一、SVM支持向量机
1、SVM原理
在机器学习,支持向量机的监督学习模型与相关的学习算法可以分析用于数据分类和回归分析。给定一组训练样例,每个训练样例被标记为属于两个类别中的一个或另一个,SVM训练算法建立一个模型,将新的例子分配给一个类别或另一个类别,使其成为非概率二元线性分类器(尽管方法如Platt缩放存在以在概率分类设置中使用SVM)。SVM模型是将这些例子表示为空间中的点的映射,以便将各个类别的例子除以尽可能宽的明显差距。然后将新示例映射到同一空间中,并预测属于基于它们落在哪一侧的类别。
比如,我们有两种颜色的球在桌子上,我们要分开它们。

我们拿到一根棍子放在桌子上,是否完成得很漂亮?
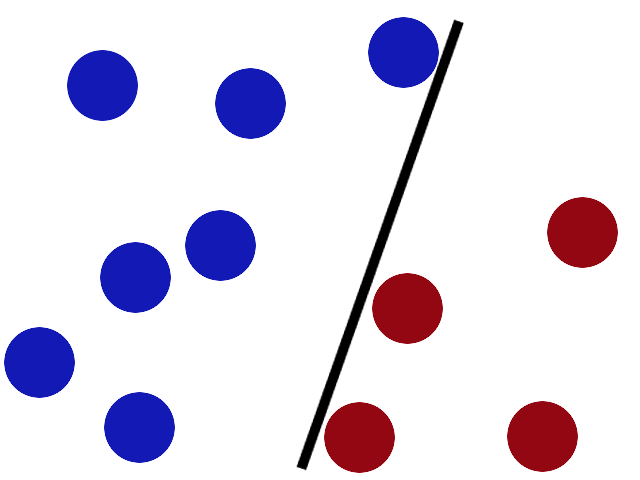
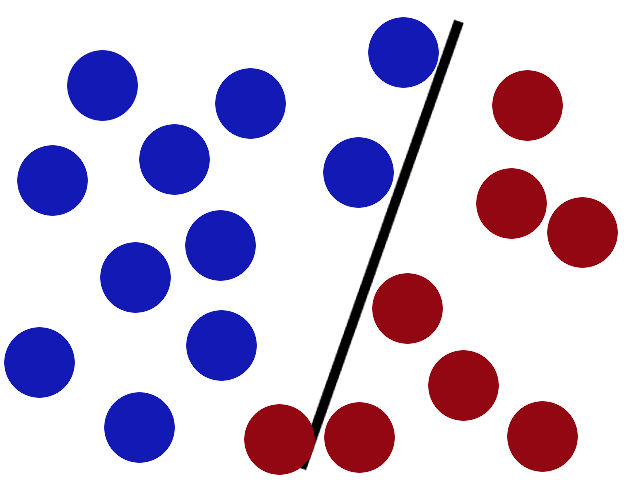
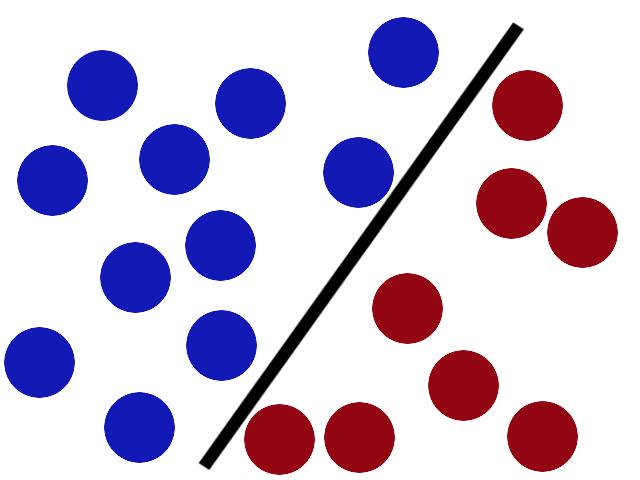
有些贱人来了,桌子上放了更多的球,这种方法很有效,但其中一个球在错误的一边,现在可能有一个更好的地方放置棒。
SVM试图通过尽可能在棒的两侧留出尽可能大的间隙来将棒放置在最佳位置。
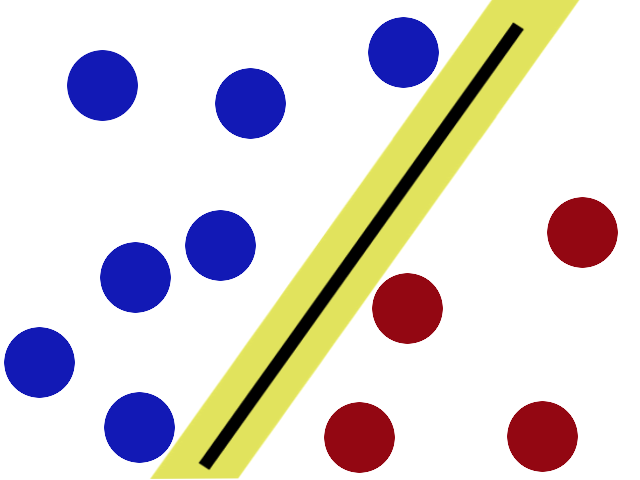
现在,当贱人回来时,棍子仍然是一个不错的位置。
SVM工具箱还有另一个更重要的技巧。贱人已经看到你用棍子有多好,所以他给了你一个新的挑战。

世界上没有任何棍棒可以让你分球,所以你会怎么做?你当然翻桌子!把球扔进空中。然后,用你的专业忍者技能,你抓住一张纸并将其滑入球之间。
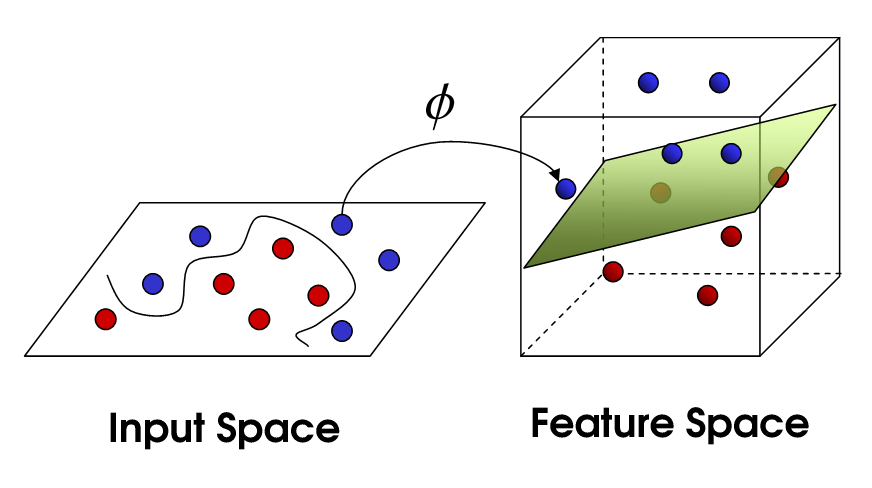
现在,贱人站着看球,他们的球会看起来被一些弯曲的线条分开。
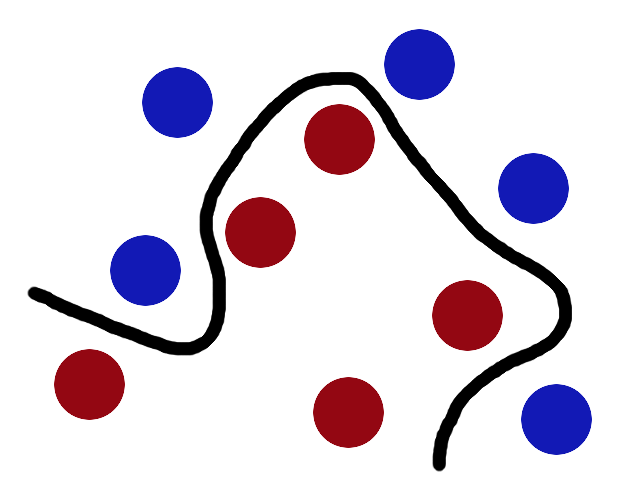
再之后,无聊的大人们,把这些球叫做 「data」,把棍子 叫做 「classifier」, 最大间隙trick 叫做「optimization」, 拍桌子叫做「kernelling」, 那张纸叫做「hyperplane」。
2、opencv的SVM参数
OpenCV 3.3中给出了支持向量机(Support Vector Machines)的实现,即cv::ml::SVM类,此类的声明在include/opencv2/ml.hpp文件中,实现在modules/ml/src/svm.cpp文件中,它既支持两分类,也支持多分类,还支持回归等,OpenCV中SVM的实现源自libsvm库。其中:
(1)、cv::ml::SVM类:继承自cv::ml::StateModel,而cv::ml::StateModel又继承自cv::Algorithm;
(2)、create函数:为static,new一个SVMImpl用来创建一个SVM对象;
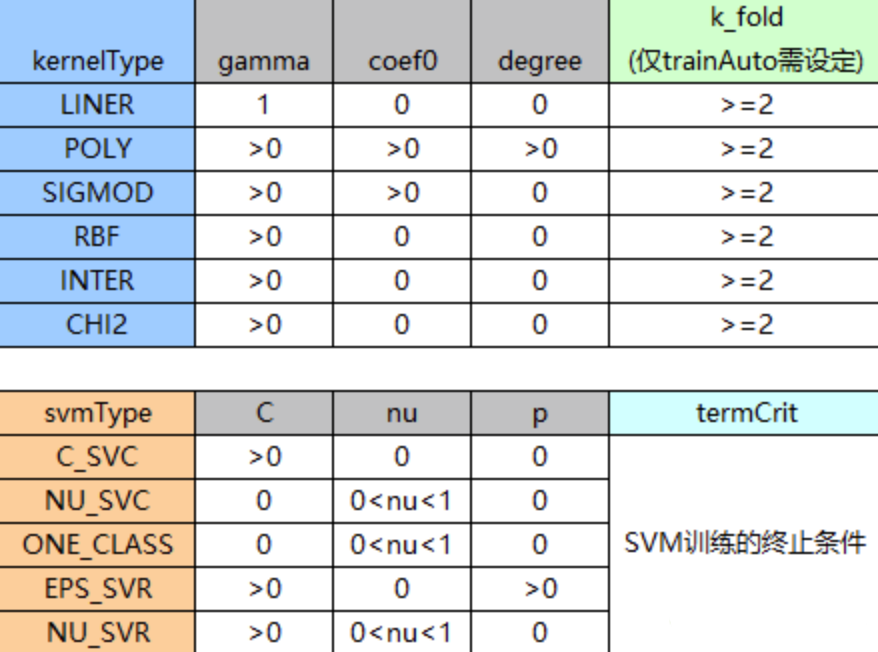
(3)、setType/getType函数:设置/获取SVM公式类型,包括C_SVC、NU_SVC、ONE_CLASS、EPS_SVR、NU_SVR,用于指定分类、回归等,默认为C_SVC;
(4)、setGamma/getGamma函数:设置/获取核函数的γ参数,默认值为1;
(5)、setCoef0/getCoef0函数:设置/获取核函数的coef0参数,默认值为0;
(6)、setDegree/getDegree函数:设置/获取核函数的degreee参数,默认值为0;
(7)、setC/getC函数:设置/获取SVM优化问题的C参数,默认值为0;
(8)、setNu/getNu函数:设置/获取SVM优化问题的υ参数,默认值为0;
(9)、setP/getP函数:设置/获取SVM优化问题的ε参数,默认值为0;
(10)、setClassWeights/getClassWeights函数:应用在SVM::C_SVC,设置/获取weights,默认值是空cv::Mat;
(11)、setTermCriteria/getTermCriteria函数:设置/获取SVM训练时迭代终止条件,默认值是cv::TermCriteria(cv::TermCriteria::MAX_ITER + TermCriteria::EPS,1000, FLT_EPSILON);
(12)、setKernel/getKernelType函数:设置/获取SVM核函数类型,包括CUSTOM、LINEAR、POLY、RBF、SIGMOID、CHI2、INTER,默认值为RBF;
(13)、setCustomKernel函数:初始化CUSTOM核函数;
(14)、trainAuto函数:用最优参数训练SVM;
