

前提:
某大型跨境电商业务发展非常快,线上机器扩容也很频繁,但是对于线上机器的运行情况,特别是jvm内存的情况,一直没有一个统一的标准来给到各个应用服务的owner。经过618大促之后,和运维的同学讨论了下,希望将线上服务器的jvm参数标准化,可以以一个统一的方式给到各个应用,提升线上服务器的稳定性,同时减少大家都去调整jvm参数的时间。
参考了之前在淘宝天猫工作的公司的经历:经过大家讨论,根据jdk的版本以及线上机器配置,确定了一个推荐的默认jvm模版:
最终推荐的jvm模版:
jdk版本 机器配置 建议jvm参数 备注
jdk1.7 6V8G -server -Xms4g -Xmx4g -Xmn2g -Xss768k -XX:PermSize=512m -XX:MaxPermSize=512m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:+DisableExplicitGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=68 -verbose:gc -XX:+PrintGCDetails -Xloggc:{CATALINA_BASE}/logs/gc.log -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={CATALINA_BASE}/logs 前台
jdk1.7 8V8G -server -Xms4g -Xmx4g -Xmn2g -Xss768k -XX:PermSize=512m -XX:MaxPermSize=512m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:+DisableExplicitGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=68 -verbose:gc -XX:+PrintGCDetails -Xloggc:{CATALINA_BASE}/logs/gc.log -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={CATALINA_BASE}/logs 前台
jdk1.7 4V8G -server -Xms4g -Xmx4g -Xmn2g -Xss768k -XX:PermSize=512m -XX:MaxPermSize=512m -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSClassUnloadingEnabled -XX:+DisableExplicitGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=68 -verbose:gc -XX:+PrintGCDetails -Xloggc:{CATALINA_BASE}/logs/gc.log -XX:+PrintGCDateStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath={CATALINA_BASE}/logs 前台
jdk1.7 6V8G -server -Xms4g -Xmx4g -XX:MaxPermSize=512m \
-verbose:gc -XX:+PrintGCDetails -Xloggc{CATALINA_BASE}/logs/gc.log -XX:+PrintGCTimeStamps \ 后台
