

背景
基于维度模型理论的数据仓库中,一个特别重要的部分是渐变维度的处理,其中用的最多的方法是对维度表进行SCD2类型拉链表操作。具体实现使用upsert模式,即更新旧数据的时间戳,并且插入新数据。
但是在使用Hive作为数据仓库的场景下,对SCD2的操作就比较麻烦。因为Hive不支持更新操作,所以通常做法是把流程中的各部分数据清洗后单独保存为独立的临时表,然后通过union all的方式对目标表进行overwrite操作。
不过,通过一些特殊的配置,可以开启Hive对ACID的支持特性,从而实现对Hive进行update,delete这些操作。
本文以HDP 2.4版本为例,演示一下如何实现这个需求。这里先简要描述需要执行的步骤。
- 开启hive acid特性(通过Ambari操作)
- 建立支持acid的hive表(满足bucket,orc,tblproperties的要求)
- 演示基本DML操作(insert, update, delete)
- SCD 2算法的一个简单实现
- acid特性的不足(当前还不支持Spark SQL)
前置条件
Hive全局配置
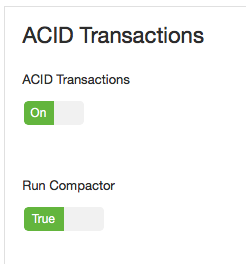
首先必须开启Hive对ACID事务的支持。在Amabri界面修改hive配置,打开ACID Transactions,如下图
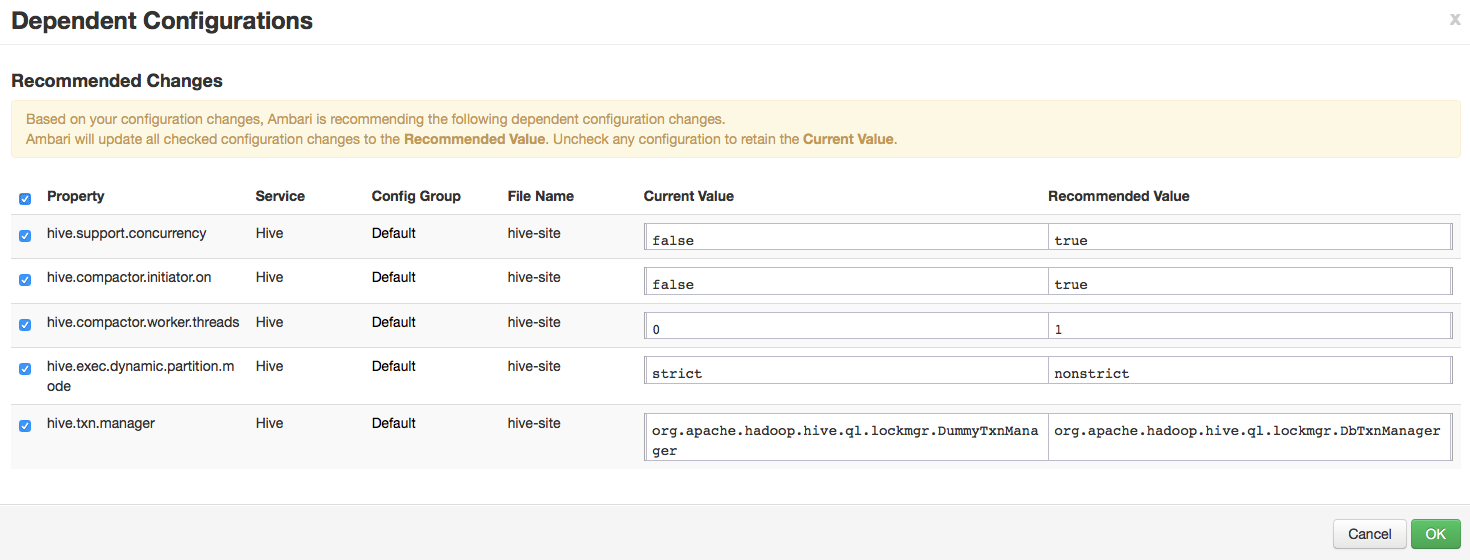
在开启这个配置的时候,Amabri会提示是否自动修改一些其他的参数,选择OK确定即可,如下图
Hive表格式
一个hive表要支持事务,需要同时满足下列条件:
- 使用bucket,注意这里不是partition,而是bucket;
- 保存为ORC格式;
- 指定表属性transactional
一个满足上述条件的建表语句如下
create table if not exists demo(
area_id bigint,
area_code string,
area_name string,
gmt_create timestamp
)
clustered by (area_id) into 8 buckets
stored as orc
tblproperties('transactional'='true')
;
演示数据
本例中使用到三张表:
- demo_d01 初始化数据
- demo_d02 变量数据,包括新增的数据,以及对原有数据的修改
- demo_d00 需要进行SCD2操作的目标表