(15)、getSupportVectors/getUncompressedSupportVectors函数:获取所有的支持向量;
(16)、getDecisionFunction函数:决策函数;
(17)、getDefaultGrid/getDefaultGridPtr函数:生成SVM参数网格;
(18)、save/load函数:保存/载入已训练好的model,支持xml,yaml,json格式;
(19)、train/predict函数:用于训练/预测,均使用基类StatModel中的。
原文链接:http://bytesizebio.net/2014/02/05/support-vector-machines-explained-well/
公式链接:https://en.wikipedia.org/wiki/Support_vector_machine
SVM参数链接:https://docs.opencv.org/master/d1/d2d/classcv_1_1ml_1_1SVM.html
实例
svm_type()—— 指定SVM的类型:
参数:
- C_SVC:C表示惩罚因子,C越大表示对错误分类的惩罚越大。
- NU_SVC:和C_SVC相同。
- ONE_CLASS:不需要类标号,用于支持向量的密度估计和聚类.
- EPSILON_SVR:-不敏感损失函数,对样本点来说,存在着一个不为目标函数提供任何损失值的区域,即-带。
- NU_SVR:由于EPSILON_SVR需要事先确定参数,然而在某些情况下选择合适的参数却不是一件容易的事情。而NU_SVR能够自动计算参数。
kernel_type()—— SVM的内核类型:
参数:
- LINEAR:线性核函数(linear kernel)
- POLY:多项式核函数(ploynomial kernel)
- RBF:径向机核函数(radical basis function)
- SIGMOID: 神经元的非线性作用函数核函数(Sigmoid tanh)
- PRECOMPUTED:用户自定义核函数
train()
参数:
- InputArray samples, 训练样本
- int layout, 排版,参数:ROW_SAMPLE,每个训练样本是一行样本,COL_SAMPLE,每个训练样本占据一列样本
- InputArray responses, 与训练样本相关联的响应向量
getDecisionFunction()
