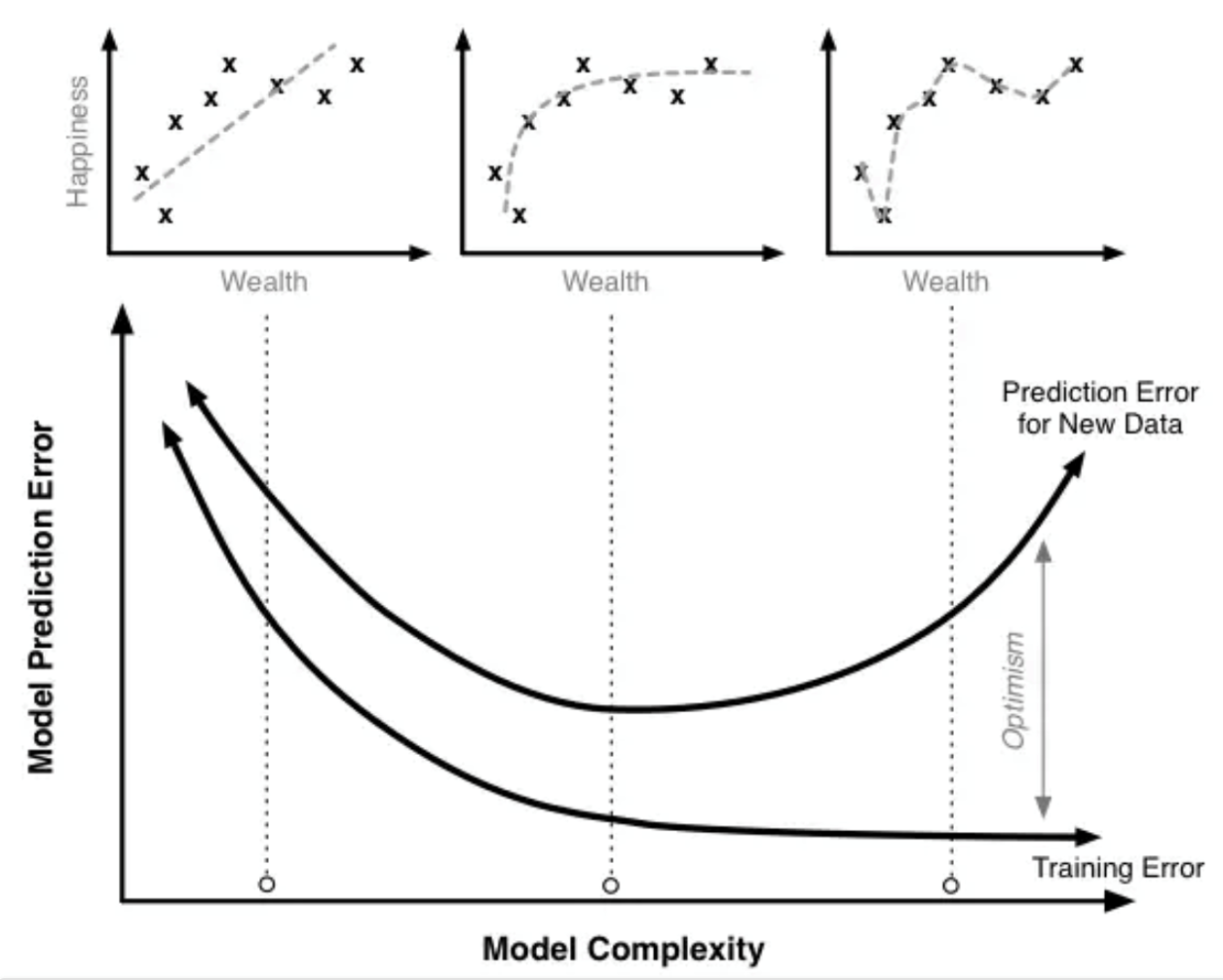
泛化性
对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E中学习。-- Tom M. Mitchell
如下图,虽然第三幅图没有偏差,但是对于未知的点的预测效果,没有图二好。这就是泛化性。
常见任务与算法
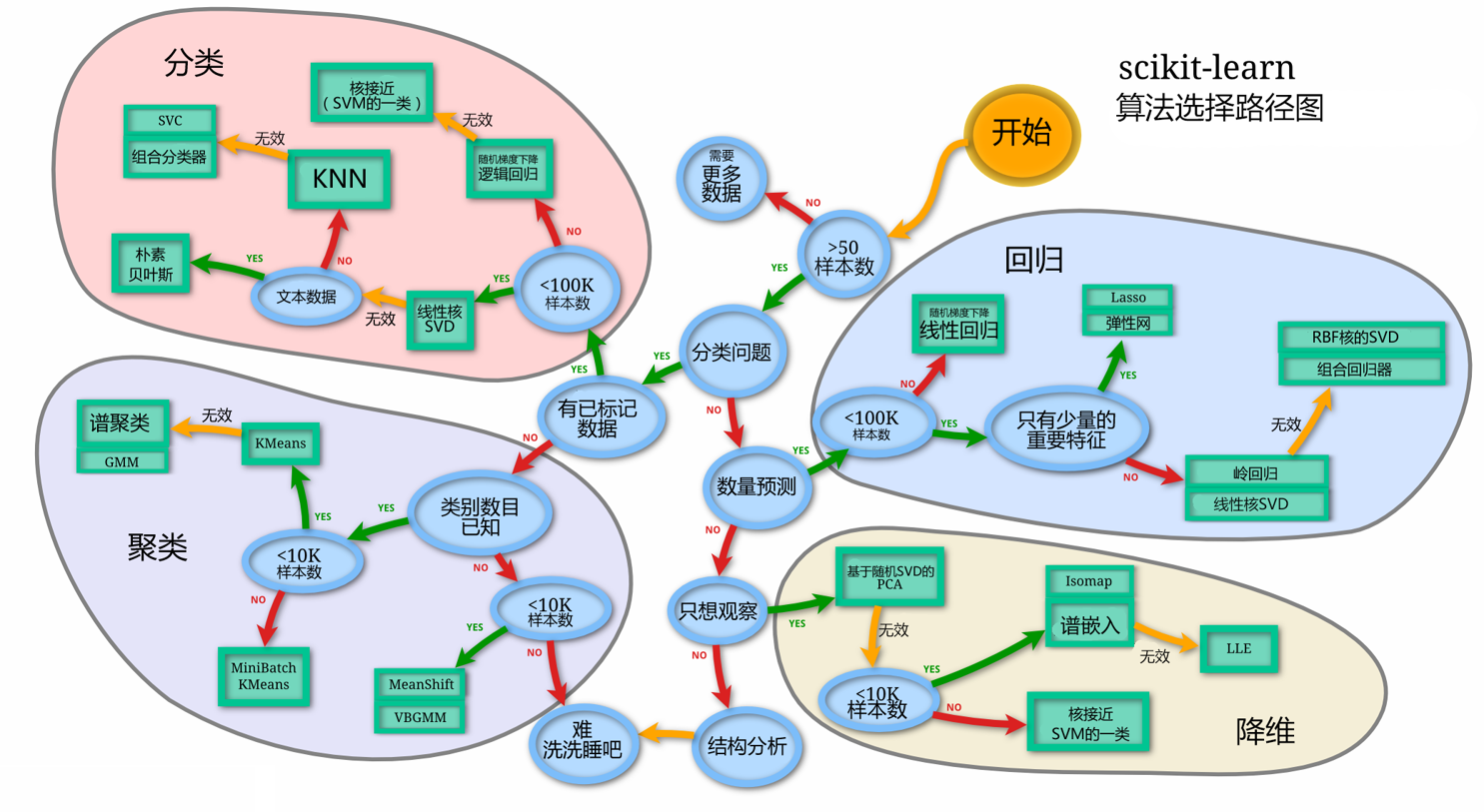
要针对具体学习问题进行
如果不针对某一具体的学习问题,则没有哪个算法比其他算法更高效
- 在某些问题上表现很好的学习算法,在另一些问题上却可能不尽如人意
- 学习算法的归纳偏好与问题是否匹配,往往起决定性作用
- 归纳偏好是学习算法本身所做的关于“什么样的模型更好”的假设
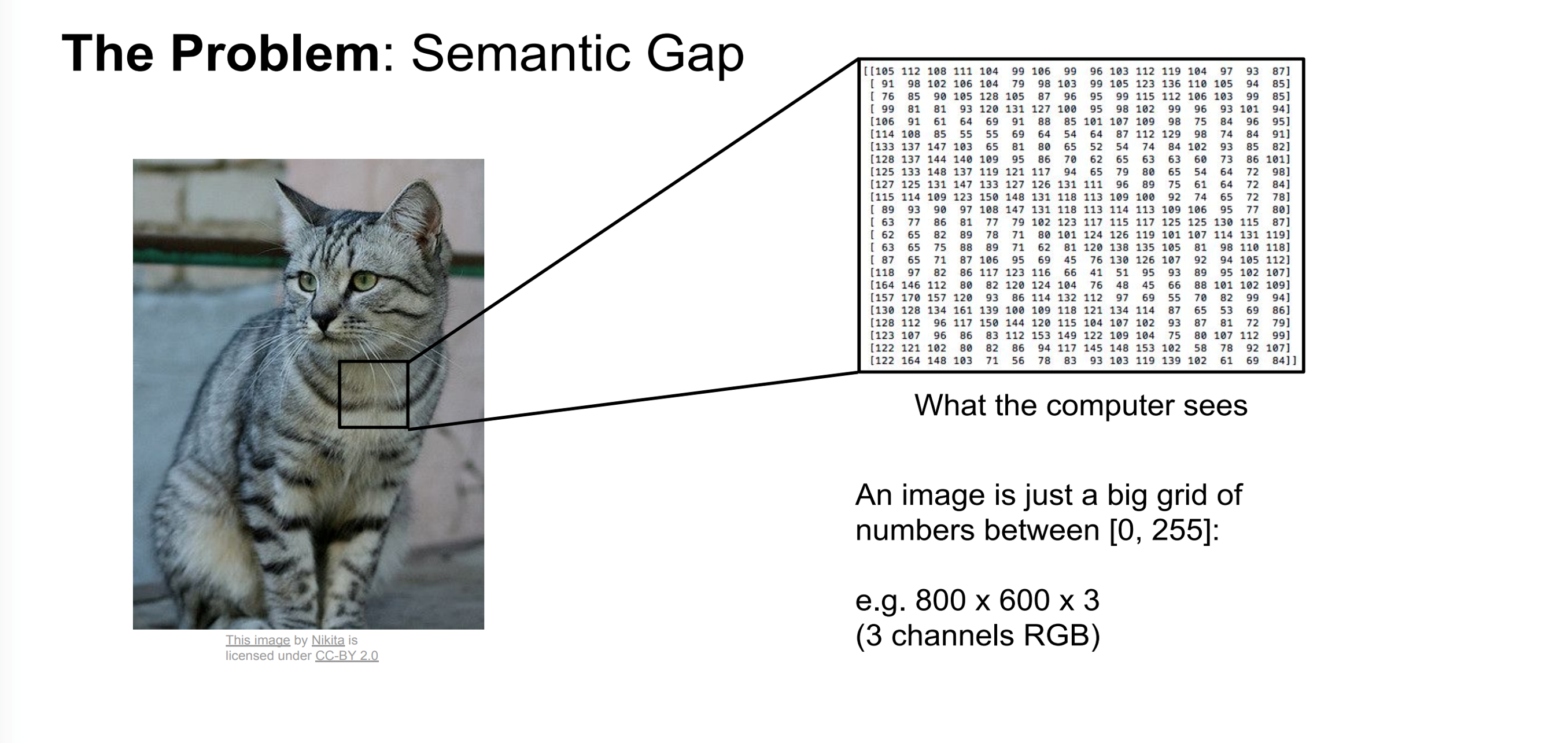
图像分类
人可以轻而易举进行图像分类,而机器不行,因为存在语义鸿沟。
如下图,人看到猫,计算机看到的是数字,计算机是语义这个概念的。
K近邻
K近邻就是K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。

换言之,给定一个训练数据集,我有一个新的实例,如果在数据中与该实例最邻近的K个实例,这些实例中大多数属于某一类,那么就判断该新的实例属于某一类。
缺点:
- 分类器必须记住所有训练数据并将其存储起来,以便于未来测试数据用于比较。这在存储空间上是低效的,数据集的大小很容易就以GB计。
- 对一个测试图像进行分类需要和所有训练图像作比较,算法计算资源耗费高。
线性分类器
由于K近邻存在明显缺点,所以我们需要一种更强大的方法来解决图像分类问题,此处可以用线性分类器
推荐学习资料
书籍
- 尼克《人工智能简史》
- Miroslav Kubat《机器学习导论》
- 周志华《机器学习》(西瓜书)
- Aurelien Geron《 Hands-on Machine Learning with Scikit-learn & Tensorflow 》
- Ian Goodfellow等《Deep Learning》(花书)
文章
- Getting Started With MachineLearning (all in one) by 梁劲 http://sina.lt/f3W8
- Machine learning 101 by Jason Mayes http://sina.lt/f3W3
课程
- 机器学习速成课程 https://developers.google.com/machine-learning/crash-course/
- 台湾大学李宏毅教授 http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
- 吴恩达教授 http://mooc.study.163.com/smartSpec/detail/1001319001.htm
- 斯坦福大学 cs231n http://cs231n.stanford.edu/
- 斯坦福大学 cs224n http://web.stanford.edu/class/cs224n/
其他
- scikit-learn Tutorials http://scikit-learn.org/stable/tutorial/index.html
- 机器学习术语表 https://developers.google.com/machine-learning/crash-course/glossary
Q&A
-
机器学习与社会科学的关系?
机器学习的发展很大程度上依托于社会科学,因为机器学习其实就是在探究心理学的理念以及大脑如何学习与思考,机器学习在发展过程中又会反哺社会科学。 -
中国人工智能领域处于领先位置,但为什么这方面的资料都是国外的?
中国是一个大国,社会行为方面的数据非常丰富。但是由于在计算机领域我们起步比较晚,所以在基础领域我们的研究并不深。这不仅仅是人工智能领域,包括整个计算机学科领域,我们很多的应用都是基于国外的基础理论。但是到实际应用领域,我们是非常领先的。例如人脸识别,中国人口众多,可供训练的样本非常丰富。中国在人工智能面临的挑战是如何将我们在应用中的经验和总结与基础理论相结合,推动学术发展。 -
