

让我们来看一下机器学习是如何应用于医护行业以及如何借助Apache Spark对患者的监控数据进行处理
现如今,IoT数据,实时流式数据分析(streaming analytics),机器学习以及分布式计算的组合相比之前有了长足的进步,同时成本也比以前要低,这使得我们可以更快地完成更多数据的存储及分析。

这里列举一些IoT,大数据以及机器学习协同完成任务的例子:
- 医疗保健:对慢性疾病的持续监控
- 智慧城市:交通流量和拥堵的管理疏导
- 制造业:结构优化以及预测建筑是否需要保养维护
- 运输业:路径规划,减少燃油消耗
- 汽车:无人驾驶汽车
- 电信,信息传输:异常检查
- 零售:基于位置的广告推荐
要理解IoT,流式数据和机器学习结合为什么可以提升医疗保健的效果,首先应当了解慢性疾病——如心脏病等是人类的主要疾病,人们的大部分医疗费用都是用在其上,而其中的关键是如何做好慢性疾病的护理以避免慢性病人不必要的住院。利用机器学习可以使用更便宜的传感器监控重要的生命体征,让医生更快地根据患者的病情开出更智能的药方,这一模式在低成本实现可扩展的慢性疾病管理上也具有着一定潜力。
斯坦福大学的一个研究小组的结果表明机器学习模型可以比专家更好地从心电图(EKG)中识别出心率失常。
正如麦肯锡全球研究所的Michael Chui所说:“放置在患者身上的传感器可以实现远程实时监控以提供早期预警,从而避免慢性疾病的突发和昂贵的护理费用。而单单对充血性心力衰竭更好的护理就可能为美国减少每年10亿美元的费用开销。”
监控数据可以进行实时分析并在必要时向护理人员发送警报以便他们可以即时了解病人情况的变化。低的误报率以及对真正的突发情况发出异常警报都是必不可少的;在UCSF的一名病人就是因为服用了超出常规剂量39倍的抗生素而死去。超量39倍的警告和超量1%的警告看起来是完全一样的,以至于看到了太多次警告的医生和药剂师常常不会看警告内容。
本文中我们将讨论流式机器学习在心脏监控数据异常检测上的应用,通过这个例子来展示数字医疗技术到底是怎样应用的。我们将细致讨论如何通过技术来控制触发警报的准确率从而降低误报率。关于这个应用的细节,可以从这里下载pdf文档查看,这项应用是基于 Ted Dunning 和 Ellen Friedman 编写的Practical Machine Learning: A New Look At Anomaly Detection。
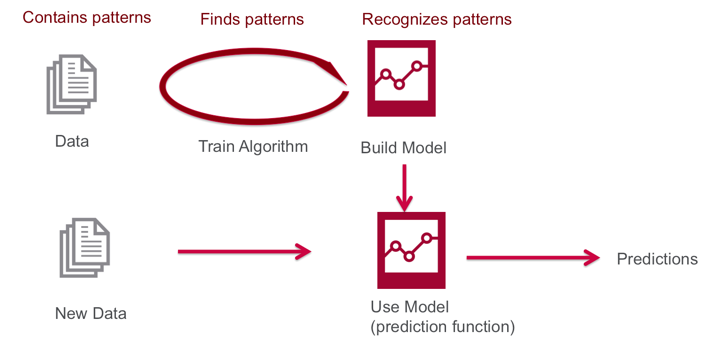
什么是机器学习?
机器学习通过算法在数据中发现相应的模式(find patterns)并建模来识别这些模式(recognize patterns),从而在新的数据上进行预测(predict)。
什么是异常检测?