demo_d01
-- init table
drop table if exists demo_d01;
create table if not exists demo_d01(
area_id bigint,
area_code string,
area_name string,
gmt_create timestamp
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
;
初始化数据,样本如下,是在2015-09-25这天的数据
47498,CHNP001,北京,2015-09-25 11:34:29.0
47499,CHNP002,天津,2015-09-25 11:34:29.0
47500,CHNP003,河北,2015-09-25 11:34:29.0
47501,CHNP004,山西,2015-09-25 11:34:29.0
47502,CHNP005,内蒙古,2015-09-25 11:34:29.0
demo_d02
-- delta table
drop table if exists demo_d02;
create table if not exists demo_d02(
area_id bigint,
area_code string,
area_name string,
gmt_create timestamp
)
row format delimited
fields terminated by ','
lines terminated by '\n'
stored as textfile
;
变量数据,包括新增的数据,以及对原有数据的修改。样本如下,模拟2015-09-26的变量数据,包括一条新增和一条修改。并且为了简化后面SCD的演示,使用了提前生成好的代理关键字area_id
57502,CHNP005,内蒙古-新,2015-09-26 11:34:29.0
57509,CHNP006,四川,2015-09-26 11:34:29.0
demo_d00
这个表同时满足前面提到的几个条件,可以支持ACID事务操作。
-- target table
drop table if exists demo_d00;
create table if not exists demo_d00(
area_id bigint,
area_code string,
area_name string,
gmt_create timestamp
)
