

曾几何时,Javascript还没那么牛逼,几乎所有人都觉得它是用来做网页特效的脚本而已。彼时仓促创建出来的javascript的自身缺点被各种吐槽。随着web的发展,Javascript如今是媳妇熬成婆,应用越来越广泛。
虽然Javascript自身很努力,但是还是缺乏一项重要功能,那就是模块。毕竟Python有require,PHP有include和require。js通过<script>标签引入的方式虽说也没问题,但是缺乏组织和约束,也很难达到安全和易用。所以CommonJS规范的提出简直就是革命性的。
现在我们就来说说在Node中的CommonJS模块的规范和实现。
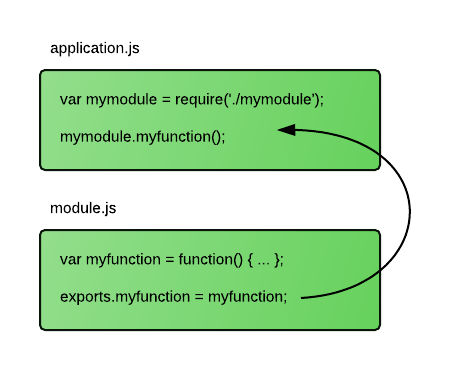
CommonJS的模块规范
CommonJS对模块定义分为三部分:模块定义、模块引用和模块标识。
- 模块定义:
首先创建一个a.js的文件,在里面写上:
module.exports = 'hello world';
在Node中,一个文件就是一个模块,module.exports对象可以导出当前模块的方法或者变量。以上的代码就是将字符串hello world导出,上下文就提供了require()方法来引入外部模块。
- 模块引用:
创建一个b.js的文件,在里面写上:
let b = require('./b.js'); //.js可以不写,这我们后面会讲到
console.log(b); // hello world
3)模块标识: 模块标识其实就是require()方法里的参数,它可以以 . 和 .. 开头的相对路径,也可以是绝对路径。可以没有文件名后缀.js,后面会讲到为何可以没有后缀。
Node的模块实现
上面的代码就是最简单的模块的使用。那么在我们这几行简单的代码背后,在实现过程中究竟是什么样的过程呢?我们一点点来分析。
Node在引入模块经历3个步骤:路径分析、文件定位和编译执行
在Node中模块有两类:一类是Node提供的核心模块,另一类是用户自己编写的文件模块。
部分的核心模块直接加载在内存中,所以引入这部分模块时,文件定义和编译执行都可以省略,在路径分析中优先判断,加载速度也是最快的。
另外需要知晓的是,Node引入的模块都会进行缓存,以减少二次引用时的开销。它缓存的是编译和执行后的对象,而不是和浏览器一样,缓存的是文件。
-
路径分析 上面已经说了,require()方法里参数叫模块标识,路径分析其实就是基于标识符来查找的。模块标识符在Node中分为以下几类:
- 核心模块,比如http、fs、path等。
- . 或 .. 开始的相对路径文件模块。
- 以/开始的绝对路径文件模块。
- 非路径形式的文件模块,如自定义的connect模块。
-
核心模块的优先级仅次于缓存加载,由于在Node源码编译中已经被编译为二进制代码,所以加载过程是最快的。
-
相对路径文件模块在分析路径时,require()方法会将路径转为真实路径,并以绝对路径最为索引,将编译执行后的结果放入缓存,以使二次引用时加载更快。
-
自定义模块是特殊的文件模块,可能是文件或者包的形式,也是查找最慢的一种模块。
Node在定位文件模块的具体文件时制定的查找策略可以表现为一个路径数组。
在js文件中console.log(module.paths);
放到任意目录中执行;
就会得到类似以下的数组:
[ '/Users/lq/Desktop/node_modules', //当前文件目录下的node_modules目录
'/Users/lq/node_modules',//父目录下的node_modules目录
'/Users/node_modules',//父目录的父目录下的node_modules目录
'/node_modules' ]//沿路径向上逐级递归,直到找到根目录下的node_modules目录
当前文件的路径越深,模块查找就越耗时,这是自定义模块加载慢的原因。
- 文件定位
require()在分析标识符的时候,可能会出现没有传递文件拓展名的情况。CommonJS模块规范是允许这种情况出现的,不过Node会按照.js、.json、.node的顺序补足拓展名。依次调用fs模块同步阻塞式地判断文件是否存在。
在这个过程中,Node对CommonJS模块规范进行了一定的支持。首先,Node会在当前目录下查找包描述文件package.json,通过JSON.parse()解析出包描述对象,取出main属性指定的文件名进行定位,如果缺少拓展名,就进入上面说的拓展名分析步骤,按顺序补足拓展名再查找。如果main属性指定的文件名错误或者没有包描述文件package.json,Node会将index当作默认文件名,依次查找index.js、index.json、index.node。如果所有的路径数组都遍历了,还是没有找到,就会抛出错误。
- 模块编译 在定位到具体的文件后,Node会新建一个模块对象,然后根据路径进行编译。根据不同的拓展名操作不同的方法。
- 如果是.js文件,通过fs模块同步读取文件后编译执行
- 如果是.json文件,通过fs模块同步读取文件后,用JSON.parse()解析返回结果
- 如果是.node文件,通过dlopen()方法加载最后编译生成的文件。这是C/C++编写的拓展文件,本人在后面实现原理的过程中予以忽略。
说了这么多,下面直接进入实现环节
先创建一个a.js文件,写入:
module.exports = 'hello world';
再创建一个b.js,写入:
let b = require('./a.js');
console.log(b); //hello world
打印的结果是hello wrold。这是Node自带的require方法。现在我们来实现下我们自己的require方法。
我们直接在b.js里修改下:
//引入Node的核心模块
let fs = require('fs');
let path = require('path');
let vm = require('vm');
function Module(p) {
this.id = p; //当前模块的标识,也就是绝对路径
this.exports = {}; //每个模块都有exports属性,添加一个
this.loaded = false; //是否已经加载完
}
//对文件内容进行头尾包装
Module.wrapper = ['(function(exports,require,module){', '})']
//所有的加载策略
Module._extensions = {
'.js': function (module) { //读取js文件,增加一个闭包
let script = fs.readFileSync(module.id, 'utf8');
let fn = Module.wrapper[0] + script + Module.wrapper[1];//包装在一个闭包里
vm.runInThisContext(fn).call(module.exports, module.exports, myRequire, module);//通过runInThisContext()方法执行不污染全局
return module.exports;
},
'.json': function (module) {
return JSON.parse(fs.readFileSync(module.id, 'utf8')); //读取文件
}
}
Module._cacheModule = {} //存放缓存
Module._resolveFileName = function (moduleId) { //根据传入的路径参数返回一个绝对路径的方法
let p = path.resolve(moduleId);
if (!path.extname(moduleId)) { //如果没有传文件后缀
let arr = Object.keys(Module._extensions); //将对象的key转成数组
for (let i = 0; i < arr.length; i++) { //循坏数组添加后缀
let file = p + arr[i];
try {
fs.accessSync(file); //查看文件是否存在,存在的就返回
return file;
} catch (e) {
console.log(e); //不存在报错
}
}
} else {
return p; //如果已经传递了文件后缀,直接返回绝对路径
}
}
Module.prototype.load = function (filepath) { //模块加载的方法
let ext = path.extname(filepath);
let content = Module._extensions[ext](this);
return content;
}
function myRequire(moduleId) { //自定义的myRequire方法
let p = Module._resolveFileName(moduleId); //将传递进来的模块标示转成绝对路径
if (Module._cacheModule[p]) { //如果模块已经存在
return Module._cacheModule[p].exports; //直接返回编译和执行之后的对象
}
let module = new Module(p); //模块不存在,先创建一个新的模块对象
let content = module.load(p); //模块加载后的内容
Module._cacheModule[p] = module;
module.exports = content;
return module.exports;
}
let b = myRequire('./a.js');
console.log(b);
这样就可以通过自己的myRequire()方法拿到a.js里的字符串hello world了。当然,module的源码不止这么多,有兴趣的可以自己查看。本文只是说明下module加载的原理。有写的不够严谨的地方,望谅解。如有错漏,可指出,定及时修改。
参考
部分内容根据《深入浅出Node.js》一书整理
