

我们在前面已经实现了Scrapy微博爬虫,虽然爬虫是异步加多线程的,但是我们只能在一台主机上运行,所以爬取效率还是有限的,分布式爬虫则是将多台主机组合起来,共同完成一个爬取任务,这将大大提高爬取的效率。
一、分布式爬虫架构
在了解分布式爬虫架构之前,首先回顾一下Scrapy的架构,如下图所示。
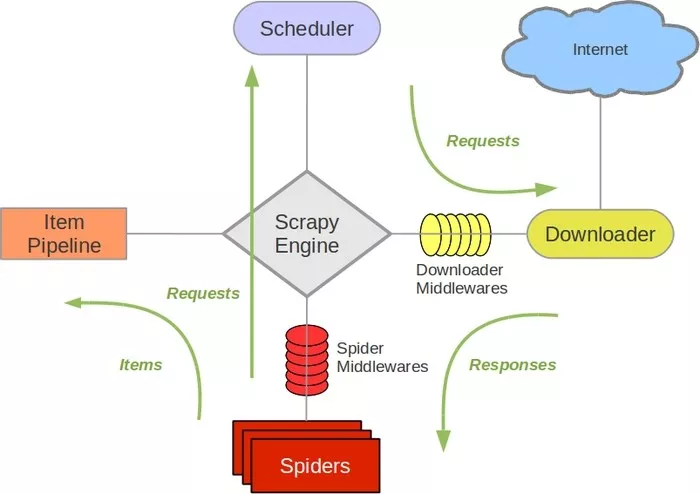
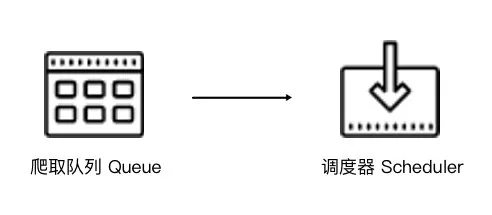
Scrapy单机爬虫中有一个本地爬取队列Queue,这个队列是利用deque模块实现的。如果新的Request生成就会放到队列里面,随后Request被Scheduler调度。之后,Request交给Downloader执行爬取,简单的调度架构如下图所示。
如果两个Scheduler同时从队列里面取Request,每个Scheduler都有其对应的Downloader,那么在带宽足够、正常爬取且不考虑队列存取压力的情况下,爬取效率会有什么变化?没错,爬取效率会翻倍。
这样,Scheduler可以扩展多个,Downloader也可以扩展多个。而爬取队列Queue必须始终为一个,也就是所谓的共享爬取队列。这样才能保证Scheduer从队列里调度某个Request之后,其他Scheduler不会重复调度此Request,就可以做到多个Schduler同步爬取。这就是分布式爬虫的基本雏形,简单调度架构如下图所示。
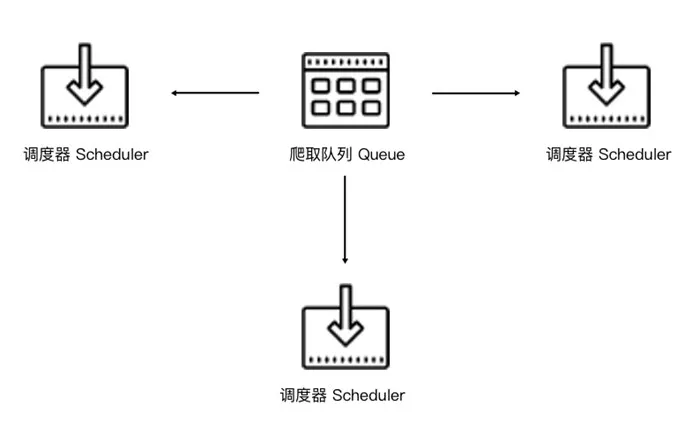
我们需要做的就是在多台主机上同时运行爬虫任务协同爬取,而协同爬取的前提就是共享爬取队列。这样各台主机就不需要各自维护爬取队列,而是从共享爬取队列存取Request。但是各台主机还是有各自的Scheduler和Downloader,所以调度和下载功能分别完成。如果不考虑队列存取性能消耗,爬取效率还是会成倍提高。
二、维护爬取队列
那么这个队列用什么来维护?首先需要考虑的就是性能问题。我们自然想到的是基于内存存储的Redis,它支持多种数据结构,例如列表(List)、集合(Set)、有序集合(Sorted Set)等,存取的操作也非常简单。
Redis支持的这几种数据结构存储各有优点。
列表有
lpush()、lpop()、rpush()、rpop()方法,我们可以用它来实现先进先出式爬取队列,也可以实现先进后出栈式爬取队列。集合的元素是无序的且不重复的,这样我们可以非常方便地实现随机排序且不重复的爬取队列。
有序集合带有分数表示,而Scrapy的Request也有优先级的控制,我们可以用它来实现带优先级调度的队列。
我们需要根据具体爬虫的需求来灵活选择不同的队列。
三、如何去重
Scrapy有自动去重,它的去重使用了Python中的集合。这个集合记录了Scrapy中每个Request的指纹,这个指纹实际上就是Request的散列值。我们可以看看Scrapy的源代码,如下所示:
import hashlib
def request_fingerprint(request, include_headers=None):
if include_headers:
include_headers = tuple(to_bytes(h.lower())
for h in sorted(include_headers))
cache = _fingerprint_cache.setdefault(request, {})
if include_headers not in cache:
fp = hashlib.sha1()
fp.update(to_bytes(request.method))
fp.update(to_bytes(canonicalize_url(request.url)))
fp.update(request.body or b'')
if include_headers:
for hdr in include_headers:
if hdr in request.headers:
fp.update(hdr)
for v in request.headers.getlist(hdr):
fp.update(v)
cache[include_headers] = fp.hexdigest()