clustered by (area_id) into 8 buckets
stored as orc
tblproperties('transactional'='true')
;
ACID事务操作
这里先简单讲解一下DML操作的实现,不涉及SCD部分。并且为了方便演示文件夹中的文件数量变化,这里仅使用了一个bucket,而不是建表脚本中的8个。
insert
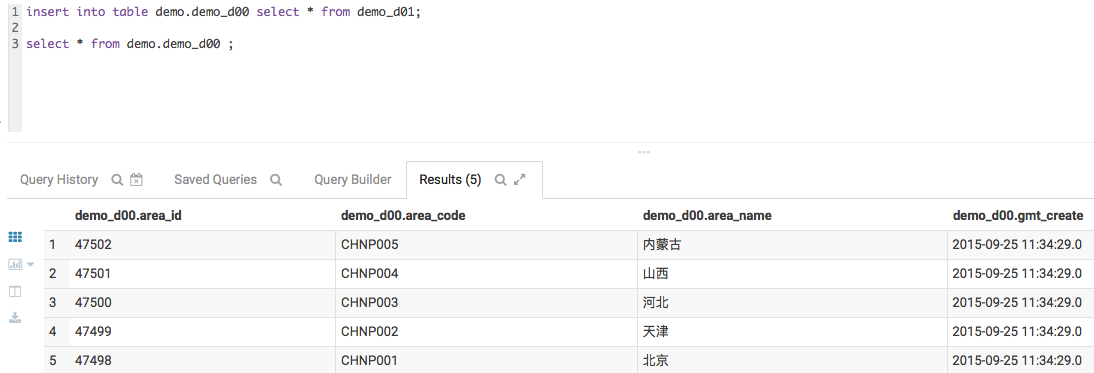
insert into table demo.demo_d00 select * from demo_d01;
初始化之后的数据如下
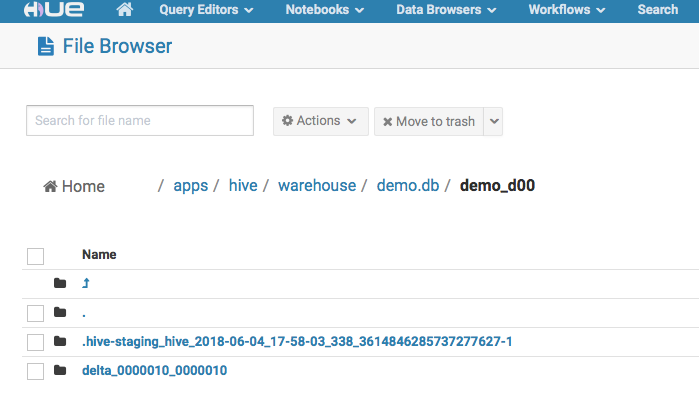
当一个hive表插入了初始化数据后,在对应的文件目录下有这些文件。和普通orc格式的hive表不同,这里有两个文件夹,如下图
update
update demo.demo_d00 set area_code='xxx' where area_id=47501;
select * from demo.demo_d00;
更新操作后的数据如下,可以看到原来的CHNP004变成了xxx
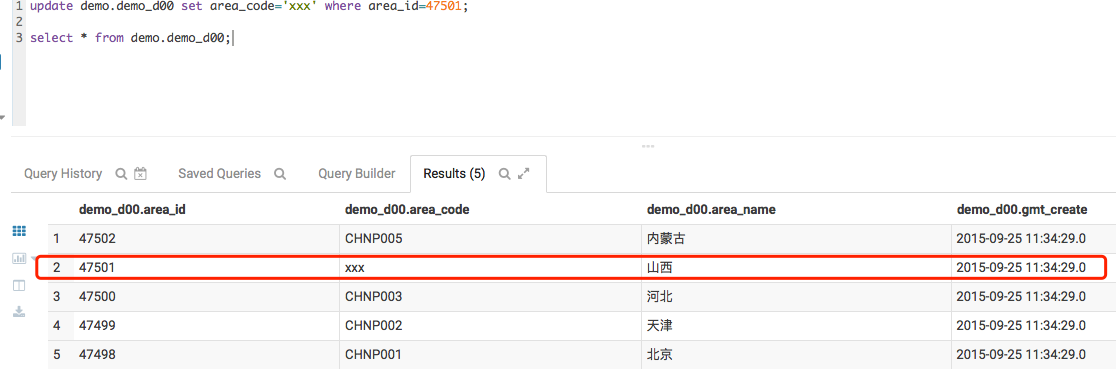
ORC格式的文件本身是不支持更新的,所以对hive表的更新并不是直接修改数据文件,而是通过增加变更数据集(Change Set)的方式完成的。文件夹目录下增加了新的文件,这部分新文件就是本次操作的delta集,如下图中红色框:
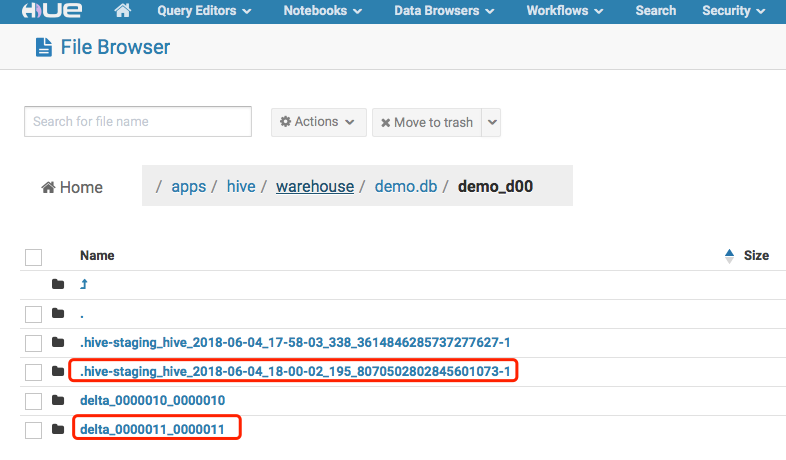
delete
delete from demo.demo_d00 where area_id=47500;
select * from demo.demo_d00;
数据如下
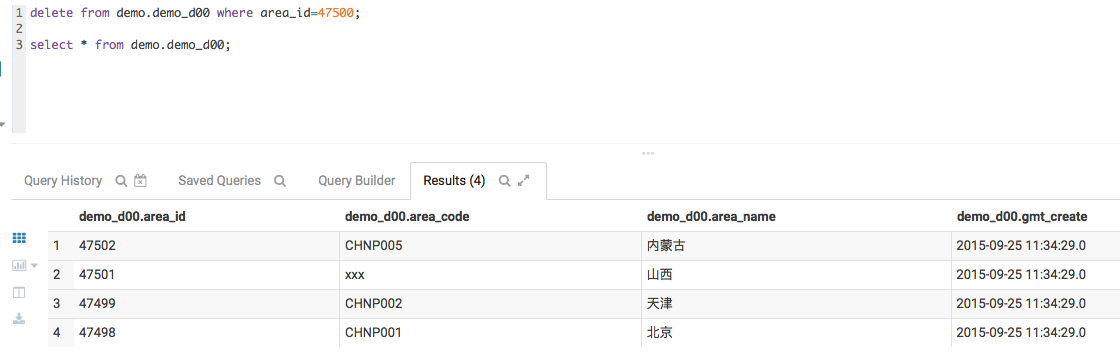
文件如下,可以清楚的看到,不论是update还是delete,实际都是通过delta文件的方式进行的,并没有修改原始的文件。
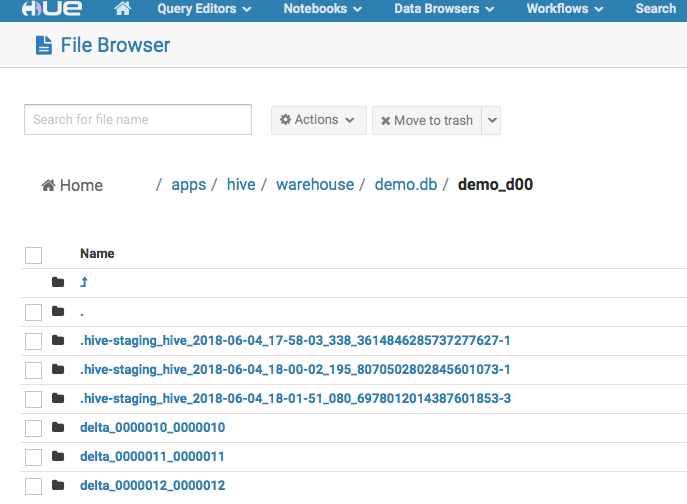
实现SCD 2
渐变维度SCD 2的处理过程可以简单的描述为
- 修改已经存在维度数据的时间戳;
- 把更新的维度数据作为一条新维度插入;
- 插入其他新增维度数据;
常规实现
我们用一个简化的模型来模拟这个SCD 2的更新过程
-- 初始化目标表
truncate table demo.demo_d00;
