

- 原文地址:How JavaScript works: Service Workers, their lifecycle and use cases
- 原文作者:Alexander Zlatkov
- 译文出自:掘金翻译计划
- 本文永久链接:github.com/xitu/gold-m…
- 译者:talisk
- 校对者:allen,赵立杨
这是专门探索 JavaScript 及其构建组件的系列的第八个。在识别和描述核心元素的过程中,我们也分享了一些我们在构建 SessionStack 时的最佳实践。SessionStack 是一个强大且性能卓越的 JavaScript 应用程序,可以向你实时显示用户在 Web 应用程序中遇到技术问题或用户体验问题时的具体情况。
如果你没看过之前的章节,你可以在这里看到:
- [译] JavaScript 是如何工作的:对引擎、运行时、调用堆栈的概述
- [译] JavaScript 是如何工作的:在 V8 引擎里 5 个优化代码的技巧
- [译] JavaScript 是如何工作的:内存管理 + 处理常见的4种内存泄漏
- [译] JavaScript 是如何工作的: 事件循环和异步编程的崛起 + 5个如何更好的使用 async/await 编码的技巧
- [译] JavaScript 是如何工作的:深入剖析 WebSockets 和拥有 SSE 技术 的 HTTP/2,以及如何在二者中做出正确的选择
- [译] JavaScript 是如何工作的:与 WebAssembly 一较高下 + 为何 WebAssembly 在某些情况下比 JavaScript 更为适用
- [译] JavaScript 是如何工作的:Web Worker 的内部构造以及 5 种你应当使用它的场景
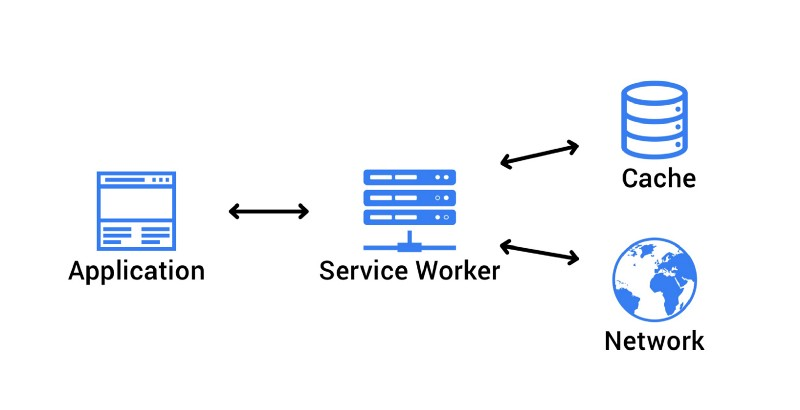
你可能已经知道了渐进式 Web 应用只会越来越受欢迎,因为它们旨在使 Web 应用的用户体验更加流畅,提供原生应用体验而不是浏览器的外观和感觉。
构建渐进式 Web 应用程序的主要要求之一是使其在网络和加载方面非常可靠 —— 它应该可用于不确定或不可用的网络条件。
在这篇文章中,我们将深入探讨 Service Worker:它们如何运作以及开发者应该关心什么。最后,我们还列出了开发者应该利用的 Service Worker 的一些独特优势,并在 SessionStack 中分享我们自己团队的经验。
概览
如果你想了解 Service Worker 的一切内容,你应该从阅读我们博客上,关于 Web Workers 的文章开始。
基本上,Service Worker 是 Web Worker 的一个类型,更具体地说,它像 Shared Worker:
- Service Worker 在其自己的全局上下文中运行
- 它没有绑定到特定的网页
- 它不能访问到 DOM
Service Worker API 令人兴奋的主要原因之一是它可以让你的网络应用程序支持离线体验,从而使开发人员能够完全控制流程。
Service Worker 的生命周期
Service Worker 的生命周期与你的网页是完全分开的,它由以下几个阶段组成:
- 下载
- 安装
- 激活
下载
这是浏览器下载包含 Service Worker 的 .js 文件的时候。
安装
要为你的Web应用程序安装 Service Worker,你必须先注册它,你可以在 JavaScript 代码中进行注册。当注册 Service Worker 时,它会提示浏览器在后台启动 Service Worker 安装步骤。
通过注册 Service Worker,你可以告诉浏览器你的 Service Worker 的 JavaScript 文件在哪里。我们来看下面的代码:
if ('serviceWorker' in navigator) {
window.addEventListener('load', function() {
navigator.serviceWorker.register('/sw.js').then(function(registration) {
// Registration was successful
console.log('ServiceWorker registration successful');