return cache[include_headers]request_fingerprint()就是计算Request指纹的方法,其方法内部使用的是hashlib的sha1()方法。计算的字段包括Request的Method、URL、Body、Headers这几部分内容,这里只要有一点不同,那么计算的结果就不同。计算得到的结果是加密后的字符串,也就是指纹。每个Request都有独有的指纹,指纹就是一个字符串,判定字符串是否重复比判定Request对象是否重复容易得多,所以指纹可以作为判定Request是否重复的依据。
那么我们如何判定重复呢?Scrapy是这样实现的,如下所示:
def __init__(self):
self.fingerprints = set()
def request_seen(self, request):
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
return True
self.fingerprints.add(fp)在去重的类RFPDupeFilter中,有一个request_seen()方法,这个方法有一个参数request,它的作用就是检测该Request对象是否重复。这个方法调用request_fingerprint()获取该Request的指纹,检测这个指纹是否存在于fingerprints变量中,而fingerprints是一个集合,集合的元素都是不重复的。如果指纹存在,那么就返回True,说明该Request是重复的,否则这个指纹加入到集合中。如果下次还有相同的Request传递过来,指纹也是相同的,那么这时指纹就已经存在于集合中,Request对象就会直接判定为重复。这样去重的目的就实现了。
Scrapy的去重过程就是,利用集合元素的不重复特性来实现Request的去重。
对于分布式爬虫来说,我们肯定不能再用每个爬虫各自的集合来去重了。因为这样还是每个主机单独维护自己的集合,不能做到共享。多台主机如果生成了相同的Request,只能各自去重,各个主机之间就无法做到去重了。
那么要实现去重,这个指纹集合也需要是共享的,Redis正好有集合的存储数据结构,我们可以利用Redis的集合作为指纹集合,那么这样去重集合也是利用Redis共享的。每台主机新生成Request之后,把该Request的指纹与集合比对,如果指纹已经存在,说明该Request是重复的,否则将Request的指纹加入到这个集合中即可。利用同样的原理不同的存储结构我们也实现了分布式Reqeust的去重。
四、防止中断
在Scrapy中,爬虫运行时的Request队列放在内存中。爬虫运行中断后,这个队列的空间就被释放,此队列就被销毁了。所以一旦爬虫运行中断,爬虫再次运行就相当于全新的爬取过程。
要做到中断后继续爬取,我们可以将队列中的Request保存起来,下次爬取直接读取保存数据即可获取上次爬取的队列。我们在Scrapy中指定一个爬取队列的存储路径即可,这个路径使用JOB_DIR变量来标识,我们可以用如下命令来实现:
scrapy crawl spider -s JOB_DIR=crawls/spider更加详细的使用方法可以参见官方文档,链接为:https://doc.scrapy.org/en/latest/topics/jobs.html。
在Scrapy中,我们实际是把爬取队列保存到本地,第二次爬取直接读取并恢复队列即可。那么在分布式架构中我们还用担心这个问题吗?不需要。因为爬取队列本身就是用数据库保存的,如果爬虫中断了,数据库中的Request依然是存在的,下次启动就会接着上次中断的地方继续爬取。
所以,当Redis的队列为空时,爬虫会重新爬取;当Redis的队列不为空时,爬虫便会接着上次中断之处继续爬取。
五、架构实现
我们接下来就需要在程序中实现这个架构了。首先实现一个共享的爬取队列,还要实现去重的功能。另外,重写一个Scheduer的实现,使之可以从共享的爬取队列存取Request。
幸运的是,已经有人实现了这些逻辑和架构,并发布成叫Scrapy-Redis的Python包。接下来,我们看看Scrapy-Redis的源码实现,以及它的详细工作原理。
本资源首发于崔庆才的个人博客静觅: Python3网络爬虫开发实战教程 | 静觅
如想了解更多爬虫资讯,请关注我的个人微信公众号:进击的Coder
weixin.qq.com/r/5zsjOyvEZ… (二维码自动识别)