参数:
- int i,决策函数的索引。如果解决的问题是回归,1类或2类分类,那么只会有一个决策函数,并且索引应该总是0.否则,在N类分类的情况下,将会有N(N- 1 )/ 2 决策功能。
- OutputArray alpha, α 权重的可选输出向量,对应于不同的支持向量。在线性SVM的情况下,所有的alpha都是1。
- OutputArray svidx, 支持向量矩阵内的支持向量索引的可选输出向量。在线性SVM的情况下,每个决策函数由单个“压缩”支持向量组成。
import cv2
import numpy as np
import matplotlib.pyplot as plt
#1 准备data
rand1 = np.array([[155,48],[159,50],[164,53],[168,56],[172,60]])
# 女生身高和体重数据
rand2 = np.array([[152,53],[156,55],[160,56],[172,64],[176,65]])
# 男生身高和体重数据
# 2 建立分组标签,0代表女生,1代表男生
label = np.array([[0],[0],[0],[0],[0],[1],[1],[1],[1],[1]])
# 3 合并数据
data = np.vstack((rand1,rand2))
data = np.array(data,dtype='float32')
# 4 训练
# ml 机器学习模块 SVM_create() 创建
svm = cv2.ml.SVM_create()
# 属性设置
svm.setType(cv2.ml.SVM_C_SVC) # svm type
svm.setKernel(cv2.ml.SVM_LINEAR) # line
svm.setC(0.01)
# 训练
result = svm.train(data,cv2.ml.ROW_SAMPLE,label)
# 预测
pt_data = np.vstack([[167,55],[162,57]]) #0 女生 1男生
pt_data = np.array(pt_data,dtype='float32')
print(pt_data)
(par1,par2) = svm.predict(pt_data)
print(par2)
结果:
[[167. 55.]