}, function(err) {
// Registration failed
console.log('ServiceWorker registration failed: ', err);
});
});
}
该代码检查当前环境中是否支持Service Worker API。如果是,则 /sw.js 这个 Service Worker 就被注册了。
每次页面加载时都可以调用 register() 方法,浏览器会判断 Service Worker 是否已经注册,并且会正确处理。
register() 方法的一个重要细节是 Service Worker 文件的位置。在这种情况下,你可以看到 Service Worker 文件位于域的根目录。这意味着 Service Worker 的范围将是整个网站。换句话说,这个 Service Worker 将会收到这个域的所有内容的 fetch 事件(我们将在后面讨论)。如果我们在 /example/sw.js 注册 Service Worker 文件,那么 Service Worker 只会看到以 /example/ 开头的页面的 fetch 事件(例如 /example/page1/、/example/page2/)。
在安装阶段,最好加载和缓存一些静态资源。资源成功缓存后,Service Worker 安装完成。如果没有成功(加载失败)—— Service Worker 将重试。一旦安装成功,静态资源就已经在缓存中了。
如果注册需要在加载事件之后发生,这就解答了你“注册是否需要在加载事件之后发生”的疑惑。这不是必要的,但绝对是推荐的。
为什么这样呢?让我们考虑用户第一次访问网络应用程序的情况。当前还没有 Service Worker,浏览器无法事先知道最终是否会安装 Service Worker。如果安装了 Service Worker,则浏览器需要为这个额外的线程承担额外的 CPU 和内存开销,否则浏览器会将计算资源用于渲染网页上。
最重要的是,如果在页面上安装一个 Service Worker,就可能会有延迟加载和渲染的风险 —— 而不是尽快让你的用户可以使用该页面。
请注意,这种情况仅仅是在第一次访问页面时很重要。后续页面访问不受 Service Worker 安装的影响。一旦在第一次访问页面时激活 Service Worker,它可以处理加载、缓存事件,以便随后访问 Web 应用程序。这一切都是有意义的,因为它需要准备好处理受限的的网络连接。
激活
安装 Service Worker 之后,下一步是将它激活。这一步是管理之前缓存内容的好机会。
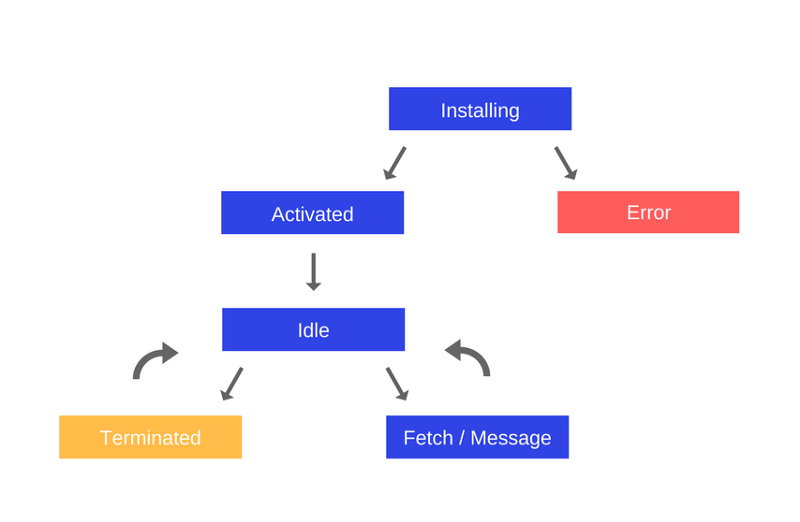
一旦激活,Service Worker 将开始控制所有属于其范围的页面。一个有趣的事实是:首次注册 Service Worker 的页面将不会被控制,直到该页面再次被加载。一旦 Service Worker 处于控制之下,它将处于以下状态之一:
- 它将处理当页面发出网络请求或消息时发生的 fetch 和 message 事件
- 它将被终止以节省内存
以下是生命周期的示意图:
处理 Service Worker 内部的装置
在页面处理注册过程之后,让我们看看 Service Worker 脚本中发生了什么,它通过向 Service Worker 实例添加事件监听来处理 install 事件。
这些是处理 install 事件时需要采取的步骤:
- 开启一个缓存
- 缓存我们的文件
- 确认是否缓存了所有必需的资源
在 Service Worker 内部的一个简单装置可能会看起来像这样:
var CACHE_NAME = 'my-web-app-cache';
var urlsToCache = [
'/',
'/styles/main.css',
'/scripts/app.js',
'/scripts/lib.js'
];
self.addEventListener('install', function(event) {
// event.waitUntil takes a promise to know how
// long the installation takes, and whether it
// succeeded or not.
