


Hardware Bitmap在Oreo中引入,作用和它的名字一样,在Graphics Memory中分配Bitmap,这一点区别传统Java Heap上分配的情况。
回顾下传统的Bitmap如何分配方式:
Android开发基本使用BitmapFactory工厂类创建一块Bitmap对象,考虑到reuse和size放缩优化增加了一个Options类,它定义在BitmapFactory中。
public static Bitmap decodeStream(InputStream is, Rect outPadding, Options opts) {
...
Bitmap bm = null;
Trace.traceBegin(Trace.TRACE_TAG_GRAPHICS, "decodeBitmap");
try {
if (is instanceof AssetManager.AssetInputStream) {
final long asset = ((AssetManager.AssetInputStream) is).getNativeAsset();
bm = nativeDecodeAsset(asset, outPadding, opts);
} else {
bm = decodeStreamInternal(is, outPadding, opts);
}
...
return bm;
}
BitmapFactory通过nativeXXX call到jni流程中,最终都是调用BitmapFactory.cpp#doDecode接口。
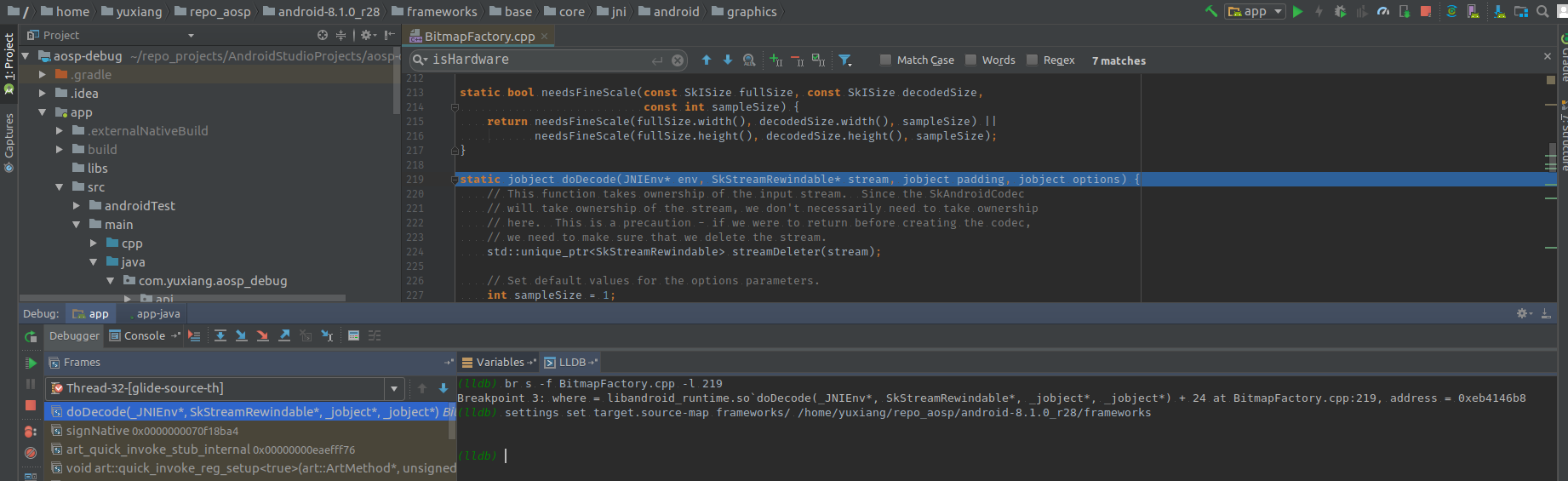
与内存分配相关部分是解析Options,拿到width、height、format(888,565)等,缺省的情况下使用文件流参数,通过HeapAllocator在native层malloc一块内存。
bitmap::createBitmap(env, defaultAllocator.getStorageObjAndReset(),bitmapCreateFlags, ninePatchChunk, ninePatchInsets, -1);
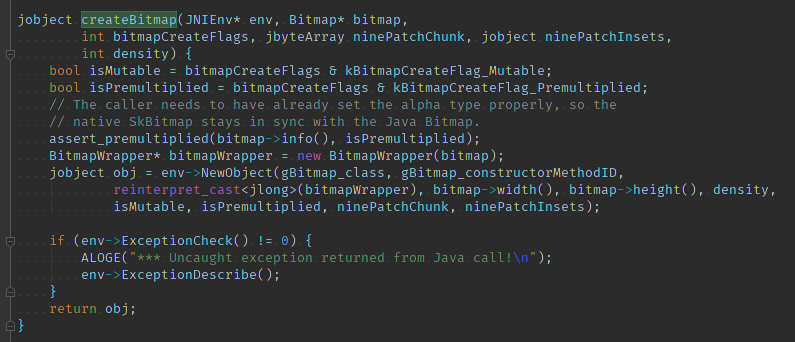
最后native层回调Java层,并将native Bitmap传给Java Bimtap,所以Bitmap.java的构造来自native层回调,理解这一点非常重要,并且Java层的Bitmap是通过mNativePtr关联到native层Bitmap对象。这是Oreo以前的方式。
Hardware Bitmap又是个啥?