某互联网(bat)公司的推荐配置:

配置说明:
1. 堆设置
o -Xms:初始堆大小
o -Xmx:最大堆大小
o -XX:NewSize=n:设置年轻代大小
o -XX:NewRatio=n:设置年轻代和年老代的比值。如:为3,表示年轻代与年老代比值为1:3,年轻代占整个年轻代年老代和的1/4
o -XX:SurvivorRatio=n:年轻代中Eden区与两个Survivor区的比值。注意Survivor区有两个。如:3,表示Eden:Survivor=3:2,一个Survivor区占整个年轻代的1/5
o -XX:MaxPermSize=n:设置持久代大小
2. 收集器设置
o -XX:+UseSerialGC:设置串行收集器
o -XX:+UseParallelGC:设置并行收集器
o -XX:+UseParalledlOldGC:设置并行年老代收集器
o -XX:+UseConcMarkSweepGC:设置并发收集器
3. 垃圾回收统计信息
-XX:+PrintGC
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:filename
"
4. 并行收集器设置
-XX:ParallelGCThreads=n:设置并行收集器收集时使用的CPU数。并行收集线程数。
-XX:MaxGCPauseMillis=n:设置并行收集最大暂停时间
-XX:GCTimeRatio=n:设置垃圾回收时间占程序运行时间的百分比。公式为1/(1+n)
5. 并发收集器设置
-XX:+CMSIncrementalMode:设置为增量模式。适用于单CPU情况。
-XX:ParallelGCThreads=n:设置并发收集器年轻代收集方式为并行收集时,使用的CPU数。并行收集线程数。
(4)
参数解释:
-Xms3072m -Xmx3072m
针对JVM堆的设置,通过-Xms -Xmx限定其最小、最大值
-Xmn1024m设置年轻代大小为1024m
整个JVM内存大小=年轻代大小 + 年老代大小 + 持久代大小(perm)。
-Xss768k 设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。更具应用的线程所需内存大小进行调整。在相同物理内存下,减小这个值能生成更多的线程。但是操作系统对一个进程内的线程数还是有限制的,不能无限生成,经验值在3000~5000左右。
-XX:PermSize=512m -XX:MaxPermSize=512m
持久代一般固定大小为64m,所以增大年轻代后,将会减小年老代大小。此值对系统性能影响较大,Sun官方推荐配置为整个堆的3/8。
设置非堆内存初始值,默认是物理内存的1/64;由XX:MaxPermSize设置最大非堆内存的大小,默认是物理内存的1/4
-XX:+UseConcMarkSweepGC
CMS收集器也被称为短暂停顿并发收集器。它是对年老代进行垃圾收集的。CMS收集器通过多线程并发进行垃圾回收,尽量减少垃圾收集造成的停顿。CMS收集器对年轻代进行垃圾回收使用的算法和Parallel收集器一样。这个垃圾收集器适用于不能忍受长时间停顿要求快速响应的应用。
-XX:+UseParNewGC对年轻代采用多线程并行回收,这样收得快;
-XX:+CMSClassUnloadingEnabled
如果你启用了CMSClassUnloadingEnabled ,垃圾回收会清理持久代,移除不再使用的classes。这个参数只有在 UseConcMarkSweepGC 也启用的情况下才有用。
