

最近的项目中为了能够提升那么一丢丢性能,尝试了一下对 chunks 进行预加载处理。虽然做了异步加载的处理,但是项目大小决定了还是有多个异步的 chunk.js 需要进行预加载,这里我指的是 preload 与 prefetch。
这里推荐一个 GoogleChromeLabs 团队推出的插件:preload-webpack-plugin。
A webpack plugin for injecting <link rel='preload|prefecth'> into HtmlWebpackPlugin pages, with async chunk support

使用大致如下,具体参考其文档:
config = rewirePreloadPlugin(config, env, {
rel: 'preload',
include: 'initial',
as(entry) {
if (/\.(css|less)$/.test(entry)) return 'style';
if (/\.woff$/.test(entry)) return 'font';
if (/\.(png|jpg|jpeg|svg)$/.test(entry)) return 'image';
return 'script';
}});
这个插件对字体元素( woff ),自动加了跨域:
源码:
const crossOrigin = asValue === 'font' ? 'crossorigin="crossorigin" ' : '';
filesToInclude+= `<link rel="${options.rel}" as="${asValue}" ${crossOrigin}href="${entry}">\n`使用后:
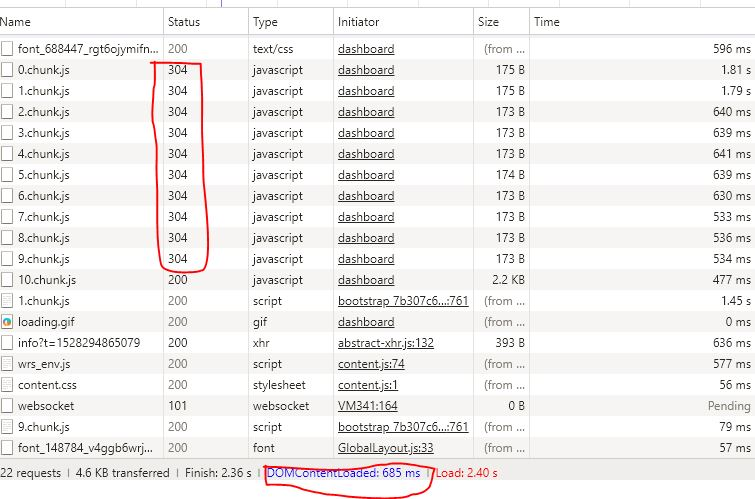
将会在你的 index.html 中的 Head 标签里面添加一堆 <link rel='preload' as='script' href='xxx.chunk.js'>
这就意味着这些资源都会被预加载,然后从缓存中去获取。将会提升网页打开的效率,但是滥用也会浪费带宽。
实际使用中有一个问题,就是我使用的是 create-react-app 并且没有 eject 的情况下,目前这个插件对于 preload 的模式包括 include: 'initial' | 'allChunks' | 'asyncChunks' |'allAssets' | ['chunkName'],(ps: initial 模式还是尤雨溪大大提的 PR )并且提供了黑白名单,应该说是很细粒度的控制我们去按需设置文件为 preload 的。
但是实际上还是会造成有我不需要其 preload 的文件被设置了,这就造成了浪费。
Preload 与 Prefetch
<link rel='prefetch'> 出现的更早,浏览器支持度也挺不错,通俗的理解是着眼于下一个页面资源的预加载,所以在当前页面的优先级是很低的。
prefetch 在浏览器空闲时间下载或预取用户在不久的将来可能访问的文档,在当前的页面加载完成后预取资源放进缓存中,在之后的调用就直接从缓存中获取,从而提升性能。
<link rel='preload' as=''> 则是着眼于现在(当前页面)。浏览器遇到 rel= 'preload' 的标签就会将其推入到预加载器中,这个预加载器也将用于其他我们所需要的,各种各样的,任意类型的资源。为了完成基本的配置,你还需要通过 href和as 属性指定需要被预加载资源的资源路径及其类型。
引用一段 MDN 的描述:
<link>元素的rel属性的属性值preload能够让你在你的HTML页面中<head>元素内部书写一些声明式的资源获取请求,可以指明哪些资源是在页面加载完成后即刻需要的。对于这种即刻需要的资源,你可能希望在页面加载的生命周期的早期阶段就开始获取,在浏览器的主渲染机制介入前就进行预加载。这一机制使得资源可以更早的得到加载并可用,且更不易阻塞页面的初步渲染,进而提升性能。本文提供了一个如何有效使用preload机制的基本说明
其特点是 声明式的资源获取请求(fetch)、不易(注意不是不会)阻塞 onLoad、as 提供的细粒度的控制
