

站内搜索,可以认为是针对一个网站特性内容的搜索功能。由于内容、格式可控,站内搜索比全网搜索的实现要简单很多。
简书这个网站本身自带一个搜索,但是缺乏针对个人文章的搜索,所以本文的实战内容是解决这个痛点。
代码在 github.com/letiantian/…,可以使用下面的方式把代码下载下来查看:
git clone https://github.com/letiantian/jianshu-site-search.git
代码在Python2.7下运行。需要安装以下依赖:
pip install elasticsearch==6.0.0 --user
pip install uniout --user
pip install requests --user
pip install beautifulsoup4 --user
pip install Django --user
1. 数据源
如果是简书给自己做个人搜索,从数据库里拿就行了。
我这种情况,自然用爬虫抓取。
1.1 抓取什么内容?
抓取某个人所有的文章,最终是URL、标题、正文三个部分。
1.2 如何抓取?
以www.jianshu.com/u/7fe2e7bb7…这个(随便找的)用户主页为例。7fe2e7bb7d47可以认为是这个用户的ID。
文章地址类似http://www.jianshu.com/p/9c2fdb9fa5d1,9c2fdb9fa5d1是文章 ID。
经过分析,可以以此请求下面的地址,从中解析出文章地址,得到地址集合:
http://www.jianshu.com/u/7fe2e7bb7d47?order_by=shared_at&page=1
http://www.jianshu.com/u/7fe2e7bb7d47?order_by=shared_at&page=2
http://www.jianshu.com/u/7fe2e7bb7d47?order_by=shared_at&page=3
// ... page的值不断增加
// ... 当page不存在的时候,简书会返回page=1的内容,这时候停止抓取
然后,依次抓取文章内容,保存下来。
crawler.py 用于抓取文章,使用方法:
python crawler.py 7fe2e7bb7d47
文章对应的网页会保存到data目录,用文章ID命名。
2. 最简单的搜索引擎实现
对于每个搜索词查看每个文章的标题和正文中有无该词:
- 标题中有该搜索词,为该文章加2分。
- 正文中有该搜索词,为该文章加1分。
一篇文章命中的搜索词越多,分值越高。
将结果排序输出即可。
代码实现在simple_search.py ,使用方法:
$ python simple_search.py 人民 名义
你输入了: 人民 名义
搜索结果:
url: http://www.jianshu.com/p/6659d5fc5503
title: 《人民的名义》走红的背后 文化产业投资难以言说的痛
score: 6
url: http://www.jianshu.com/p/ee594ea42815
title: LP由《人民的名义》反思 GP投资权力真空怎么破
score: 6
url: http://www.jianshu.com/p/4ef650769f73
title: 弘道资本:投资人人贷、ofo 人民币基金逆袭的中国样本
score: 3
这种方法的缺点是:
- 因为是遍历每个文章,文章变多后,速度会变慢
- 搜索结果排序不理想
- 没有引入中文分词特性
3. 基于 Elasticsearch 的实现
Elasticsearch 是一个通用的搜索引擎解决方案,提供了优雅的 HTTP Restful 接口、丰富的官方文档。 阮一峰为它写了一份简明易懂的教程:全文搜索引擎 Elasticsearch 入门教程,推荐阅读。
Elasticsearch 基本原理:
- 对搜索内容进行分词,得到若干搜索词。
- 通过倒排索引找到含有搜索词的文章集合。
- 通过TF-IDF、余弦相似性计算文章集合中每个文章和搜索内容的相似性。
- 根据相似性进行排序,得到搜索结果。
3.1 环境搭建
我们先搭建环境:
- 安装Java。
- 官网下载最新的 6.0.0 版本,解压。
- 安装ik分词插件。
./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.0.0/elasticsearch-analysis-ik-6.0.0.zip
或者下载下来解压到Elasticsearch的plugins目录。 4. 启动:
./bin/elasticsearch
环境搭建完成。
3.2 创建索引
python es_create_index.py
创建时指定了分词器。
3.3 索引数据
python es_index_data.py
为了防止一篇文章被重复索引,添加索引时 Document ID 设置为文章 ID。
3.4 搜索
python es_search.py 人民的名义
高亮搜索结果:
python es_hl_search.py 人民的名义
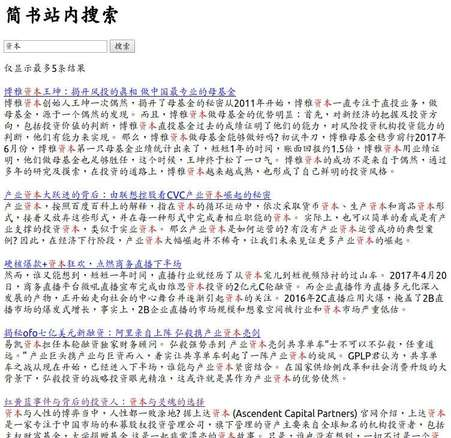
3.5 基于web的搜索
基于Django实现了一个简单的web界面。运行:
python webui/manage.py runserver
浏览器访问http://127.0.0.1:8000/即可。体验效果:
4. 关于 Elasticsearch 的一些思考
4.1 如何看待停止词?
停止词是非常常见的单词,例如的、the等。一般用法是在分词后去掉停止词,然后进行索引。这种做法的常见理由是减少索引大小。同时,从理论上看,也可以提升检索速度。
相应的,这里有两个问题需要探讨:
- 索引大小的减小量是什么数量级,如果只是减少了1%,这种优化并无必要。
- 检索速度的提升是什么数量级,如果只是提升1%,说服力并不大。
是否能达到业务的需求才是目标。如果需要在搜索的这个词的时候有结果,那么上面的做法就是不合理的。
我更倾向于底层索引不启用停止词,而是根据业务需求在业务层进行必要的停止词处理。
4.2 防止深度搜索
要Elasticsearch返回搜索结果的第10001条到第10010条数据,是一个耗时的操作,因为Elasticsearch要先得到打分最高的前10010条数据,然后从中取出第10001条到第10010条数据。
用户感知到的搜索界面是分页的,每页是固定数量的数据(如10条),用户会跳转到第1001页的搜索结果吗?不会。第1001页的搜索结果有意义吗?没有意义,用户应该调整搜索词。
综上,应限制用户得到的搜索结果数量。
4.3 处理海量数据
本文的示例的数据由一个用户的所有文章组成,数据量很小。如果简书全站搜索也是用Elasticsearch,它能处理好吗?
事实上,Elasticsearch 支持分片和分布式部署,能近实时的处理海量数据。注意,索引耗时会很大,但是搜索很快。
4.4 如何在搜索结果中加入推广内容
推广内容本身也可以被Elasticsearch索引起来,根据情况插入搜索结果中就行了。
本文发布于樂天的开发笔记-掘金,同时发布于樂天笔记。
