

一、什么是zab协议?
ZAB 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
Zab 协议分为两大块:
- 广播(boardcast):Zab 协议中,所有的写请求都由 leader 来处理。正常工作状态下,leader 接收请求并通过广播协议来处理。
- 恢复(recovery):当服务初次启动,或者 leader 节点挂了,系统就会进入恢复模式,直到选出了有合法数量 follower 的新 leader,然后新 leader 负责将整个系统同步到最新状态。
1.1广播(boardcast)
广播的过程实际上是一个简化的二阶段提交过程:
- Leader 接收到消息请求后,将消息赋予一个全局唯一的 64 位自增 id,叫做:zxid,通过 zxid 的大小比较即可实现因果有序这一特性。
- Leader 通过先进先出队列(通过 TCP 协议来实现,以此实现了全局有序这一特性)将带有 zxid 的消息作为一个提案(proposal)分发给所有 follower。
- 当 follower 接收到 proposal,先将 proposal 写到硬盘,写硬盘成功后再向 leader 回一个 ACK。
- 当 leader 接收到合法数量的 ACKs 后,leader 就向所有 follower 发送 COMMIT 命令,同事会在本地执行该消息。
- 当 follower 收到消息的 COMMIT 命令时,就会执行该消息
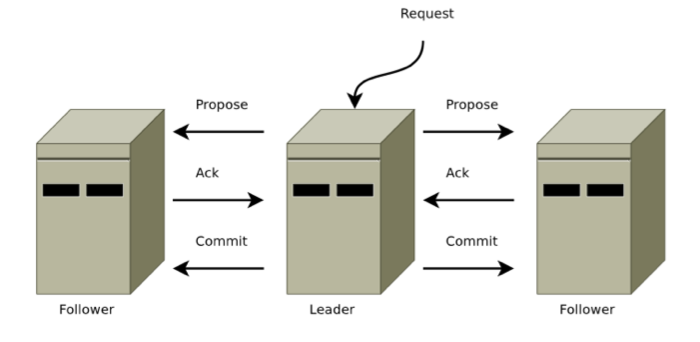 广播过程
广播过程相比于完整的二阶段提交,Zab 协议最大的区别就是不能终止事务,follower 要么回 ACK 给 leader,要么抛弃 leader,在某一时刻,leader 的状态与 follower 的状态很可能不一致,因此它不能处理 leader 挂掉的情况,所以 Zab 协议引入了恢复模式来处理这一问题。从另一角度看,正因为 Zab 的广播过程不需要终止事务,也就是说不需要所有 follower 都返回 ACK 才能进行 COMMIT,而是只需要合法数量(2f+1 台服务器中的 f+1 台) 的follower,也提升了整体的性能。
1.2恢复(recovery)
由于之前讲的 Zab 协议的广播部分不能处理 leader 挂掉的情况,Zab 协议引入了恢复模式来处理这一问题。为了使 leader 挂了后系统能正常工作,需要解决以下两个问题:
- 已经被处理的消息不能丢
- 被丢弃的消息不能再次出现
已经被处理的消息不能丢
这一情况会出现在以下场景:当 leader 收到合法数量 follower 的 ACKs 后,就向各个 follower 广播 COMMIT 命令,同时也会在本地执行 COMMIT 并向连接的客户端返回「成功」。但是如果在各个 follower 在收到 COMMIT 命令前 leader 就挂了,导致剩下的服务器并没有执行都这条消息。
如图 1-1,消息 1 的 COMMIT 命令 Server1(leader)和 Server2(follower) 上执行了,但是 Server3 还没有收到消息 1 的 COMMIT 命令,此时 leader Server1 已经挂了,客户端很可能已经收到消息 1 已经成功执行的回复,经过恢复模式后需要保证所有机器都执行了消息 1。
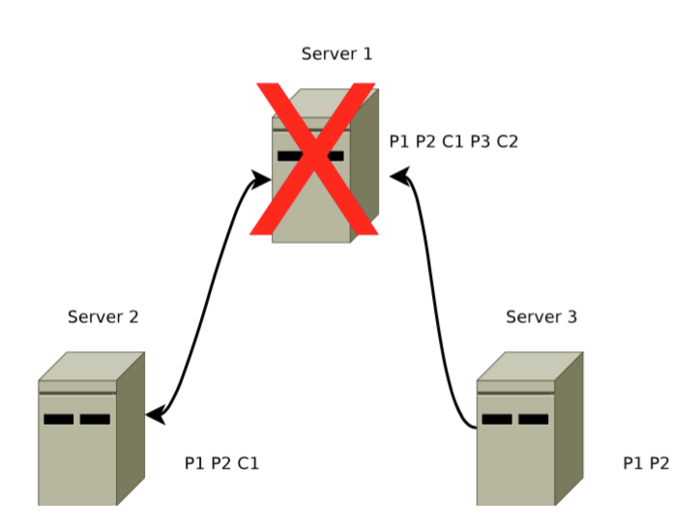
为了实现已经被处理的消息不能丢这个目的,Zab 的恢复模式使用了以下的策略:
- 选举拥有 proposal 最大值(即 zxid 最大) 的节点作为新的 leader:由于所有提案被 COMMIT 之前必须有合法数量的 follower ACK,即必须有合法数量的服务器的事务日志上有该提案的 proposal,因此,只要有合法数量的节点正常工作,就必然有一个节点保存了所有被 COMMIT 消息的 proposal 状态。
- 新的 leader 将自己事务日志中 proposal 但未 COMMIT 的消息处理。
- 新的 leader 与 follower 建立先进先出的队列, 先将自身有而 follower 没有的 proposal 发送给 follower,再将这些 proposal 的 COMMIT 命令发送给 follower,以保证所有的 follower 都保存了所有的 proposal、所有的 follower 都处理了所有的消息。
通过以上策略,能保证已经被处理的消息不会丢
被丢弃的消息不能再次出现
这一情况会出现在以下场景:当 leader 接收到消息请求生成 proposal 后就挂了,其他 follower 并没有收到此 proposal,因此经过恢复模式重新选了 leader 后,这条消息是被跳过的。 此时,之前挂了的 leader 重新启动并注册成了 follower,他保留了被跳过消息的 proposal 状态,与整个系统的状态是不一致的,需要将其删除。
如图 1-2 ,在 Server1 挂了后系统进入新的正常工作状态后,消息 3被跳过,此时 Server1 中的 P3 需要被清除。
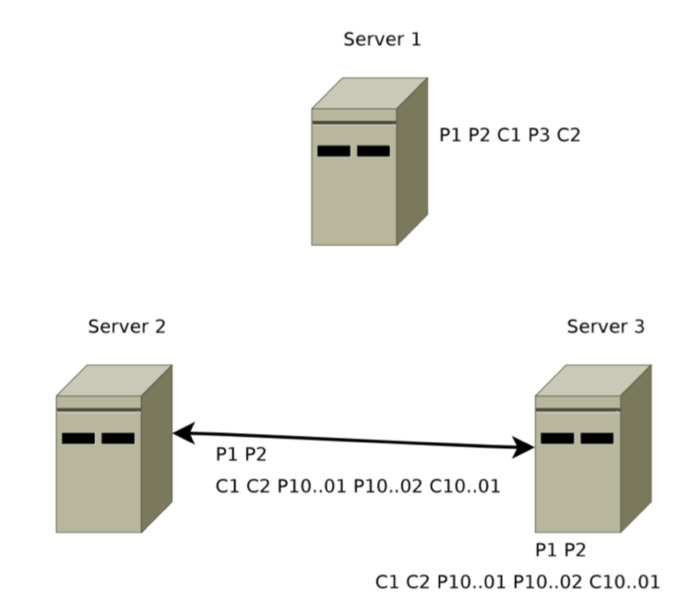
Zab 通过巧妙的设计 zxid 来实现这一目的。一个 zxid 是64位,高 32 是纪元(epoch)编号,每经过一次 leader 选举产生一个新的 leader,新 leader 会将 epoch 号 +1。低 32 位是消息计数器,每接收到一条消息这个值 +1,新 leader 选举后这个值重置为 0。这样设计的好处是旧的 leader 挂了后重启,它不会被选举为 leader,因为此时它的 zxid 肯定小于当前的新 leader。当旧的 leader 作为 follower 接入新的 leader 后,新的 leader 会让它将所有的拥有旧的 epoch 号的未被 COMMIT 的 proposal 清除。
二、总结
- 主从架构下,leader 崩溃,数据一致性怎么保证?leader 崩溃之后,集群会选出新的 leader,然后就会进入恢复阶段,新的 leader 具有所有已经提交的提议,因此它会保证让 followers 同步已提交的提议,丢弃未提交的提议(以 leader 的记录为准),这就保证了整个集群的数据一致性。
- 选举 leader 的时候,整个集群无法处理写请求的,如何快速进行 leader 选举?这是通过 Fast Leader Election 实现的,leader 的选举只需要超过半数的节点投票即可,这样不需要等待所有节点的选票,能够尽早选出 leader。