-XX:+DisableExplicitGC禁止System.gc(),免得程序员误调用gc方法影响性能;
-XX:+UseCMSInitiatingOccupancyOnly
标志来命令JVM不基于运行时收集的数据来启动CMS垃圾收集周期。而是,当该标志被开启时,JVM通过CMSInitiatingOccupancyFraction的值进行每一次CMS收集,而不仅仅是第一次。然而,请记住大多数情况下,JVM比我们自己能作出更好的垃圾收集决策。因此,只有当我们充足的理由(比如测试)并且对应用程序产生的对象的生命周期有深刻的认知时,才应该使用该标志。
-XX:CMSInitiatingOccupancyFraction=68
默认CMS是在tenured generation(年老代)占满68%的时候开始进行CMS收集,如果你的年老代增长不是那么快,并且希望降低CMS次数的话,可以适当调高此值;
-XX:+UseParNewGC:对年轻代采用多线程并行回收,这样收得快;
-XX:HeapDumpPath
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-Xloggc:/usr/aaa/dump/heap_trace.txt
上面的的参数打Heap Dump信息
" -XX:+HeapDumpOnOutOfMemoryError
此参数可以控制OutOfMemoryError时打印堆的信息
大家可能注意到了,这里推荐采用cms方式进行垃圾回收;
CMS是一种以获取最短回收停顿时间为目标的收集器,可以有效减少服务器停顿的时间;
CMS的GC线程对CPU的占用率会比较高,但在多核的服务器上还是展现了优越的特性,目前也被部署在国内的各大电商网站上。所以这里强烈推荐!
cms的概念:
CMS收集器也被称为短暂停顿并发收集器。它是对年老代进行垃圾收集的。CMS收集器通过多线程并发进行垃圾回收,尽量减少垃圾收集造成的停顿。CMS收集器对年轻代进行垃圾回收使用的算法和Parallel收集器一样。这个垃圾收集器适用于不能忍受长时间停顿要求快速响应的应用。CMS采用了多种方式尽可能降低GC的暂停时间,减少用户程序停顿。停顿时间降低的同时牺牲了CPU吞吐量 。这是在停顿时间和性能间做出的取舍,可以简单理解为"空间(性能)"换时间。
调整的节奏:
由于怕影响线上应用,所以调整的步骤分三步:
第一步:部分影响少量机器试点,对比未调整的机器,观察调整后的结果;
第二步:调整部分应用的参数,进行压测,观察高并发压测之后的效果;
第三步:调整部分核心应用的jvm参数,通过818大促来实际检验效果;
目前818大促已经结果。正好做一个个总结。
一:长期表现,
第一个变化:fgc的次数减少,减少了大概一倍以上;
mobile工程,调整前基本上一天1-2辆次,调整后基本上就是2-3天一次: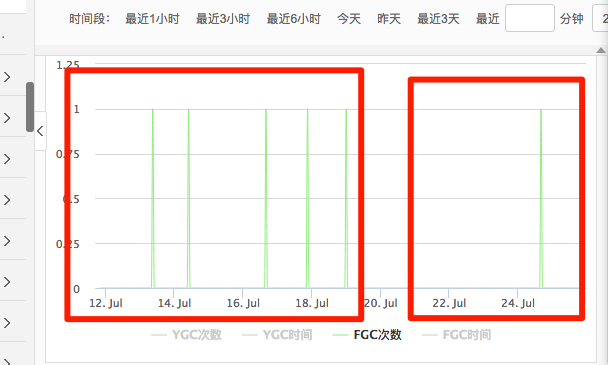
online(另外一个工程):可以明显看到fgc的统计频率少了很多;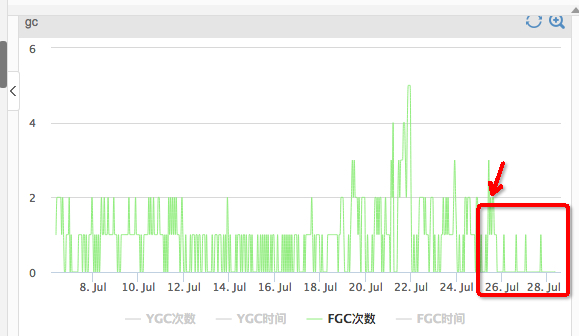
第二个变化:fgc的时间减少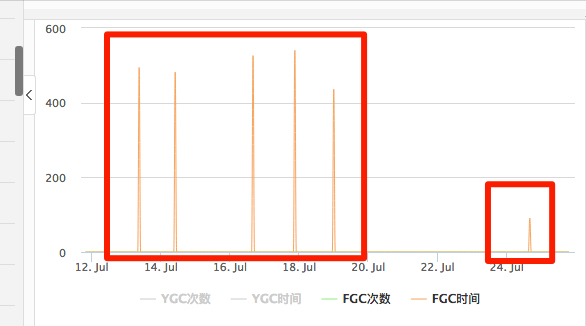
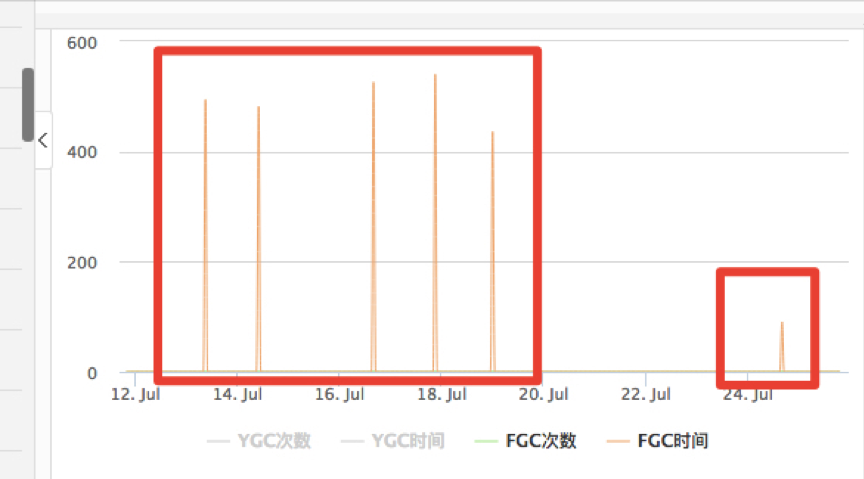
原来一次fgc要将近500ms,现在只要100ms不到了。
也证明了cms最大的好处就是减少fgc的停顿时间。
二:压测及大促表现
fgc的时间基本上是大大缩短,yanggc的时间变长,次数变化不大;