insert into table demo.demo_d00 select * from demo.demo_d01;
-- SCD2 修改已经存在维度数据的时间戳
update demo.demo_d00
set gmt_create = '2015-09-26 00:00:00'
where exists (select 1 from demo.demo_d02 d2 where demo_d00.area_code=d2.area_code);
-- SCD2 把变量维度(包括更新和新增两部分)数据作为新维度插入
insert into table demo.demo_d00 select * from demo.demo_d02;
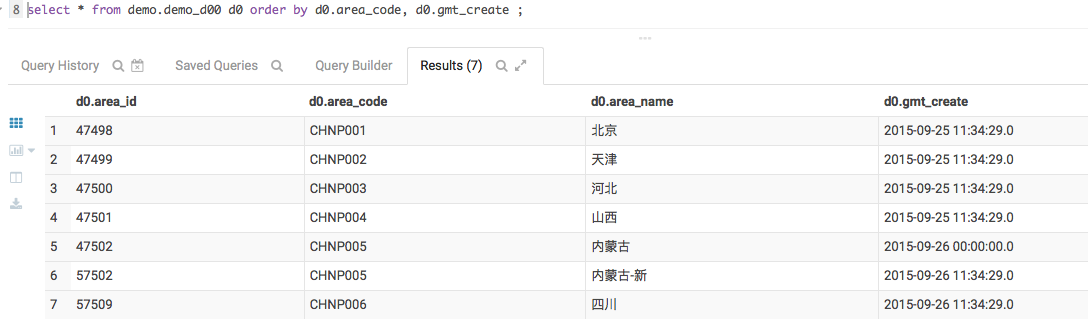
完成后的维度表数据如下,其中CHNP005有两条数据,一条是时间戳已经截止的,另一条是当前的。在hive环境用这个方法实现SCD 2的更新过程,和普通RDBMS没有差异。
Merge语法
在HDP 2.6之后,新增的merge into语法可以更方便的实现upsert操作。
因为我们的环境是HDP 2.4,所以这里不做具体测试,但是我会把语句写在这里,有机会的时候可以继续这个测试。
-- HDP 2.6 提供了merge语法
merge into demo_d00
using demo_d01 d01
on demo_d00.area_code = d01.area_code
when matched then update set
gmt_create = '2015-09-26 00:00:00'
when not matched then insert
values(d01.area_id, d01.area_code, d01.area_name, d01.gmt_create)
;
当前不足
当前我们的测试环境下(HDP 2.4, Spark 2.3.0),只有原生hive才提供了ACID的支持。我们常用的Spark SQL并不支持这种用法。
spark-sql> delete from demo.demo_d00 where area_id=47500;
Error in query:
Operation not allowed: delete from(line 1, pos 0)
== SQL ==
delete from demo.demo_d00 where area_id=47500
^^^
spark-sql>