异常检测是无监督学习方法的一个实例。
无监督学习算法并不需要预先获得样本的类别或者目标值。它通常用于在输入数据中寻找到其中的规律以及数据之间的相似之处——比方说可以通过用户的消费数据对相似的顾客进行分组。
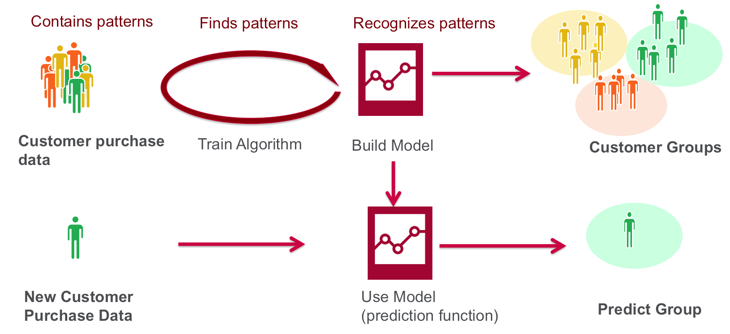
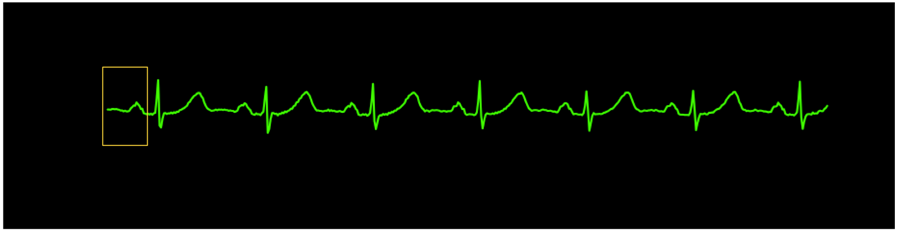
异常检测首先会建立起正常体征的模式/群组,然后将观测到的体征与之进行对比,如果确定两者之间存在明显的偏差,就可以发出警报。在这个方法之下,我们最初并没有我们想要分类的异常状况下心脏状况的数据集。所以我们首先查阅文献寻找偏差值并对它进行近乎实时的评估。
通过聚类构建模型
心脏病专家已经定义了正常心电图的波形模式;我们利用这些模式来训练模型根据之前观测到的心跳活动来预测后续时刻的观测值并与实际值进行比较来评估异常行为。
为了对正常的心跳行为进行建模,我们处理提取了一份心电图并将它拆分为大约1/3秒的片段(数据是从某一特定的病人或者许多患者中的一组提取得到的,片段与片段之间存在重叠),随后通过聚类算法来对相似的波形进行分组。
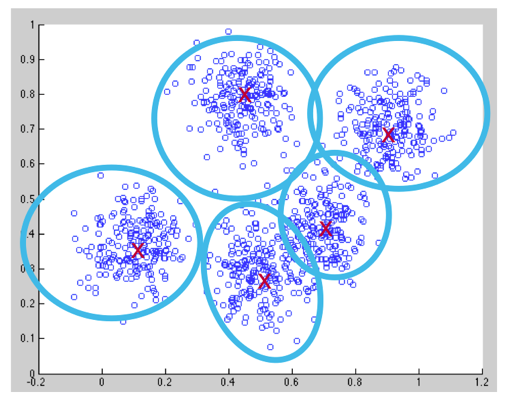
聚类算法可以对数据集中出现的数据进行分组。聚类算法训练完成后可以通过分析输入样本之间的相似度从而将样本归类到相应的类别下。K-means聚类算法会将观测值分为K组,每个观测值属于哪一个组取决于样本距离哪一个聚类中心的距离最短。
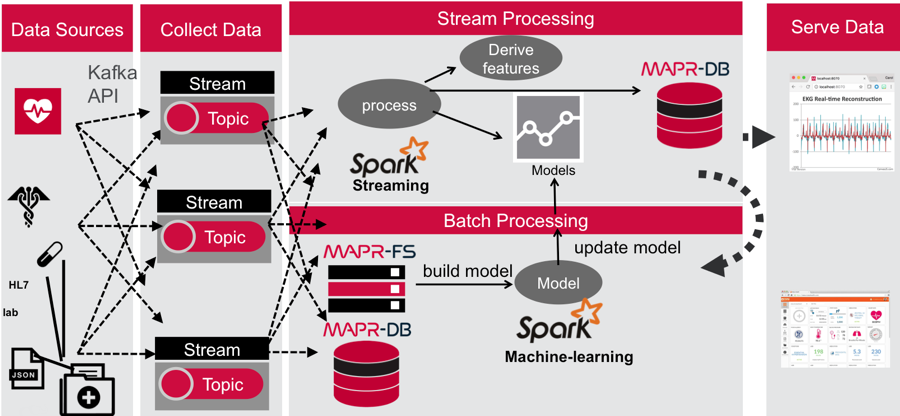
在下面的Apache Spark代码中,我们完成了一下工作:
- 将心电图数据转化为向量。
- 创建K-means对象并设置聚类的个数以及聚类算法训练的最大迭代次数。
- 在输入数据上训练模型。
- 保存模型以备随后使用。

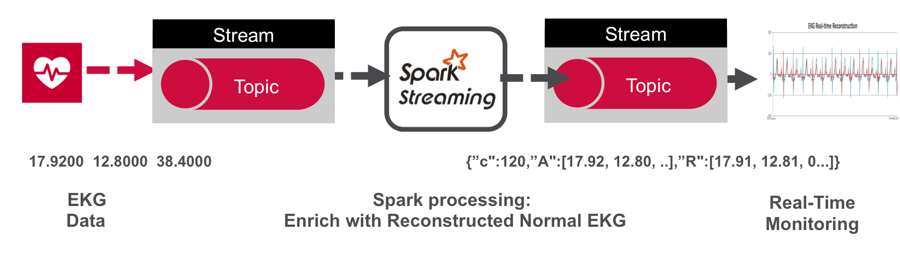
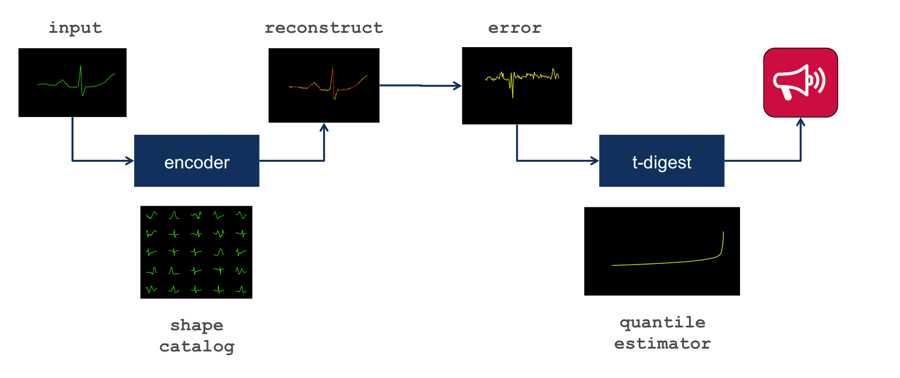