数据来源:测试团队的压测总结
说明 | ||||
fullgc次数 | 1 | 1 | 1 | |
fullgc总时间 | 343 | 250 | 1219 | |
默认垃圾收集器/CMS fullgc 时间 | 3.55 | 4.88 | CMS fullgc时间比默认垃圾收集器时间明显要少。 | |
fullgc时间点 | 2:48:36 | 3:14:36 | 5:30:36 | |
fullgc时使用率CPU% | 40% | 10% | 16% | |
fullgc时的load Average | 1.19 | 0.49 | 1.21 | |
younggc总次数 | 1094 | 1098 | 1078 | |
younggc总时间 | 44093 | 44632 | 30387 | |
younggc平均时间 | 40.30 | 40.65 | 28.19 | |
younggc最大时间 | 1332 | 1268 | 928 | |
CMS/默认垃圾收集器(younggc总时间) | 1.45 | 1.47 | CMS younggc时间比默认垃圾收集器耗时 | |
CMS/默认垃圾收集器(younggc平均时间) | 1.43 | 1.44 | CMS younggc时间比默认垃圾收集器耗时 | |
CMS/默认垃圾收集器(younggc最大时间) | 1.44 | 1.37 | CMS younggc时间比默认垃圾收集器最差情况要差 |
<!--EndFragment-->
三:关于哨兵上统计full gc的次数的解释,哨兵上
我们可以安全的说:
1. Full GC == Major GC指的是对老年代/永久代的stop the world的GC
2. Full GC的次数 = 老年代GC时 stop the world的次数
3. Full GC的时间 = 老年代GC时 stop the world的总时间
4. CMS 不等于Full GC,我们可以看到CMS分为多个阶段,只有stop the world的阶段被计算到了Full GC的次数和时间,而和业务线程并发的GC的次数和时间则不被认为是Full GC
Full GC的次数说的是stop the world的次数,所以一次CMS至少会让Full GC的次数+2,因为CMS Initial mark和remark都会stop the world,记做2次。而CMS可能失败再引发一次Full GC
如果CMS并发GC过程中出现了concurrent mode failure的话那么接下来就会做一次mark-sweep-compact的full GC,这个是完全stop-the-world的。
正是这个特征,使得CMS的每个并发GC周期总共会更新full GC计数器两次,initial mark与final re-mark各一次;如果出现concurrent mode failure,则接下来的full GC自己算一次。
四:遇到的几个问题:
问题一:堆栈溢出;
-Xss256k这个参数调整了,远涛反馈可能会影响trace的调用。 报如下错误:
Java.lang.StackOverflowError
at net.sf.jsqlparser.util.deparser.ExpressionDeParser.visitBinaryExpression(ExpressionDeParser.java:278)
at net.sf.jsqlparser.util.deparser.ExpressionDeParser.visit(ExpressionDeParser.java:246)