[162. 57.]]
[[0.]
[1.]]
二、Hog特征
方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。它通过计算和统计图像局部区域的梯度方向直方图来构成特征。Hog特征结合SVM分类器已经被广泛应用于图像识别中,尤其在行人检测中获得了极大的成功。需要提醒的是,HOG+SVM进行行人检测的方法是法国研究人员Dalal在2005的CVPR上提出的,而如今虽然有很多行人检测算法不断提出,但基本都是以HOG+SVM的思路为主。
HOG特征提取算法的实现过程:
HOG特征提取方法就是将一个image(你要检测的目标或者扫描窗口):
1)灰度化(将图像看做一个x,y,z(灰度)的三维图像);
2)采用Gamma校正法对输入图像进行颜色空间的标准化(归一化);目的是调节图像的对比度,降低图像局部的阴影和光照变化所造成的影响,同时可以抑制噪音的干扰;
3)计算图像每个像素的梯度(包括大小和方向);主要是为了捕获轮廓信息,同时进一步弱化光照的干扰。
4)将图像划分成小cells(例如6*6像素/cell);
5)统计每个cell的梯度直方图(不同梯度的个数),即可形成每个cell的descriptor;
6)将每几个cell组成一个block(例如3*3个cell/block),一个block内所有cell的特征descriptor串联起来便得到该block的HOG特征descriptor。
7)将图像image内的所有block的HOG特征descriptor串联起来就可以得到该image(你要检测的目标)的HOG特征descriptor了。这个就是最终的可供分类使用的特征向量了。
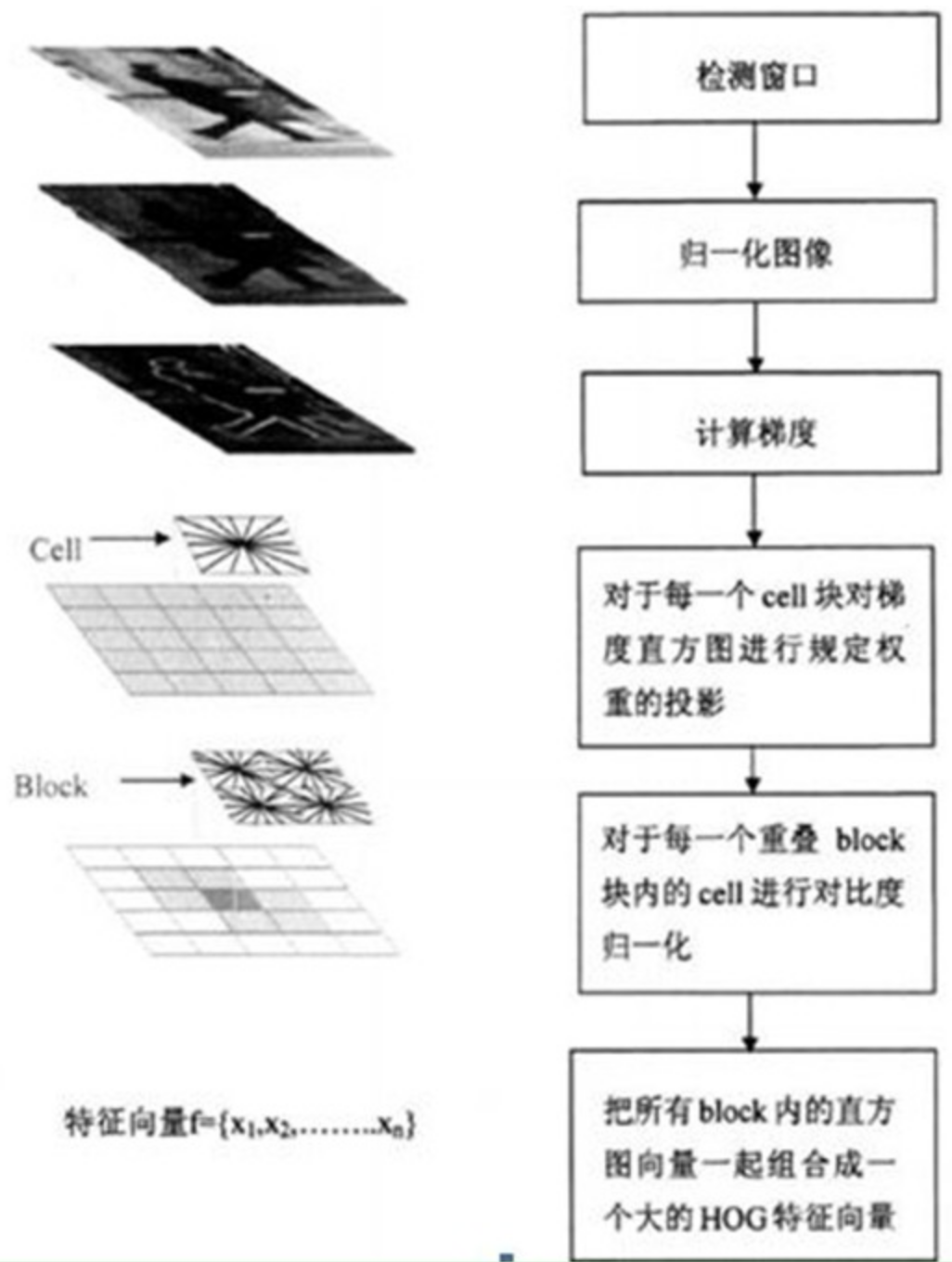
原文链接:https://blog.csdn.net/liulina603/article/details/8291093
三、实例
HOGDescriptor()
参数:
- Size win_size=Size(64, 128),检测窗口大小。
- Size block_size=Size(16, 16),块大小,目前只支持Size(16, 16)
- Size block_stride=Size(8, 8),块的滑动步长,大小只支持是单元格cell_size大小的倍数。
- Size cell_size=Size(8, 8),单元格的大小,目前只支持Size(8, 8)。
- int nbins=9, 直方图bin的数量(投票箱的个数),目前每个单元格Cell只支持9个。
- double win_sigma=DEFAULT_WIN_SIGMA,高斯滤波窗口的参数。
- double threshold_L2hys=0.2,块内直方图归一化类型L2-Hys的归一化收缩率
- bool gamma_correction=true,是否gamma校正
- nlevels=DEFAULT_NLEVELS,检测窗口的最大数量
正样本:
负样本:
import cv2
import numpy as np
import matplotlib.pyplot as plt
# 第一步:确定标准
PosNum = 820