通过以上步骤,我们得到了一系列聚类中心图像构成的目录(catalog),我们可以用它来重建(reconstruct)一个心电图的数据,判断它与我们目录中的哪一个心电图波形最为相似。
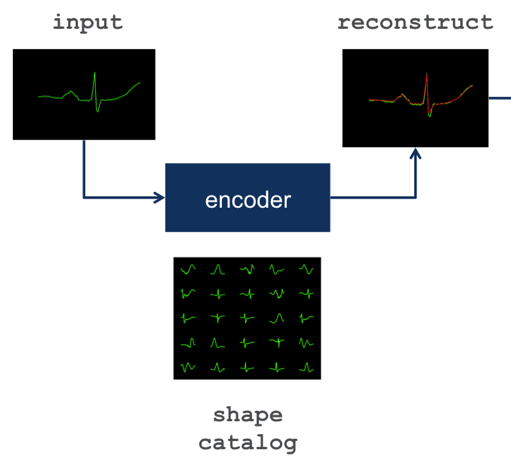
利用正常数据得到的模型对实时流数据进行处理
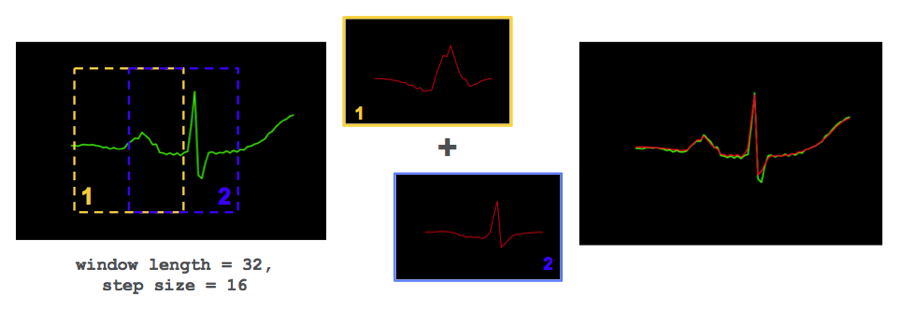
为了将获得的真实心电图数据与上一步建模得到的正常心跳行为进行比较,当心跳波形到达左图中的绿色波形中的重叠区域时,我们可以获得与之匹配的正常波形,如中间的红色波形所示,将两段红色波形进行叠加就可以得到与左侧绿色波形相似的正常心电图波形。(为了从重叠的波形片当中重建波形,我们乘了一个基于正弦的窗函数)
在下面的Apache Spark代码当中,我们完成了以下步骤:
- 使用DStream的foreachRDD方法来处理DStream中的每一个RDD。
- 将心电图数据解析为向量。
- 利用聚类模型得到当前时间窗中波形对应的正常波形类别。
- 用当前获得的类别id,32个实际心电图观测点以及32个重建得到的心电图数据点创建信息。
- 将增强的信息传递给另一个MapR-ES topic

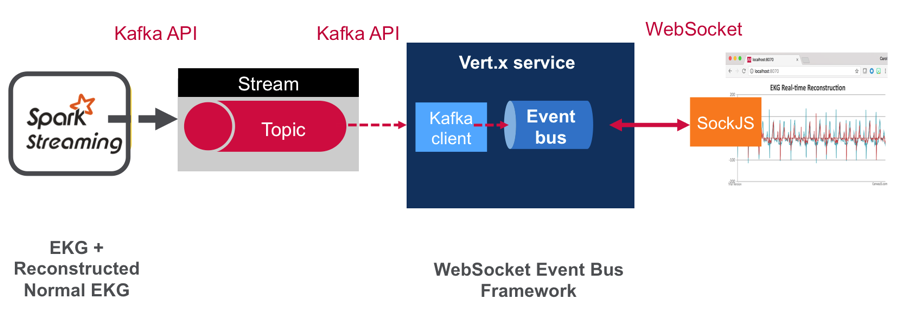
在实时的仪表盘中展示实际观测的心电图以及重建得到的正常心电图波形
我们使用了用于构建交互式时间驱动的微服务工具包Vert.x来构建实时的web应用展示观测到的心电图波形和重建的正常心电图数据。在这个web应用当中:
- Vert.x Kafka客户端消费来自MapR-ES topic的增强心电图数据并将在Vert.x的event bus上进行消息推送。
- JavaScript浏览器客户端订阅Vert.x 的event bus,使用SockJS来展示观测到的心电图波形(绿色)以及重建的预期波形(红色)。
异常检测