event.waitUntil(
caches.open(CACHE_NAME)
.then(function(cache) {
console.log('Opened cache');
return cache.addAll(urlsToCache);
})
);
});
如果所有文件都成功缓存,则将安装 Service Worker。如果任何一个文件都无法下载,则安装步骤将失败。所以要小心你放在那里的文件。
处理 install 事件完全是可选的,你可以避免它,在这种情况下,你不需要执行这里的任何步骤。
运行时缓存请求
这部分是货真价实的内容。你将看到如何拦截请求并返回创建的缓存(以及创建新缓存)的位置。
在安装 Service Worker 后,用户进入了新的页面,或者刷新当前页面后,Service Worker 将收到 fetch 事件。 下面是一个演示如何返回缓存资源,或发送新请求后缓存结果的示例:
self.addEventListener('fetch', function(event) {
event.respondWith(
// This method looks at the request and
// finds any cached results from any of the
// caches that the Service Worker has created.
caches.match(event.request)
.then(function(response) {
// If a cache is hit, we can return thre response.
if (response) {
return response;
}
// Clone the request. A request is a stream and
// can only be consumed once. Since we are consuming this
// once by cache and once by the browser for fetch, we need
// to clone the request.
var fetchRequest = event.request.clone();
// A cache hasn't been hit so we need to perform a fetch,
// which makes a network request and returns the data if
// anything can be retrieved from the network.
return fetch(fetchRequest).then(
function(response) {
// Check if we received a valid response
if(!response || response.status !== 200 || response.type !== 'basic') {
return response;
}
// Cloning the response since it's a stream as well.
// Because we want the browser to consume the response
// as well as the cache consuming the response, we need
// to clone it so we have two streams.
var responseToCache = response.clone();
caches.open(CACHE_NAME)
.then(function(cache) {
// Add the request to the cache for future queries.
cache.put(event.request, responseToCache);
});
return response;
}
);
})
);
});
概括地说这其中发生了什么:
event.respondWith()将决定我们如何回应fetch事件。我们传递来自caches.match()的一个 promise,它检查请求并查找是否有已经创建的缓存结果。- 如果在缓存中,响应内容就被恢复了。
- 否则,将会执行
fetch。 - 检查状态码是不是
200,同时检查响应类型是 basic,表明响应来自我们最初的请求。在这种情况下,不会缓存对第三方资源的请求。 - 响应被缓存下来
请求和响应必须被复制,因为它们是流。流的 body 只能被使用一次。并且由于我们想消费它们,而浏览器也必须消费它们,因此我们便需要克隆它们。
上传 Service Worker
当有一个用户访问你的 web 应用,浏览器将尝试重新下载包含了 Service Worker 的 .js 文件。这将在后台执行。
如果与当前 Service Worker 的文件相比,新下载的 Service Worker 文件中存在哪怕一个字节的差异,则浏览器将会认为有变更,且必须启动新的 Service Worker。
新的 Service Worker 将启动并且安装事件将被移除。然而,在这一点上,旧的 Service Worker 仍在控制你的 web 应用的页面,这意味着新的 Service Worker 将进入 waiting 状态。
一旦你的 web 应用程序当前打开的页面都被关掉,旧的 Service Worker 就会被浏览器干掉,西南装的 Service Worker 将完全掌控应用。这就是它激活的事件将被干掉的时候。
为什么需要这些?为了避免两个版本的 Web 应用程序同时运行在不同的 tab 上 —— 这在网络上实际上非常常见,并且可能会产生非常糟糕的错误(例如,在浏览器中本地存储数据时,会有不同的 schema)。
从缓存中删除数据
activate 回调中最常见的步骤是缓存管理。我们应该现在做这件事,因为如果你在安装步骤中清除了所有旧缓存,旧的 Service Worker 将突然停止提供缓存中的文件。
这里提供了一个如何从缓存中删除一些不在白名单中的文件的例子(在本例中,有 page-1、page-2 两个实体):
self.addEventListener('activate', function(event) {
var cacheWhitelist = ['page-1', 'page-2'];
event.waitUntil(
// Retrieving all the keys from the cache.