# 正样本个数
NegNum = 1931
# 负样本个人
winSize = (64,128)
# 一个窗口(win)的大小是64x128
blockSize = (16,16)
# 每个块的大小是16x16
blockStride = (8,8)
# 每个块的步长是8x8
# 一个窗口有((64-16)/8+1)*((128-16)/8+1) = 7*15 = 105个块(block)
cellSize = (8,8)
# 每个胞元的大小是8x8
# 一个块(block)有 (16/8)*(16/8) = 4胞元(cell)
nBin = 9
# 一个胞元有 9 个bin,表示每一个胞元对应的向量就是9维
# 窗口对应的一维特征向量维数n = 105 * 4 * 9 = 3780
# hog+svm检测行人,最终的检测方法是最基本的线性判别函数,wx + b = 0,刚才所求的3780维向量其实就是w,而加了一维的b就形成了opencv默认的3781维检测算子
# 第二步:创造一个HOG描述子和检测器
hog = cv2.HOGDescriptor(winSize,blockSize,blockStride,cellSize,nBin)
# 第三步:启动SVM分离器
svm = cv2.ml.SVM_create()
# 第四步:计算Hog
featureNum = int(((128-16)/8+1)*((64-16)/8+1)*4*9)
# 窗口对应的一维特征向量维数n
featureArray = np.zeros(((PosNum+NegNum),featureNum),np.float32)
# 创建Hog特征矩阵
labelArray = np.zeros(((PosNum+NegNum),1),np.int32)
# 创建标签矩阵
# 给图片样本打标签,正样本是1,负样本是-1
for i in range(0,PosNum):
fileName = 'pos/'+str(i+1)+'.jpg'
# 导入正样本图片
img = cv2.imread(fileName)
hist = hog.compute(img,(8,8))
# 每个hog特性的维数是3780
for j in range(0,featureNum):
featureArray[i,j] = hist[j]
# featureArray装载hog特征, [1,:]代表hog特征1, [2,:]代表hog特征2
labelArray[i,0] = 1
# 正样本的label是 1
for i in range(0,NegNum):
fileName = 'neg/'+str(i+1)+'.jpg'
img = cv2.imread(fileName)
hist = hog.compute(img,(8,8))
for j in range(0,featureNum):
featureArray[i+PosNum,j] = hist[j]
labelArray[i+PosNum,0] = -1
# 负样本的label是 -1
# SVM属性设置
svm.setType(cv2.ml.SVM_C_SVC)
# SVM模型类型:C_SVC表示SVM分类器,C_SVR表示SVM回归
svm.setKernel(cv2.ml.SVM_LINEAR)