at net.sf.jsqlparser.expression.operators.conditional.OrExpression.accept(OrExpression.java:37)
at net.sf.jsqlparser.util.deparser.ExpressionDeParser.visitBinaryExpression(ExpressionDeParser.java:278)
at net.sf.jsqlparser.util.deparser.ExpressionDeParser.visit(ExpressionDeParser.java:246)
因为这个参数是设置每个线程的堆栈大小。JDK5.0以后每个线程堆栈大小为1M,以前每个线程堆栈大小为256K。在相同物理内存下,减小这个值能生成更多的线程。
所以今天去掉某台inventory机器的-Xss256k参数,看一下是不是这个导致的
问题二:初始化标记阶段耗时过长:
一般的建议是cms阶段两次STW的时间不超过200ms,如果是CMS Initial mark阶段导致的时间过长:
在初始化标记阶段(CMS Initial mark),为了最大限度地减少STW的时间开销,我们可以使用:
-XX:+CMSParallelInitialMarkEnabled
开启初始标记过程中的并行化,进一步提升初始化标记效率;
问题三:remark阶段stw的时间过长
如下图: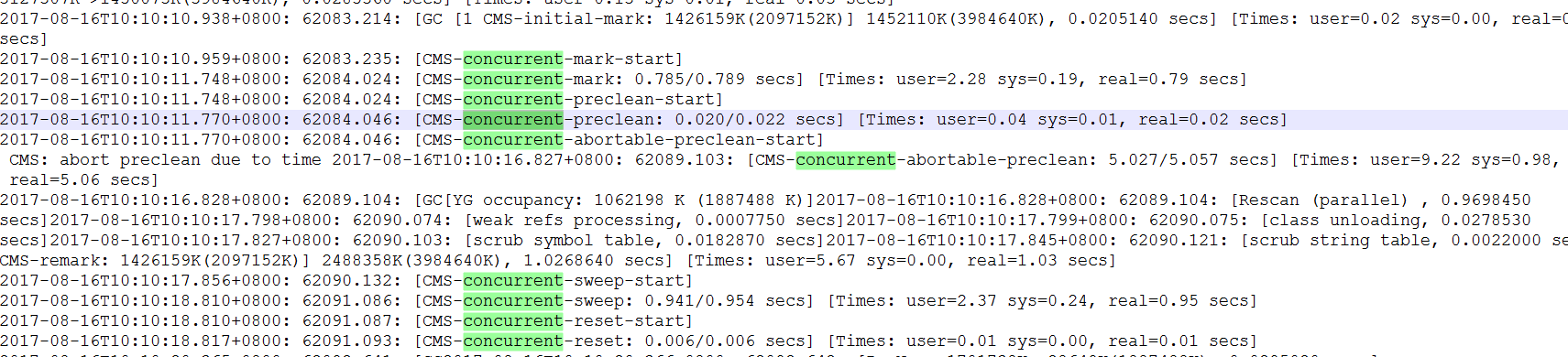
可以采用的方式是:
在CMS GC前启动一次ygc,目的在于减少old gen对ygc gen的引用,降低remark时的开销-----一般CMS的GC耗时 80%都在remark阶段
-XX:+CMSScavengeBeforeRemark
jmap分析:
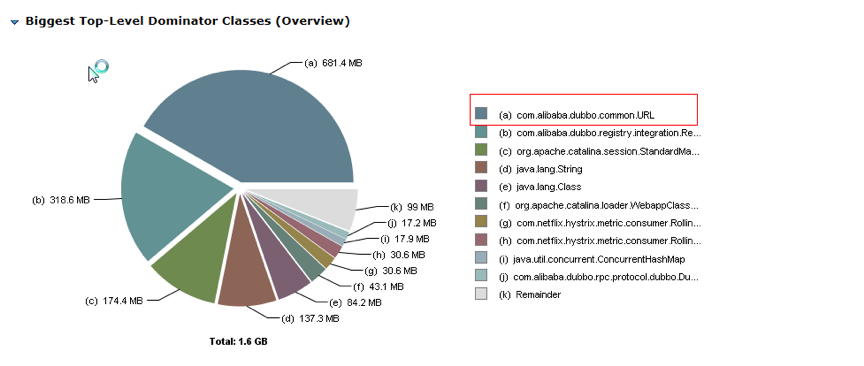
问题四:nio框架占用DirectMemory导致的OutOfMemoryError
处理方式:使用XX:+DisableExplicitGC
增加DirectMemory的大小;
1、DirectMemory不属于java堆内存、分配内存其实是调用操作系统的Os:malloc()函数。
2、容量可通过-XX:MaxDirectMemorySize指定,如果不指定,则默认与Java堆的最大值(-Xmx指定)一样。注意 ibm jvm默认Direct Memory与-Xmx无直接关系。
3、Direct Memory 内存的使用避免Java堆和Native堆中来回复制数据。从某些场景中提高性能。
4、直接ByteBuffer对象会自动清理本机缓冲区,但这个过程只能作为Java堆GC的一部分来执行,因此它们不会自动响应施加在本机堆上的压力。
5、GC仅在Java堆被填满,以至于无法为堆分配请求提供服务时发生,或者在Java应用程序中显示调用System.gc()函数来释放内存(一些NIO框架就是用这个方法释放占用的DirectMemory)。
6、该区域使用不合理,也是会引起OutOfMemoryError。
7、在需要频繁创建Buffer的场合,由于创建和销毁DirectBuffer的代价比较高昂,是不宜使用DirectBuffer的,但是如果能将DirectBuffer进行复用,那么 ,在读写频繁的情况下,它完全可以大幅改善性能。(对DirectBuffer的读写比普通Buffer快,但是对他的创建和销毁比普通Buffer慢)。