caches.keys().then(function(cacheNames) {
return Promise.all(
// Looping through all the cached files.
cacheNames.map(function(cacheName) {
// If the file in the cache is not in the whitelist
// it should be deleted.
if (cacheWhitelist.indexOf(cacheName) === -1) {
return caches.delete(cacheName);
}
})
);
})
);
});
HTTPS 要求
在构建 Web 应用程序时,开发者可以通过本地主机使用 Service Worker,但是一旦将其部署到生产环境中,则需要准备好 HTTPS(这是拥有 HTTPS 的最后一个原因)。
使用 Service Worker,你可以劫持连接并伪造响应。若不使用 HTTPS,你的 web 应用程序变得容易发生中间人攻击。
为了更安全,你需要在通过 HTTPS 提供的页面上注册 Service Worker,以便知道浏览器接收的 Service Worker 在通过网络传输时未被修改。
浏览器支持
浏览器对 Service Worker 的支持正在变得越来越好:

你可以在这个网站上追踪所有浏览器的适配进程 —— jakearchibald.github.io/isservicewo…。
Service Workers 正在打开美好特性的大门
Service Worker 提供的一些独一无二的特性:
- 推送通知 —— 允许用户选择从 web 应用程序及时获取通知。
- 后台同步 —— 在用户网络不稳定时,允许开发者推迟操作,直到用户具有稳定的连接。这样,就可以确保无论用户想要发送什么数据,都可以发出去。
- 定时同步(未来支持)—— 提供管理定期后台同步功能的 API。
- 地理围栏(未来支持)—— 开发者可以自定义参数,创建感兴趣区域的地理围栏。当设备跨越地理围栏时,Web 应用程序会收到通知,这可以让开发者根据用户的地理位置提供有效服务。
这些将在本系列未来的博客文章中详细讨论。
我们一直致力于使 SessionStack 的用户体验尽可能流畅,优化页面加载和响应时间。
当你在 SessionStack(或实时观看)中重播用户会话时,SessionStack 前端将不断从我们的服务器提取数据,以便无缝地创建缓冲区,像你刚才,同本文中一样的经历。为了提供一些上下文 —— 一旦你将 SessionStack 的库集成到 Web 应用程序中,它将不断收集诸如 DOM 更改,用户交互,网络请求,未处理的异常和调试消息等数据。
当会话正在重播或实时流式传输时,SessionStack 会提供所有数据,让开发者可以在视觉和技术上查看用户在自己的浏览器中体验到的所有内容。这一切都需要快速实现,因为我们不想让用户等待。
由于数据是由我们的前端提取的,因此这是一个很好的地方,可以利用 Service Worker 来重新加载我们的播放器,以及重新传输数据流等情况。处理较慢的网络连接也非常重要。
如果你想尝试 SessionStack,这有个免费的计划。
参考资料
掘金翻译计划 是一个翻译优质互联网技术文章的社区,文章来源为 掘金 上的英文分享文章。内容覆盖 Android、iOS、前端、后端、区块链、产品、设计、人工智能等领域,想要查看更多优质译文请持续关注 掘金翻译计划、官方微博、知乎专栏。