# 核函数类型: LINEAR:线性核函数(linear kernel),POLY:多项式核函数(ploynomial kernel),RBF:径向机核函数(radical basis function),SIGMOID: 神经元的非线性作用函数核函数(Sigmoid tanh),PRECOMPUTED:用户自定义核函数
svm.setC(0.01)
# SVM类型(C_SVC/ EPS_SVR/ NU_SVR)的参数C,C表示惩罚因子,C越大表示对错误分类的惩罚越大
# 第六步:训练函数
ret = svm.train(featureArray,cv2.ml.ROW_SAMPLE,labelArray)
# 第七步:检测 (1、创建myhog,参数myDeteect)
alpha = np.zeros((1),np.float32)
# 权重的可选输出向量
rho = svm.getDecisionFunction(0,alpha)
# 检索决策函数。
print(rho)
print(alpha)
alphaArray = np.zeros((1,1),np.float32)
supportVArray = np.zeros((1,featureNum),np.float32)
resultArray = np.zeros((1,featureNum),np.float32)
alphaArray[0,0] = alpha
resultArray = -1*alphaArray*supportVArray
myDetect = np.zeros((3781),np.float32)
for i in range(0,3780):
myDetect[i] = resultArray[0,i]
myDetect[3780] = rho[0]
# myDetect是3781维,其中3780维来自resultArray,最后一维来自rho
myHog = cv2.HOGDescriptor()
myHog.setSVMDetector(myDetect)
# 第八步:导入待检测图片的加载
imageSrc = cv2.imread('Test2.jpg',1)
# 加载待检测图片
objs = myHog.detectMultiScale(imageSrc,0,(8,8),(32,32),1.05,2)
# 检测图片
x = int(objs[0][0][0])
y = int(objs[0][0][1])
w = int(objs[0][0][2])
h = int(objs[0][0][3])
# 原始坐标(x,y),宽w,高h
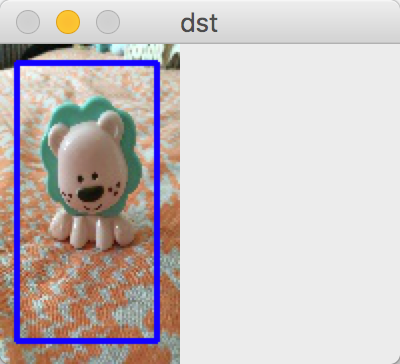
# 第九步:绘制展示
cv2.rectangle(imageSrc,(x,y),(x+w,y+h),(255,0,0),2)
cv2.imshow('dst',imageSrc)
cv2.waitKey(0)
待检测图片:

结果:
(0.19296025963377925, array([[1.]]), array([[0]], dtype=int32))
[0.]