是否建议初学者从深度学习开始入手学习?
不建议。应该系统学习基础概念及其关系,练习熟悉常用方法,再进一步学习。 -
Pytorch和TensorFlow两个机器学习库,选择哪个学习比较好?
两者皆可。TensorFlow是google出品,开源可以参考的比较多。目前来说做学术研究Pytorch多一些,做应用层面的TensorFlow多一些。 -
学习过程中应该如何实践?
学习在线课程,做这些课程的练习,同时要去论坛和别人交流,才能进步。或者参加天池等的一些人工智能竞赛,逼迫自己去实践。 -
AI开发用什么编程语言合适?
虽然python有很多的库,而且主流框架很多都使用Pythen的接口。但是只会Pyhton不够,七牛AI开发过程中使用了包括C++、GO等编程语言。 -
是否有必要看学术论文?
有必要。现在一项技术从科研到落地的时间特别短,紧跟最新的科研成果很有必要。 -
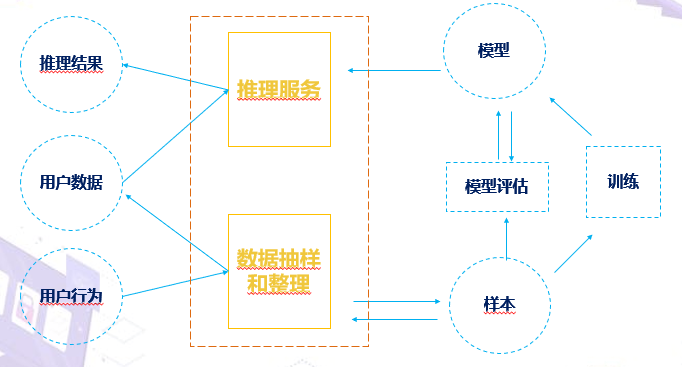
AI开发过程
收集源数据--抽样、整理生成样本--放入计算实体训练(过程中做超参数调试)--形成模型(评估模型是否满足需求,通过另外一批样本测试)--满足则上线
直播回顾
附上直播回顾链接:
一堂课掌握AI自学路径图(上)
一堂课掌握AI自学路径图(下)
感谢各位看官,欢迎批评指正😄