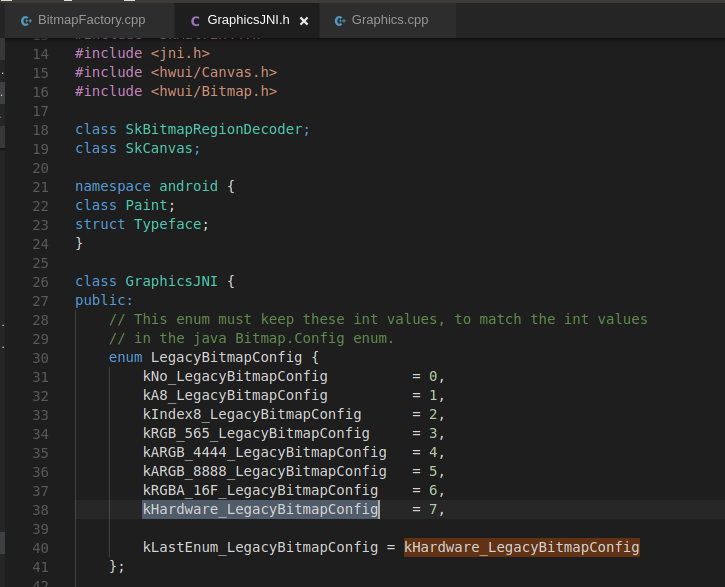
它的内存分配路径不太相同,同样是native层doDecode接口却使用hwui/Bitmap.cpp的allocateHardwareBitmap方法
sk_sp<Bitmap> Bitmap::allocateHardwareBitmap(SkBitmap& bitmap) {
return uirenderer::renderthread::RenderProxy::allocateHardwareBitmap(bitmap);
}
它向Renderhread发起一个MethodInvokeRenderTask,生成纹理上传GPU。
// RenderThread.cpp
sk_sp<Bitmap> RenderThread::allocateHardwareBitmap(SkBitmap& skBitmap) {
auto renderType = Properties::getRenderPipelineType();
switch (renderType) {
case RenderPipelineType::OpenGL:
return OpenGLPipeline::allocateHardwareBitmap(*this, skBitmap);
case RenderPipelineType::SkiaGL:
return skiapipeline::SkiaOpenGLPipeline::allocateHardwareBitmap(*this, skBitmap);
case RenderPipelineType::SkiaVulkan:
return skiapipeline::SkiaVulkanPipeline::allocateHardwareBitmap(*this, skBitmap);
default:
LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t) renderType);
break;
}
return nullptr;
}
// SkiaOpenGLPipeline.cpp
sk_sp<Bitmap> SkiaOpenGLPipeline::allocateHardwareBitmap(renderthread::RenderThread& renderThread,
SkBitmap& skBitmap) {
...
// glTexSubImage2D is synchronous in sense that it memcpy() from pointer that we provide.
// But asynchronous in sense that driver may upload texture onto hardware buffer when we first
// use it in drawing
glTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, info.width(), info.height(), format, type,
bitmap.getPixels());
GL_CHECKPOINT(MODERATE);
...
}
返回后,GPU中多了一块当前进程上传的Bitmap纹理,而进程内native层Bitmap会被GC回收。回想下路径,最开始BitmapFactory.java发起decode需求,要求Hareware类型,jni流程进入natice层调用doDecode接口,graphics/Bitmap.cpp通过RenderProxy向渲染线程发送一个MethodInvokeRenderTask生成Bitmap纹理,这一切完成后,JNI流程原路返回完成一次调用,路径中所有local reference全部释放。至于你可能要问了,HW Bitmap的最佳实践是什么,我也正在项目中尝试使用它,欢迎更多的想法在留言区。