总结其优势:
- 更精确地优化资源加载优先级,这种方式可以确保资源根据其重要性依次加载。
- 匹配未来的加载需求,在适当的情况下(相同的资源),重复利用同一资源。
- 为资源应用正确的内容安全策略。
- 为资源设置正确的
Accept请求头。
注意:忽略 as 属性,或者错误的 as 属性会使 preload 等同于 XHR 请求,浏览器不知道加载的是什么,因此会赋予此类资源非常低的加载优先级。
preload 还支持 onload 预加载完成回调、MIME、跨域获取、响应式的预加载、脚本化加载等,更多可以参考 MDN,以及这里,还有这里。
缓存
既然 preload 以及 prefetch 都是优先从 HTTP 缓存中获取资源,我们必然要接触很多 304 Not Modified 响应。
我们先来看一个 304 响应:
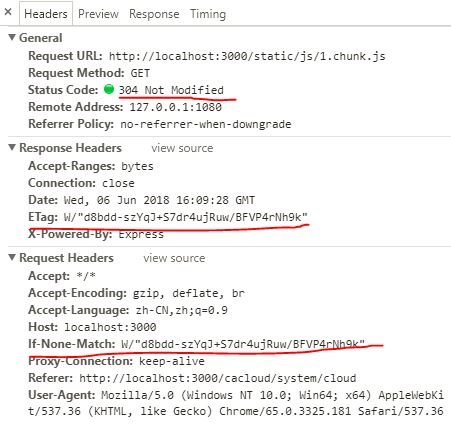
304 中最重要的两个请求头就是 If-None-Match 和 If-Modified-Since。
前者的值是上一次响应中返回的 ETag,ETag 是对该资源的一种唯一标识,只要资源有变化,Etag 就会重新生成。服务器接收到请求头中的 If-None-Match 之后就和文件资源的 Etag 做比较,如果一样,说明资源没有变化,就返回一个 304 Not Modified 并且没有响应体。客户端收到 304 响应后,就会从缓存中读取对应的资源,如果不相同,则表示资源发生了改变,那么服务器就会返回 HTTP/200 OK 响应,响应体就是该资源当前最新的内容.客户端收到 200 响应后,就会用新的响应体覆盖掉旧的缓存资源。
后者对应的上一次响应返回的 Last-Modified。Last-Modified 是该资源文件最后一次更改时间,服务器会在 response header 里返回,同时浏览器会将这个值保存起来,在下一次发送请求时,放到 request header 里的 If-Modified-Since 里,服务器在接收到后也会做比对,如果没过期则返回304,如果过期则返回200 ok。同样会更新旧的文件。
如果两个头部都不带的请求就是无条件(unconditionally)请求该资源,服务器也就必须返回完整的资源数据。
上面所述的几个头部就是协商缓存的关键人物了。
这里还要说明一个概念就是条件请求,所谓条件就是无法确定前端缓存资源是否最新,所以通过上述的头部来做一个验证,返回 304 或者 200。通过条件请求我们可以节省出一个响应体,但是请求还是发出去了。
这里如果连请求都不想发出去怎么办呢?
强缓存、协商缓存
浏览器缓存主要有两类:缓存协商和彻底缓存,也有称之为协商缓存和强缓存。
1.强缓存:不会向服务器发送请求,直接从缓存中读取资源,在chrome控制台的network选项中可以看到该请求返回200的状态码;
2.协商缓存:向服务器发送请求,服务器会根据这个请求的request header的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的response header通知浏览器从缓存中读取资源;
两者的共同点是,都是从客户端缓存中读取资源;区别是强缓存不会发请求,协商缓存会发请求。
浏览器缓存流程图:
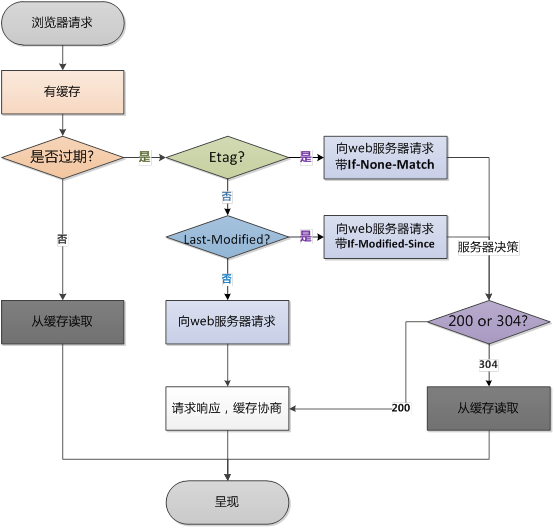
所以我们可以通过设置 Expires( HTTP1.0 ) 以及 Cache-Control( HTTP1.1 ),来命中强缓存,从而跳过发送请求的过程。
Expires:response header里的过期时间,浏览器再次加载资源时,如果在这个过期时间内,则命中强缓存。
Cache-Control:当值设为max-age= 600 时,则代表在这个请求正确返回时间(浏览器也会记录下来)的 10 分钟内再次加载资源,就会命中强缓存。
用户行为对浏览器缓存的控制:
- F5 刷新,浏览器会设置max-age=0,跳过强缓存判断,会进行协商缓存判断。
- Ctrl + F5, 跳过协商缓存与强缓存,直接从服务器拉取资源。
- 地址栏访问,链接跳转是正常用户行为,将会触发浏览器缓存机制。
未完待续....
