

前段时间我们分享了怎么免费用谷歌的 GPU 训练机器学习模型,详情戳这里。
这次我们又有了新的薅羊毛机会:通过 Kaggle Kernels 免费使用英伟达 GPU!
什么是 Kaggle Kernels?
可能有些朋友不是很熟悉 Kaggle Kernels,但 Kaggle 应该知道,至少搞数据科学和机器学习的会听说过 Kaggle 挑战赛。Kaggle 是一个用来从事数据科学研究或分享数据科学知识的平台从 Kaggle 上我们不仅能练习数据科学,还能从 Kaggle 社区中学到很多知识。
而 Kaggle 的产品 Kaggle Kernels 相当于一个内置于浏览器的 Jupyter Notebooks,一切运行都在你眼前呈现,由你自由支配。一句话:Kaggle Kernels 就是一个能在浏览器中运行 Jupyter Notebooks 的免费平台。
也就是说,只要有网络有浏览器,你随时随地都能在你的浏览器上拥有 Jupyter Notebook 环境,不用再自己设置本地环境。
由于 Kaggle Kernels 的处理能力来自云端服务器,而不是本地机器,所以我们能在不怎么消耗笔记本电量的情况下,在上面完成很多数据科学和机器学习工作。
在 Kaggle 上注册一个账户后,就可以选择一个自己想要使用的数据集,点击几下就能启动一个新的 Kernel,也就是 Notebook。
我们用的数据集都预先加载到了该 Kernel 上,所以把数据集导入机器、再等待数据集输入模型中这样一套耗时的流程,我们就不用再做了。
具体如何使用 Kaggle Kernels,可以参考这篇教程。
最近 Kaggle 又推出了一个大福利:用户通过 Kaggle Kernels 可以免费使用 NVidia K80 GPU !
经过 Kaggle 测试后显示,使用 GPU 后能让你训练深度学习模型的速度提高 12.5 倍。
以使用 ASL Alphabet 数据集训练模型为例,在 Kaggle Kernels 上用 GPU 的总训练时间为 994 秒,而此前用 CPU 的总训练时间达 13,419 秒。直接让你训练模型的时间缩短为原来的 12 分之一。 当然在自己实际使用中,模型训练时间缩短多长会涉及多个因素,比如模型架构、批次大小、输入流水线的复杂程度等等。不管怎么说,我们现在可以通过 Kaggle Kernels 免费使用 GPU 了!
如何在 Kaggle Kernels 上使用 GPU
Kaggle 官网上分享了怎样能在 Kaggle Kernels 上使用 GPU,并展示了示例代码:
添加 GPU
我们首先打开 Kernel 控制界面,为当前的 Kernel 设置运行一个 GPU。
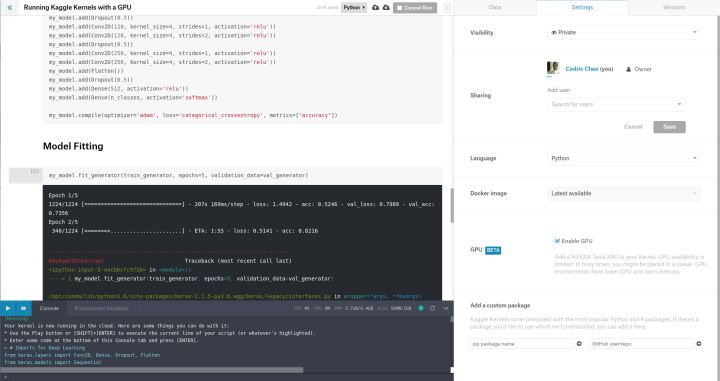
选择“Setting”选项,然后选择“Enable GPU”。接着在控制栏上检查你的 Kernel 是否连上了 GPU,连接状态应显示为“GPU ON”,如下图所示:

不少数据科学库并不能使用 GPU,因此对于一些任务来说(特别是使用 TensorFlow、Keras和 PyTorch 这些深度学习库的时候),GPU 会非常有价值。
数据
我们用到的数据集包含了涉及 29 种美式手语的图像,这些手语用来指代 26 个英语字母以及空格、删除、无物的意思等等。我们的模型会查看这些图像,学习分类每张图像上的手语。
# 导入深度学习所需的库和数据
from keras.layers import Conv2D, Dense, Dropout, Flatten
from keras.models import Sequential
from keras.preprocessing.image import ImageDataGenerator
# 保证运行中的连续性
from numpy.random import seed
seed(1)
from tensorflow import set_random_seed
set_random_seed(2)
# 导入以查看数据
import cv2
from glob import glob
from matplotlib import pyplot as plt
from numpy import floor
import random
def plot_three_samples(letter):
print("Samples images for letter " + letter)
base_path = '../input/asl_alphabet_train/asl_alphabet_train/'
img_path = base_path + letter + '/**'
path_contents = glob(img_path)
plt.figure(figsize=(16,16))
imgs = random.sample(path_contents, 3)
plt.subplot(131)
plt.imshow(cv2.imread(imgs[0]))
plt.subplot(132)
plt.imshow(cv2.imread(imgs[1]))
plt.subplot(133)
plt.imshow(cv2.imread(imgs[2]))
return
plot_three_samples('A')
plot_three_samples('B')
对应字母“B”的图像样本:

数据处理设定
data_dir = "../input/asl_alphabet_train/asl_alphabet_train"
target_size = (64, 64)
target_dims = (64, 64, 3) # add channel for RGB
n_classes = 29
val_frac = 0.1
batch_size = 64
data_augmentor = ImageDataGenerator(samplewise_center=True,
samplewise_std_normalization=True,
validation_split=val_frac)
train_generator = data_augmentor.flow_from_directory(data_dir, target_size=target_size, batch_size=batch_size, shuffle=True, subset="training")
val_generator = data_augmentor.flow_from_directory(data_dir, target_size=target_size, batch_size=ba
发现属于 29 种类别的 78300 张图像
发现属于 29 种类别的 8700 张图像
模型设定
my_model = Sequential()
my_model.add(Conv2D(64, kernel_size=4, strides=1, activation='relu', input_shape=target_dims))
my_model.add(Conv2D(64, kernel_size=4, strides=2, activation='relu'))
my_model.add(Dropout(0.5))
my_model.add(Conv2D(128, kernel_size=4, strides=1, activation='relu'))
my_model.add(Conv2D(128, kernel_size=4, strides=2, activation='relu'))
my_model.add(Dropout(0.5))
my_model.add(Conv2D(256, kernel_size=4, strides=1, activation='relu'))
my_model.add(Conv2D(256, kernel_size=4, strides=2, activation='relu'))
my_model.add(Flatten())
my_model.add(Dropout(0.5))
my_model.add(Dense(512, activation='relu'))
my_model.add(Dense(n_classes, activation='softmax'))
my_model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=["accuracy"])
模型拟合
my_model.fit_generator(train_generator, epochs=5, validation_data=val_generator)
Epoch 1/5
1224/1224 [==============================] - 206s 169ms/step - loss: 1.1439 - acc: 0.6431 - val_loss: 0.5824 - val_acc: 0.8126
Epoch 2/5
1224/1224 [==============================] - 179s 146ms/step - loss: 0.2429 - acc: 0.9186 - val_loss: 0.5081 - val_acc: 0.8492
Epoch 3/5
1224/1224 [==============================] - 182s 148ms/step - loss: 0.1576 - acc: 0.9495 - val_loss: 0.5181 - val_acc: 0.8685
Epoch 4/5
1224/1224 [==============================] - 180s 147ms/step - loss: 0.1417 - acc: 0.9554 - val_loss: 0.4139 - val_acc: 0.8786
Epoch 5/5
1224/1224 [==============================] - 181s 148ms/step - loss: 0.1149 - acc: 0.9647 - val_loss: 0.4319 - val_acc: 0.8948
<keras.callbacks.History at 0x7f5cbb6537b8>
关于如何赢得 Kaggle 挑战赛,你可能还喜欢:
