

原作者:李嘉铭
原文发于作者知乎专栏,点击查看原文,集智已获得转载授权。再次感谢作者。
引言
我成为宅之后一直抱有的一大遗憾,就是从小手残不会画画,唯一能提的恐怕只有在美术课上,把新垣结衣画成吴三桂之类的惨剧。
在接触了机器学习之后,感觉手残的我还可以拯救一下。毕竟现在的AI会下棋,会开车,还吟的一手好诗,会画画似乎也不是不可能。为此我研究了如下的课题:能否打破次元壁,让AI把现实中的人脸转换成漫画风格的图片?
事实上近几年来教AI画画的尝试数不胜数。我曾经的文章里介绍过其中的两个:图像风格迁移和用生成对抗网络(GAN)进行线稿上色,两者都和我们的课题密切相关。
图像风格迁移

简单来说,图像风格迁移是把一张画作的风格迁移到照片上的过程。风格可以包括笔触,用色,光影,物体比例等等。自从Gatys在2015年发明了用神经网络的图像迁移方法之后,一直困扰研究者的一个问题就是,由于图像风格迁移大多使用事先训练好的物品识别网络,而物品识别使用的训练集是现实中的图片,现有的图像迁移方法对于和现实中的物体比例不同的画风束手无策。具体到二三次元来说的话有两者头身比不同,眼睛鼻子大小不同等一系列问题。
其实最直接的解决方法也不难:花钱。请人标注一个专门用于艺术画作方面的数据集,并重新训练物品识别器,然而愿意花钱做这个苦差事的研究者寥寥无几。在用图像风格迁移把人脸转换成二次元风格就这样基本被堵死了。
GAN
如果图像风格迁移是打破次元壁的一条路,那另一条路则是生成对抗网络,亦即所谓的GAN(Generative Adversarial Network)。GAN是现在大名鼎鼎的研究者Ian Goodfellow在2014年提出的用于生成任何数据的算法,只要给予足够的训练数据和时间以及足够强的神经网络。通过两个互相博弈的神经网络,GAN可以模仿并生成真假难辨的图像。比较有名的几个应用例子如用于二次元头像生成的MakeGirlsMoeMakeGirlsMoe,以及英伟达(Nvidia)研究所推出的高清晰度真人头像生成模型PGGAN。

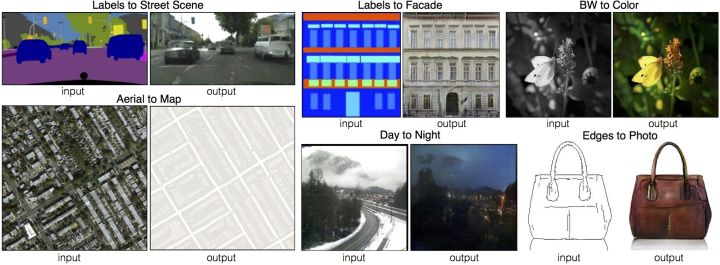
无配对跨领域图像转换
必须使用不成对的图片的限制,使图像类型转换难度上升了一个等级,堪比在没有辞典的情况下学习一门新语言。
幸好,被贫穷限制想象力的貌似不止我一个,还有Facebook人工智能研究所。在2016年Facebook发布了一篇名叫Unsupervised Cross-Domain Image Generation的论文,其核心内容便是如何在没有成对数据,但一类图像有标注的情况下做到两种类型图片之间的互相“翻译”。不久之后的2017年,Jun-Yan Zhu等人提出了名为CycleGan的用于无标注不成对数据集的模型。
这两个模型的一大共同之处便在于,为了解决数据集不配对的问题,两个模型都做了如下的假设:先把A类图片转换成B类,再把B类转换回A时,原图和经过两次翻译的图片之间不应该差太多。用翻译打个比方,把中文句子翻译成英文之后,再把英语句子翻译回中文时得到的应该是和一开始相同的句子,而二次翻译之后与原输入不同之处就可以当作循环误差(cycle consistency loss)。CycleGAN就是通过减少循环误差来训练神经网络,并做到两类不配对的图片之间的互相转化。
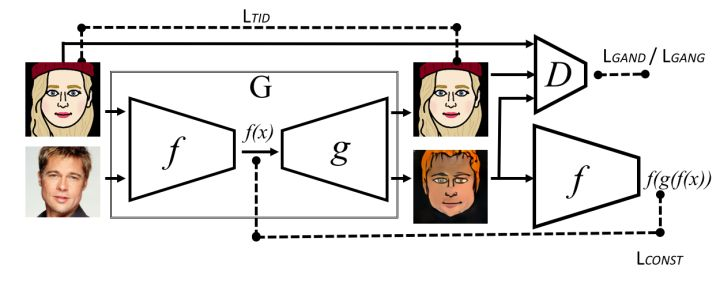
尝试CycleGAN
好消息是,CycleGan有现成的开源代码。找到现有的算法之后,我开始收集训练所需的数据。我用CelebA的20万张图片作为三次元头像数据库,用MakeGirlsMoe里提到的方法从日本游戏网站Getchu截取了共计约3万张二次元头像。


换个角度再试一次!
幸运的是,在现有的GAN算法行不通的时候,还有图片风格迁移方面的经验可以借鉴。早在2016年,谷歌大脑(Google Brain)的Vincent Dumoulin等人便发现,仅仅让神经网络学习Batch Norm(批规范化层)中的两个参数,就可以实现让一张图片转换成许多不同风格的效果,甚至可以把不同的风格互相混搭。他们的论文A Learned Representation For Artistic Style表明,本来用于让神经网络训练更稳定的Batch Norm参数还有更多可发掘的潜力。
Twin-GAN - 技术细节
借鉴了以上提到的想法,并经过一些尝试之后,我确定了如下名叫Twin-GAN的网络结构:在图像生成器方面我用了至今效果最好的英伟达的PGGAN。由于PGGAN的输入是一个随机的高维向量,而我们的输入是一张图片,所以我用了和PGGAN对称的编码器(encoder)将输入的头像图片编码为高维向量,并且为了还原图片的细节,我用了UNet的结构将编码器和图像生成网络之间的卷积层连接了起来。我的神经网络的输入和输出主要有三种:
- 三次元头像->编码器->高维向量->PGGAN生成器+三次元用Batch Norm参数->三次元头像
- 二次元头像->编码器->高维向量->PGGAN生成器+二次元用Batch Norm参数->二次元头像
- 三次元头像->编码器->高维向量->PGGAN生成器+二次元用Batch Norm参数->二次元头像
和Facebook的论文里提到的一样,让三次元和二次元头像共用一个编码器和一个生成器的主要目的是让神经网络能够认识到,虽然长的不太一样,二次元和三次元的图片所描绘的内容都是人脸。这对于二三次元的转换至关重要。而最终决定是二次元还是三次元的开关就在Batch Norm参数里。
损失函数方面,我主要用了以下四个函数:
- 三次元到三次元的还原损失函数(l1+GAN loss)
- 二次元到二次元的还原损失函数(l1+GAN loss)
- 三次元到二次元的GAN损失函数
- 三次元到二次元的循环损失函数(cycle consistency loss)。
成果
实际训练完成后的效果如下:


不理想的地方也在这张图中一目了然,有些时候它会把背景也当作头发的颜色来利用(如左下角),还有些时候他会把人的朝向弄反,这些错误在图片转换的时候也能见到。
其实我们的算法应用范围不只是二三次元转换,拿猫脸来训练会怎么样?


后记:
现有算法最大的问题之一还是在数据集上,由于我收集的二次元头像大多为女性,所以神经网络会把三次元男性娘化成二次元女性。另外不正确的把背景当作发色,忽略以及错误的识别某些特征之类的也常有发生,比如以下就是一个失败的例子:

值得一提的是,前几个月由Shuang Ma提出的利用Attention Map的名为DA-GAN的图片生成算法也有不错的效果,其中的算法也有许多值得借鉴的地方。并且英伟达就在昨天公布了他们最新的研究,展示了能够把猫变成狗的神经网络。这让我更加期待将来图像转换领域的进一步发展。This is exciting!
相关论文以及网站会视情况尽快推出,相关更新敬请关注我的知乎帐号。感谢阅读!
注:本文为了方便理解,简化了许多论点,并不严禁,还请注意和谅解。对技术细节有兴趣的可以读引用部分的论文。
引用
A Neural Algorithm of Artistic Style
A Learned Representation For Artistic Style
Unsupervised Cross-Domain Image Generation
Spectral Normalization for Generative Adversarial Networks
Conditional generative adversarial nets
Multimodal Unsupervised Image-to-Image Translation
欢迎关注我们,学习资源,AI教程,论文解读,趣味科普,你想看的都在这里!