观测的心电图波形和预期的心电图波形之间的差值(绿色波形减去红色波形)即重建误差,也叫残差(对应下方的黄色波形),如果残差很大,那么可能出现了异常。
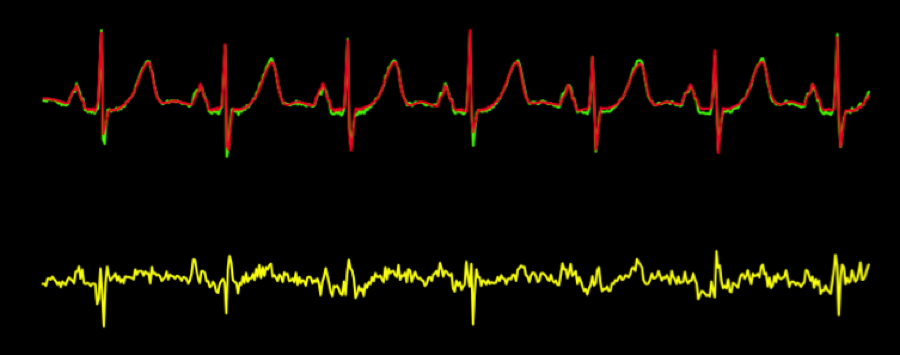
异常检测的目标是在保证低的误报率的同时发现真正的问题;这里的挑战是如何确定触发警报的残差阈值。
T-digest算法可以基于数据集的分布来评估重建误差的大小。将这个算法加入到异常检测的工作流之后你可以将警报的数目设定为全体观测值的一定百分比。T-digist算法可以用适量的样本非常精准地估计出它的分布(尤其是长尾分布,这也是我们通常关注的异常值的分布)。在得到分布的估计之后,就可以设定产生警报的阈值了。比方说,设定阈值为99%时每100次重建大约就有一次警报,这会产生相对多的警报(根据异常的定义,它应当是少见的)。而设置为99.9%时,基本1000次重建才会出现一次警报。
总结
这篇文章介绍了流式系统如何利用输入的心脏监控数据进行异常检测,展示了数据如何通过一个自编码器模型与后续的上下文数据进行比对从而检测出异常的心跳数据。本文也是IoT,实时流式数据,机器学习和数据可视化以及警报场景相结合提升医护人员工作效率并降低维护成本的一个实例。
在IoT的不同场景下,要求企业对数据进行收集、汇总,了解整个设备群从而理解其中会发生的事件和情况。除此之外,根据MapR的 Jack Norris所说,企业也应当对边界事件注入智能以便他们可以更快地对这些事件作出反应。拥有一个通用的数据结构可以帮助你以相同的方式处理所有的数据,控制数据的访问以及以更快、更高效的方式应用智能算法。
问答
基于云计算的物联网应用场景有哪些?
相关阅读
从互联网+到智慧智能,医疗行业的发展到底有多快?
在物联网中应用机器学习:使用 Android Things 与 TensorFlow
对大数据和物联网环境中数据科学自动化的见解
此文已由作者授权腾讯云+社区发布,原文链接:https://cloud.tencent.com/developer/article/1106060?fromSource=waitui

